
シバタツ流! DWHチューニングの極意
第3回 パーティショニング

「Oracle Partitioning」はデータウェアハウスを構築するにあたって最も重要なオプション製品と言えるでしょう。表をパーティショニングすることによって、データをパーティション単位でDROPできたり、パーティション単位で圧縮するかどうか選べたりと、管理上のメリットも大きいのですが、今回はパフォーマンス・チューニングという観点に絞って説明したいと思います。
■パーティション・プルーニング
OLTPで使用されるデータベースのパフォーマンスを上げる最も基本的な方法は索引(Bツリー索引)を作成することであることは皆さんご存知でしょう。おさらいになりますが、読み込まないといけないデータ・ブロック数を減らすことでクエリーの応答速度が短くなることが索引を作成する理由です。つまり言い換えると、読み込まないといけないデータ・ブロック数が減らせれば索引という手法にこだわる必要はないわけです。では、他の方法はないのでしょうか? また、索引の説明に「全データの○%以下の結果を取得するようであれば索引を作るべき」という文章がよくありますが、だとすると○%以上の結果を取得する場合に使える手段はないのでしょうか?この2つの回答になるのがパーティション・プルーニングです。
パーティショニングとは、ある列の値をもとに表を分割する機能です。分割方法には範囲指定の「レンジ」、値指定の「リスト」、値のハッシュ値を使用する「ハッシュ」の3種類があり、2種類を組み合わせて使うことも可能です。
たとえば2007年から2011年の5年間の注文データを管理しているデータウェアハウスで、2010年に何件の取引があったのかを調べたいとします。SQLで書くと以下のとおりです。
■パーティション・プルーニング
OLTPで使用されるデータベースのパフォーマンスを上げる最も基本的な方法は索引(Bツリー索引)を作成することであることは皆さんご存知でしょう。おさらいになりますが、読み込まないといけないデータ・ブロック数を減らすことでクエリーの応答速度が短くなることが索引を作成する理由です。つまり言い換えると、読み込まないといけないデータ・ブロック数が減らせれば索引という手法にこだわる必要はないわけです。では、他の方法はないのでしょうか? また、索引の説明に「全データの○%以下の結果を取得するようであれば索引を作るべき」という文章がよくありますが、だとすると○%以上の結果を取得する場合に使える手段はないのでしょうか?この2つの回答になるのがパーティション・プルーニングです。
パーティショニングとは、ある列の値をもとに表を分割する機能です。分割方法には範囲指定の「レンジ」、値指定の「リスト」、値のハッシュ値を使用する「ハッシュ」の3種類があり、2種類を組み合わせて使うことも可能です。
たとえば2007年から2011年の5年間の注文データを管理しているデータウェアハウスで、2010年に何件の取引があったのかを調べたいとします。SQLで書くと以下のとおりです。
SELECT COUNT(*) FROM orders
WHERE ymd BETWEEN '2010-01-01' AND '2010-12-31';
WHERE ymd BETWEEN '2010-01-01' AND '2010-12-31';
2007年から2011年の取引数がすべて均等だとすると、2010年の取引数は全体の20%です。これではたとえYMD列に索引を作ったとしても索引は使われず、ORDER表全体のデータ・ブロックを読むことになるでしょう。
そこで以下のようにORDERS表をパーティショニング表として作成します。
そこで以下のようにORDERS表をパーティショニング表として作成します。
CREATE TABLE orders (
.......
ymd DATE
)
PARTITION BY RANGE (ymd) (
PARTITION r2007 VALUES LESS THAN (TO_DATE('2008-01-01', 'YYYY-MM-DD')),
PARTITION r2008 VALUES LESS THAN (TO_DATE('2009-01-01', 'YYYY-MM-DD')),
PARTITION r2009 VALUES LESS THAN (TO_DATE('2010-01-01', 'YYYY-MM-DD')),
PARTITION r2010 VALUES LESS THAN (TO_DATE('2011-01-01', 'YYYY-MM-DD')),
PARTITION r2011 VALUES LESS THAN (TO_DATE('2012-01-01', 'YYYY-MM-DD'))
)
;
.......
