Data Mesh aziendale
Soluzioni, casi d'uso e casi di studio
Che cos'è un data mesh?
Il data mesh, un tema che sta generando molto interesse nel settore dei software aziendali, è un nuovo approccio nel concepire i dati, che si basa su un'architettura distribuita per la gestione dei dati. L'idea è di rendere i dati più accessibili e disponibili per gli utenti business connettendo direttamente proprietari, produttori e consumatori di dati. Il data mesh mira a migliorare i risultati delle soluzioni incentrate sui dati e a promuovere l'adozione di moderne architetture dati.
Da un punto di vista aziendale, il data mesh introduce nuove idee sulla "concezione dei dati come prodotto". In altre parole, i dati vengono concepiti come un prodotto che soddisfa un "lavoro da fare", ad esempio migliorare il processo decisionale, aiutare a rilevare frodi o avvisare l'azienda di cambiamenti nelle condizioni della supply chain. Per creare dati di alto valore, le aziende devono cambiare cultura e mentalità e impegnarsi in un approccio più interfunzionale dei modelli di business.
Da un punto di vista tecnologico, la visione di Oracle sul data mesh coinvolge tre nuove aree di interesse importanti per l'architettura basata sui dati:
- Strumenti che forniscono prodotti di dati come raccolte, eventi e analisi dei dati
- Architetture di dati distribuite e decentralizzate che aiutano le organizzazioni che decidono di passare da architetture monolitiche a strategie di multicloud e cloud ibrido o che devono operare a livello globale in modo decentrato
- Data in movimento per le organizzazioni che non dipendono esclusivamente da dati centralizzati, statici o orientati ai batch e che invece utilizzano registri di dati basati sugli eventi e pipeline incentrate sullo streaming per gli eventi di dati in tempo reale che offrono analytics più tempestivi
Altri aspetti come gli strumenti self-service per utenti non tecnici e solidi modelli di governance dei dati sono tanto importanti per l'architettura di data mesh quanto per altre metodologie di gestione dei dati più centralizzate e classiche.
Un nuovo concetto per i dati

Un approccio basato sul data mesh è un cambio di paradigma nel concepire i dati come prodotto. Il data mesh introduce cambiamenti organizzativi e di processo di cui le aziende avranno bisogno per poter gestire i dati come asset tangibile del business. La prospettiva di Oracle per l'architettura di data mesh richiede l'allineamento tra dati organizzativi e analitici.
Un data mesh mira a connettere i produttori di dati direttamente agli utenti business e, nella massima misura possibile, a rimuovere l'intermediazione dell'IT dai progetti e dai processi che incorporano, preparano e trasformano le risorse di dati.
L'attenzione di Oracle al data mesh permette di offrire ai nostri clienti una piattaforma in grado di soddisfare questi nuovi requisiti tecnologici. Sono inclusi strumenti per la produzione di dati, architetture decentralizzate basate sugli eventi e modelli di streaming per i dati. Per la creazione di modelli di dati e altre problematiche sociotecniche, Oracle si allinea al lavoro svolto dall'opinion leader in materia di data mesh, Zhamak Dehghani.
Vantaggi di un data mesh
Investire in un data mesh può offrire notevoli vantaggi, tra cui:
- Totale chiarezza nel valore dei dati grazie a best practice per l'applicazione dei dati intesa come prodotti
- Oltre il 99,999% dei dati operativi disponibili utilizza pipeline di dati basate su microservizi per il consolidamento e la migrazione dei dati.
- Cicli di innovazione 10 volte più veloci, passando da un ETL manuale orientato ai batch a una trasformazione e un caricamento continui (CTL).
- Riduzione di oltre il 70% nella progettazione dei dati, vantaggi in termini di CI/CD, strumenti per pipeline di dati senza codice e self-service e sviluppo agile.
Il data mesh non è solo un modo di pensare, ma molto di più
Il data mesh si trova ancora a un livello iniziale di maturità del mercato. Di conseguenza, può succedere spesso che diversi contenuti di marketing inerenti a presunte soluzioni di "data mesh" non soddisfino l'approccio o i principi di base.
Un vero data mesh è un modo di pensare, un modello organizzativo e un approccio all'architettura dei dati aziendali con strumenti di supporto. Una soluzione di data mesh dovrebbe avere le seguenti caratteristiche: concezione dei dati come prodotto, architettura decentralizzata, proprietà basata sul dominio, dati in distribuiti, accesso self-service e una solida gestione della governance dei dati.
Un data mesh non è nessuno dei elementi seguenti:
- Un prodotto del fornitore: non si tratta di prodotti software data mesh.
- Un data lake o un data lakehouse: sono complementari e possono far parte di un data mesh più ampio che si estende su più lake, pond e sistemi operativi di record.
- Un catalogo dati o un grafico: un data mesh richiede un'implementazione fisica.
- Un progetto di consulenza occasionale: il data mesh è un percorso, non un singolo progetto.
