
Apply best practices to improve analysis of your critical retail data
The ability to perform live data analysis using high-quality data is crucial for organizations in many industries, but it’s particularly important for retailers. Timely insights drawn from accurate data can help improve customer satisfaction by offering in-the-moment product recommendations and ensuring stock is in the right place at the right time; optimize merchandising, marketing, and sales efforts with real-time assessments of how well promotions are performing; lower costs and risk via more-precise inventory forecasts; and more. In short, effective live data analysis has the potential to positively impact retail operations across your organization.
To get the greatest value from live data analysis, you need to implement a single optimized approach to data lifecycle management across your most critical datasets. This approach helps you
- Reduce data complexity and duplication.
- Minimize the risk and costs associated with poor-quality data.
- Create a single, consistent view of your data.
- Deliver data in a consistent form across the organization.
- Make self-service business intelligence (BI) for reporting and advanced data analytics available, regardless of the tools used by domain teams.
- Build flexibility into your data landscape, keeping the cost of change in the future as low as possible.
Modernize your analytics with an optimized analytics solution
The following architecture demonstrates how Oracle Data Platform is built to provide retailers with a cohesive, comprehensive framework to manage the entire data analytics lifecycle. At its center are two critical components: the operational data store (ODS)—used to store operational data that is ingested and persisted in raw form with no transformations applied—and a data warehouse, where the data is stored in optimized form for query performance and advanced analysis.
When combined, the ODS and data warehouse create a data platform capable of more efficient and advanced analytics. The combination enables the effective application of advanced analytics and visualization tools while retaining the ability to investigate the data in its raw form to identify anomalies or insights without impacting the performance of the underlying transactional application. This approach is beneficial for retailers because it prevents contradictory and inaccurate duplication of the same source data, which, if used to inform an organization’s decisions, can cause delays, errors, and ultimately lost sales.
Let’s take a closer look at how Oracle Data Platform incorporates an ODS, data warehouse, and other key components to help retailers effectively use live data analysis.
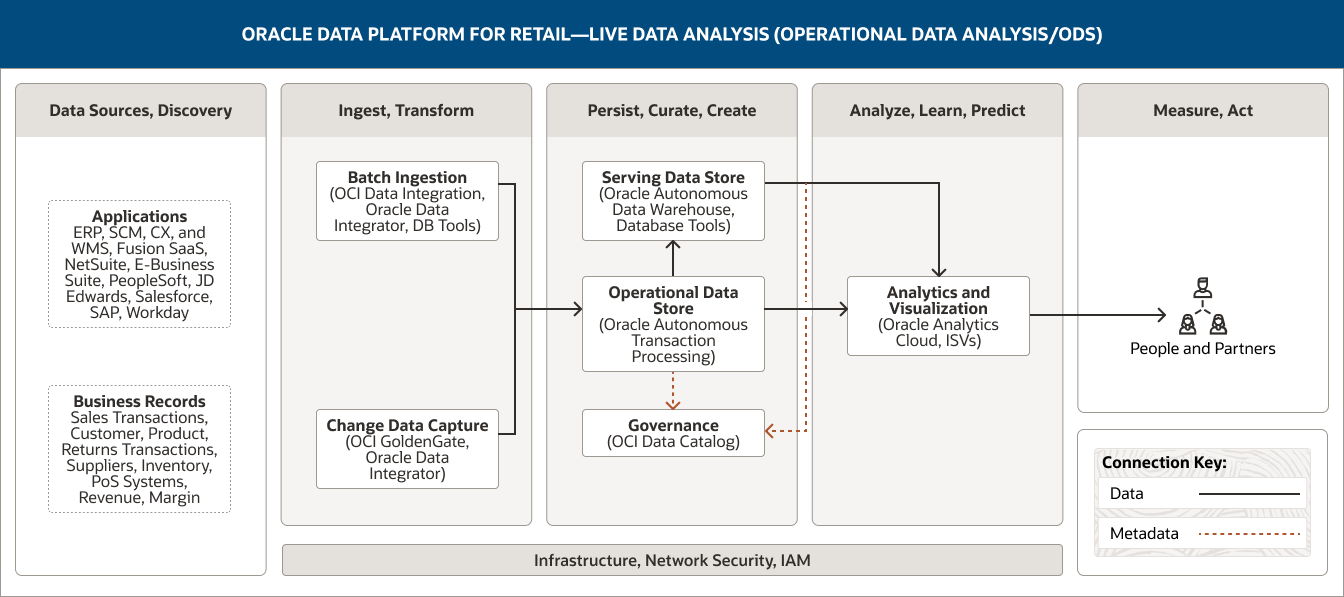
This image shows how Oracle Data Platform for retail can be used to support the analysis of live and historical data in optimized form. The platform includes the following five pillars:
- 1. Data Sources, Discovery
- 2. Connect, Ingest, Transform
- 3. Persist, Curate, Create
- 4. Analyze, Learn, Predict
- 5. Measure, Act
The Data Sources, Discovery pillar includes two categories of data.
