Konsolidierung von Werksdaten

Mit konsolidierten Echtzeitdaten die Effizienz optimieren und Risiken mindern
Die Hersteller von heute müssen wissen, wie effizient alle ihre Anlagen über mehrere Werke hinweg laufen – sie müssen sofort benachrichtigt werden, wenn ein Problem auftritt, nicht erst fünf oder zehn Minuten später. Das ist jedoch auch eine ihrer größten Herausforderungen, da sie dazu auf den Echtzeitzugriff auf Daten von mehreren entfernten Standorten aus angewiesen sind, die möglicherweise nur über eine begrenzte oder sporadische Internetverbindung verfügen. Um dieses Problem zu lösen, müssen wir das maschinelle Lernen (ML) und die Datenerfassung an den Netzrand verlagern.
Einfachere Entscheidungsfindung am Netzwerkrand
Wir können Oracle Data Platform so konfigurieren, dass dieses Problem gelöst wird, indem wir Oracle Roving Edge Devices (REDs) nutzen. Jedes RED wurde entwickelt, um Daten zu erfassen, zu speichern, auszuführen, zu verwalten und Erkenntnisse daraus zu gewinnen, sodass Hersteller in der Lage sind, den Entscheidungsfindungsprozess und die Verwaltung von Produktionsanlagen an der Schnittstelle zu automatisieren. Oracle Data Platform für die Fertigung umfasst außerdem Funktionen zur Erkennung von Anomalien, die zur Behebung von Störungen in der Fertigungslinie eingesetzt werden können und wartungsbezogene Erkenntnisse zur Verbesserung der Schadensbegrenzung und -behebung liefern.
Die folgende Architektur zeigt, wie Oracle Data Platform die Konsolidierung von Werksdaten unterstützt, indem es erweiterte Analysen und maschinelles Lernen am Netzrand bereitstellt, um Anomalien zu erkennen, eine intelligente Datenerfassung durchzuführen und Echtzeitinformationen für den Betrieb bereitzustellen.
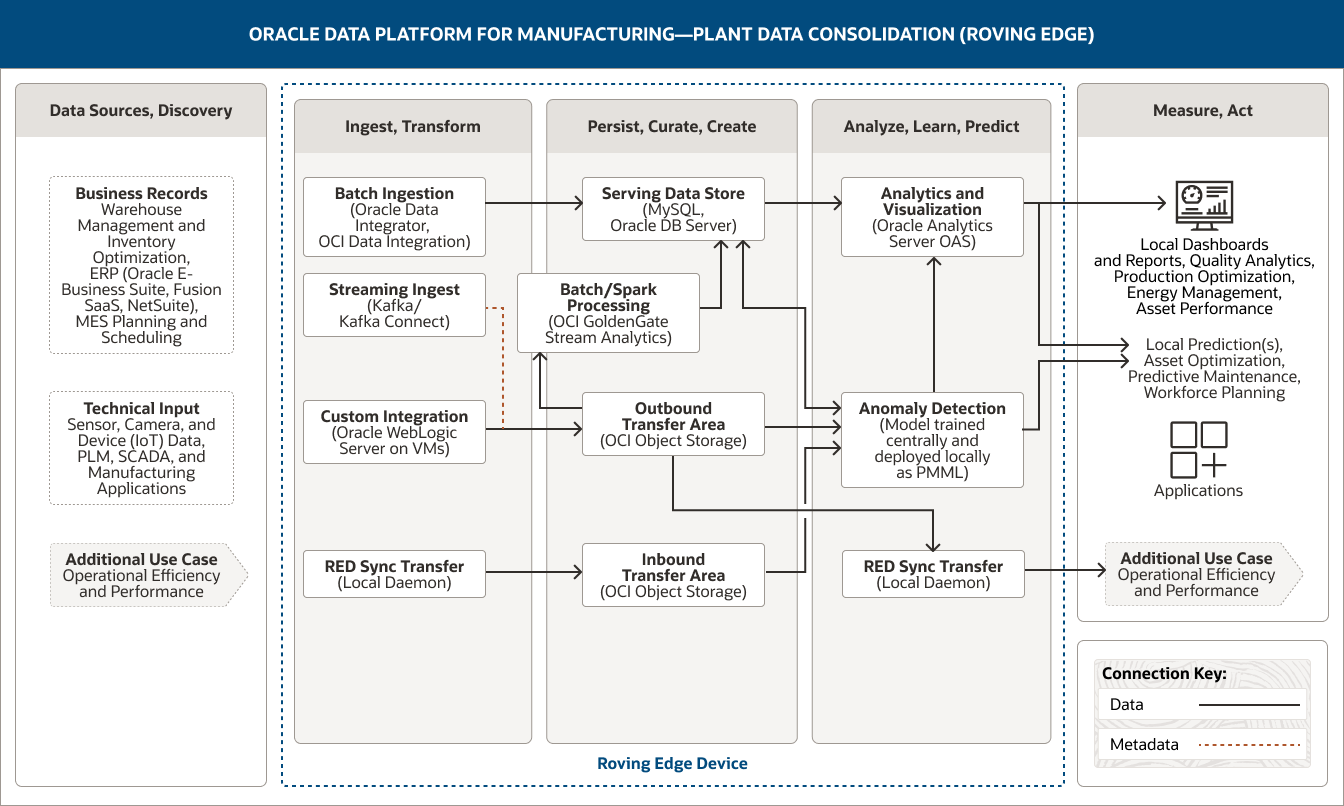
Diese Abbildung zeigt, wie Werksdaten mit Oracle Data Platform für die Fertigung konsolidiert werden können. Die Plattform umfasst die folgenden fünf Pillar:
- 1. Datenquellen, erkennen
- 2. Aufnehmen, transformieren
- 3. Ausharren, kuratieren, schaffen
- 4. Analysieren, lernen, prognostizieren
- 5. Messen, handeln
Der Pillar „Datenquellen, Entdeckung“ umfasst zwei Datenkategorien.
- 1. Geschäftsdatensätze umfassen Daten zur Lagerverwaltung und Bestandsoptimierung, ERP-Daten (Oracle E-Business Suite, Fusion SaaS, NetSuite) sowie MES-Planungs- und -Terminierungsdaten.
- 2. Technische Eingabedaten umfassen Sensor-, Kamera- und Gerätedaten (IoT) sowie Daten aus PLM-, SCADA- und Fertigungsanwendungen.
Der Pillar „Aufnehmen, transformieren“ umfasst vier Funktionen.
- 1. Die Batchaufnahme nutzt Oracle Data Integrator und OCI Data Integration.
- 2. Die Streamingaufnahme nutzt Kafka Connect.
- 3. Die benutzerdefinierte Integration nutzt Oracle WebLogic Server auf VMs.
- 4. Der RED-Synchronisierungstransfer nutzt einen lokalen Daemon.
Die Batchaufnahme verbindet sich einseitig mit dem Serving Data Store.
Die Streamingaufnahme und die benutzerdefinierte Integration verbinden sich einseitig mit dem ausgehenden Transferbereich.
Außerdem stellt der RED-Synchronisierungstransfer einseitig eine Verbindung zum eingehenden Transferbereich her.
Der Pillar „Beibehalten, kurieren, erstellen“ umfasst vier Funktionen.
- 1. Der Serving Data Store nutzt MySQL und Oracle DB-Server.
- 2. Batchverarbeitung/Spark-Verarbeitung nutzt OCI GoldenGate Stream Analytics.
- 3. Der ausgehende Transferbereich nutzt OCI Object Storage.
- 4. Der eingehende Transferbereich nutzt OCI Object Storage.
Diese Funktionen sind innerhalb des Pillars miteinander verbunden. Die Batch-/Spark-Verarbeitung ist einseitig mit dem Serving Data Store verbunden.
Der ausgehende Transferbereich ist einseitig mit der Batch-/Spark-Verarbeitung verbunden.
Drei Funktionen sind mit der Säule „Analysieren, lernen, prognostizieren“ verbunden.