- Un prodotto di analytics self-service: i classici analytics self-service, la preparazione e il data wrangling possono far parte di un data mesh, così come altre architetture di dati.
- Una struttura di dati: sebbene concettualmente correlato, il concetto di struttura di dati è più ampio e comprende una vasta gamma di stili di integrazione e gestione dei dati, mentre il data mesh è più che altro associato a modelli di progettazione basati su decentralizzazione e dominio.
Perché utilizzare un data mesh?
La triste verità è che le architetture monolitiche del passato sono ingombranti, costose e poco flessibili. Nel corso degli anni, è diventato chiaro che la maggior parte del tempo e dei costi legati alle piattaforme aziendali digitali, dalle applicazioni agli analytics, viene impiegata per attività di integrazione. Di conseguenza, la maggior parte delle iniziative legate alle piattaforme non ha successo.
Sebbene il data mesh non sia una soluzione miracolosa per le architetture di dati centralizzate e monolitiche, i principi, le pratiche e le tecnologie della strategia di data mesh sono progettati per raggiungere alcuni dei più urgenti obiettivi di modernizzazione legati a iniziative di business basate sui dati.
Di seguito elenchiamo alcuni dei trend tecnologici che hanno portato alla diffusione dei data mesh:
- Il 70-80% delle trasformazioni digitali non ha successo
- I costi legati all'indisponibilità dei dati operativi sono in aumento
- Il lock-in cloud è reale e può diventare ancora più costoso
- I data lake raramente hanno successo e si concentrano solo sugli analytics
- L'ascesa dei dati distribuiti sta portando a un'architettura più efficace, efficiente ed economica
- I silos organizzativi aggravano i problemi legati alla condivisione dei dati
- I dati determinano un vantaggio competitivo, quindi è fondamentale gestirli al meglio
Per saperne di più su tutti i vantaggi del data mesh, leggi il report di Zhamak Dehghani del 2019: Come andare oltre un data lake monolitico e adottare un data mesh distribuito.
Definizione di data mesh
La strategia decentralizzata dietro al data mesh mira a trattare i dati come un prodotto creando un'infrastruttura di dati self-service per rendereli più accessibili agli utenti business.
Orientamento ai risultati
Concezione dei dati come prodotto- Cambio di mentalità e adozione del punto di vista del utilizzatore di dati
- I proprietari dei domini sono responsabili dei KPI/SLA dei prodotti di dati
- Semantica legata alla rete di tecnologia e di dominio uguale per tutti
- I dati non passeranno più di mano in mano
- Acquisisci dati in tempo reale direttamente dai record e consenti alle pipeline self-service di fornire i dati quando necessario
- Una funzionalità essenziale per abilitare i dati decentralizzati e i dati allineati
Rifiuto dell'architettura IT monolitica
Architettura decentralizzata- Un'architettura progettata per dati, servizi e cloud decentralizzati
- Progettato per gestire qualsiasi evento, formato e complessità
- Elaborazione dei flussi per impostazione predefinita, elaborazione batch per le eccezioni
- Progettata per supportare gli sviluppatori e connettere direttamente i consumatori con i produttori di dati
- Sicurezza, convalida, provenienza e trasparenza integrate
Le funzionalità di Oracle per adottare un data mesh
Quando si passa dalla teoria alla pratica, è necessario implementare soluzioni di tipo aziendale per i dati mission-critical e Oracle può fornire una gamma di soluzioni affidabili per potenziare un data mesh aziendale.
Crea e condividi prodotti di dati
- Raccolte di dati multi-modello con il database convergente Oracle, che consentono lo "shape shifting" dei prodotti di dati nei formati richiesti dagli utilizzatori di dati
- Prodotti self-service come applicazioni o API tramite Oracle APEX Application Development e Oracle REST Data Services per ottenere facilmente l'accesso e la condivisione di tutti i dati
- Singolo punto di accesso per le query SQL o la virtualizzazione dei dati con Oracle Cloud SQL e Big Data SQL
- Dati per il Machine Learning con la piattaforma di data science di Oracle, Oracle Cloud Infrastructure (OCI) Data Catalog e la piattaforma Oracle per i data lakehouse
- Dati allineati alla fonte prodotti da eventi in tempo reale, alert sui dati con Oracle Stream Analytics
- Prodotti di dati self-service allineati al consumatore in una soluzione completa Oracle Analytics Cloud
Adotta un'architettura decentratalizzata
- CI/CD agile e di tipo "service mesh" per i container di dati utilizzando i database Oracle collegabili con Kubernetes, Docker o cloud nativi con Autonomous Database
- Sincronizzazione dei dati di più aree geografiche, multicloud e su cloud ibrido con i microservizi e Veridata di Oracle GoldenGate per una struttura di transazioni attive e affidabile
- Sfrutta la maggior parte dei dati relativi ad applicazioni, processi di business e IoT (Internet of Things) con Oracle Integration Cloud e Oracle Internet of Things Cloud
- Utilizzo di Oracle GoldenGate o Oracle Transaction Manager for Microservices per le code degli eventi, il sourcing degli eventi o l'inclusione in tempo reale in Kafka e data lake
- Trasferimento di pattern decentralizzati basati su domini nel tuo service mesh con Oracle Verrazzano, Helidon e Graal VM
3 attributi chiave di un data mesh
Il data mesh non è solo una nuovo termine tecnico che va di moda. Si tratta di una nuova serie di principi, pratiche e funzionalità tecnologiche che rendono i dati più accessibili e individuabili. Il concetto di data mesh si distingue dalle precedenti generazioni di approcci e architetture di integrazione dei dati scostandosi dalle enormi architetture monolitiche dei dati aziendali del passato e promuovendo invece una moderna architettura distribuita, decentralizzata e basata sui dati per il futuro. Il concetto di data mesh comprende fondamentalmente i seguenti attributi chiave:
1. Concezione dei dati come prodotto
Un cambio di mentalità è il primo e più importante passo verso un data mesh. La disponibilità ad adottare le pratiche di innovazione apprese è il trampolino di lancio verso una corretta modernizzazione dell'architettura dei dati.
