أتمتة المهام بأمان باستخدام RAG واختيار نماذج اللغة الكبيرة

مقدمة
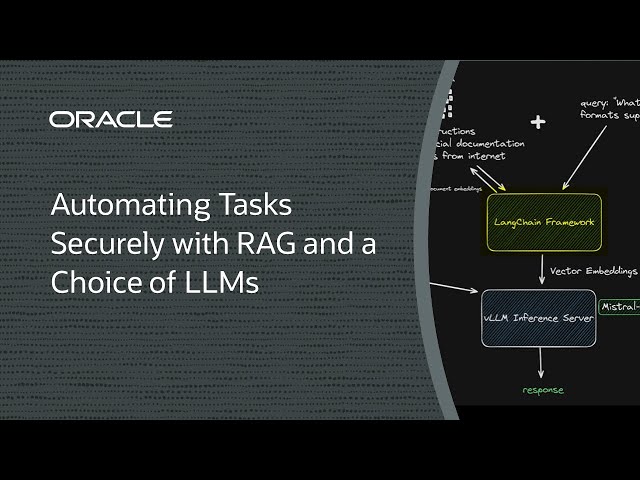
في محاولة لتبسيط المهام المتكررة أو أتمتتها بالكامل، لماذا لا تستعين بالذكاء الاصطناعي؟ قد يبدو استخدام نموذج الأساس لأتمتة المهام المتكررة أمرًا جذابًا، ولكنه قد يعرض البيانات السرية للخطر. الإنشاء المعزز للاستعادة (RAG) هو بديل للضبط الدقيق، مما يحافظ على عزل بيانات الاستدلال عن مجموعة النماذج.
نريد الحفاظ على فصل بيانات الاستدلال والنماذج الخاصة بنا—لكننا نريد أيضًا اختيار نموذج اللغة الكبير (LLM) الذي نستخدمه ووحدة معالجة رسومات قوية لتحقيق الكفاءة. تخيل لو كان بإمكانك القيام بكل هذا باستخدام وحدة معالجة رسومات واحدة فقط!
في هذا العرض التوضيحي، سنعرض كيفية نشر حل RAG باستخدام وحدة معالجة رسومات NVIDIA A10 واحدة؛ وإطار عمل مفتوح المصدر مثل LangChain أو LlamaIndex أو Qdrant أو vLLM؛ وLLM خفيف يبلغ طوله 7 مليارات معلمة من Mistral AI. إنه توازن رائع بين السعر والأداء ويحافظ على فصل بيانات الاستدلال مع تحديث البيانات حسب الحاجة.
العرض التوضيحي