ymd DATE
)
PARTITION BY RANGE (ymd) (
PARTITION r2007 VALUES LESS THAN (TO_DATE('2008-01-01', 'YYYY-MM-DD')),
PARTITION r2008 VALUES LESS THAN (TO_DATE('2009-01-01', 'YYYY-MM-DD')),
PARTITION r2009 VALUES LESS THAN (TO_DATE('2010-01-01', 'YYYY-MM-DD')),
PARTITION r2010 VALUES LESS THAN (TO_DATE('2011-01-01', 'YYYY-MM-DD')),
PARTITION r2011 VALUES LESS THAN (TO_DATE('2012-01-01', 'YYYY-MM-DD'))
)
;
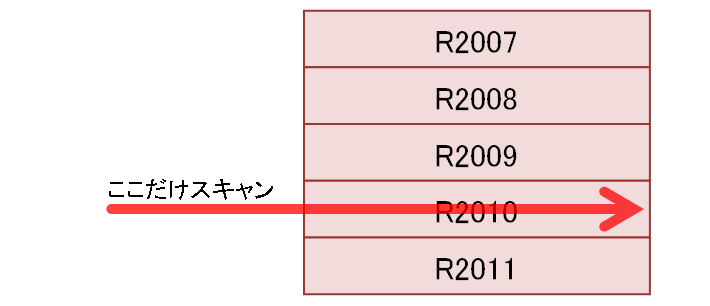
R2007 / R2008 / R2009 / R2011パーティションには条件にマッチする行が絶対にないので、R2010パーティションだけをスキャンすればよくなります。つまり、読込みデータ・ブロックの数が瞬時に80%も減りました。このように、条件にマッチする行が絶対にないパーティションにはそもそもアクセスしない機能をパーティション・プルーニングと呼びます。
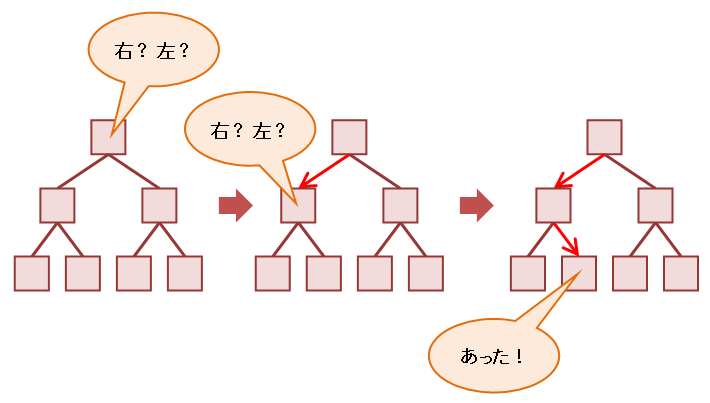
データベースの索引は一般的に書籍の索引にたとえられます。たとえば、ある本から「パーティション・プルーニング」という単語を探したい場合、1ページ目からくまなく探すよりも巻末の索引を使ったほうが速いでしょう。一方、「この本全体でいくつの読点(、)が使われているか」を数えるのであれば、索引ではなく1ページ目からくまなく探すことになります。しかし、「第3章でいくつの読点が使われているか」であれば、1ページ目から探さずに、誰しも自然に第3章だけを探すでしょう。それこそがパーティション・プルーニングです。
パーティション・プルーニングが行われたかどうかは、実行計画のPstart列 / Pstop列から分かります。
パーティション・プルーニングが行われたかどうかは、実行計画のPstart列 / Pstop列から分かります。
---------------------------------------- ----------------- |Id | Operation | Name | | Pstart| Pstop | ---------------------------------------- ----------------- | 0 | SELECT STATEMENT | | ...... | | | | 1 | SORT AGGREGATE | | | | | | 2 | PARTITION RANGE SINGLE| | | 3 | 3 | |*3 | TABLE ACCESS FULL | ORDERS | | 3 | 3 | ---------------------------------------- -----------------
では、どの列でパーティショニングを行えばよいのでしょうか。多くのデータウェアハウスでは日付列が存在し、日付ごとに集計したりすることが多いと思いますので、まずはその日付列でパーティショニングするのが良いでしょう。パーティション表はサブパーティションとして、もう1つの列でパーティショニングすることができます。サブパーティショニングされる列には「よく使われる条件列」かつ「パーティション・プルーニングの効果が高い列」が候補になります。たとえば売上げデータであれば店舗IDでのリスト・サブパーティションが候補になるでしょう。