Queste pratiche apprese includono:
- Design thinking: una metodologia comprovata per la risoluzione di "problemi inaspettati", applicata ai dati aziendali per la creazione di prodotti di eccellenti
- Teoria Jobs-to-be-done, che applica un'innovazione incentrata sui clienti e un processo di innovazione basato sui risultati per garantire che i dati aziendali risolvano reali problemi di business

Le metodologie di design thinking offrono tecniche comprovate che contribuiscono ad abbattere i silos organizzativi, i quali molto spesso ostacolano l'innovazione interfunzionale. La teoria Jobs-to-be-done è la base essenziale per la progettazione di dati che soddisfano obiettivi specifici dei consumatori finali o I lavori da svolgere e definisce lo scopo del prodotto.
Sebbene l'approccio di dati come prodotto sia stato inizialmente adottato dalla community di data science, ora viene applicato a tutti gli aspetti della gestione dei dati. Invece di creare architetture tecnologiche monolitiche, il data mesh si concentra sui consumatori di dati e sui risultati di business.
Sebbene la concezione dei dati come prodotto possa essere applicata ad altre architetture di dati, è una parte essenziale di un data mesh. Per esempi pragmatici su come concepire i dati come prodotto, il team di Intuit ha realizzato un'analisi dettagliata delle proprie esperienze.
Prodotti di dati
I prodotti di qualsiasi tipo, dalle materie prime agli articoli nel tuo negozio di fiducia, vengono realizzati come asset di valore, sono destinati ad essere consumati e hanno una funzione specifica da svolgere. A seconda del dominio di business o del problema da risolvere, i dati possono assumere varie forme e includere:
- Analytics: report e dashboard cronologici/in tempo reale
- Set di dati: raccolte di dati in forme/formati diversi
- Modelli: oggetti dominio, modelli di dati, funzioni di machine learning (ML)
- Algoritmi: modelli ML, punteggio, regole di business
- Servizi di dati e API: documenti, payload, argomenti, API REST e molto altro
Un dato viene creato per essere consumato, è in genere gestito al di fuori dell'IT e richiede il tracciamento di attributi aggiuntivi, come:
- Mappatura degli stakeholder: chi è il proprietario, crea e utilizza questo prodotto?
- Confezionamento e documentazione: come viene utilizzato? Come viene etichettato?
- Scopo e valore: qual è il valore implicito/esplicito del prodotto? Può deprezzarsi nel tempo?
- Qualità e coerenza: quali sono i KPI e gli SLA di utilizzo? Sono verificabili?
- Provenienza, ciclo di vita e governance: i dati sono affidabili e spiegabili?
2. Architettura dei dati decentralizzata

I sistemi IT decentralizzati sono un dato di fatto nella realtà moderna e con l'avvento delle applicazioni SaaS e dell'infrastruttura di cloud pubblico (IaaS), il decentramento di dati e applicazioni è ormai indispensabile. Le architetture software delle applicazioni stanno passando dai monoliti centralizzati del passato ai microservizi distribuiti (un service mesh). L'architettura dei dati seguirà lo stesso trend verso il decentramento, con dati che diventano più distribuiti su una più ampia varietà di siti fisici e su molte reti. È il cosiddetto data mesh.
Che cos'è un mesh?
Un mesh è una topologia di rete che consente a un grande gruppo di nodi non gerarchici di funzionare insieme in modo collaborativo.
Ecco alcuni esempi comuni di tecnologia:
- WiFiMesh: molti nodi che funzionano insieme per una copertura migliore
- ZWave/Zigbee: reti di dispositivi smart home a basso consumo energetico
- 5G mesh: connessioni cellulari più affidabili e resilienti
- Starlink: rete a banda larga satellitare su scala globale
- Service mesh: un modo per fornire controlli unificati sui microservizi decentralizzati (software applicativo)
Il data mesh è allineato a questi concetti di rete e fornisce un metodo decentralizzato di distribuire i dati su reti virtuali/fisiche e su grandi distanze. Le architetture monolitiche legacy di integrazione dei dati, come ETL e gli strumenti di federazione dei dati, e più recentemente i servizi di cloud pubblico, come AWS Glue, richiedono un'infrastruttura altamente centralizzata.
