Verbesserung der wertorientierten Pflege durch Leistungsüberwachung

Verbesserung der Personalsituation und der Patientenversorgung
Die Gesundheitssysteme von heute stehen vor zwei großen, miteinander verknüpften Herausforderungen: Burnout der Mitarbeiter und Personalmangel. Fast 50 % der befragten Ärzte und Krankenpfleger berichteten über erhebliche Burnout-Symptome, die auf die hohe Belastung durch bürokratische und administrative Aufgaben und zu viele Arbeitsstunden zurückzuführen sind. Infolgedessen haben sich viele Arbeitnehmer dazu entschlossen, die Branche auf der Suche nach einer besseren Work-Life-Balance zu verlassen, wodurch in den Krankenhäusern große Personallücken entstehen, die sie nicht füllen können. In mehr als der Hälfte der US-Krankenhäuser liegt die Zahl der unbesetzten Stellen für Pflegekräfte bei über 7,5 %, und die Ausgaben für Überstunden und Leiharbeit sind seit 2013 um 169 % gestiegen. Leider deuten viele Schätzungen darauf hin, dass sich der Fachkräftemangel im Gesundheitswesen in den kommenden zehn Jahren nur noch verschlimmern wird.
Um diese beiden Herausforderungen zu meistern, müssen die Anbieter ihre Personalmodelle so optimieren, dass das Wohlergehen des medizinischen Personals im Vordergrund steht und gleichzeitig die bestmöglichen Patientenerfahrungen und -ergebnisse gewährleistet sind. Datenplattformen werden eine entscheidende Rolle spielen, da sie den Anbietern einen zentralen Zugang zu Daten aus unterschiedlichen Systemen sowie fortschrittliche Analysen und maschinelle Lernmodelle bieten, mit denen sie den Personalbedarf genauer prognostizieren können. Mit diesen Erkenntnissen können Gesundheitsorganisationen die Arbeitsbelastung besser ausgleichen und jederzeit eine angemessene Personalbesetzung sicherstellen, um Burnout zu verhindern und die Patientenversorgung zu verbessern.
Vereinfachung der Personalplanung im Gesundheitswesen durch maschinelles Lernen
Während klinische Daten den Ärzten viel über ihre Patienten verraten, können betriebliche Systeme, wie z. B. Human Capital Management-(HCM-)Systeme, den Pflegeeinrichtungen viel über ihre Mitarbeiter verraten, z. B. über historische Dienstpläne, Arbeitsstunden und Krankheitszeiten von Ärzten und anderem Personal. Wie die folgende Architektur demonstriert, vereinheitlicht Oracle Data Platform klinische und betriebliche Daten und nutzt fortschrittliche Analysen und maschinelles Lernen, um Anbietern zu vermitteln, wie Personalmodelle die Behandlungsergebnisse der Patienten beeinflussen, wie Personalentscheidungen die nächste Arbeitswoche der Pfleger beeinflussen könnten, welche personellen Lücken im Falle eines weiteren starken Anstiegs der COVID-19-Fälle geschlossen werden müssen, wie ein optimales Personalmodell zu einem bestimmten Zeitpunkt aussieht und vieles mehr.