- 1. Applications comprises data from ERP, SCM, CX, and WMS applications, Fusion SaaS, NetSuite, E-Business Suite, PeopleSoft, JD Edwards, Salesforce, SAP, and Workday.
- 2. Business records comprises sales transactions, customer data, product data, returns transactions, supplier data, inventory data, data from point-of-sale systems, and revenue and margin data.
The Connect, Ingest, Transform pillar comprises two capabilities.
- 1. Batch ingestion uses OCI Data Integration, Oracle Data Integrator, and DB tools. Change data capture uses OCI GoldenGate and Oracle Data Integrator.
- 2. Both capabilities connect unidirectionally into the operational data store capability within the Persist, Curate, Create pillar.
The Persist, Curate, Create pillar comprises three capabilities.
- 1. The operational data store uses Oracle Autonomous Transaction Processing.
- 2. The serving data store uses Oracle Autonomous Data Warehouse and database tools.
- 3. Governance uses OCI Data Catalog.
These capabilities are connected within the pillar. The operational data store is unidirectionally connected to the serving data store.
One capability connects into the Analyze, Learn, Predict pillar: The serving data store connects unidirectionally to the analytics and visualization capability.
The Analyze, Learn, Predict pillar comprises one capability.
- 1. Analytics and visualization uses Oracle Analytics Cloud, GraphStudio, and ISVs.
The Measure, Act pillar comprises a single category of consumer: dashboards and reports.
The three central pillars—Ingest, Transform; Persist, Curate, Create; and Analyze, Learn, Predict—are supported by infrastructure, network, security, and IAM.
There are two (or optionally three) main methods of injecting data into an architecture to enable retailers to better analyze their data.
- To start our process, we need to gain visibility into up-to-date data from our business records and applications (for example, inventory levels across retail locations). To do so, we use OCI GoldenGate to enable change data capture (CDC) ingestion of near real-time data from operational databases (transactional processing). This will include all records or discrete record sets related to retail transactions, including point-of-sale and web transactions (both sales and returns), and inventory, logistics, and supply chain data. In addition to triggering data ingestion using time stamps or flag filters, data can be ingested through a CDC mechanism that detects changes as they happen. OCI GoldenGate provides a CDC mechanism that can process source changes noninvasively by processing log files of completed transactions and storing these captured changes in external trail files, independent of the database. Changes are then reliably transferred to a staging database or operational data store.
- We can now add datasets relevant to core retail transactions, including inventory and product data, customer records, and offers and prices. These datasets often comprise large volumes of often on-premises data, and in most cases, batch ingestion is typically most efficient.
That said, there are some things to consider when deciding how to collect transactional data from operational sources to populate operational data stores. The techniques available vary mostly in terms of the latency of data integration, ranging from scheduled daily batches to continuous real-time integration. Data is captured from sources via incremental queries that filter either based on a time stamp or flag. The techniques also vary in whether they use a pull or push operation; a pull operation pulls in new data at fixed intervals, while a push operation loads data into the target once a change appears. A daily batch ingestion is most suitable if intraday freshness isn’t required for the data—for example, data on longer-term trends or data that’s only calculated once daily, such as financial close information. Batch loads might be performed in a downtime window if the business model doesn’t require 24-hour data warehouse availability. Different techniques, such as real-time partitioning or trickle and flip exist to minimize the impact of a load to a live data warehouse when no downtime window is available. - Optionally, we can also use streaming ingestion to ingest data read from beacons at store locations through IoT, machine-to-machine communication, and other means. Video imaging can also be consumed this way. Additionally, in this use case, we intend to analyze and rapidly respond to consumer sentiment by analyzing social media messages, responses to first-party posts, and trending messages. Social media (application) messages/events will be ingested with the option to perform some basic transformation/aggregation before the data is stored in cloud storage. Additional stream analytics can be used to identify correlating consumer events and behavior, and identified patterns can be fed back (manually) for OCI Data Science to examine the raw data.