Una soluzione di data mesh completa dovrebbe essere in grado di funzionare in un framework multicloud e di spaziare potenzialmente tra sistemi on-premise e più cloud pubblici, fino alle reti edge.
Sicurezza distribuita
In un mondo in cui i dati sono altamente distribuiti e decentralizzati, il ruolo della sicurezza delle informazioni è fondamentale. A differenza dei monoliti altamente centralizzati, i sistemi distribuiti devono delegare le attività necessarie per autenticare e autorizzare vari utenti a diversi livelli di accesso. Individuare reti affidabili e sicure non è un compito facile.
Di seguito riportiamo alcune considerazioni:
- Crittografia dei dati in archivio: dati/eventi scritti nello storage
- Autenticazione distribuita: per servizi e data store, ad esempio mTLS, certificati, SSO, aree di memorizzazione segrete e data vault
- Crittografia in movimento: dati/eventi che transitano nella memoria
- Identity Management: servizi di tipo LDAP/IAM tra più piattaforme
- Autorizzazioni distribuite: per consentire agli endpoint del servizio di redigere i dati
Ad esempio: sidecar Open Policy Agent (OPA) per inserire il Policy Decision Point (PDP) nel cluster container/K8S in cui viene elaborato l'endpoint del microservizio. LDAP/IAM può essere un qualsiasi servizio compatibile con JWT. - Mascheramento deterministico per offuscare in modo affidabile e coerente i dati PII
La sicurezza all'interno di qualsiasi sistema IT può essere una questione complessa e cosa ancora più ardua è garantire un elevato livello di sicurezza all'interno dei sistemi distribuiti. Tuttavia, si tratta di problemi risolvibili.
Domini di dati decentralizzati
Un principio fondamentale del data mesh è la nozione di distribuzione della proprietà e della responsabilità. La procedura ottimale consiste nell'associare la proprietà dei prodotti e dei domini di dati ai membri di un'organizzazione che si occupano più da vicino dei dati. In pratica, questo metodo può determinare un allineamento ai dati di origine (ad esempio, origini di dati non elaborati, come sistemi operativi di record/applicazioni) o ai dati analitici (ad esempio, dati generalmente compositi o aggregati, formattati per un facile utilizzo da parte dei consumatori di dati). In entrambi i casi, i produttori e consumatori di dati sono spesso allineati alle business unit anziché alle organizzazioni IT.
I vecchi metodi di organizzazione dei gruppi di dati cadono spesso nella trappola dell'allineamento con le soluzioni tecnologiche, come strumenti ETL, data warehouse, data lake, o con l'organizzazione strutturale di un'azienda (risorse umane, marketing e altri settori di attività). Tuttavia, per un dato problema di business, i gruppi di dati sono spesso più allineati all'ambito del problema che viene risolto, al contesto di un determinato processo di business o alla famiglia di applicazioni in un'area specifica del problema. Nelle grandi organizzazioni, questi gruppi di dati vanno generalmente al di là di strutture interne e funzioni tecnologiche.
La decomposizione funzionale dei gruppi di dati ha la priorità assoluta nel data mesh. Per realizzare la modellazione del dominio è possibile applicare varie metodologie di decomposizione dei dati all'architettura di data mesh, tra cui la modellazione classica di data warehouse (come Kimball e Inmon) o la modellazione di data vault, ma la metodologia più comune attualmente utilizzata nell'architettura di data mesh è la progettazione basata sul dominio (DDD). L'approccio DDD derivante dalla decomposizione funzionale dei microservizi è ora utilizzato in un contesto di data mesh.
3. Dati dinamici in movimento
Come contributo alle discussioni sull'argomento, Oracle ha sottolineato l'importanza dei dati mutevoli come fattore chiave di un moderno data mesh. I dati mutevoli sono assolutamente essenziali per estrarre i data mesh dal mondo legacy dell'elaborazione batch monolitica e centralizzata. Le funzionalità dei dati mutevoli rispondono a diverse domande chiave sul data mesh, tra cui:
- Come posso accedere ai dati allineati alla fonte in tempo reale?
- Quali strumenti possono distribuire affidabili transazionidi dati affidabili su un data mesh fisicamente decentralizzato?
- Che cosa posso utilizzare per rendere disponibili i dati sotto forma di API?
- Per i prodotti di dati analitici che necessitano di continui aggiornamenti, come potrei allinearmi ai set di dati e garantire fiducia e validità?
Queste domande non sono solo una questione di "dettagli di implementazione", ma hanno un ruolo fondamentale per l'architettura dei dati stessa. Un progetto basato sul dominio per i dati statici utilizzerà tecniche e strumenti diversi rispetto a un processo dinamico con dati dinamici dello stesso progetto. Ad esempio, nelle architetture i dinamiche, il registro dei dati è la fonte di informazioni principale.
