Drive manufacturing operational efficiency and performance

Improve output, quality, and sustainability with advanced analytics
For the manufacturing industry, using data to improve operational efficiency and performance is particularly relevant as the use case can be applied to any kind of manufacturing production system, including computerized numerical control infrastructure, supply chain and warehouse systems, logistics and test systems, and so on.
While manufacturers have traditionally focused on historical descriptive and diagnostic metrics, they’re now starting to use advanced analytics, machine learning, and data science to measure performance improvements and develop proactive, predictive, and prescriptive recommendations.
This use case is focused on the data platform architecture required to ingest, store, manage, and gain insights from data produced by manufacturing execution systems (MESs), warehouse management systems (WHMSs), computerized maintenance management systems (CMMSs), and maintenance systems to measure the operational efficiency of equipment, lines, and plants as well as performance metrics.
By ingesting, curating, and analyzing data on production processes and performance, manufacturers can identify and eliminate bottlenecks and inefficiencies to optimize production schedules and increase output. Applying the same approach to data on product quality, manufacturers can identify patterns and the root causes of defects, helping them implement more-effective quality control measures. Additionally, by including data on energy consumption, manufacturers can identify areas where they can drive energy efficiency to reduce costs and improve sustainability.
Optimize predictive maintenance and lower costs with a comprehensive data platform
The architecture presented here demonstrates how we can combine recommended Oracle components to build an analytics architecture that covers the entire data analytics lifecycle, from discovery through to action and measurement, and delivers the wide range of business benefits described above.
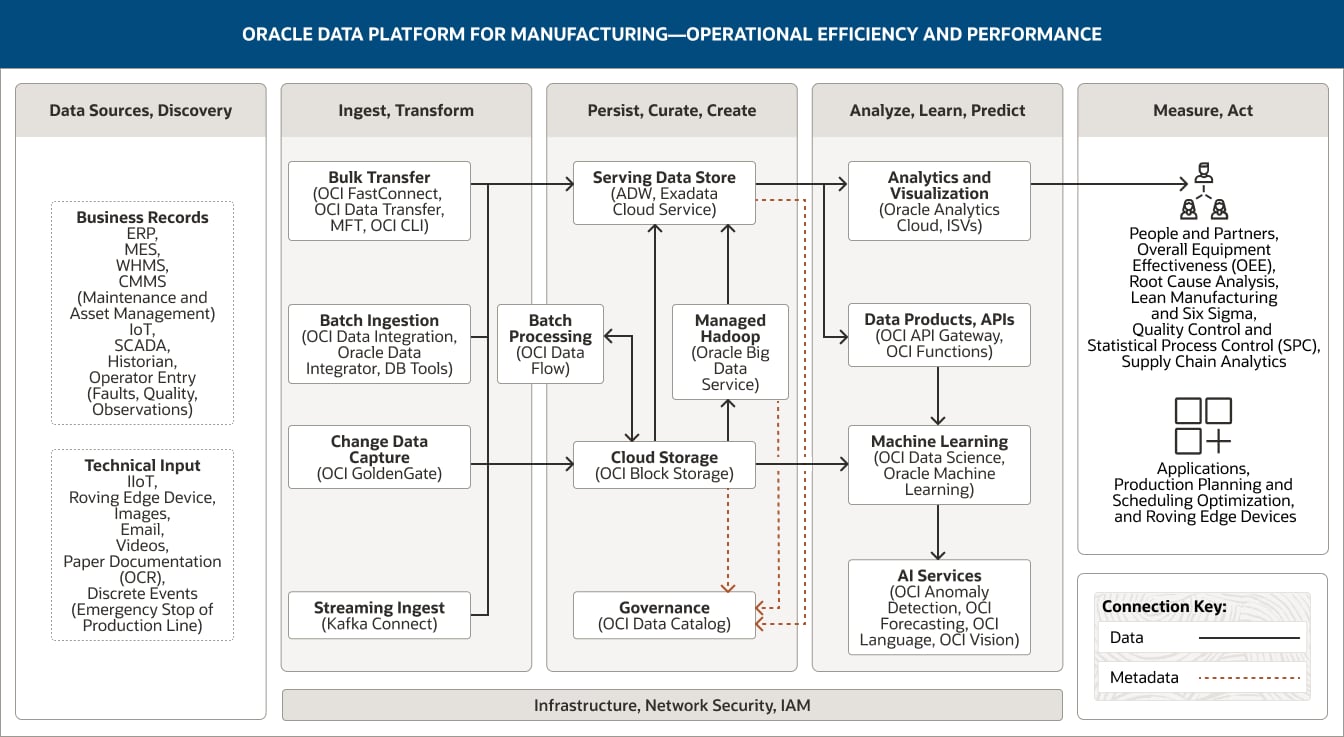
This image shows how Oracle Data Platform for manufacturing can be used to support operational efficiency and performance. The platform includes the following five pillars:
- 1. Data Sources, Discovery
- 2. Ingest, Transform
- 3. Persist, Curate, Create
- 4. Analyze, Learn, Predict
- 5. Measure, Act
The Data Sources, Discovery pillar includes three categories of data.