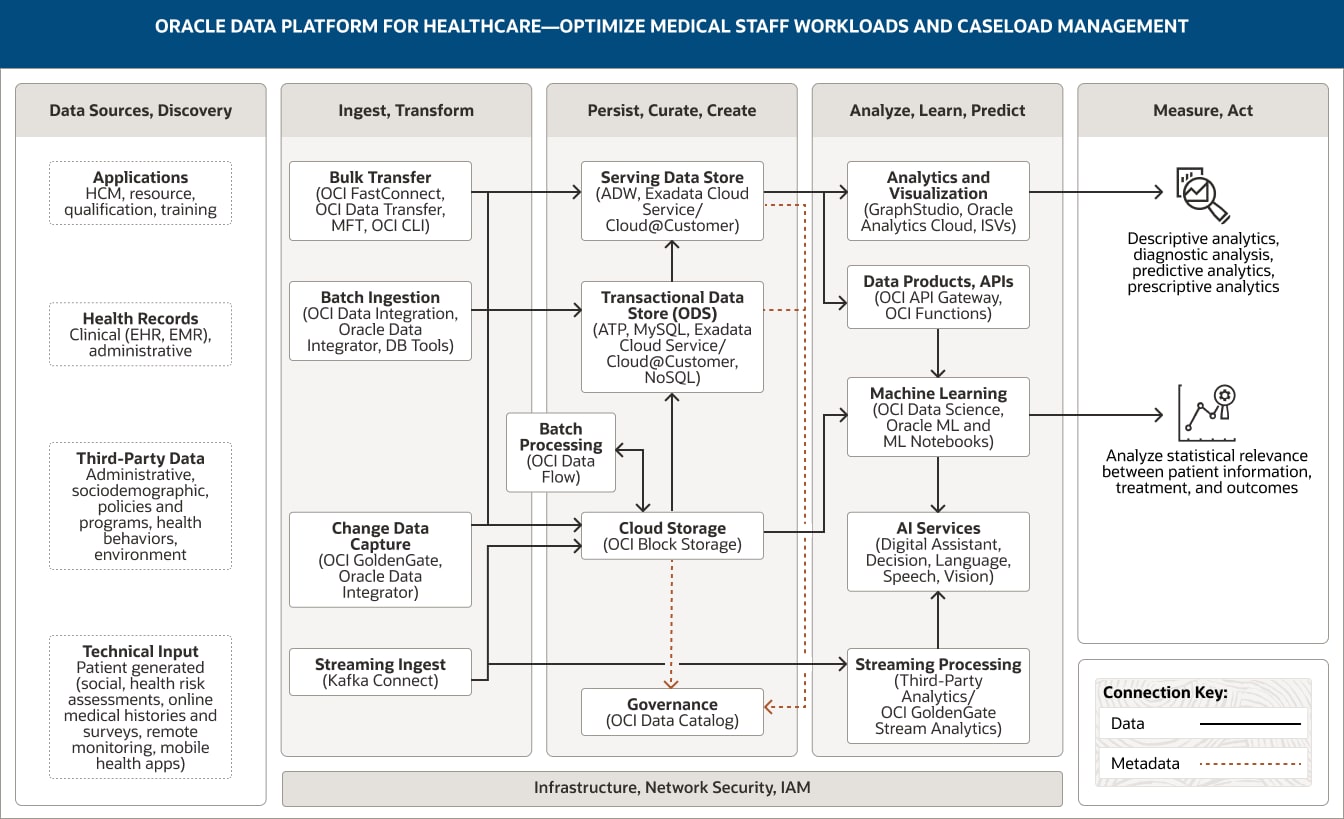
Diese Abbildung zeigt, wie das Arbeitspensum des medizinischen Personals mit Oracle Data Platform for Healthcare optimiert werden können. Die Plattform umfasst die folgenden fünf Pillar:
- 1. Datenquellen, erkennen
- 2. Aufnehmen, transformieren
- 3. Ausharren, kuratieren, schaffen
- 4. Analysieren, lernen, prognostizieren
- 5. Messen, handeln
Der Pillar „Datenquellen, Entdeckung“ umfasst vier Datenkategorien.
- 1. Die Anwendungsdaten umfassen HCM-, Ressourcen-, Qualifikations- und Schulungsdaten.
- 2. Zu den Gesundheitsdaten gehören klinische Daten wie Daten aus elektronischen Patientenakten, EMR und Verwaltungssystemen.
- 3. Daten von Dritten umfassen administrative und soziodemografische Daten sowie Daten zu Politik und Programmen, Gesundheitsverhalten und Umwelt.
- 4. Zu den technischen Eingabedaten gehören patientengenerierte Daten (z. B. soziale Daten, Gesundheitsrisikobewertungen, Online-Anamnesen und Umfrageantworten) sowie Daten aus der Fernüberwachung und aus mobilen Gesundheits-Apps.
Der Pillar „Aufnehmen, transformieren“ umfasst vier Funktionen.
- 1. Die Massenübertragung verwendet OCI FastConnect, OCI Data Transfer, MFT und OCI CLI.
- 2. Die Batchaufnahme verwendet OCI Data Integration, Oracle Data Integrator und DB-Tools.
- 3. Die Datenänderungserfassung verwendet OCI GoldenGate und Oracle Data Integrator.
- 4. Die Streaming-Aufnahme verwendet Kafka Connect.
Alle vier Funktionen verbinden sich unidirektional mit dem Serving Data Store, dem Cloud-Speicher und dem Transaktionsdatenspeicher innerhalb der Säule „Ausharren, kuratieren, schaffen“.
Darüber hinaus ist die Streaming-Aufnahme mit der Stream-Verarbeitung innerhalb des Pillars „Analysieren, lernen, prognostizieren“ verbunden.