Registro di dati basati sugli eventi

I registri sono una componente fondamentale per la creazione di una architettura dei dati distribuita. Come succede con un registro contabile, un registro di dati memorizza le transazioni quando si verificano.
Durante la distribuzione del registro, I dati diventano "ripetibili" in qualsiasi posizione. Alcuni registri sono un po' come la scatola nera di un aereo utilizzata per le funzioni ad alta disponibilità e il disaster recovery.
A differenza dei data store centralizzati e monolitici, i registri distribuiti sono creati appositamente per tenere traccia di eventi atomici e/o transazioni che si verificano in altri sistemi (esterni).
Un mesh dati non è solo un singolo tipo di registro. A seconda dei casi d'uso e dei requisiti, un data mesh può utilizzare diversi tipi di registri basati sugli eventi, tra cui:
- Registro di eventi per uso generico, come Kafka o Pulsar
- Registro di dati: CDC/strumenti di replica distribuiti
- Middleware per la messaggistica, inclusi ESB, MQ, JMS e AQ
- Registro della blockchain per transazioni sicure, immutabili e con più parti
Insieme, questi registri possono essere utilizzati come una sorta di registro di eventi permanente per l'intera azienda, fornendo un elenco aggiornato degli eventi che si verificano nei sistemi di record e di analytics.
Flussi di dati diversificati

I flussi di dati diversificati sono sempre più diffusi. Possono variare in base ai tipi di evento, ai payload e alla semantica delle transazioni. Un data mesh dovrebbe supportare i tipi di flusso necessari per una vasta gamma di carichi di lavoro di dati aziendali.
Eventi semplici:
- Base64/JSON: eventi raw e senza schema
- telemetria raw: eventi isolati
Eventi di log dell'applicazione di base/Internet of Things (IoT):
- JSON/Protobuf: potrebbero avere uno schema
- MQTT: protocolli specifici per IoT
Eventi del processo aziendale dell'applicazione:
- Eventi SOAP/REST: XML/XSD, JSON
- B2B: protocolli e standard di scambio
Eventi/transazioni dati:
- Record delle modifiche logici: LCR, SCN, URID
- Limiti coerenti: commit rispetto alle operations
Elaborazione del flusso dati
Per l'elaborazione dei flussi si intende la modifica dei dati in un flusso di eventi. A differenza di "funzioni lambda", il processore di flusso mantiene lo stato di dati all'interno di una particolare finestra temporale e può applicare query analitiche molto più avanzate sui dati.
- Soglie, alert e monitoraggio della telemetria
- Funzioni RegEx, matematica/logica e concatenazione
- Registrazione per record, sostituire e nascondere
Filtro dati di base:
ETL semplice:
CEP e ETL complesso:
- Elaborazione di eventi complessi (CEP)
- Elaborazione DML (ACID) e gruppi di tuple
- Aggregazioni, ricerche, join complessi
Stream analytics:
- Analisi delle serie temporali e finestre temporali personalizzate
- Geospaziale, Machine Learning e intelligenza artificiale integrata
Altri attributi e principi importanti
Naturalmente, un data mesh ha più di tre attributi. Ci siamo concentrati su questi tre aspetti per attirare l'attenzione sugli attributi che Oracle considera come alcuni degli aspetti nuovi e unici del moderno approccio al data mesh.
Altri importanti attributi relativi al data mesh includono:
- Strumenti self-service: il data mesh segue il trend complessivo della gestione dei dati verso il self-service e sempre più sviluppatori alle prime armi dovranno appartenere alla categoria di proprietari di dati
- Governance dei dati: il data mesh ha anche abbracciato il trend a lungo termine verso un modello di governance federato più formalizzato, sostenuto dai Chief Data Officer, dai Data Steward e dai fornitori di Data Catalog da molti anni.
- Usabilità dei dati : approfondendo i principi del data mesh, si gettano le basi per garantire che i dati siano altamente utilizzabili. I principi per i prodotti basati sui dati richiederanno dati preziosi, utilizzabili e facili da condividere.
7 casi d'uso di data mesh
Un data mesh di successo soddisfa i casi d'uso i di dati operativi e analitici. I sette casi d'uso seguenti illustrano la vasta gamma di funzionalità che un data mesh apporta ai dati aziendali.
Integrando dati operativi e analytics in tempo reale, le aziende possono prendere migliori decisioni operative e strategiche.MIT Sloan School of Management
1. Modernizzazione delle applicazioni
Guardando al di là delle migrazioni in modalità "lift and shift" delle architetture di dati monolitiche al cloud, molte organizzazioni cercano anche di dismettere le proprie applicazioni centralizzate del passato e di passare a un'architettura applicativa di microservizi più moderna.