Der Serving Data Store ist einseitig mit der Analyse- und Visualisierungsfunktion und bidirektional mit der Anomalieerkennungsfunktion verbunden. Der ausgehende Übertragungsbereich ist einseitig mit den Funktionen zur Anomalieerkennung und zum RED-Synchronisierungstransfer verbunden.
Der eingehende Übertragungsbereich verbindet sich einseitig mit der Anomalieerkennungsfunktion.
Der Pillar „Analysieren, lernen, prognostizieren“ umfasst drei Funktionen.
- 1. Analytics und Visualisierung nutzt Oracle Analytics Server.
- 2. Die Anomalieerkennung verwendet ein Modell, das zentral trainiert und lokal als PMML bereitgestellt wird.
- 3. Der RED-Synchronisierungstransfer verwendet einen lokalen Daemon.
Die Funktion zur Anomalieerkennung ist unidirektional mit der Analyse- und Visualisierungsfunktion innerhalb der Säule verbunden.
Drei Funktionen sind mit der Säule „Messen, handeln“ verbunden. Die Analyse- und Visualisierungsfunktion ist unidirektional mit lokalen Dashboards und Berichten sowie mit lokalen Prognosen verbunden. Die Funktion zur Anomalieerkennung ist unidirektional mit lokalen Vorhersagen verbunden, und die RED-Synchronisierungsübertragungsfunktion ist unidirektional mit einem zusätzlichen Anwendungsfall verbunden.
Die Säule „Messen, handeln“ erfasst, wie die konsolidierten Werksdaten verwendet werden können. Diese potenziellen Nutzungsmöglichkeiten sind in vier Gruppen unterteilt.
- Die erste Gruppe umfasst lokale Dashboards und Berichte.
- Die zweite Gruppe umfasst lokale Prognosen.
- Die dritte Gruppe umfasst Anwendungen.
- Die vierte Gruppe enthält einen zusätzlichen Anwendungsfall, nämlich die betriebliche Effizienz und Leistung.
Die drei zentralen Säulen – Aufnehmen, transformieren; Ausharren, kuratieren, schaffen; und Analysieren, lernen, prognostizieren – werden durch Oracle Roving Edge Device(s) unterstützt.
Es gibt vier wesentliche Möglichkeiten, Daten in eine Architektur einzubringen, damit die Hersteller die betriebliche Effizienz und Leistung leicht nachvollziehen können.
- Mit einer benutzerdefinierten Integration aus Oracle Integration Repository können wir Daten aus verschiedenen Quellen integrieren – sowohl strukturiert als auch unstrukturiert –, sodass eine Zusammenarbeit mit Geräten, benutzerdefinierten APIs usw. möglich ist. Die Daten können aus jeder Art von Anwendungsentwicklung übernommen werden (z. B. eigenständiger Java- oder Python-Code, Oracle WebLogic Server-basierte Anwendungen oder Kubernetes-basierte Anwendungen). Die Daten werden in einem Objektspeicher gespeichert, um sie weiter zu verfeinern, nach außen zu übertragen oder KI-Modelle zu trainieren.
- Die RED-Datensynchronisierung ist eine effiziente und einfache Möglichkeit, ML-Modelle von einem zentralen Speicherort (z.B. Ihrem Objektspeicher-Repository für trainierte Modelle in Oracle Cloud Infrastructure (OCI)) an den Rand zu übertragen. In diesem Anwendungsfall würde die Randdefinition die RED zusammen mit anderen Maschinen in der Anlage selbst platzieren. Neue Versionen von Modellen werden im „Standalone“ Predictive Model Markup Language-(PMML-)Format gespeichert. Der lokale Daemon führt ein Update durch, wenn ein neues Modell erkannt wird, und überträgt es automatisch an die RED. Die RED-Datensynchronisierung ist zudem eine hervorragende Möglichkeit, alle Daten, die im Laufe des Tages von verschiedenen REDs erfasst werden (z.B. relevante Anomalien, Signale usw.), an Ihren zentralen Speicherort zu übertragen, was höchstwahrscheinlich der Objektspeicher auf OCI ist. Diese Daten werden dann für das Reporting und ML-Modelltraining verwendet. Das Datenvolumen dieser RED-Datensynchronisierungsprozesse bestimmt Ihre Anforderungen an die Telekommunikations- oder Satellitenbandbreite zwischen Netzwerkrand und Rechenzentrum.