Der Pillar „Beibehalten, kurieren, erstellen“ umfasst fünf Funktionen.
- 1. Der Serving Data Store verwendet Autonomous Data Warehouse, Exadata Cloud Service und Exadata Cloud@Customer.
- 2. Der Transaktionsdatenspeicher verwendet Autonomous Transaction Processing, MySQL, Exadata Cloud Service, Exadata Cloud@Customer und NoSQL.
- 3. Der Cloud-Speicher verwendet OCI Object Storage.
- 4. Die Batchverarbeitung verwendet OCI Data Flow.
- 5. Governance verwendet OCI Data Catalog.
Diese Funktionen sind innerhalb des Pillars miteinander verbunden. Der Cloud-Speicher ist unidirektional mit dem Serving Data Store und außerdem bidirektional mit der Batchverarbeitung verbunden.
Der Transaktionsdatenspeicher ist unidirektional mit dem Serving Data Store verbunden.
Zwei Funktionen sind mit der Säule „Analysieren, lernen, prognostizieren“ verbunden: Der Serving Data Store ist sowohl mit den Analyse- und Visualisierungsfunktionen als auch mit den Datenprodukten und APIs verbunden. Der Cloud-Speicher ist mit der ML-Funktion verbunden.
Der Pillar „Analysieren, lernen, prognostizieren“ umfasst fünf Funktionen.
- 1. Analysen und Visualisierungen verwenden Oracle Analytics Cloud, GraphStudio und ISVs.
- 2. Datenprodukte, APIs verwenden OCI API Gateway und OCI Functions.
- 3 Maschinelles Lernen verwendet OCI Data Science, Oracle Machine Learning und Oracle ML Notebooks.
- 4. AI-Services verwenden Oracle Digital Assistant, OCI Decision, OCI Speech, OCI Language und OCI Vision.
- 5. Die Streamingverarbeitung verwendet OCI GoldenGate Stream Analytics und Streamanalysen von Drittanbietern.
Drei Funktionen sind innerhalb der Säule miteinander verbunden. Datenprodukte und APIs sind unidirektional mit dem maschinellen Lernen verbunden, das wiederum unidirektional mit den KI-Diensten verbunden ist, und die Stromverarbeitung ist unidirektional mit den KI-Diensten verbunden.
Der Serving Data Store, der Transaktionsdatenspeicher und der Objektspeicher stellen Metadaten für OCI Data Catalog bereit.
Die Säule „Messen, handeln“ erfasst, wie die Datenanalyse zur Optimierung der Arbeitsbelastung des medizinischen Personals und des Caseload-Managements eingesetzt werden kann. Diese Anwendungen sind in zwei Gruppen unterteilt.
- 1. Die erste Gruppe umfasst beschreibende Analysen, Diagnoseanalysen sowie prädiktive und präskriptive Analysen.
- 2. Die zweite Gruppe umfasst die Analyse der statistischen Relevanz zwischen Patienteninformation, Behandlung und Ergebnissen.
- 3. Die drei zentralen Säulen – Aufnehmen, transformieren; Ausharren, kuratieren, schaffen; und Analysieren, lernen, prognostizieren – werden durch Infrastruktur, Netzwerk, Sicherheit und IAM unterstützt.
Es gibt im Wesentlichen drei Möglichkeiten, Daten in eine Architektur einzubringen, die es Organisationen des Gesundheitswesens ermöglichen, zu verstehen, wie die einzelnen Abteilungen zu einem bestimmten Zeitpunkt am besten besetzt werden können.
- Historische Personal- und Patientendaten sind entscheidend für das Verständnis und die Vorhersage des künftigen Personalbedarfs. Die HCM-Anwendung wird einen Großteil der Daten liefern, die für einen Einblick in frühere Personalbesetzungsmodelle und einzelne Mitarbeiter benötigt werden. Und die Anwendung für Aufnahme, Entlassung und Verlegung (ADT) enthält grundlegende Angaben zu jedem Patienten. Diese Daten können mit Patientendaten aus Drittanbieterquellen angereichert werden, zu denen beispielsweise unstrukturierte Daten aus sozialen Medien gehören können. Häufige Echtzeit- oder Beinahe-Echtzeitextrakte, für die eine Datenänderungserfassung erforderlich ist, sind gängig, und Daten werden regelmäßig von HCM- und ADT-Betriebssystemen über OCI GoldenGate aufgenommen. OCI GoldenGate ist zudem eine entscheidende Komponente der sich entwickelnden Data-Mesh-Architekturen, bei denen „Datenprodukte“ die zentralen Datenobjekte sind.
