Doorlooptijden van leveranciers voorspellen om supply chain-activiteiten te optimaliseren

Uitdagingen in de supply chain oplossen met nauwkeurigere, datagestuurde prognoses voor doorlooptijden
De COVID-19-pandemie gooide de gewoonten van consumenten overhoop. Vanwege tekorten waren mensen gedwongen om nieuwe merken te proberen. Ze kwamen veel minder vaak in winkels, met name in supermarkten; maar als ze kwamen, kochten ze vaak meer. Hierdoor raakten winkels sneller door hun voorraden, wat een ongekende belasting vormde voor supply chains en financiële modellen en leidde tot problemen met de brutomarge.
Tegelijkertijd stegen de kosten voor het niet op voorraad hebben van producten en kunnen problemen met het aanvullen van voorraden de winstgevendheid en het algehele succes van het bedrijf ondermijnen. Consumenten tolereren minder vaak lege schappen. Ze hebben immers vrijwel onmiddellijke toegang tot prijzen en beschikbare producten bij steeds meer concurrenten, die de behoeften van kopers kunnen vervullen met services en producten die ze op meerdere manieren kunnen leveren. Het is zelfs zo dat 29% van de consumenten zegt dat als producten niet onmiddellijk leverbaar zijn, ze naar een ander merk zouden overstappen.
Voor de detailhandel is het nu de uitdaging om consequent klanten tevreden te stellen die de gewenste hoeveelheid handelswaar willen vinden waar en wanneer ze het willen. Om hun financiële doelen te behalen, moeten detailhandelaars hun voorraden strategisch beheren op elk punt in hun supply chains en ervoor zorgen dat het aanvullingsproces altijd soepel en efficiënt verloopt.
Als ze de doorlooptijd van leveranciers kunnen voorspellen, dus hoeveel tijd het kost voor een leverancier om een product of service te leveren nadat een order is geplaatst, kunnen detailhandelaren hun productieschema's plannen en voorraden beheren. Zo kunnen ze effectief de klantvraag vervullen en tegelijkertijd overtollige voorraad en de bijbehorende kosten tot een minimum beperken.
De doorlooptijd voor een leverancier is afhankelijk van diverse factoren, zoals de afstand tussen de leverancier en de bestemming van het product, de complexiteit van het product, de beschikbaarheid van grondstoffen, productiecapaciteit en de tijd benodigd voor transport. Vanwege het aantal variabelen heeft de detailhandel een dataplatform nodig dat centrale toegang biedt tot historische en realtime data uit uiteenlopende bedrijfssystemen, bedrijfsrecords en technische invoeren. Met deze data kunnen vervolgens machine learning-modellen worden getraind, zodat de verwachte doorlooptijden worden voorspeld op basis van inkoopordertransacties.
Risico's in supply chain-activiteiten elimineren en voorraadbeheer verbeteren met geavanceerde analyse en machine learning
In dit gebruiksscenario laten we zien hoe Oracle Data Platform is opgezet om detailhandelaars te helpen met behulp van geavanceerde analyse- en prognosemethoden (inclusief statistische modellering, trendanalyse en historische data-analyse) en machine learning de verwachte leveringsdatum van goederen nauwkeurig te schatten. Met deze informatie kunnen detailhandelaren de voorraadplanning optimaliseren en effectief de impact beheren van variabelen zoals:
- doorlooptijden en transport, inclusief het coördineren van de beschikbaarheid bij leveranciers, transportschema's, transporttijden en kosten;
- diverse productportefeuilles, zoals de uitdagingen van het beheer van een breed scala aan producten, beschikbaarheid, pakketconfiguraties, bestelvoorwaarden en kosten voor honderden leveranciers;
- complexiteit van de lokale markt, zoals vraagpatronen en invloeden zoals seizoensgebondenheid en promoties;
- financiële en fysieke beperkingen, zoals budgetten, opslagbeperkingen en gewenste aantal voorraadslagen;
- voorraaddruk op afhandelingslocaties, zoals de financiële gevolgen van te grote voorraden en afwaarderingen, de druk om consistent uitstekende klantenservice te bieden en de noodzaak om producten altijd beschikbaar te hebben om geen verkoop mis te lopen en erosie van klantloyaliteit te voorkomen.
