
Oracle Database 11g: 著者:Arup Nanda |

ピボットとアンピボット
簡単なSQLを使用して任意のリレーショナル表からスプレッドシート型のクロス集計レポートに情報を表示し、クロス集計表から任意のデータをリレーショナル表に格納します。
ピボット
ご存知のとおり、リレーショナル表は当然ながら表形式です。つまり、列/値ペアで提示されます。CUSTOMERSという名前の表について検討してみましょう。
SQL> desc customers Name Null? Type ----------------------------------------- -------- --------------------------- CUST_ID NUMBER(10) CUST_NAME VARCHAR2(20) STATE_CODE VARCHAR2(2) TIMES_PURCHASED NUMBER(3)
この表に対して次のselect文を実行します。
select cust_id, state_code, times_purchased from customers order by cust_id;
出力結果は次のようになります。
CUST_ID STATE_CODE TIMES_PURCHASED
------- ---------- ---------------
1 CT 1
2 NY 10
3 NJ 2
4 NY 4
...
以降、省略
データが、値の行としてどのように表現されるかを見てみましょう。各顧客について、顧客の住所がある州と、店舗からの購入回数がレコードとして表示されます。顧客が店舗から購入した品物が増えると、列times_purchasedが更新されます。 では、購入頻度を州別にレポートする場合、つまり、購入回数が1回のみ、2回、3回、などの顧客の数を州別にカウントする場合を考えてみましょう。通常のSQLで、次の文を実行できます。
select state_code, times_purchased, count(1) cnt from customers group by state_code, times_purchased;
出力結果は次のようになります。
ST TIMES_PURCHASED CNT
-- --------------- ----------
CT 0 90
CT 1 165
CT 2 179
CT 3 173
CT 4 173
CT 5 152
...
以降、省略
必要なのはこの情報ですが、これでは解読するのが少し困難です。この同じデータを見やすく表現するには、クロス集計レポートを使用する方法があります。クロス集計レポートでは、スプレッドシートと同じように、データを縦方向、州を横方向に配列できます。
Times_purchased
CT NY NJ ...
以降、省略
1 0 1 0 ...
2 23 119 37 ...
3 17 45 1 ...
...
以降、省略
11gより前のOracle Databaseでこれを実行する場合は、各値についてなんらかのDECODE関数を使用し、個別の値を個別の列として書き込むという方法を取りました。ですが、この手法は分かりやすいとはとても言えません。 幸い、現在はピボットという優れた新機能があり、pivotという相応な名前の新しい演算子を使用して任意の問合せをクロス集計形式で表示できます。この問合せの記述方法は次のとおりです。
select * from (
select times_purchased, state_code
from customers t
)
pivot
(
count(state_code)
for state_code in ('NY','CT','NJ','FL','MO')
)
order by times_purchased
/
出力結果は次のようになります。
.TIMES_PURCHASED 'NY' 'CT' 'NJ' 'FL' 'MO'
--------------- ---------- ---------- ---------- ---------- ----------
0 16601 90 0 0 0
1 33048 165 0 0 0
2 33151 179 0 0 0
3 32978 173 0 0 0
4 33109 173 0 1 0
... 以下、省略
pivot演算子の威力がこの例に現れています。state_codeは列ではなくヘッダー行に表示されています。従来の表形式での表示方法を次の図に示します。

図1:従来の表形式での表示
クロス集計レポートでは、図2に示すように、Times Purchased列をヘッダー行に変える必要があります。列を反時計回りに90度回転させてヘッダー行にしたかのように、列が行になります。この図形的な回転を行うにはピボット・ポイントが必要ですが、この例ではうまい具合にcount(state_code)式がピボット・ポイントです。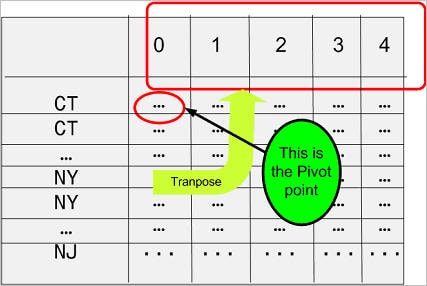
図2:ピボット演算後の表示
この式は、次のように問合せの構文に含める必要があります。
...
pivot
(
count(state_code)
for state_code in ('NY','CT','NJ','FL','MO')
)
...
2行目の"for state_code ..."は、問合せの対象を指定値のみに限定しています。この行は必ず記述する必要があります。そのため、困ったことに、使用できる値が事前に分かっている必要があります。この制約は、XML形式の問合せでは緩和されます。これについては後ほど説明します。
出力のヘッダー行を見てみましょう。
.TIMES_PURCHASED 'NY' 'CT' 'NJ' 'FL' 'MO'
--------------- ---------- ---------- ---------- ---------- ----------
列ヘッダーは、表自体に含まれるデータ、つまり州コードです。略称でも州名がすぐに分かるかもしれませんが、"CT"ではなく"Connecticut"のように、略称の代わりに州名を表示する必要があるとします。その場合は、問合せに少し手を加える必要があります。FOR句を下に示すように変更します。
select * from (
select times_purchased as "Puchase Frequency", state_code
from customers t
)
pivot
(
count(state_code)
for state_code in ('NY' as "New York",'CT' "Connecticut",'NJ' "New Jersey",'FL' "Florida",'MO' as "Missouri")
)
order by 1
/
Puchase Frequency New York Connecticut New Jersey Florida Missouri
----------------- ---------- ----------- ---------- ---------- ----------
0 16601 90 0 0 0
1 33048 165 0 0 0
2 33151 179 0 0 0
3 32978 173 0 0 0
4 33109 173 0 1 0
...