- Jetzt können wir auch noch Streaming-Daten von Wearables hinzufügen, die in Echtzeit über einen Streaming-Dienst/Kafka aufgenommen werden. So können wir beispielsweise Daten von Wearables mit GPS-Tracking erfassen, die den Standort und die Bewegungen des Personals über den Tag hinweg überwachen, und diese Daten nutzen, um zu verstehen, wie wir das Personal besser den Abteilungen und Patienten zuweisen können. Diese gestreamten Daten (Ereignisse) werden aufgenommen, und einige grundlegende Transformationen/Aggregationen werden ausgeführt, bevor die Daten im Cloud-Speicher gespeichert werden.
- Auch wenn sich die Echtzeitanforderungen ständig weiterentwickeln, ist die häufigste Extraktion aus Gesundheitssystemen eine Art Batchaufnahme mit einem Extraktions-, Transformations- und Lade- oder Export-, Lade- und Transformationsprozess. Die Batchaufnahme wird verwendet, um Daten aus Systemen zu importieren, die keine Streaming-Aufnahme unterstützen (z. B. ältere Mainframe-Systeme). Um den Patientenbedarf vollständig zu verstehen, müssen wir auch Daten aus einem operativen System wie einem elektronischen Patientenakten (EMR) oder einem elektronischen Krankenakten (EHR)-System aufnehmen, höchstwahrscheinlich über das Fast Healthcare Interoperability Resources-Protokoll. Die Daten stammen aus verschiedenen Produkten und Regionen. Batchaufnahmen können häufig erfolgen, z. B. alle 10 oder 15 Minuten, aber es handelt sich immer noch um Massenaufnahmen, da die Transaktionen in Gruppen und nicht einzeln extrahiert und verarbeitet werden.
Die Datenpersistenz und die Verarbeitungsoptionen für alle gesammelten Daten basieren vier Komponenten.
- Aufgenommene Rohdaten werden im Cloud-Speicher für die Batchverarbeitung gespeichert. Dabei werden die erforderlichen Bereinigungen, Anreicherungen usw. ausgeführt, um die Daten in den erforderlichen Status zu versetzen, der von nachgelagerten Benutzern verwendet werden muss – z. B. Personen, Anwendungen oder Plattformen für maschinelles Lernen. Obwohl einige Daten direkt im dienenden Datenspeicher abgelegt werden können, werden diese Daten gleichzeitig auch im Cloud-Speicher abgelegt. Diese Daten werden mit Spark verarbeitet. Die Verarbeitung kann direkt mit OCI Data Flow oder als Teil einer größeren Pipeline mit den Orchestrierungsfunktionen in OCI Data Integration durchgeführt werden. Die verarbeiteten Datensätze werden an den Cloud-Speicher zurückgegeben, wo sie weiter aufbewahrt, kuratiert und analysiert und schließlich in optimierter Form in den dienenden Datenspeicher geladen werden.
- Der Transaktionsdatenspeicher wird für Betriebsberichte und als Datenquelle für ein Domain-Data Warehouse oder ein Enterprise Data Warehouse (EDW) verwendet. Er ist ein ergänzendes Element eines EDW in einer Entscheidungsunterstützungs-Umgebung und wird für operative Berichterstattung, Kontrollen und Entscheidungsfindung verwendet, im Gegensatz zum EDW, das für die taktische und strategische Entscheidungsunterstützung verwendet wird. Ein Operational Data Store (ODS) ist in der Regel eine relationale Datenbank, die darauf ausgelegt ist, Daten aus mehreren Quellen zu integrieren und aufzubewahren, um sie für zusätzliche Vorgänge, Berichte, Kontrollen und operative Entscheidungsunterstützung zu nutzen.
- Wir haben jetzt verarbeitete Datensätze erstellt, die in optimierter relationaler Form dauerhaft gespeichert werden können, um die Verwaltungs- und Abfrageperformance im dienenden Datenspeicher zu gewährleisten. Dadurch erhalten die Anbieter die Möglichkeit, alle Daten und Variablen zu prüfen, die für die Entwicklung optimaler Personaleinsatzpläne erforderlich sind.
Die Fähigkeit, zu analysieren, vorherzusagen und zu handeln, beruht auf zwei Technologien.