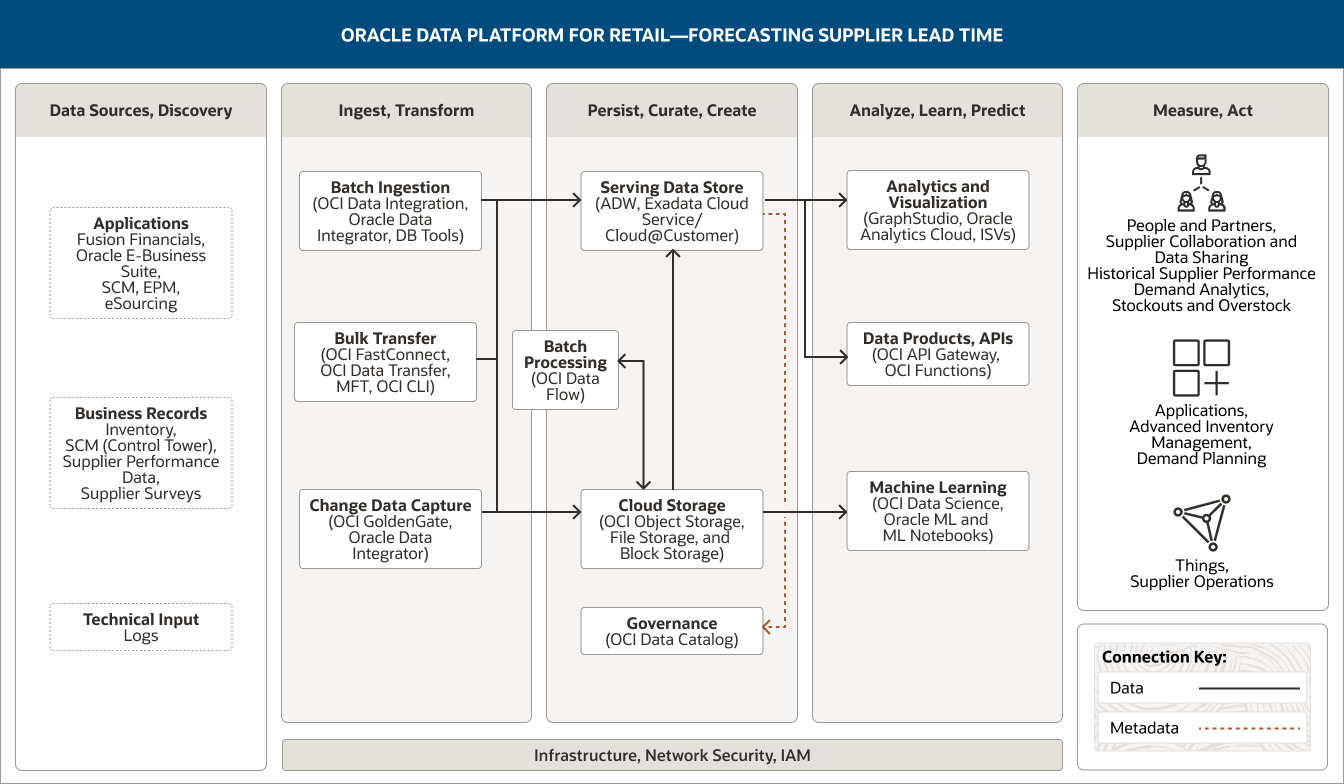
In deze afbeelding ziet u hoe Oracle Data Platform voor de detailhandel kan worden gebruikt om doorlooptijden van leveranciers te voorspellen en supply chain-activiteiten te optimaliseren. Dit helpt detailhandelaren hun marktpositie te behouden en hun winstgevendheid te maximaliseren. Het platform omvat deze vijf pijlers:
- 1. Databronnen, discovery
- 2. Opnemen, transformeren
- 3. Persistent maken, samenstellen, maken
- 4. Analyseren, leren, voorspellen
- 5. Meten, handelen
De pijler Databronnen, discovery omvat drie categorieën data.
- 1. Applicatiedata komt uit Fusion Financials, Oracle E-Business Suite, SCM, EPM en eSourcing.
- 2. De bedrijfsdata omvatten voorraad, SCM (verkeerstoren), data over leveranciersprestaties en leveranciersenquêtes.