以降、省略
FOR句では値の別名を指定することができ、別名が列ヘッダーになります。
アンピボット
物質に反物質があるように、ピボットにも"反ピボット"があるべきですよね。
冗談はさておき、ピボット演算を反転させる演算の必要は本当にあるのです。下に示すクロス集計レポートを表示するスプレッドシートがあるとします。
| Purchase Frequency | New York | Connecticut | New Jersey | Florida | Missouri |
| 0 | 12 | 11 | 1 | 0 | 0 |
| 1 | 900 | 14 | 22 | 98 | 78 |
| 2 | 866 | 78 | 13 | 3 | 9 |
| ... | . |
このデータをCUSTOMERSというリレーショナル表にロードする必要があります。
SQL> desc customers Name Null? Type ----------------------------------------- -------- --------------------------- CUST_ID NUMBER(10) CUST_NAME VARCHAR2(20) STATE_CODE VARCHAR2(2) TIMES_PURCHASED NUMBER(3)
スプレッドシート・データはリレーショナル形式に非正規化してから格納する必要があります。もちろん、DECODEを使用してデータをCUSTOMERS表にロードする、SQL*LoaderまたはSQLの複雑なスクリプトを記述することもできますが、pivotの反転演算—Oracle Database 11gで使用できるようになったアンピボット—を使用して列を分割して行にすることもできます。
分かりやすくするために、例を使って説明します。まず、pivot演算を使用してクロス集計表を作成しましょう。
1 create table cust_matrix
2 as
3 select * from (
4 select times_purchased as "Puchase Frequency", state_code
5 from customers t
6 )
7 pivot
8 (
9 count(state_code)
10 for state_code in ('NY' as "New York",'CT' "Conn",'NJ' "New Jersey",'FL' "Florida",
'MO' as "Missouri")
11 )
12* order by 1
データが表にどのように格納されているかは、次の方法で確認できます。
SQL> select * from cust_matrix
2 /
Puchase Frequency New York Conn New Jersey Florida Missouri
----------------- ---------- ---------- ---------- ---------- ---------
1 33048 165 0 0 0
2 33151 179 0 0 0
3 32978 173 0 0 0
4 33109 173 0 1 0
... 以下、省略
スプレッドシートにデータが格納されるとき、各州("New York"、"Conn"など)は表の列になります。
SQL> desc cust_matrix Name Null? Type ----------------------------------------- -------- --------------------------- Puchase Frequency NUMBER(3) New York NUMBER Conn NUMBER New Jersey NUMBER Florida NUMBER Missouri NUMBER
州コードとその州のカウントのみが行に表示されるように、表を分割する必要があります。この処理は、次に示すunpivot演算で実行できます。
select *
from cust_matrix
unpivot
(
state_counts
for state_code in ("New York","Conn","New Jersey","Florida","Missouri")
)
order by "Puchase Frequency", state_code
/
出力結果は次のようになります。
Puchase Frequency STATE_CODE STATE_COUNTS
----------------- ---------- ------------
1 Conn 165
1 Florida 0
1 Missouri 0
1 New Jersey 0
1 New York 33048
2 Conn 179
2 Florida 0
2 Missouri 0
...