- Die Analyse- und Visualisierungsservices bieten deskriptive Analysen (Beschreibung aktueller Trends mit Histogrammen und Diagrammen), prädiktive Analysen (Vorhersage zukünftiger Ereignisse, Ermittlung von Trends und Bestimmung der Wahrscheinlichkeiten ungewisser Ergebnisse) und präskriptive Analysen (Vorschläge für geeignete Maßnahmen, die zu einer optimalen Entscheidungsfindung führen). Zusammen können sie zur Vorhersage des Personalbedarfs und zur Abgabe geeigneter Empfehlungen verwendet werden. Mithilfe von Analysen lässt sich beispielsweise vorhersagen, ob ein Cluster von Patienten, die in einem bestimmten Gebiet leben, unterschiedlichen Umwelteinflüssen (z. B. Temperatur) ausgesetzt sind und bestimmte Symptome aufweisen, auf einen bevorstehenden Krankheitsausbruch hinweist, der es erforderlich machen würde, dass ein Anbieter sein Personalmodell ändert, um den erwarteten Anstieg der Fallzahlen zu bewältigen.
- Neben dem Einsatz von erweiterten Analysen werden auch Modelle für maschinelles Lernen entwickelt, trainiert und bereitgestellt. Diese trainierten Modelle können sowohl auf aktuelle als auch auf historische Betriebsdaten angewendet werden, um Ereignisse und Trends zu erkennen, z. B. eine Zunahme unzufriedener Mitarbeiter, die zu einer höheren Fluktuationsrate führen kann. Diese und weitere Ergebnisse können wieder in der Dienstschicht gespeichert und mit Analysetools wie Oracle Analytics Cloud gemeldet werden. Das Modell und die Daten können außerdem in Systeme des maschinellen Lernens wie OCI Data Science eingespeist werden, um die Modelle weiter zu trainieren und effizientere Personalbesetzungsmodelle zu empfehlen, bevor sie gefördert werden. Auf diese Modelle kann über APIs zugegriffen werden, die im bereitstellenden Datenspeicher bereitgestellt oder als Teil der Streaming-Analysepipeline von OCI GoldenGate eingebettet werden.
- Unsere kuratierten, getesteten und qualitativ hochwertigen Daten und Modelle können Governance-Regeln und -Richtlinien anwenden und als „Datenprodukt“ (API) innerhalb einer Data-Mesh-Architektur für die Verteilung im Gesundheitswesen verfügbar gemacht werden.
Mehr als nur Personal: Nutzung von Daten zur Bewältigung anderer wichtiger Herausforderungen im Gesundheitswesen
Neben der Möglichkeit, bessere und genauere Personaleinsatzmodelle für Ihre Gesundheitseinrichtung zu entwickeln, kann Oracle Data Platform Ihnen außerdem dabei helfen, den Betrieb in anderen Bereichen zu optimieren, um die Patientenversorgung zu verbessern, Kosten zu senken und die Employee Experience zu verbessern. Im Folgenden sind einige Beispiele.
- Eine ganzheitliche und koordinierte Betreuung von Patientengruppen fördern.
- Das Potenzial für Systemausfälle im Falle einer voraussichtlichen Pandemie im Voraus erkennen und proaktiv eingreifen, um den Erfolg des Systems zu gewährleisten.
- Trends in Patientenkohorten beobachten, um die Wirksamkeit ihrer Pflegeprogramme zu bewerten.
- Bereiche mit übermäßigem Behandlungsaufwand ermitteln.
- Qualität und Kosten der Pflege überwachen.
- Risikostratifikationsmodelle für Patienten erstellen.
- Das Risiko der Wiederaufnahme eines Patienten vorhersagen.
- Präventive Maßnahmen zur Unterstützung des Patientenselbstmanagements empfehlen.
Verwandte Ressourcen
-
Anwendungsfall
Optimierung der Lieferkette im Gesundheitswesen
Erfahren Sie, wie Sie die Resilienz Ihrer Lieferkette mit Oracle Data Platform für das Gesundheitswesen steigern können.
-
Anwendungsfall
Gesundheitsmanagement für die Bevölkerung
Erfahren Sie, wie Sie mit Oracle Data Platform für das Gesundheitswesen die Verwaltung der Gesundheitsversorgung optimieren können, um den Bedürfnissen der Patienten besser gerecht zu werden, die Ergebnisse zu verbessern und die Kosten zu senken.
-
Anwendungsfall
Verbesserung der wertorientierten Pflege durch Leistungsüberwachung
Erfahren Sie, wie Sie Ihre Strategie für eine wertorientierte Pflege mit Oracle Data Platform einfacher evaluieren können.
