Oracle Machine Learning for R
Oracle Machine Learning for R (OML4R) makes the open source R statistical programming language and environment ready for the enterprise and big data. Designed for problems involving both large and small volumes of data, OML4R integrates R with Oracle Database.
Machine Learning for R
Data scientists and broader R users can take advantage of the R ecosystem on data managed by Oracle Database. R provides a suite of software packages for data manipulation, graphics, statistical functions, and machine learning algorithms. Oracle Machine Learning for R extends R’s capabilities through three primary areas: transparent access and manipulation of database data from R, in-database machine learning algorithms, ease of deployment using embedded R execution.
Oracle Machine Learning also supports a "drag and drop" graphical user interface, Oracle Data Miner, that is integrated with Oracle SQL Developer and is capable of executing user-defined R functions as part of user-created analytics workflows.
Product Details
Open all Close allFeatures Overview
- Rapidly develop and deploy R scripts that work directly on database data
- Use scalable in-database machine learning algorithms, data preparation, data exploration, and statistical analysis from a natural R API
- Execute user-defined R functions in data- and task-parallel manner using database managed R engines from R and SQL APIs
- Use in-database R script repository and R object Datastore with user access privileges
- Include R-based results through Oracle Analytics Cloud, Oracle Data Visualization Desktop, and Oracle Business Intelligence dashboards
Business Benefits
- Use Oracle Database as a high performance compute environment through an R interface
- Draw upon scalable in-database machine learning algorithms and statistical functions
- Operationalize R scripts in production applications and eliminate porting R code or reinventing deployment infrastructure
- Minimize data movement
- Use R packages contributed by the R community
- Automatically leverage existing database backup and recovery mechanisms and procedures
- Reach data from the Data Lake through Oracle Big Data SQL
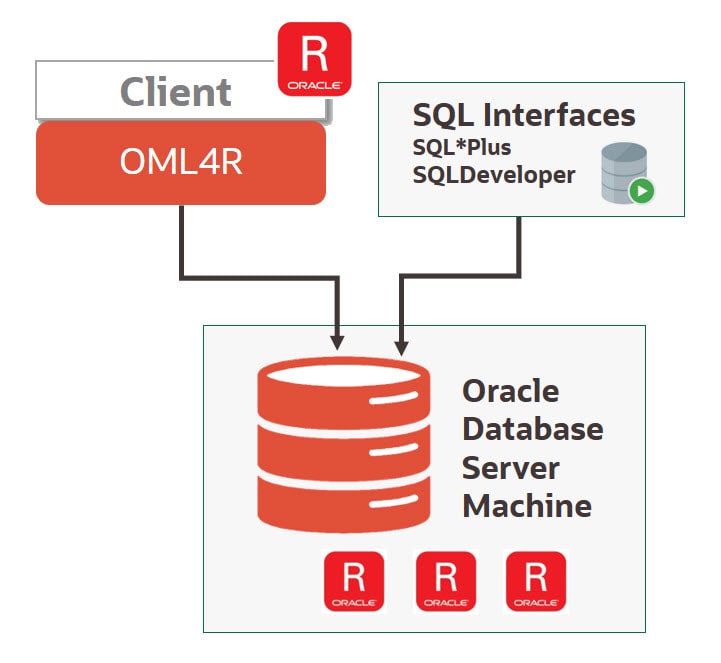
Core Features
Transparency layer - Leverage R data.frame proxy objects so data remains as database tables and views. Overloaded R functions translate select R functionality to equivalent SQL for in-database processing, parallelism, scalability and security. Data scientists can use familiar R syntax to manipulate database data that remains in the database. Leverage the package OREdplyr, which provides overloaded functionality from the popular open source R dplyr package.
Machine Learning Algorithms - R users can take advantage of Oracle Machine Learning’s library of in-database, parallel algorithms using the R language. Users can specify machine learning models using the familiar R formula syntax. Algorithms support classification, regression, anomaly detection, clustering, feature extraction, time series, and association rules.
Embedded R Execution - Manage and invoke user-defined R functions in Oracle Database for data-parallel, task-parallel, and non-parallel execution, which may also use third-party R packages, e.g., from the CRAN repository. When data scientists require techniques from the R ecosystem to satisfy unique requirements, they can leverage the R ecosystem.
Additional Features
Integrated Text Mining - The in-database algorithms accept text columns from tables and views, and then automates term and theme extraction. The extracted data is combined with other predictors in building models and scoring data.
Partitioned Models - With in-database models, users can automatically create ensembles of models, where each component model is built on a user-specified partition of the data. Scoring is enabled and simplified using a single integrated model.
Documentation
Release 1.5.1
Tutorials
- Introduction to Oracle's R Technologies (PDF)
- Transparency Layer (PDF)
- OREdplyr Package (PDF)
- Embedded R Execution - R API (PDF)
- Embedded R Execution - SQL API (PDF)
- Machine Learning Algorithms (PDF)
- Statistics Engine (PDF)