以降、省略
それぞれの列名がどのようにしてSTATE_CODE列の値になったかを見てみましょう。state_codeが列名であると、Oracleにはどうして分かったのでしょうか。問合せに含まれる次の句がOracleに教えたのです。
for state_code in ("New York","Conn","New Jersey","Florida","Missouri")
"New York"、"Conn"などを、アンピボットする必要がある新しい列、state_codeの値とすることが、ここで指定されていました。元のデータの一部を見てみましょう。
Purchase Frequency New York Conn New Jersey Florida Missouri
----------------- ---------- ---------- ---------- ---------- - ---------
1 33048 165 0 0 0
列だった"New York"はたちまち行の値になりましたが、値33048は、どの列に、どのようにして表示するのでしょうか。この疑問に答えてくれるのは、上の問合せに含まれるunpivot演算子の内側にあるfor句のすぐ上にある句です。state_countsを指定しましたが、これが結果の出力で作成される新しい列の名前なのです。
unpivotはpivotの逆の操作だと考えることもできますが、pivotの結果が当然unpivotで戻せると思わないでください。たとえば、上の例では表CUSTOMERSに対してpivot演算を使用して、新しい表CUST_MATRIXを作成しました。その後、表CUST_MATRIXに対してunpivotを使用しましたが、元の表CUSTOMERSの詳細は元に戻りませんでした。その代わり、リレーショナル表にロードできるように、クロス集計レポートが異なる方法で表示されました。つまり、unpivotはpivotの実行結果を元に戻すためのものではありません。ピボット表を作成した後に元の表を削除する前に、この事実を十分考慮する必要があります。
unpivotの使用例として非常に興味深いものの中には、前述した例のような普通の強力なデータ操作の域を超えているものもあります。Amis TechnologiesでOracle ACE Directorを務めるLucas Jellemaは、テストを目的として特定のデータの行を生成する方法を紹介しています。ここでは、彼のオリジナル・コードを少し変更した形式を使用して、英語のアルファベットの母音を生成します。
select value
from
(
(
select
'a' v1,
'e' v2,
'i' v3,
'o' v4,
'u' v5
from dual
)
unpivot
(
value
for value_type in
(v1,v2,v3,v4,v5)
)
)
/
出力結果は次のようになります。
V - a e i o u
このモデルを拡張すれば、どのような種類の行でも生成できます。Lucas、この素晴らしい技を披露してくれてありがとう。
XML型
上の例では、有効なstate_codeを次のように指定する必要がありました。
for state_code in ('NY','CT','NJ','FL','MO')
この要件は、state_code列にどのような値が存在するかを把握していることを前提としたものです。使用できる値が分からない場合は、どのようにして問合せを作成するのでしょうか。
pivot演算には、XMLという句があります。この句を使用するとピボット演算の出力をXMLとして作成でき、その場合はリテラル値の代わりに特殊な句、ANYを指定できます。次に例を示します。
select * from (
select times_purchased as "Purchase Frequency", state_code
from customers t
)
pivot xml
(
count(state_code)
for state_code in (any)
)
order by 1
/
出力はCLOBとして返されるので、LONGSIZEが大きい値に設定されていることを確認してから問合せを実行してください。 SQL> set long 99999
この問合せには、元のpivot演算と明らかに異なる点が2つあります(太字部分)。1つ目は、単にpivotではなく、pivot xmlという句を指定した点です。これにより、出力はXMLで作成されます。2つ目はfor句で、state_codeの値をいくつも並べるのではなく、for state_code in (any)としている点です。XMLの表記法ではANYキーワードの使用を許可しているため、state_codeの値を入力する必要がありません。出力結果は次のようになります。
Purchase Frequency STATE_CODE_XML
------------------ --------------------------------------------------
1 <PivotSet><item><column name = "STATE_CODE">CT</co
lumn><column name = "COUNT(STATE_CODE)">165</colum
n></item><item><column name = "STATE_CODE">NY</col
umn><column name = "COUNT(STATE_CODE)">33048</colu
mn></item></PivotSet>
2 <PivotSet><item><column name = "STATE_CODE">CT</co
lumn><column name = "COUNT(STATE_CODE)">179</colum
n></item><item><column name = "STATE_CODE">NY</col
umn><column name = "COUNT(STATE_CODE)">33151</colu
mn></item></PivotSet>
... 以下、省略
ご覧のとおり、列STATE_CODE_XMLはXML型で、ルート要素は<PivotSet>です。各値は名前/値の要素ペアとして表現されます。任意のXMLパーサーで出力を使用して、さらに便利な出力を作成できます。
ANY句の他に副問合せも記述できます。希望する州のリストがあり、それらの州の行だけを選択する必要があるとします。preferred_statesという名前の新しい表に、希望する州を配置します。
SQL> create table preferred_states
2 (
3 state_code varchar2(2)
4 )
5 /
Table created.
SQL> insert into preferred_states values ('FL')
2> /
1 row created.
SQL> commit;
Commit complete.
この場合のpivot演算は次のようになります。
select * from ( select times_purchased as "Puchase Frequency", state_code from customers t ) pivot xml ( count(state_code) for state_code in (select state_code from preferred_states) ) order by 1 /
for句の副問合せとしては何を指定してもかまいません。たとえば、希望する州に関する制限なしにすべてのレコードを選択する場合は、for句として次の句を使用できます。
for state_code in (select distinct state_code from customers)
副問合せから戻される値は1つ1つ異なっている必要があります。同じ値が含まれると、問合せは失敗します。そのため、上の句ではDISTINCT句を指定しています。
まとめ
pivotは非常に重要かつ実用的な機能をSQL言語にもたらしました。大量のDECODE関数を使用した複雑で分かりにくいコードを記述する代わりに、ピボット機能を使用して任意のリレーショナル表のクロス集計レポートを作成できます。同様に、unpivot演算を使用すれば、任意のクロス集計レポートを通常のリレーショナル表として格納するために変換することができます。 pivotからの出力は、通常のテキストまたはXMLで作成できます。XMLで作成する場合は、pivot演算で検索する必要のある値のドメインを指定する必要がありません。
ピボット演算およびアンピボット演算について詳しくは、Oracle Database 11g SQL言語リファレンスを参照してください。
記事一覧へ戻る