- Die Batchaufnahme nutzt Oracle Data Integrator, eine umfassende Datenintegrationslösung, die alle Anforderungen an die Datenintegration erfüllt: von Batch-Loads mit hohem Datenvolumen und hoher Leistung über ereignisgesteuerte Integrationsprozesse bis hin zu SOA-fähigen Datenservices. Während sich die Echtzeit-Anforderungen weiterentwickeln, ist der häufigste Extraktionsprozess aus ERP-, Planungs-, Lagerverwaltungs- und Transportmanagementsystemen eine Batchaufnahme mit einem Extraktions-, Transformations- und Lade- oder einem Extraktions-, Lade- und Transformationsprozess. Diese Extrakte können häufig erfolgen, z. B. alle 10 oder 15 Minuten, aber sie haben immer noch den Charakter einer Massenverarbeitung, da die Transaktionen in Gruppen und nicht einzeln extrahiert und verarbeitet werden. OCI bietet verschiedene Services für die Batchaufnahme, wie z. B. den nativen OCI Data Integration-Service und Oracle Data Integrator, die auf einer OCI Compute-Instanz laufen. Je nach Volumes und Datentypen können Daten in den Objektspeicher oder direkt in eine strukturierte relationale Datenbank zur dauerhaften Speicherung geladen werden.
- Die Analyse von Daten in Echtzeit aus verschiedenen Quellen kann Fertigungsunternehmen wertvolle Einblicke in ihre betriebliche Effizienz und Gesamtleistung verschaffen. Oracle Data Platform nutzt die Streamingaufnahme, um Datenstreams aus mehreren ISA-95-Level-2-Systemen aufzunehmen, wie Überwachungssteuerungs- und Datenerfassungssysteme (SCADA), programmierbare Logiksteuerelemente und Batchautomatisierungssysteme. Streaming-Daten (Ereignisse) werden aufgenommen und einige grundlegende Transformationen/Aggregationen werden durchgeführt, bevor die Daten im Objektspeicher gespeichert werden. Mithilfe von Streaming-Analysen können korrelierende Ereignisse identifiziert werden, und die identifizierten Muster können (manuell) für eine Data Science-Untersuchung der Rohdaten zurückgeführt werden. Während herkömmliche Analysetools Informationen aus Daten im Ruhezustand extrahieren, bewertet die Streaming-Analyse den Wert von Daten in Bewegung, d. h. in Echtzeit.
Die Datenpersistenz und -verarbeitung basiert auf drei Komponenten.
- Im Serving Data Store werden Daten von Oracle Database Server oder MySQL zur Datenverarbeitung verwaltet. Der Serving Data Store bietet eine persistente relationale Ebene, die häufig verwendet wird, um Daten über SQL-basierte Tools direkt an Endbenutzer zu liefern. Er fungiert auch als Dienstschicht für spezielle Analysen.
- Alle Daten, die von Datenquellen in ihrer Rohform (als native Datei oder Extrakt) abgerufen werden, werden erfasst und in den Objektspeicher geladen, um für das aktuelle oder zukünftige ML-Modelltraining verwendet zu werden. Der Cloud-Objektspeicher ist die gängigste Datenpersistenzschicht für unsere Datenplattform. Er dient sowohl als Eingangs-Transferbereich als auch als Ausgangs-Transferbereich. Er kann sowohl für strukturierte als auch für unstrukturierte Daten verwendet werden.
- Mit dem Objektspeicher als primäre Datenpersistenz-Stufe ist OCI GoldenGate Stream Analytics die primäre Verarbeitungs-Engine. Die Batchverarbeitung umfasst mehrere Aktivitäten, einschließlich der grundlegenden Behandlung hinsichtlich der Qualität, der Verwaltung fehlender Daten und der Filterung basierend auf definierten ausgehenden Datasets. Die Ergebnisse werden basierend auf der erforderlichen Verarbeitung und den verwendeten Datentypen in verschiedene Ebenen des Objektspeichers oder in ein persistentes relationales Repository zurückgeschrieben.