パーティション・プルーニングとは何かが分かったところで、データ・ブロックについてもう少し深く見てみましょう。読込みブロック数が索引を使った場合とパーティショニングした場合で完全に同じ数であった場合、どちらのほうが高速なのでしょうか? これは一般的にパーティショニングのほうが高速になります。
索引はその構造上、必ず索引ブロックをひとつひとつ読んでいく必要があります。なぜなら、前のブロックを読まないと次にどのブロックを読まないといけないかが決まらないからです。
パーティション・プルーニングとは何かが分かったところで、データ・ブロックについてもう少し深く見てみましょう。読込みブロック数が索引を使った場合とパーティショニングした場合で完全に同じ数であった場合、どちらのほうが高速なのでしょうか? これは一般的にパーティショニングのほうが高速になります。
索引はその構造上、必ず索引ブロックをひとつひとつ読んでいく必要があります。なぜなら、前のブロックを読まないと次にどのブロックを読まないといけないかが決まらないからです。
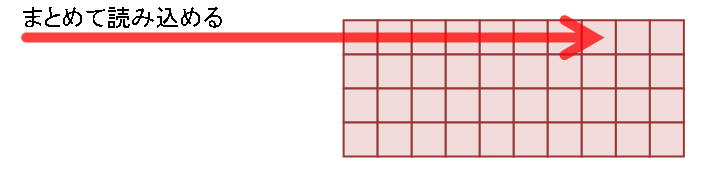
一方、パーティショニングの場合は表スキャンになるので、読み込むブロックの多くは連続しているため、初期化パラメータのDB_FILE_MULTIBLOCK_READ_COUNT単位にまとめて読むことができます。
ストレージ・ディスクのスループットは順次アクセスのときが最大で、ランダム・アクセスはそれに比べると大幅にスループットが落ちます。つまり、同じブロック数を読み込むのであっても、索引スキャンはランダム・アクセスになるため、順次アクセスできるパーティショニングを使ったほうが高速になるわけです。
メモリーはランダム・アクセスでも性能が落ちませんので、バッファ・キャッシュにブロックがキャッシュされている場合には性能差はありません。ただ、データウェアハウスのような大規模データをすべてキャッシュできるシステムはあまりないのが現実です。キャッシュ・ヒット率が悪い状況で索引に頼ると「キャッシュされていれば速いけど、されていないとものすごく遅い」という状況になってしまいます。それが、パーティションであれば「キャッシュされていれば速いけど、されていなくても比較的速い」というブレの少ないシステムになります。
必ず索引ブロックをひとつひとつ読んでいく必要があるということは、パラレル・クエリーもできないということを意味します。高性能なストレージを用意したものの、索引だと1つのサーバー・プロセスしか使えずに、そこがボトルネックになってしまってスループットが出ないという状況が起き得ますが、パーティションであればパラレル・クエリーできるのでストレージの性能を最大限引き出せます。
メモリーはランダム・アクセスでも性能が落ちませんので、バッファ・キャッシュにブロックがキャッシュされている場合には性能差はありません。ただ、データウェアハウスのような大規模データをすべてキャッシュできるシステムはあまりないのが現実です。キャッシュ・ヒット率が悪い状況で索引に頼ると「キャッシュされていれば速いけど、されていないとものすごく遅い」という状況になってしまいます。それが、パーティションであれば「キャッシュされていれば速いけど、されていなくても比較的速い」というブレの少ないシステムになります。
必ず索引ブロックをひとつひとつ読んでいく必要があるということは、パラレル・クエリーもできないということを意味します。高性能なストレージを用意したものの、索引だと1つのサーバー・プロセスしか使えずに、そこがボトルネックになってしまってスループットが出ないという状況が起き得ますが、パーティションであればパラレル・クエリーできるのでストレージの性能を最大限引き出せます。