- 3. Technische invoerdata zijn afkomstig uit logboeken.
De pijler Opnemen, transformeren omvat drie functionaliteiten.
- 1. Batchopname maakt gebruik van OCI Data Integration, Oracle Data Integrator en databasetools.
- 2. Bulkoverdracht maakt gebruik van OCI FastConnect, OCI Data Transfer, MFT en OCI CLI.
- 3. Wijzigingsdata vastleggen maakt gebruik van OCI GoldenGate.
Alle drie functionaliteiten verbinden unidirectioneel door naar de functionaliteit Cloudopslag in de pijler Persistent maken, samenstellen, maken.
De pijler Persistent maken, samenstellen, maken omvat vier functionaliteiten.
- 1. De aanbiedende dataopslag maakt gebruik van Autonomous Data Warehouse of Exadata Cloud Service.
- 2. Cloudopslag maakt gebruik van OCI Object Storage.
- 3. Batchverwerking maakt gebruik van OCI Data Flow.
- 4. Governance maakt gebruik van OCI Data Catalog.
Deze functionaliteiten verbinden binnen de pijler onderling naar elkaar door. Cloudopslag verbindt unidirectioneel door naar de aanbiedende dataopslag en ook bidirectioneel naar Batchverwerking.
Eén functionaliteit verbindt door naar de pijler Analyseren, leren, voorspellen: de aanbiedende dataopslag verbindt door naar de functionaliteiten Analyse en visualisatie en Machine learning.
De pijler Analyseren, leren, voorspellen omvat drie functionaliteiten.
- 1. Analyse en visualisatie maakt gebruik van Oracle Analytics Cloud, GraphStudio en ISV's.
- 2. Dataproducten, API's maakt gebruik van OCI API Gateway en OCI Functions.
- 3. Machine learning maakt gebruik van OCI Data Science, Oracle ML en Oracle ML Notebooks.
De pijler Meten, handelen, omvat drie consumers: Dashboard en rapporten, Applicaties en Modellen.
Dashboards en rapporten omvat mensen en partners, leverancierssamenwerking en het delen van data, historische leveranciersprestaties, vraaganalyse en voorraadtekorten en overtollige voorraden.
Applicaties omvat geavanceerd voorraadbeheer en vraagplanning.
Modellen omvat leveranciersactiviteiten./p>
De drie centrale pijlers, Opnemen, transformeren; Persistent maken, samenstellen, maken; en Analyseren, leren, voorspellen, worden ondersteund door infrastructuur, netwerk, beveiliging en IAM.
Er zijn drie belangrijke manieren om data in een architectuur in te voegen, zodat detailhandelaren effectief de doorlooptijden van leveranciers kunnen voorspellen.
- Allereerst moeten we de algehele voorraadpositie kennen, zodat we er zeker van zijn dat we niet te weinig of te veel op voorraad hebben van onze producten. We gebruiken hiervoor Oracle Cloud Infrastructure (OCI) GoldenGate. Hiermee nemen we vastgelegde wijzigingsdata op van bijna realtime data voor magazijnvoorraden uit operationele databases voor alle productlijnen of een subset van productlijnen. Met deze data kunnen we prijzen aanpassen om voorraad af te bouwen of voorraadtekorten te voorkomen.
- Om de prestaties van leveranciers nauwkeurig te kunnen voorspellen, moeten we ook historische prestaties, trends en patronen kennen. Doorgaans moeten we hiervoor veel transactiedata (inclusief ERP-data zoals inkoop-, facturatie-, supply chain- en logistieke data) en andere operationele metrics en datasets (zoals data over consumptie, voorraad en hot swaps) laden uit lokale dataopslagplaatsen, met behulp van methoden en services voor bulkoverdracht zoals OCI Data Transfer Service.