Data persistence and processing is built on two components.
- The operational data store is used for operational reporting on raw data and as a source of data for an enterprise or domain-level service data store or enterprise data warehouse (EDW). It’s a complementary element to an EDW in a decision support environment. An ODS is typically a relational database designed to integrate and persist data from multiple sources to be used for additional operations, reporting, controls, and operational decision support, whereas the EDW is used for tactical and strategic decision support. Usually the ODS’s data model is very close to the OLTP source application’s data model. Any source data should be accepted by the ODS and almost no data quality rules should be implemented, ensuring you have a store representing all the data of the day from operational systems. Unlike a production master data store, the data is not passed back to the operational system. Data warehouses are typically read-only and batch updated on a specific schedule, while operational data stores are maintained in closer to real time and trickle fed constantly.
- We have now created processed datasets ready to be persisted in optimized relational form for curation
and query performance in the serving data store. In this use case, the serving data
store is a data warehouse, a type of persistence platform that is designed to support
business intelligence activities and increasingly advanced analytics. The main goal of a data warehouse
is to consolidate and deliver accurate indicators to business users to help them make informed decisions
in their day-to-day work as well as larger strategic business decisions. To do this, data warehouses are
highly specialized, often contain large amounts of historical data, and are solely intended to perform
queries and analysis. A data warehouse centralizes and consolidates large amounts of data from multiple
sources, such as application log files and transaction applications, and then delivers it in optimal
form for analysis. Its analytical capabilities allow organizations to derive valuable business insights
from their data to improve decision-making. Over time, it builds a historical record that can be
invaluable to data scientists and business analysts. Because of these capabilities, a data warehouse can
be considered an organization’s “source of truth.” There has been a tendency to view data warehouses
purely as technology assets, but they actually provide a unique environment to bring business users and
IT together to develop and deliver a shared understanding of a retailer’s operating environment and to
complete tasks such as
- Defining business needs (key indicators); identifying source data that concerns key indicators; and specifying business rules to transform source information into key indicators
- Modelling the data structure of the target warehouse to store the key indicators
- Populating the indicators by implementing business rules
- Measuring the overall accuracy of the data by setting up data quality rules
- Developing reports on key indicators
- Making key indicators and metadata available to business users through ad hoc query tools or predefined reports
- Measuring business users’ satisfaction and adding or modifying key indicators
The ability to analyze, learn, and predict is built on two technologies.
- Analytics and visualization services deliver descriptive analytics (describes current trends with
histograms and charts), predictive analytics (predicts future events, identifies trends, and determines
the probability of uncertain outcomes), and prescriptive analytics (proposes suitable actions, leading
to optimal decision-making), enabling retailers to answer questions such as
- How do actual sales this period compare to the current plan?
- What is the retail value of inventory on hand, and how does it compare to the same period last year?
- What are the best-selling items in a division or department?
- How effective was the last promotion?
Alongside the use of advanced analytics and visualizations, machine learning models can be developed, trained, and deployed.
Governance is a critical factor to consider when building a solution such as this. Business users rely on the accuracy of key indicators from the data warehouse to make decisions. If these indicators are wrong, the decisions are also likely to be wrong. Depending on the data quality strategy you have defined, business users will likely need to actively participate in the monitoring of data discrepancies. They will have to help the IT team refine how the indicators are calculated and assist with the qualification and identification of erroneous data. This generally leads to the modification and testable improvement of the business rules.
- Our curated, tested, and high-quality data and models can have your governance rules and policies applied and can be exposed as a data product (API) within a data mesh architecture for distribution across the retail organization. This can be critical to addressing data quality issues. Poor data quality impacts almost every retail organization. Inconsistent, inaccurate, incomplete, and out-of-date data is often the root cause of expensive business problems such as operational inefficiencies, faulty analysis, unrealized economies of scale, and dissatisfied customers. These data quality issues and the business-level problems associated with them can be solved by committing to a comprehensive data quality effort across the enterprise, exploiting the capabilities of the architecture described above.