- 1. Oracle App’s data comprises data from Fusion SaaS, Oracle E-Business Suite, CX
- 2. Business Records (1st Party Data) CRM, Transactions, Account Information, Revenue, and Margin
- 3. 3rd Party Data comprises Forex Rates, Market Feeds, and Commodity Prices
The Ingest, Transform pillar comprises four capabilities.
- 1. Batch ingestion uses OCI Data Integration, Oracle Data Integrator, and DB tools.
- 2. Bulk transfer uses OCI FastConnect, OCI Data Transfer, MFT, and OCI CLI.
- 3. Change data capture uses OCI GoldenGate.
- 4. Streaming ingest uses OCI Streaming Kafka Connect.
All four capabilities connect unidirectionally into the serving data store and cloud storage within the Persist, Curate, Create pillar.
Additionally, streaming ingest is connected to stream processing within the Analyze, Learn, Predict pillar.
The Persist, Curate, Create pillar comprises five capabilities.
- 1. The serving data store uses Oracle Autonomous Data Warehouse and Exadata Cloud Service.
- 2. Cloud storage uses OCI Object Storage.
- 3. Managed Hadoop uses Oracle Big Data Service
- 4. Batch processing uses OCI Data Flow.
- 5. Governance uses OCI Data Catalog.
These capabilities are connected within the pillar. Cloud storage is unidirectionally connected to the serving data store; it is also bidirectionally connected to batch processing.
Two capabilities connect into the Analyze, Learn, Predict pillar. The serving data store connects to both the analytics and visualization capability and also to the data products, APIs capability. Cloud storage connects to the machine learning capability.
The Analyze, Learn, Predict pillar comprises two capabilities.
- 1. Analytics and visualization uses Oracle Analytics Cloud, GraphStudio, and ISVs.
- 2. Machine learning uses Oracle Machine Learning.
The Measure, Act pillar captures how the data analysis may be used: by people and partners.
Peoples and Partners comprises Operational Efficiency (Processing times, Error rates, Resource utilization), Process Bottleneck Identification, Customer Lifetime Value, Market and Competitive Analysis, Performance Attribution.
The three central pillars—Ingest, Transform; Persist, Curate, Create; and Analyze, Learn, Predict—are supported by infrastructure, network, security, and IAM.
Connect, ingest, and transform data
Our solution is composed of three pillars, each supporting specific data platform capabilities. The first pillar provides the capability to connect, ingest, and transform data.
There are four main ways to inject data into an architecture to enable manufacturing organizations to enhance operational efficiency and performance.