- We kunnen nu met batchopname datasets toevoegen die relevant zijn voor leveranciers, zoals orders die gedurende een specifieke periode bij de leverancier zijn geplaatst, inclusief de datum van de order, de bestelde hoeveelheid en de leveringsdatum. Deze datasets bevatten vaak grote hoeveelheden data die meestal in on-premises systemen is opgeslagen. In de meeste gevallen is batchopname de geschikte en meest efficiënte methode. Voor onze leveranciersdata nemen we de data dagelijk op met behulp van Oracle Data Integrator. Deze data zijn voornamelijk afkomstig uit operationele transactieverwerkingssystemen en worden doorgaans gemodelleerd in zeer gestructureerde relationele vorm. Voorbeelden van deze data zijn inkoopordertransacties, inclusief leveranciersdetails (bijvoorbeeld naam, ID, registratie en contactgegevens), herkomst en bestemming, overeengekomen leveringsdatum, werkelijke leveringsdatum, contractartikelen en prijs, verzendmethode, enzovoort. Data over leveranciersprestaties, zoals de betrouwbaarheid van leveringen, kwaliteit van goederen of diensten en eventuele vertragingen of problemen die zich in het verleden voordeden, kunnen ook worden opgenomen. Deze data zijn vaak minder gestructureerd en vereisen mogelijk meer inspanning voor verwerking.
- Door de doorlooptijd te berekenen voor elke order die eerder bij de leverancier is geplaatst, kunnen we een gemiddelde doorlooptijd berekenen en trends en variaties identificeren. Deze trends en variaties kunnen worden gecorreleerd met externe factoren die van invloed kunnen zijn op de doorlooptijd van de leverancier. Denk hierbij aan vertragingen in het transport, veranderingen in de productiecapaciteit van de leverancier, milieu- of omgevingsfactoren (zoals noodweer) of sociopolitieke gebeurtenissen (zoals conflicten of stakingen). Met aanvullende data kunnen markttrends en vraagpatronen worden gevolgd om te anticiperen op potentiële pieken in de vraag die de doorlooptijd van de leverancier kunnen beïnvloeden.
Datapersistentie en -verwerking zijn gebaseerd op drie componenten.
- De opgenomen, onbewerkte data uit alle bronnen worden opgeslagen in de cloudopslag. Met OCI Data Flow voeren we de batchverwerking uit van deze persistent gemaakte data, voorraadniveaus, geomapping-data en productreferentiedata. In de batchverwerking worden de data opnieuw verwerkt en worden eventuele dubbele en ontbrekende waarden of uitschieters verwijderd die de analyse kunnen verstoren. Deze verwerkte datasets worden geretourneerd naar de cloudopslag voor verdere persistentie, samenstelling en analyse. Uiteindelijk worden ze in geoptimaliseerde vorm geladen in de aanbiedende dataopslag in een indeling die gemakkelijke analyse mogelijk maakt.
- We hebben nu verwerkte datasets gemaakt die persistent kunnen worden gemaakt in geoptimaliseerde relationele vorm voor samenstelling en goede queryprestaties in de aanbiedende dataopslag die Oracle Autonomous Data Warehouse biedt. Hierdoor kunnen we de producten identificeren en retourneren op basis van prijs, vraagprofiel, voorraadniveau en locatie.
Het vermogen om te analyseren, te leren en te voorspellen is gebaseerd op drie technologieën.
- Dankzij services voor analyse en visualisatie kunnen we statistische technieken gebruiken, zoals regressieanalyse en tijdreeksanalyse, evenals machine learning-algoritmes om patronen en trends in de data te identificeren. Met deze analyse kunnen we vervolgens een prognosemodel ontwikkelen dat de doorlooptijd van de leverancier nauwkeurig kan voorspellen en de nauwkeurigheid van het model continu kan valideren door de voorspelde doorlooptijden te vergelijken met de werkelijke doorlooptijden voor een reeks orders. Met de resultaten van deze validatie wordt het model verfijnd en de nauwkeurigheid ervan verbeterd. Onze services voor analyse en visualisatie bieden de volgende functionaliteiten:
- Met beschrijvende analyses worden actuele trends beschreven met histogrammen en grafieken en prijsbepalingsalgoritmes ontwikkeld. Deze maken gebruik van vooraf gedefinieerde regels om prijzen aan te passen op basis van specifieke criteria, zoals verkoopprestaties, voorraadniveaus of prijzen van concurrenten. Een detailhandelaar kan bijvoorbeeld een regel instellen om de prijs van een product met 10% te verlagen als het al meer dan 30 dagen op voorraad is en de aankoop van nieuwe voorraad uitstellen of onderhandelen over een prijs voor een latere levering met behulp van doorlooptijdprognoses om de beste timing te bepalen.