Make better decisions with better data
Oracle Data Platform is built to ensure you have organizationwide access to consistent, high-quality data when and where you need it so you can do the following:
- Make better-informed decisions.
- Minimize the cost of future changes with a consistent, but flexible, data landscape.
- Reflect process and data changes many times with fewer silos and no impact on data availability and quality.
- Reduce the risk of errors in critical financial and regulatory reporting by eliminating siloed copies of the same data with differing transformation logic across the enterprise data landscape.
- Provide self-serve advanced analytics and data discovery for reporting with far better data availability—access to data is no longer tied to the specific tools used by domain teams.
- Reduce storage costs for growth of the ODS and other data stores.
- Spend more time looking at the insight the data provides and less time identifying the discrepancies caused by multiple copies of data across disconnected silos.
- Reduce risk by no longer having multiple copies of data, which increase the surface attack area.
Related resources
-
Use case
Gain Insights to Optimize Your Retail Pricing
Learn how to optimize your inventory and promotions with Oracle Data Platform for retail in this use case.
-
Use case
Gain Insights to Optimize Your Retail Inventory
Learn how to optimize your inventory and promotions with Oracle Data Platform for retail. This use case will show you how to increase sales and better meet customer demand.
-
Use case
Accurately Forecast Supplier Lead Time with a Data Platform
Learn how a retail data platform can improve supplier lead time forecasting so you can ensure you have the right products available to meet customer demand.
Get started
Try 20+ Always Free cloud services, with a 30-day trial for even more
Oracle offers a Free Tier with no time limits on more than 20 services such as Autonomous AI Database, Arm Compute, and Storage, as well as US$300 in free credits to try additional cloud services. Get the details and sign up for your free account today.
-
What’s included with Oracle Cloud Free Tier?
- Two Autonomous AI Database instances, 20 GB each
- AMD and Arm Compute VMs
- 200 GB total block storage
- 10 GB object storage
- 10 TB outbound data transfer per month
- 10+ more Always Free services
- US$300 in free credits for 30 days for even more
Learn with step-by-step guidance
Experience a wide range of OCI services through tutorials and hands-on labs. Whether you're a developer, admin, or analyst, we can help you see how OCI works. Many labs run on the Oracle Cloud Free Tier or an Oracle-provided free lab environment.
-
Get started with OCI core services
The labs in this workshop cover an introduction to Oracle Cloud Infrastructure (OCI) core services including virtual cloud networks (VCN) and compute and storage services.
Start OCI core services lab now -
Autonomous AI Database quick start
In this workshop, you’ll go through the steps to get started using Oracle Autonomous AI Database.
Start Autonomous AI Database quick start lab now -
Build an app from a spreadsheet
This lab walks you through uploading a spreadsheet into an Oracle Database table, and then creating an application based on this new table.
Start this lab now
Explore over 150 best practice designs
See how our architects and other customers deploy a wide range of workloads, from enterprise apps to HPC, from microservices to data lakes. Understand the best practices, hear from other customer architects in our Built & Deployed series, and even deploy many workloads with our "click to deploy" capability or do it yourself from our GitHub repo.
Popular architectures
- Apache Tomcat with MySQL Database Service
- Oracle Weblogic on Kubernetes with Jenkins
- Machine-learning (ML) and AI environments
- Tomcat on Arm with Oracle Autonomous AI Database
- Log analysis with ELK Stack
- HPC with OpenFOAM
See how much you can save on OCI
Oracle Cloud pricing is simple, with consistent low pricing worldwide, supporting a wide range of use cases. To estimate your low rate, check out the cost estimator and configure the services to suit your needs.
Experience the difference:
- 1/4 the outbound bandwidth costs
- 3X the compute price-performance
- Same low price in every region
- Low pricing without long-term commitments
Contact sales
Interested in learning more about Oracle Cloud Infrastructure? Let one of our experts help.
-
They can answer questions like:
- What workloads run best on OCI?
- How do I get the most out of my overall Oracle investments?
- How does OCI compare to other cloud computing providers?
- How can OCI support your IaaS and PaaS goals?