索引のディスク使用量も無視できません。実データよりも索引のほうが容量を使っているシステムは少なくありませんが、パーティショニングであれば追加で必要な容量はありません。また、索引があるとデータ・ローディングなどの性能は確実に落ちますが、パーティショニングであれば性能への影響はほとんどなく、むしろ競合が減って高速になることもあります。データウェアハウスではパーティショニングを中心に考え、索引は補助的な使用にとどめると良いでしょう。
■パーティション・ワイズ結合
パーティション・プルーニングは読込みブロック数を減らすことでIO負荷を抑えて高速化できる手法でしたが、パーティション・ワイズ結合はCPUや一時領域の使用量、Oracle Real Application Clusters (Oracle RAC) 環境では加えてインターコネクトのネットワーク転送量を減らすことで高速化する手法で、パラレル・クエリーのときに使用できます。
たとえば何百万人もの顧客がいるECサイトで、2010年に合計10万円以上買い物した顧客数を調べたいとします。SQLで書くと以下のとおりです。
■パーティション・ワイズ結合
パーティション・プルーニングは読込みブロック数を減らすことでIO負荷を抑えて高速化できる手法でしたが、パーティション・ワイズ結合はCPUや一時領域の使用量、Oracle Real Application Clusters (Oracle RAC) 環境では加えてインターコネクトのネットワーク転送量を減らすことで高速化する手法で、パラレル・クエリーのときに使用できます。
たとえば何百万人もの顧客がいるECサイトで、2010年に合計10万円以上買い物した顧客数を調べたいとします。SQLで書くと以下のとおりです。
SELECT COUNT(*)
FROM (
SELECT c.customer_id, SUM(o.total_yen) total
FROM orders o, customers c
WHERE o.customer_id = c.customer_id
AND o.ymd BETWEEN '2010-01-01' AND '2010-12-31'
GROUP BY c.customer_id
)
WHERE total > 100000
;
FROM (
SELECT c.customer_id, SUM(o.total_yen) total
FROM orders o, customers c
WHERE o.customer_id = c.customer_id
AND o.ymd BETWEEN '2010-01-01' AND '2010-12-31'
GROUP BY c.customer_id
)
WHERE total > 100000
;
この場合、ORDERS表とCUSTOMERS表では何百万行もの結合がおこわなれ、CPUや一時領域などのリソースを大量に使用してしまいます。そこで、パーティション・ワイズ結合を行うために、ORDERS表とCUSTOMERS表を結合する列でハッシュ・パーティショニングします。
CREATE TABLE orders (
order_id NUMBER(20),
customer_id NUMBER(8),
.......
)
PARTITION BY HASH (customer_id)
PARTITIONS 32
;
CREATE TABLE customers (
customer_id NUMBER(8),
......
)
PARTITION BY HASH (customer_id)
PARTITIONS 32
;
order_id NUMBER(20),
customer_id NUMBER(8),
.......
)
PARTITION BY HASH (customer_id)
PARTITIONS 32
;
CREATE TABLE customers (
customer_id NUMBER(8),
......