- Voorspellende analyses geven prognoses voor toekomstige gebeurtenissen, identificeren trends en bepalen de waarschijnlijkheid van onzekere resultaten. Met voorspellende analyses kunnen detailhandelsbedrijven op basis van historische verkoopdata correlaties tussen prijs en vraag identificeren. Deze analyse kunnen ze vervolgens gebruiken om te voorspellen hoe veranderingen in het gedrag van consumenten de vraag beïnvloeden en voorraadplannen dienovereenkomstig aanpassen, op basis van geschatte doorlooptijden. Zo zorgen ze ervoor dat er voldoende fysieke voorraad aanwezig is wanneer ze deze nodig hebben en beperken ze tegelijkertijd overtollige voorraad en de bijbehorende kosten tot een minimum. Ook kunnen met voorspellende analyses prijselasticiteitsmodellen worden ontwikkeld. Deze maken gebruik van statistische modellen om te meten hoe gevoelig de vraag is voor prijswijzigingen. Detailhandelaren kunnen deze analyse gebruiken om de optimale voorraadniveaus te identificeren voor maximale verkoop en winstgevendheid en hun voorraadaankopen op basis daarvan af te stemmen.
- Met sturende analyses worden geschikte acties voorgesteld om optimale besluitvorming te ondersteunen. Ze kunnen worden gebruikt om doorlooptijden te voorspellen en zo de kosten voor het aanhouden van voorraad en voorraadtekorten te minimaliseren. Door inkoop- en productieactiviteiten af te stemmen op de doorlooptijden van leveranciers, kunnen detailhandelaars de overtollige voorraad, transportkosten en kosten van spoedlevering verlagen en beter onderhandelen met leveranciers over prijzen en voorwaarden op basis van nauwkeurige doorlooptijden.
- Naast het gebruik van geavanceerde analyses worden machine learning-modellen ontwikkeld, getraind en geïmplementeerd. Deze modellen passen kunstmatige intelligentie toe om grote hoeveelheden data te analyseren en patronen en trends te identificeren waarmee voorraadaankopen en voorraadniveaus kunnen worden geoptimaliseerd. Detailhandelaren kunnen met machine learning-algoritmen het gedrag van klanten voorspellen, bepalen wanneer ze voorraad moeten inkopen van welke leveranciers en prijzen op meerdere producten en markten optimaliseren.
- Op onze samengestelde, geteste en hoogwaardige data en modellen kunnen governance- en beleidsregels worden toegepast. Ze kunnen beschikbaar worden gesteld als een 'dataproduct' (API) in een data mesh-architectuur voor distributie binnen de detailhandelorganisatie.
Voorraadbeheer en klanttevredenheid verbeteren met een dataplatform voor de detailhandel
Als ze leveranciersdoorlooptijden nauwkeurig voorspellen, kunnen detailhandelaren hun voorraadniveaus en productieschema's beter plannen. Zo hebben ze de juiste producten in de juiste hoeveelheden beschikbaar om aan de klantvraag te voldoen, zelfs als deze fluctueert op basis van seizoensgebondenheid, promoties en andere invloeden. Dit stelt ze in staat het volgende te doen:
- bepalen wanneer voorraad moet worden ingekocht en van welke leveranciers;
- de kosten voor het aanhouden van voorraad minimaliseren door de juiste hoeveelheden producten te bestellen op het juiste moment en voorraadtekorten te vermijden, wat kan leiden tot gemiste verkoopkansen en ontevreden klanten;
- hun cashflow beheren door aankopen en betalingen aan leveranciers te plannen, zodat ze hun werkkapitaal kunnen optimaliseren en cashflowtekorten kunnen voorkomen;
- sterkere relaties opbouwen met leveranciers door betere communicatie over doorlooptijden en andere prestatiemetrics, wat kan leiden tot betere prestaties, betere prijzen en betrouwbaardere leveringsschema's.
Gerelateerde bronnen
-
Gebruiksscenario
Win inzichten om uw retailprijzen te optimaliseren.
Ontdek in dit gebruiksscenario hoe u uw voorraad en promoties kunt optimaliseren met Oracle Data Platform voor de detailhandel.
-
Gebruiksscenario
Win inzichten om uw retailvoorraad te optimaliseren.