Die Fähigkeit, zu analysieren, zu lernen und Vorhersagen zu treffen, beruht auf zwei Technologien.
- Die Analyse- und Visualisierungsservices bieten deskriptive Analysen (Beschreibung aktueller Trends mit Histogrammen und Diagrammen), prädiktive Analysen (Vorhersage zukünftiger Ereignisse, Ermittlung von Trends und Bestimmung der Wahrscheinlichkeiten ungewisser Ergebnisse) und präskriptive Analysen (Vorschläge für geeignete Maßnahmen, die zu einer optimalen Entscheidungsfindung führen). Oracle Analytics Server bietet die Funktionalität zur Bereitstellung von deskriptiven Analysen im Zusammenhang mit der betrieblichen Berichterstattung und präskriptiven Analysen. Darüber hinaus können ML-Modelle direkt in den Oracle Analytics Server-Datenfluss integriert werden. Oracle Analytics Server ist für die On-Premises-Ausführung konzipiert und bietet Dashboards, Berichte, Warnmeldungen, Self-Service-Datenaufbereitung und vom Endbenutzer gesteuerte Algorithmen für maschinelles Lernen. Oracle Data Platform für die Fertigung ist völlig offen und flexibel, sodass Sie, falls gewünscht, stattdessen Tools von Drittanbietern verwenden können.
- Neben dem Einsatz fortschrittlicher Analyseverfahren werden ML-Modelle entwickelt, trainiert und eingesetzt, um die Erkennung von Anomalien zu unterstützen. OCI Anomaly Detection ist ein KI-Dienst, der es Entwicklern erleichtert, geschäftsspezifische Modelle zur Erkennung von Anomalien zu erstellen, die kritische Vorfälle markieren und so die Erkennung und Lösung beschleunigen. Diese Modelle werden an der zentralen Stelle trainiert und im PMML-Format bereitgestellt, damit sie lokal als Java- oder Python-Code ausgeführt werden können.
Entscheidungsfindung automatisieren, um die Rentabilität zu steigern
Oracle Data Platform ermöglicht es Herstellern, den größtmöglichen Nutzen aus all ihren verfügbaren Daten zu ziehen und gleichzeitig den Datenzugriff und die Datenspeicherung zu vereinfachen und zu rationalisieren. Durch die Möglichkeit, die Datenerfassung und das ML-Scoring über Oracle Roving Edge Devices an den Netzwerkrand zu bringen, können Hersteller bessere Geschäftsentscheidungen treffen, die auf genauen Daten basieren, die wiederum immer verfügbar sind, wenn sie sie benötigen. Dadurch können sie ihre Effizienz und Produktion steigern und gleichzeitig die Kosten senken.
Verwandte Ressourcen
-
Anwendungsfall
Einsatz von Daten zur Verbesserung des Arbeitsschutzes
Erfahren Sie, wie Sie mithilfe einer Datenplattform, die Sie anhand von erweiterten Analysen bei der Verbesserung des Arbeitsschutzes unterstützt, Ihre Fertigungsprozesse sicherer machen können.
-
Anwendungsfall
Daten zur Verbesserung der betrieblichen Effizienz und Leistung in der Fertigung
Erfahren Sie, wie Sie mithilfe einer Datenplattform, die durch maschinelles Lernen zur Leistungssteigerung beiträgt, Fertigungsprozesse effizienter verwalten können.
-
Anwendungsfall
Daten nutzen, um von reaktiver zu vorausschauender Wartung überzugehen
Erfahren Sie, wie Sie Assets mit einer Datenplattform optimieren, die vorausschauende Wartung mit maschinellem Lernen ermöglicht.
Erste Schritte
Mehr als 20 kostenlose Cloud-Services mit einer 30-tägigen Testversion für noch mehr
Oracle bietet ein Free Tier ohne zeitliche Begrenzung für eine Auswahl von mehr als 20 Services wie Autonomous AI Database , Arm Compute und Storage an. Darüber hinaus erhalten Sie 300 US-Dollar an kostenlosen Credits, um zusätzliche Cloud-Services zu testen. Informieren Sie sich über die Einzelheiten und melden Sie sich noch heute für Ihr kostenloses Konto an.