Tuttavia, i monoliti delle applicazioni legacy dipendono in genere da database enormi, sollevando la questione di come suddividere gradualmente il piano di migrazione in modo da ridurre interruzioni, rischi e costi. Un data mesh può offrire un'importante funzionalità IT operativa per i clienti che eseguono transizioni graduali dai monoliti all'architettura mesh. Ad esempio:
- Scarcicare i sottodomini del database, ad esempio applicando il filtro dei dati per "limitato contesto"
- Replica bidirezionale delle transazioni per le migrazioni a fasi
- Sincronizzazione multi-piattaforma, ad esempio da mainframe a DBaaS
Nel gergo degli architetti di microservizi, questo approccio utilizza un transaction outbox bidirezionale per abilitare il modello di migrazione "strangler fig", un contesto delimitato alla volta.
2. Disponibilità e continuità dei dati

Le applicazioni business-critical richiedono KPI e SLA molto elevati per ottenere resilienza e continuità. Indipendentemente dal fatto che queste applicazioni siano monolitiche, microservizi o una via di mezzo, non possono subire interruzioni.
Per i sistemi mission-critical, un modello di dati distribuito con coerenza finale non è in genere accettabile. Tuttavia, queste applicazioni devono funzionare in molti data center. In fatto di business continuity, sorge spontaneo chiedersi: "Come si eseguono le applicazioni in più data center, garantendo al contempo la coerenza e correttezza dei dati?"
Indipendentemente dal fatto che le architetture monolitiche utilizzino "set di dati con partizionamento" o che i microservizi siano predisposti per l'alta disponibilità tra più siti, il data mesh offre dati corretti e ad alta velocità a qualsiasi distanza.
Un data mesh può fornire le basi per dati decentralizzati, ma corretti al 100% su tutti i siti. Ad esempio:
- Transazioni logiche a latenza molto bassa (su più piattaforme)
- Garanzie compatibili con ACID per i dati corretti
- Funzione multi-attiva, bidirezionale e risoluzione dei conflitti
3. Sourcing degli eventi e transaction outbox


Una piattaforma moderna in stile mesh dei servizi utilizza eventi per lo scambio di dati. Anziché dipendere dall'elaborazione batch nel livello di dati, i payload vengono eseguiti in modo continuo quando si verificano eventi nell'applicazione o nel data store.
Per alcune architetture, i microservizi devono scambiare i payload dei dati tra loro. Altri modelli richiedono lo scambio tra applicazioni monolitiche o data store. Sorge spontaneo chiedersi: "Come si scambiano in modo affidabile i payload dei dati dei microservizi tra le applicazioni e i data store?"
Un data mesh può fornire la tecnologia di base per lo scambio di dati incentrato sui microservizi. Ad esempio:
- Da microservizi a microservizi nel contesto
- Da microservizi a microservizi nei vari contesti
- Monolite da/verso un microservizio
I modelli di microservizi, come il sourcing di eventi, CQRS e transaction outbox, sono soluzioni in genere facili da comprendere; un data mesh fornisce gli strumenti e i framework per rendere questi pattern ripetibili e affidabili su larga scala.
4. Integrazione basata sugli eventi
Oltre ai modelli di progettazione dei microservizi, la necessità di un'integrazione aziendale si estende ad altri sistemi IT, come database, processi di business, applicazioni e dispositivi fisici di qualsiasi tipo. Un data mesh fornisce le basi per l'integrazione dei dati in movimento.
I dati in movimento sono generalmente basati sugli eventi. Un'azione dell'utente, un evento dispositivo, una fase del processo o un commit del data store possono avviare un evento con un payload di dati. Questi payload di dati sono fondamentali per l'integrazione di sistemi IoT (Internet of Things), di processi e di database aziendali, di data warehouse e di data lake.
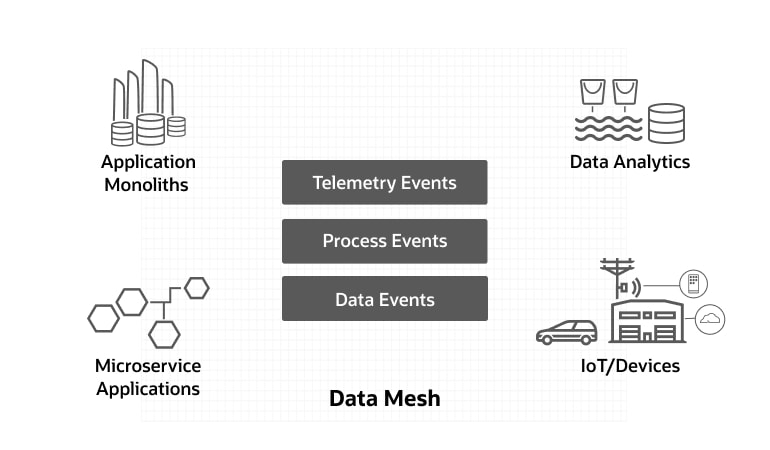
Un data mesh fornisce la tecnologia di base per un'integrazione in tempo reale in tutta l'azienda. Ad esempio:
- Connettere eventi reali dei dispositivi ai sistemi IT
- Integrare i processi di business nei sistemi ERP
- Allineare i database operativi ai data store analitici
Le grandi organizzazioni hanno naturalmente diversi sistemi vecchi e nuovi, monoliti e microservizi, data store operativi e analitici; un data mesh consente di unificare queste risorse tra domini aziendali e di dati diversi.