)
PARTITION BY HASH (customer_id)
PARTITIONS 32
;
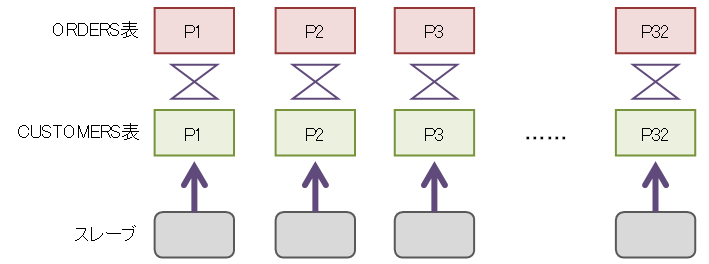
パラレル度32のパラレル・クエリーで先ほどのクエリーを実行した場合、パラレル・クエリーの1つのスレーブ・プロセスがORDERS表の1つのパーティションとCUSTOMERS表の1つのパーティションの読み込みを担当します。ORDERS表もCUSTOMERS表もCUSTOMER_ID列でハッシュ・パーティショニングされているため、ORDERS表の1つのパーティションに含まれるCUSTOMER_IDは、必ずCUSTOMERS表の特定の1つのパーティションにしか含まれません。つまり、結合の候補となる行数が32分1に減りました。また、1つのスレーブ・プロセスで結合が完了するようになったので、プロセス間通信も大幅に減りました。これにより、CPUや一時領域の使用が抑えられ、Oracle RACでインターノード・パラレル実行を行っている場合はインターコネクトのネットワーク転送量が抑えられることになります。
パーティション・ワイズ結合が行われた場合、実行計画に以下のように表れます。この4行の組み合わせがパーティション・ワイズ結合を意味します。
------------------------------------------ ----------------- | Id | Operation | Name | | Pstart| Pstop | ------------------------------------------ ----------------- ...... | 8 | PX PARTITION HASH ALL| | ...... | 1 | 32 | |* 9 | HASH JOIN | | | | | | 10 | TABLE ACCESS FULL | CUSTOMERS | | 1 | 32 | |* 11 | TABLE ACCESS FULL | ORDERS | | 1 | 32 |
なお、パーティションごとの偏りをなくすため、ハッシュ・パーティション数は2の累乗(2, 4, 8, 16, 32......) を必ず指定しましょう。また、ハッシュ・パーティショニングされる列は、データの偏りが小さいほうが望ましいです。
■パーティション・エクスチェンジ・ロード
パーティション表に対してローディングする場合、パーティション・エクスチェンジ・ロードという手法をとることができます。
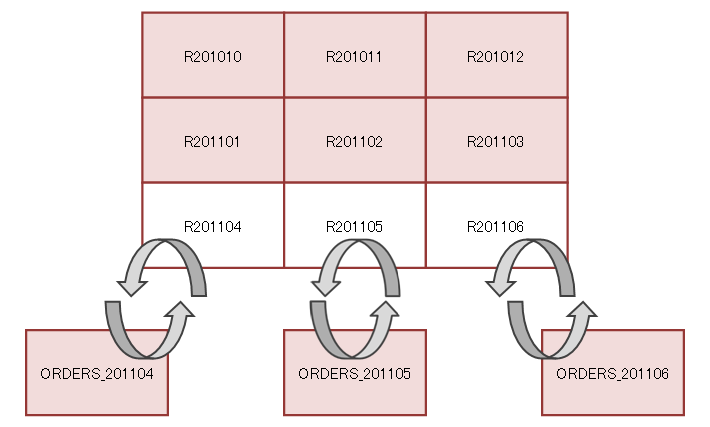
たとえば月ごとにレンジ・パーティショニングされているORDERS表に2011年4月から2011年6月のデータをローディングするとき、ORDERS表に直接ローディングするのではなく、一時的に用意したORDERS_201104表からORDERS_201106表までの3つの表にそれぞれロードします。ORDERS表にはR201104からR201106までの3つの空のパーティションを用意します。3つの表へのローディングが終わったら、これらの表の統計情報を取得し、必要あれば索引を作成します。すべての準備できたら、ALTER TABLE EXCHANGE PARTITION WITH 文でORDERS表の3つのパーティションと3つの表を交換します。WITHOUT VALIDATIONをつけていれば、この交換はデータ・ディクショナリを書き換えるだけなので瞬時に完了しますので、ORDERS表をほとんど触ることなく3カ月分のデータがロードできたことになります。以下のSQLではORDERS表のR201104パーティションとORDERS_201104表を交換しています。
■パーティション・エクスチェンジ・ロード
パーティション表に対してローディングする場合、パーティション・エクスチェンジ・ロードという手法をとることができます。