-
Was ist im kostenlosen Oracle Cloud-Kontingent enthalten?
- 2 Autonomous AI Database-Instanzen mit jeweils 20 GB
- AMD und Arm Compute-VMs
- Insgesamt 200 GB Blockspeicher
- 10 GB Objektspeicher
- 10 TB ausgehende Datenübertragung pro Monat
- Mehr als 10 permanent kostenlose Services
- Kostenlose Credits im Wert von 300 US-Dollar, 30 Tage lang noch mehr
Mit schrittweiser Anleitung lernen
Erleben Sie eine breite Palette von OCI-Services in Tutorials und praktischen Übungen. Unabhängig davon, ob Sie ein Entwickler, Administrator oder Analyst sind, können wir Ihnen zeigen, wie OCI funktioniert. Viele Übungen werden auf dem Free Tier von Oracle Cloud oder einer von Oracle bereitgestellten freien Laborumgebung ausgeführt.
-
Erste Schritte mit zentralen OCI-Services
Die Übungen in diesem Workshop umfassen eine Einführung in zentrale Oracle Cloud Infrastructure-(OCI-)Services wie virtuelle Cloud-Netzwerke (VCN) sowie Compute- und Speicherservices.
Übungen zu den zentralen OCI-Services jetzt starten -
Autonomous AI Database – Schnellstart
In diesem Workshop vermitteln wir Ihnen die ersten Schritte, um Oracle Autonomous AI Database zu nutzen.
Jetzt mit der Übung für den Schnelleinstieg in Autonomous AI Database beginnen -
App aus einer Kalkulationstabelle erstellen
In dieser Übung laden Sie eine Tabelle in eine Oracle Database-Tabelle hoch und erstellen anschließend eine Anwendung auf Basis dieser neuen Tabelle.
Diese Übung jetzt starten
Entdecken Sie mehr als 150 Best Practice-Designs
Erfahren Sie, wie unsere Architekten und anderen Kunden eine Vielzahl von Workloads bereitstellen, von Unternehmensanwendungen bis hin zu HPC, von Microservices bis hin zu Data Lakes. Informieren Sie sich über Best Practice, hören Sie von anderen Kundenarchitekten in unserer Reihe „Built & Deploy“, und stellen Sie außerdem viele Workloads mit unserer Funktion „Click-to-Deployment“ oder selbst aus unserem GitHub-Repository bereit.
Beliebte Architekturen
- Apache Tomcat mit MySQL Database Service
- Oracle Weblogic auf Kubernetes mit Jenkins
- ML- und KI-Umgebungen
- Tomcat on Arm mit Oracle Autonomous AI Database
- Loganalyse mit ELK-Stack
- HPC mit OpenFOAM
Erfahren Sie, wie viel Sie bei OCI sparen können
Die Tarife für Oracle Cloud sind unkompliziert, mit weltweit konsequent niedrigen Tarifen und zahlreichen unterstützten Anwendungsfällen. Um den für Sie zutreffenden, niedrigen Tarif zu berechnen, gehen Sie zum Kostenrechner und konfigurieren Sie die Services entsprechend Ihrer Anforderungen.
Den Unterschied entdecken:
- 1/4 der Kosten für ausgehende Bandbreite
- 3-mal besseres Preis-Leistungs-Verhältnis
- Gleicher niedriger Preis in jeder Region
- Niedrige Tarife ohne langfristige Verpflichtungen
Vertrieb kontaktieren
Möchten Sie mehr über die Oracle Cloud Infrastructure erfahren? Einer unserer Experten wird Ihnen gerne helfen.
-
Sie können Fragen beantworten wie:
- Welche Workloads werden am besten auf OCI ausgeführt?
- Wie kann ich meine gesamten Oracle Investitionen optimal nutzen?
- Wie schlägt sich OCI verglichen mit anderen Cloud-Computing-Anbietern?
- Wie kann OCI Ihre IaaS- und PaaS-Ziele unterstützen?