5. Importazione dati in streaming (per analytics)

I data store analitici possono includere data mart, data warehouse, cubi OLAP, data lake e tecnologie di data lakehouse.
In generale, ci sono solo due modi per inserire i dati in questi data store analitici:
- Caricamento batch/micro-batch su programma orario
- Importazione dati in streaming: caricamento continuo di eventi
Una data mesh fornisce le basi per la funzionalità di importazione dei dati in streaming. Ad esempio:
- Dati da database o data store
- Eventi del dispositivo dalla telemetria del dispositivo fisico
- Registrazione degli eventi dell'applicazione o transazioni di business
L'inclusione di eventi a seconda del flusso può ridurre l'impatto sui sistemi di origine, migliorare l'affidabilità dei dati (importanti per la data science) e supportare gli analytics in tempo reale.
6. Pipeline di dati in streaming

In generale, una volta incluse nei data store analitici, le pipeline devono preparare e trasformare i dati in diverse fasi o aree. I dati prodotti dagli analytics richiedono spesso questo processo di perfezionamento.
Un data mesh può fornire un livello di pipeline di dati gestito in modo indipendente che funzioni con i data store analitici, offrendo in particolare i seguenti servizi di base:
- Individuazione e preparazione dei dati self-service
- Governance delle risorse di dati nei vari domini
- Preparazione e trasformazione dei dati nei formati necessari
- Verifica dei dati a seconda dei criteri in modo da garantire la coerenza
Queste pipeline di dati devono essere in grado di funzionare su diversi data store fisici (ad esempio, mart, warehouse o lake) o come un "flusso di dati di tipo pushdown" all'interno delle piattaforme analitycs che supportano i dati in streaming, come Apache Spark e altre tecnologie di data lakehouse.
7. Streaming analytics

Gli eventi si verificano continuamente. L'analisi degli eventi in un flusso può essere fondamentale per capire cosa sta succedendo di tanto in tanto.
Questo tipo di analisi basata su serie temporali dei flussi in tempo reale può essere importante per i dati dei dispositivi IoT e per comprendere cosa accade nei data center IT o nelle transazioni finanziarie, come il monitoraggio delle frodi.
Un data mesh completo di tutte le funzionalità include le caratteristiche di base per analizzare eventi di ogni tipo, attraverso diversi tipi di finestre temporali. Ad esempio:
- Analisi semplice del flusso di eventi (eventi Web)
- Monitoraggio delle attività aziendali (eventi SOAP/REST)
- Elaborazione di eventi complessi (correlazione multi-flusso)
- Analisi degli eventi di dati (su transazioni DB/ACID)
Analogamente alle pipeline di dati, gli streaming analytics potrebbero essere eseguiti all'interno di un'infrastruttura consolidata di data lakehouse o in modo disgiunto come servizi cloud nativi.
Ottieni il massimo valore utilizzando un mesh comune per l'intera proprietà dei dati
Le aziende all'avanguardia si aspettano un'integrazione dei dati operativi e analitici in tempo reale a partire da una raccolta eterogenea di data store resilienti. L'evoluzione dell'architettura negli streaming analytics avviene parallelamente a innovazioni rapide e continue. L'alta disponibilità operativa ha portato ad analytics in tempo reale, mentre l'automazione dell'ingegneria dei dati semplifica la preparazione di quest'ultimi, consentendo a data scientist e analisti di accedere a strumenti self-service.
Riepilogo dei casi d'uso di data mesh

Crea un mesh operativo e analitico
Mettere a punto tutte queste funzionalità di gestione dei dati in un'architettura unificata avrà un impatto su tutti gli utilizzatori di dati. Una data mesh aiuterà a migliorare i sistemi globali di archiviazione per operare in tempo reale in modo affidabile, allineando i dati in tempo reale alle linee di business, ai data scientist e ai clienti. Inoltre, un data mesh semplifica la gestione dei dati per le applicazioni di microservizi di nuova generazione. Utilizzando metodi e strumenti analitici moderni, gli utenti finali, gli analisti e i data scientist reagiranno in modo ancora più tempestivo alle richieste dei clienti e alle minacce della concorrenza. Per un esempio ben documentato, leggi gli obiettivi e i risultati di Intuit.
Sfrutta i vantaggi di un data mesh in singoli progetti
Quando si adotta la mentalità e il modello operativo dei prodotti di dati, è importante sviluppare un'esperienza in ciascuna di queste tecnologie abilitanti. Nel passaggio al data mesh, puoi ottenere vantaggi incrementali trasformando la tua architettura dei dati in streaming analytics, sfruttando i tuoi investimenti operativi ad alta disponibilità in analytics in tempo reale e offrendo analytics self-service e in tempo reale per i tuoi data scientist e analisti.