- To start our process, we’ll enable the bulk transfer of operational transaction data. Bulk transfer services are used in situations where large volumes of data need to be moved to Oracle Cloud Infrastructure (OCI) for the first time—for example, data from existing on-premises analytic repositories or other cloud sources. The specific bulk transfer service we’ll use will depend on the location of the data and the transfer frequency. For example, we may use OCI Data Transfer service or OCI Data Transfer Appliance to load a large volume of on-premises data from historical planning or data warehouse repositories. When large volumes of data must be moved on an ongoing basis, we recommend using OCI FastConnect, which provides a high-bandwidth, dedicated private network connection between a customer’s data center and OCI.
- Frequent real-time or near real-time extracts are commonly required, and data is regularly ingested from warehouse management, scheduling, and order management systems using OCI GoldenGate. OCI GoldenGate uses change data capture to detect change events in the underlying structure of the systems that need to be serviced (for example, the addition of a new component, completed maintenance operations, changes in weather, and so on) and sends the data in real time to a persistence layer and/or the streaming layer.
- For manufacturing companies, analyzing data in real time from multiple sources can help provide valuable insights into their operational efficiency and overall performance. In this use case, we use streaming ingest to ingest all the data read from sensors through IoT, machine-to-machine communications, and other means. The ability to capture and analyze data streams in real time is critical to a manufacturer’s ability to perform predictive asset maintenance. Streams can originate from several ISA-95 Level 2 systems, such as supervisory control and data acquisition (SCADA) systems, programmable logic controls, and batch automation systems. Data (events) will be ingested and some basic transformations/aggregations will occur before it is stored in OCI Object Storage. Additional streaming analytics can be used to identify correlating events and any identified patterns can be fed back (manually) for an examination of the raw data using OCI Data Science.
- To analyze this high-frequency streaming data in real time, we’ll use streaming processing to deliver advanced analytics. While traditional analytics tools extract information from data at rest, streaming analytics assesses the value of data in motion, i.e., in real time. And that’s not the only benefit. Because streaming analytics can be highly automated, it can help manufacturers reduce operating costs. For example, streaming analytics can provide real-time data on basic utility costs, such as electricity and water. Factories and plants can then use an automated streaming analytics tool to access instant insights regarding areas that could be optimized to reduce energy costs and respond appropriately to certain operational events using artificial intelligence. Streaming analytics can also make real-time predictions about upcoming equipment maintenance requirements, helping companies prepare well in advance for any upcoming repairs or routine upkeep.
- While real-time needs are evolving, the most common extract from ERP, planning, warehouse management, and transportation management systems is some kind of batch ingestion using an ETL process. Batch ingestion is used to import data from systems that can’t support data streaming (for example, older SCADA or maintenance management systems). These extracts can be ingested frequently, as often as every 10 or 15 minutes, but they are still batch in nature as groups of transactions are extracted and processed rather than individual transactions. OCI offers different services to handle batch ingestion, such as the native OCI Data Integration service and Oracle Data Integrator running on an OCI Compute instance. The choice of service would primarily be based on customer preference rather than technical requirements.
Persist, process, and curate data
Data persistence and processing is built on three (optionally four) components. Some customers will use all of them, others a subset. Depending on the volumes and data types, data could be loaded into object storage or loaded directly into a structured relational database for persistent storage. When we anticipate applying data science capabilities, then data retrieved from data sources in its raw form (as an unprocessed native file or extract) is more typically captured and loaded from transactional systems into cloud storage.
- Cloud storage is the most common data persistence layer for our data platform. It can be used for both structured and unstructured data. OCI Object Storage, OCI Data Flow, and Oracle Autonomous Data Warehouse are the basic building blocks. Data retrieved from data sources in its raw format is captured and loaded into OCI Object Storage. OCI Object Storage is the primary data persistence tier, and Spark in OCI Data Flow is the primary batch processing engine. Batch processing involves several activities, including basic noise treatment, missing data management, and filtering based on defined outbound datasets. Results are written back to various layers of object storage or to a persistent relational repository based on the processing needed and the data types used.