Zie hoe u uw voorraad en promoties optimaliseert met Oracle Data Platform voor de detailhandel. In dit gebruiksscenario ziet u hoe u de verkoop stimuleert en beter in klantbehoeften voorziet.
-
Gebruiksscenario
Optimaliseer uw bedrijfsactiviteiten in de retail met Live Data Analysis
Ontdek hoe u uw retailactiviteiten verbetert door live data op te nemen en geavanceerde analytics toe te passen met Oracle Data Platform voor de detailhandel.
Aan de slag
Probeer meer dan 20 'Altijd gratis'-cloudservices uit, met een proefversie van 30 dagen voor nog meer
Oracle biedt een Free Tier zonder tijdslimiet voor meer dan 20 services zoals Autonomous AI Database, computing op ARM en storage, evenals USD 300 aan gratis tegoed om extra cloudservices uit te proberen. Lees de informatie en meld u vandaag nog aan voor uw gratis account.
-
Wat is inbegrepen in Oracle Cloud Free Tier?
- Twee Autonomous AI Database instances, elk 20 GB
- Compute VM's van AMD en Arm
- 200 GB totale blokopslag
- 10 GB objectopslag
- 10 TB uitgaande dataoverdracht per maand
- Meer dan 10 extra 'Altijd gratis'-services
- $ 300 aan gratis tegoed voor 30 dagen voor nog meer
Leer met stapsgewijze begeleiding
Ervaar een breed scala aan OCI-services via zelfstudies en praktijklabs. Of u nu een ontwikkelaar, beheerder of analist bent, wij kunnen u laten zien hoe OCI werkt. Veel labs draaien op de Oracle Cloud Free Tier of een door Oracle geleverde gratis labomgeving.
-
Aan de slag met OCI Core Services
De labs in deze workshop bevatten een inleiding tot de kernservices van Oracle Cloud Infrastructure (OCI), waaronder virtuele cloudnetwerken (VCN) en compute- en opslagservices.
Start nu het lab voor OCI-kernservices -
Snel aan de slag met Autonomous AI Database
In deze workshop doorloopt u de stappen om aan de slag te gaan met Oracle Autonomous AI Database.
Begin nu aan het lab Snel aan de slag met Autonomous AI Database -
Een app bouwen vanuit een spreadsheet
Dit lab begeleidt u bij het uploaden van een spreadsheet naar een Oracle Database tabel en het maken van een applicatie op basis van deze nieuwe tabel.
Start deze training nu
Ontdek meer dan 150 best practices
Bekijk hoe onze architecten en andere klanten een breed scala aan workloads implementeren, van bedrijfsapps tot HPC, van microservices tot data lakes. Begrijp de best practices, hoor over andere architecten van klanten in onze reeks 'Built & Deployed' en implementeer veel workloads met onze 'click-to-deploy'-functie, of doe dit zelf vanuit onze GitHub-repository.
Populaire architecturen
- Apache Tomcat met MySQL Database Service
- Oracle Weblogic op Kubernetes met Jenkins
- Machine learning (ML)- en AI-omgevingen
- Tomcat op ARM met Oracle Autonomous AI Database
- Loganalyse met ELK-stack
- HPC met OpenFOAM
Bekijk hoeveel u kunt besparen op OCI
De prijsbepaling voor Oracle Cloud is eenvoudig, met wereldwijd consistente lage prijzen, met ondersteuning voor een breed scala aan gebruiksdoelen. Ga naar de kostencalculator voor een schatting van uw lage tarief en kies en configureer de services die u nodig hebt.
Ervaar het verschil:
- Een kwart van de kosten voor uitgaande bandbreedte
- Drie keer betere Compute prijs-prestatieverhouding
- Zelfde lage prijs in elke regio
- Lage prijzen zonder langetermijnverplichtingen
Neem contact op met de verkooporganisatie
Wilt u meer weten over Oracle Cloud Infrastructure? Laat een van onze experts u helpen.
-
Ze kunnen vragen beantwoorden zoals:
- Welke workloads draaien het beste op OCI?
- Hoe profiteer ik optimaal van Oracle investeringen?
- Wat zijn de voordelen van OCI ten opzichte van andere cloudcomputing-providers?
- Hoe kan OCI uw IaaS- en PaaS-doelen ondersteunen?