たとえば月ごとにレンジ・パーティショニングされているORDERS表に2011年4月から2011年6月のデータをローディングするとき、ORDERS表に直接ローディングするのではなく、一時的に用意したORDERS_201104表からORDERS_201106表までの3つの表にそれぞれロードします。ORDERS表にはR201104からR201106までの3つの空のパーティションを用意します。3つの表へのローディングが終わったら、これらの表の統計情報を取得し、必要あれば索引を作成します。すべての準備できたら、ALTER TABLE EXCHANGE PARTITION WITH 文でORDERS表の3つのパーティションと3つの表を交換します。WITHOUT VALIDATIONをつけていれば、この交換はデータ・ディクショナリを書き換えるだけなので瞬時に完了しますので、ORDERS表をほとんど触ることなく3カ月分のデータがロードできたことになります。以下のSQLではORDERS表のR201104パーティションとORDERS_201104表を交換しています。
ALTER TABLE orders
EXCHANGE PARTITION r201104 WITH orders_201104
WITHOUT VALIDATION
;
EXCHANGE PARTITION r201104 WITH orders_201104
WITHOUT VALIDATION
;
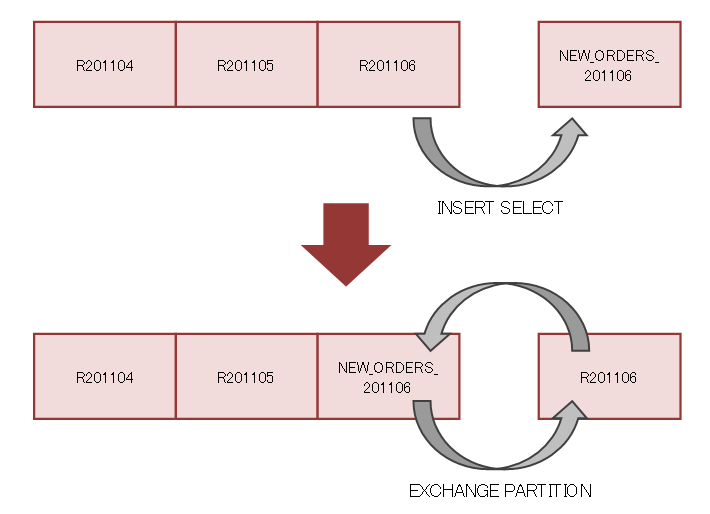
このEXCHANGE手法はローディング以外にも応用できます。たとえば1カ月分のデータをすべてUPDATEしないといけない場合、そのUPDATEされた行をCOMMIT前にSELECTすると、UNDOを見に行ってしまうため、SELECT性能に影響があります。そこで、UPDATEではなく一時的に用意された表に対してINSERT SELECTし、その一時的に用意された表をEXCHANGEします。これにより大量更新がSELECTに与える影響を抑えることができます。
このUPDATEをINSERT SELECTに書き換えるテクニックのように、SQLを書き換えることでパフォーマンスを高速化する方法を次回はもっと紹介したいと思います。
オラクルエンジニア通信:「【セミナー動画/資料】実践!! 大規模データベース管理 ~パーティション詳細編~」
次回は「SQLチューニング」に関する極意を伝授します!
オラクルエンジニア通信:「【セミナー動画/資料】実践!! 大規模データベース管理 ~パーティション詳細編~」
次回は「SQLチューニング」に関する極意を伝授します!

イラスト:岡戸妃里
Oracle Exadataリリース当初から、お客様のSQLやデータを使用したPoC (Proof of Concept) を実施し続け、本番稼働しているたくさんのシステムのパフォーマンス・チューニングを行ってきました。2010年には米オラクルの開発部門に所属し、米国のお客様のPoCを実施しつつ、そこから見えてきたOracle Databaseのパフォーマンス課題の解決に取り組みました。
日米どちらのPoCでも共通に、いつも思うことは「もっとシンプルでいいのに」ということです。Oracle Databaseにはたくさんのパラメーターやらなんやらがありますが、OLTPでは効果があっても、データウェアハウスではほとんど効果がないどころか、逆に遅くなるだけということも。そこでこの連載では、データウェアハウスのパフォーマンス・チューニングに本当に効果があることだけにポイントを絞ってご紹介していきたいと思います。これらのチューニング手法はExadataに限ったものではなく、Oracle Databaseすべてにおいて使えるものですので、多くの方の参考になればと思います。
日本オラクル株式会社 テクノロジー製品事業統括本部 技術本部 Exadata技術部
プリンシパルエンジニア 柴田竜典(しばたたつのり)