- Using Oracle Big Data Service for Hadoop (managed Hadoop) is an alternative to the OCI Object Storage and OCI Data Flow configuration. The two configurations can also potentially be used in conjunction depending on the customer and whether they have an existing investment in the Hadoop ecosystem, either from a product or skill perspective. Customers who are already using object storage under Hadoop (rather than the Hadoop Distributed File System) can transition this configuration to Oracle Big Data Service. Other components in the Hadoop environment, such as Hive, can also come into play and drive the use of Big Data Service depending on what visualization and data science tools the customer uses or intends to use. While this architecture outlines all the Oracle-provided services, customers may choose to continue to use some of their existing components, especially visualization and data science tools they already have in place.
- We’ll now use a serving data store to persist our curated data in an optimized form for query performance. The serving data store provides a persistent relational tier used to serve high-quality curated data directly to end users via SQL-based tools. In this solution, Oracle Autonomous Data Warehouse is instantiated as the serving data store for the enterprise data warehouse and, if required, more-specialized domain-level data marts. It can also be the data source for data science projects or the repository required for Oracle Machine Learning. The serving data store may take one of several forms, including Oracle MySQL HeatWave, Oracle Database Exadata Cloud Service, or Oracle Exadata Cloud@Customer.
Analyze data, predict, and act
The ability to analyze, predict, and act is facilitated by three technology approaches.
- Advanced analytics capabilities are critical for maintenance and performance optimization. In this use case, we rely on Oracle Analytics Cloud to deliver analytics and visualizations. This enables the organization to use descriptive analytics (describes current trends with histograms and charts), predictive analytics (predicts future events, identifies trends, and determines the probability of uncertain outcomes), and prescriptive analytics (proposes suitable actions to support optimal decision-making).
- In addition to advanced analytics, increasingly data science, machine learning, and artificial intelligence are used to look for anomalies, predict where breakdowns might occur, and optimize the sourcing process. OCI Data Science, OCI AI Services, or Oracle Machine Learning can be used in the databases. We use machine learning and data science methods to build and train our predictive maintenance models. These machine learning models can then be deployed for scoring via APIs or embedded as part of the OCI GoldenGate stream analytics pipeline. In some cases, these models can even be deployed in the database using the Oracle Machine Learning Services REST API (to do this, the model needs to be in Open Neural Network Exchange format). Additionally, OCI Data Science for Jupyter/Python-centric notebooks or Oracle Machine Learning for the Zeppelin notebook and machine learning algorithms can be deployed within the serving or transactional data store. Similarly, Oracle Machine Learning and OCI Data Science, either alone or in combination, can develop recommendation/decision models. These models can be deployed as a service, and we can deploy them behind OCI API Gateway to be delivered as “data products” and services. Finally, once built, the machine learning models can be deployed into applications that are part of a distributed control system (if permitted) or deployed at the edge via an Oracle Roving Edge Device or similar.
The multiple models created by combining data science with the patterns identified by machine learning can be applied to response and decisioning systems delivered by AI services.
- OCI Anomaly Detection can help monitor supply chain performance metrics (for example, raw material inventory, production throughput, work in progress, transit times, inventory turnover, and so on) in real time to identify and address disruptions. In a complex supply chain, the severity score of identified anomalies can help prioritize observed business disruptions for action.
- OCI Forecasting can help forecast supply chain metrics, such as demand, supply, and resource capacity, so appropriate actions can be taken to prepare ahead of time.
- OCI Vision and OCI Language can help understand documents, such as outgoing product quality reports and product defect reports, to enrich supply chain data.
The final yet critical component is data governance. This will be delivered by OCI Data Catalog, a free service providing data governance and metadata management (for both technical and business metadata) for all the data sources in the data platform ecosystem. OCI Data Catalog is also a critical component for queries from Oracle Autonomous Data Warehouse to OCI Object Storage as it provides a way to quickly locate data regardless of its storage method. This allows end users, developers, and data scientists to use a common access language (SQL) across all the persisted data stores in the architecture.
The benefits of using data to enhance operational efficiency and performance
As the speed of business—and the level of competition—increases, legacy systems used to deliver critical operating data can’t keep up. These systems need a lot of manual intervention to collate, integrate, and create reports from fragmented and siloed data, and that means the information arrives too late to give the business the advantage it needs.