Erste Schritte
Mehr als 20 kostenlose Cloud-Services mit einer 30-tägigen Testversion für noch mehr
Oracle bietet ein Free Tier ohne zeitliche Begrenzung für eine Auswahl von mehr als 20 Services wie Autonomous AI Database , Arm Compute und Storage an. Darüber hinaus erhalten Sie 300 US-Dollar an kostenlosen Credits, um zusätzliche Cloud-Services zu testen. Informieren Sie sich über die Einzelheiten und melden Sie sich noch heute für Ihr kostenloses Konto an.
-
Was ist im kostenlosen Oracle Cloud-Kontingent enthalten?
- 2 Autonomous AI Database-Instanzen mit jeweils 20 GB
- AMD und Arm Compute-VMs
- Insgesamt 200 GB Blockspeicher
- 10 GB Objektspeicher
- 10 TB ausgehende Datenübertragung pro Monat
- Mehr als 10 permanent kostenlose Services
- Kostenlose Credits im Wert von 300 US-Dollar, 30 Tage lang noch mehr
Mit schrittweiser Anleitung lernen
Erleben Sie eine breite Palette von OCI-Services in Tutorials und praktischen Übungen. Unabhängig davon, ob Sie ein Entwickler, Administrator oder Analyst sind, können wir Ihnen zeigen, wie OCI funktioniert. Viele Übungen werden auf dem Free Tier von Oracle Cloud oder einer von Oracle bereitgestellten freien Laborumgebung ausgeführt.
-
Erste Schritte mit zentralen OCI-Services
Die Übungen in diesem Workshop umfassen eine Einführung in zentrale Oracle Cloud Infrastructure-(OCI-)Services wie virtuelle Cloud-Netzwerke (VCN) sowie Compute- und Speicherservices.
Übungen zu den zentralen OCI-Services jetzt starten -
Autonomous AI Database – Schnellstart
In diesem Workshop vermitteln wir Ihnen die ersten Schritte, um Oracle Autonomous AI Database zu nutzen.
Jetzt mit der Übung für den Schnelleinstieg in Autonomous AI Database beginnen -
App aus einer Kalkulationstabelle erstellen
In dieser Übung laden Sie eine Tabelle in eine Oracle Database-Tabelle hoch und erstellen anschließend eine Anwendung auf Basis dieser neuen Tabelle.
Diese Übung jetzt starten
Entdecken Sie mehr als 150 Best Practice-Designs
Erfahren Sie, wie unsere Architekten und anderen Kunden eine Vielzahl von Workloads bereitstellen, von Unternehmensanwendungen bis hin zu HPC, von Microservices bis hin zu Data Lakes. Informieren Sie sich über Best Practice, hören Sie von anderen Kundenarchitekten in unserer Reihe „Built & Deploy“, und stellen Sie außerdem viele Workloads mit unserer Funktion „Click-to-Deployment“ oder selbst aus unserem GitHub-Repository bereit.
Beliebte Architekturen
- Apache Tomcat mit MySQL Database Service
- Oracle Weblogic auf Kubernetes mit Jenkins
- ML- und KI-Umgebungen
- Tomcat on Arm mit Oracle Autonomous AI Database
- Loganalyse mit ELK-Stack
- HPC mit OpenFOAM
Erfahren Sie, wie viel Sie bei OCI sparen können
Die Tarife für Oracle Cloud sind unkompliziert, mit weltweit konsequent niedrigen Tarifen und zahlreichen unterstützten Anwendungsfällen. Um den für Sie zutreffenden, niedrigen Tarif zu berechnen, gehen Sie zum Kostenrechner und konfigurieren Sie die Services entsprechend Ihrer Anforderungen.
Den Unterschied entdecken:
- 1/4 der Kosten für ausgehende Bandbreite
- 3-mal besseres Preis-Leistungs-Verhältnis
- Gleicher niedriger Preis in jeder Region
- Niedrige Tarife ohne langfristige Verpflichtungen
Vertrieb kontaktieren
Möchten Sie mehr über die Oracle Cloud Infrastructure erfahren? Einer unserer Experten wird Ihnen gerne helfen.
-
Sie können Fragen beantworten wie:
- Welche Workloads werden am besten auf OCI ausgeführt?
- Wie kann ich meine gesamten Oracle Investitionen optimal nutzen?
- Wie schlägt sich OCI verglichen mit anderen Cloud-Computing-Anbietern?
- Wie kann OCI Ihre IaaS- und PaaS-Ziele unterstützen?