Confronta e contrapponi
| Struttura di dati | Integrazione dello sviluppo di applicazioni | Data store analitico | |||||
|---|---|---|---|---|---|---|---|
| Data mesh | Integrazione dei dati | Metacatalogo | Microservizi | Messaggistica | Data lakehouse | Data warehouse distribuito | |
| Persone, processi e metodi: | |||||||
| Focus sui dati | disponibile |
disponibile |
disponibile |
1/4 offerta |
1/4 offerta |
3/4 offerta |
3/4 offerta |
| Caratteristiche tecniche dell'architettura: | |||||||
| Architettura distribuita | disponibile |
1/4 offerta |
3/4 offerta |
disponibile |
disponibile |
1/4 offerta |
3/4 offerta |
| Registri basati sugli eventi | disponibile |
non disponibile |
1/4 offerta |
disponibile |
disponibile |
1/4 offerta |
1/4 offerta |
| Supporto ACID | disponibile |
disponibile |
non disponibile |
non disponibile |
3/4 offerta |
3/4 offerta |
disponibile |
| Orientamento al flusso | disponibile |
1/4 offerta |
non disponibile |
non disponibile |
1/4 offerta |
3/4 offerta |
1/4 offerta |
| Focus sui dati analitici | disponibile |
disponibile |
disponibile |
non disponibile |
non disponibile |
disponibile |
disponibile |
| Focus sui dati operativi | disponibile |
1/4 offerta |
disponibile |
disponibile |
disponibile |
non disponibile |
non disponibile |
| Mesh fisico e logico | disponibile |
disponibile |
non disponibile |
1/4 offerta |
3/4 offerta |
3/4 offerta |
1/4 offerta |
Risultati aziendali
Vantaggi complessivi
Cicli di innovazione più veloci e basati sui dati
Costi ridotti per le operazioni di dati mission-critical
Risultati operativi
Liquidità dei dati multicloud
- Consenti ai dati di fluire liberamente
Condivisione dei dati in tempo reale
- Ops-to-Ops e Ops-to-analytics
Dati edge e basati sulla posizione
- Metti in relazione gli eventi dei dispositivi e dei dati IRL
Interscambio di dati affidabili dei microservizi
- Sourcing degli eventi con dati corretti
- DataOps e CI/CD per i dati
Continuità ininterrotta
- >99,999% di SLA di uptime
- Migrazioni cloud
Risultati analitici
Automatizza e semplifica i set di dati
- Set di dati multi-modello
Analisi dei dati delle serie temporali
- Delta/record modificati
- Fedeltà evento per evento
Elimina tutte le copie dei dati e ottieni un data store operativo
- Registri e pipeline basati sui log
Data lake e data warehouse distribuiti
- Ibridi/multicloud/globali
- Integrazione streaming/ETL
Analytics predittivi
- Monetizzazione dei dati, nuovi servizi di dati in vendita
Una soluzione che unisce
La trasformazione digitale è molto complessa e sfortunatamente la maggior parte delle aziende non riuscirà a portarla a termine con successo. Con il passare degli anni, la tecnologia, la progettazione dei software e l'architettura dei dati diventano sempre più distribuite, mentre le tecniche moderne si scostano dagli stili altamente centralizzati e monolitici.
Il data mesh è un nuovo concetto relativo ai dati, ovvero un cambiamento deliberato verso eventi di dati altamente distribuiti e in tempo reale rispetto a un'elaborazione di dati monolitica, centralizzata e in modalità batch. Fondamentalmente, il data mesh è un cambio di mentalità culturale che mette al primo posto le esigenze dei consumatori di dati. È anche un vero e proprio cambiamento tecnologico incentrato sulle piattaforme e i servizi che supportano un'architettura dei dati decentralizzata.
I casi d'uso di data mesh includono sia i dati operativi sia quelli analitici, il che rappresenta una differenza fondamentale rispetto ai data lake/lakehouse e ai data warehouse convenzionali. Questo allineamento dei domini di dati operativi e analitici è un fattore determinante per soddisfare la necessità di incrementare le funzionalità self-service per i consumatori di dati. La moderna tecnologia delle piattaforme di dati consente di eliminare qualsiasi intermediazione, connettendo direttamente produttori e consumatori di dati.
Oracle è da tempo leader di mercato nelle soluzioni di dati mission-critical e ha messo in campo alcune delle funzionalità più moderne per offrire un data mesh affidabile:
- Infrastruttura Generation 2 Cloud di Oracle con oltre 33 aree geografiche attive
- Database multi-modello per prodotti di dati "shape-shifting"
- Registro di set di dati basati su microservizi per tutti i data store
- Elaborazione dei flussi multicloud per dati affidabili e in tempo reale
- Piattaforma API, sviluppo moderno di applicazioni e strumenti self-service
- Analytics, visualizzazione dei dati e data science nativa cloud