Making the best use of your production resources is critically important to optimizing your manufacturing operations. Every minute spent producing the wrong products or producing the right products inefficiently not only increases costs and waste but also keeps you from delivering what your customers need. Optimizing operations and improving performance can bring numerous benefits for manufacturers, including the following:
- Higher efficiency, reducing production time and costs, increasing output, and improving productivity
- Fewer defects, improving product quality and increasing customer satisfaction
- The quick identification of safety risks and hazards, leading to improved safety practices and fewer workplace accidents
- Less waste, improving supply chain efficiency and optimizing inventory levels
- An improved ability to compete on price, quality, and innovation, giving companies a competitive edge in their markets
- Improved sustainability via waste reduction, boosting energy efficiency and minimizing the environmental impact of manufacturing processes
Related resources
-
Use case
Use Data to Improve Workplace Health and Safety
Learn how to make manufacturing operations safer using a data platform that helps you improve health and safety with advanced analytics.
-
Use case
Get Insights About Your Manufacturing Plant Faster with Edge Computing
Learn how to consolidate plant data more efficiently and get insights faster with Oracle Data Platform for manufacturing.
-
Use case
Use Your Data to Move from Reactive to Predictive Maintenance
Learn how to optimize assets with a data platform that enables predictive maintenance with machine learning.
Get started
Try 20+ Always Free cloud services, with a 30-day trial for even more
Oracle offers a Free Tier with no time limits on more than 20 services such as Autonomous AI Database, Arm Compute, and Storage, as well as US$300 in free credits to try additional cloud services. Get the details and sign up for your free account today.
-
What’s included with Oracle Cloud Free Tier?
- Two Autonomous AI Database instances, 20 GB each
- AMD and Arm Compute VMs
- 200 GB total block storage
- 10 GB object storage
- 10 TB outbound data transfer per month
- 10+ more Always Free services
- US$300 in free credits for 30 days for even more
Learn with step-by-step guidance
Experience a wide range of OCI services through tutorials and hands-on labs. Whether you're a developer, admin, or analyst, we can help you see how OCI works. Many labs run on the Oracle Cloud Free Tier or an Oracle-provided free lab environment.
-
Get started with OCI core services
The labs in this workshop cover an introduction to Oracle Cloud Infrastructure (OCI) core services including virtual cloud networks (VCN) and compute and storage services.
Start OCI core services lab now -
Autonomous AI Database quick start
In this workshop, you’ll go through the steps to get started using Oracle Autonomous AI Database.
Start Autonomous AI Database quick start lab now -
Build an app from a spreadsheet
This lab walks you through uploading a spreadsheet into an Oracle Database table, and then creating an application based on this new table.
Start this lab now
Explore over 150 best practice designs
See how our architects and other customers deploy a wide range of workloads, from enterprise apps to HPC, from microservices to data lakes. Understand the best practices, hear from other customer architects in our Built & Deployed series, and even deploy many workloads with our "click to deploy" capability or do it yourself from our GitHub repo.
Popular architectures
- Apache Tomcat with MySQL Database Service
- Oracle Weblogic on Kubernetes with Jenkins
- Machine-learning (ML) and AI environments
- Tomcat on Arm with Oracle Autonomous AI Database
- Log analysis with ELK Stack
- HPC with OpenFOAM
See how much you can save on OCI
Oracle Cloud pricing is simple, with consistent low pricing worldwide, supporting a wide range of use cases. To estimate your low rate, check out the cost estimator and configure the services to suit your needs.
Experience the difference:
- 1/4 the outbound bandwidth costs
- 3X the compute price-performance
- Same low price in every region
- Low pricing without long-term commitments
Contact sales
Interested in learning more about Oracle Cloud Infrastructure? Let one of our experts help.
-
They can answer questions like:
- What workloads run best on OCI?
- How do I get the most out of my overall Oracle investments?
- How does OCI compare to other cloud computing providers?
- How can OCI support your IaaS and PaaS goals?