Oracle Exadata Database Machine: Exadata Hybrid Columnar Compression (EHCC)
Por Alex Zaballa & Yenugula V. Ravikumar (OCM),
Postado em Março 2015
Revisado por Marcelo Pivovar - Solution Architect
Estimados colegas de tecnologia Oracle sejam bem-vindos a este artigo. Desta vez, vamos tratar de um tema muito comum, que em mais de uma ocasião passamos ou iremos passar. Estamos nos referindo ao problema de lidar com grandes quantidades de dados em um ambiente onde não há espaço suficiente.
Uma das possibilidades que a Oracle nos fornece, é lidar com esse tipo de cenário utilizando a compressão de dados chamada de Hybrid Columnar Compression, que desta vez iremos implementar em uma Oracle Exadata Machine. Vamos ver como podemos nos beneficiar deste recurso e também discutir os resultados da compressão entre os diferentes tipos que existem.
O Exadata Hybrid Columnar Compression é um recurso incluso no Exadata Storage Server. Este recurso proporciona um alto nível de compressão de dados sobre objetos em um banco de dados Oracle e oferece a capacidade de personalização do nível de compressão, dependendo se o ambiente é do tipo OLTP (leituras e gravações frequentes em dados não sequenciais) ou do tipo Datawarehousing (consultas frequentes para grandes quantidades de dados).
Este recurso permite que o banco de dados reduza o número de leituras e gravações físicas necessárias para utilizar uma tabela, por isso grandes quantidades de dados podem ser processados rapidamente sem gerar altas taxas de I/O.
É possível utilizar o Exadata Hybrid Columnar Compression em diversos níveis:
- Nível de Tabela
- Nível de Partição
- Nível de Tablespace
Existem dois tipos de Exadata Hybrid Columnar Compression:
Warehouse Compression
- Otimiza o desempenho de consultas.
- Indicado para aplicações do tipo Warehouse.
- Disponível em duas opções: Query High e Query Low.
Online Archival Compression
- Foco na compressão máxima dos dados.
- Adequado para dados que não mudam com frequência.
- Disponível em duas opções: Archive High e Archive Low.
Sintaxe para comprimir as tabelas:
Query Compression:
CREATE TABLE emp (…) COMPRESS FOR QUERY [LOW | HIGH];
Archive Compression:
CREATE TABLE emp (…) COMPRESS FOR ARCHIVE [LOW | HIGH];
Nota: Se a tabela que você deseja comprimir já existe, você pode usar um dos seguintes métodos:
- Package DBMS_REDEFINITION
- ALTER TABLE <NOME DA TABELA> MOVE COMPRESS FOR <TIPO DE COMPRESSÃO>;
Organização dos Dados:
As tabelas são organizados dentro de unidades de compressão (UC), como mostrado na imagem a seguir:
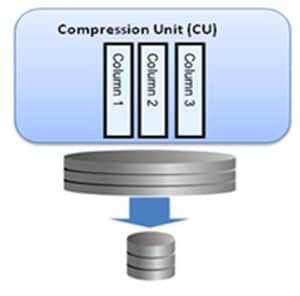
O tamanho de uma UC geralmente é de 32KB e obedece a seguinte fórmula: Tamanho de um UC = Tamanho de um bloco X Número de blocos dentro do UC
Exemplo:
Tamanho de um bloco: 8KB Número de blocos dentro de uma UC: 4 Tamanho de uma UC: 8KB * 4 = 32KB

Nota: A imagem mostra quatro blocos dentro da UC, porém isso pode mudar, porque a UC pode ter menos ou mais blocos dentro dele.
Características do Exadata Hybrid Columnar Compression (EHCC):
- As tabelas são organizadas em Unidades de Compressão (UC).
- As UCs são maiores do que os blocos do banco de dados.
- Com as UCs, os dados são organizados por colunas e não por registros.
- Cada coluna é comprimida separadamente.
- A redução média de armazenamento varia entre 10x e 15x.
- Existem casos em que foi alcançada a redução de uma tabela em 52x.
- A descompressão dos dados é realizada pelo Exadata Storage Server.
- Se a tabela for particionada, é permitido utilizar diferentes formas de compressão para a mesma tabela.
- Pode ser necessário comprimir a tabela novamente depois de algumas modificações, conforme nota do Metalink Nro 1332853.1 .
- Não é recomendado para tabelas que são modificados com frequência.
- Não é permitido em tabelas do tipo Index Organized Tables (IOT).
O Exadata Hybrid Columnar Compression suporta:
- Índices tipo B-Tree, Bitmap e Text.
- Materialized views.
- Operações de Smart Scan.
- Particionamento.
- Parallel queries.
- Data guard physical standby.
- Schema Evolution Support, Online, Metadata-Only Add/Drop Columns.
O ExadataHybrid Columnar Compression é suportado pelas seguintes soluções:
- Oracle Exadata.
- Oracle Exadata Expansion Rack.
- Pillar Axiom.
- ZFS Storage Appliance.
- Super Cluster.
Benefícios do Exadata Hybrid Columnar Compression:
- Storage.
- Disk Bandwidth.
- Flash Cache.
- DRAM Cache.
- Test Environment, Development Environment & DR Environment.
- Database Backups.
Estimativa de compressão:
Existe um “conselheiro” para a compressão na versão 11gR2 do banco de dados Oracle:
- DBMS_COMPRESSION
Este “conselheiro” irá coletar informações relacionadas com a compressão de dados, o que inclui estimativas do nível de compressão para uma determinada tabela, tanto para tabelas particionadas como para tabelas não-particionados. Isso vai ajudar o DBA a tomar uma melhor decisão para a compressão de seus objetos. Nota: Antes de executar o “conselheiro” de compressão, crie outro tablespace no banco de dados já que iremos criar tabelas temporárias e iremos realizar diversas leituras e escritas. Recomendamos a execução desta package em períodos de tempo em que não há muita carga de trabalho no banco de dados.
Exemplo de Exadata Hybrid Columnar Compression:
Em seguida, mostraremos um exemplo passo-a-passo de compressão e descompressão de objetos dentro de um banco de dados usando Exadata Hybrid Columnar Compression. O ambiente utilizado para o exemplo foi: Base de Dados: Oracle Enterprise Edition 11gR2 (11.2.0.3.0) Tipo de Exadata: Oracle Exadata Quarter Rack Sistema Operacional: Oracle Linux 5.5 x86-64
Identificando a tabela a ser comprimida:
SELECT segment_name,sum(bytes)/1024/1024 Size_MB
FROM user_segments
WHERE segment_name in ('EHCC_NOCOMPRESS')
GROUP BY segment_name;
SEGMENT_NAME Size_MB
-----------------------------------------------------------
EHCC_NOCOMPRESS 25487.0625
Criando a tabela usando o tipo de compressão QUERY HIGH:
SQL> CREATE TABLE EHCC_QUERY COMPRESS FOR QUERY HIGH AS SELECT * FROM EHCC_NOCOMPRESS;
Table created.
Criando a tabela usando o tipo de compressão ARCHIVE HIGH:
SQL> CREATE TABLE EHCC_ARCHIVE COMPRESS FOR ARCHIVE HIGH AS SELECT * FROM EHCC_NOCOMPRESS;
Table created.
Verificando o resultado:
SQL> SELECT segment_name,sum(bytes)/1024/1024 Size_MB
FROM user_segments
WHERE segment_name in ('EHCC_QUERY','EHCC_ARCHIVE')
GROUP BY segment_name;
SEGMENT_NAME Size_MB
------------------------------------------------------------
EHCC_ARCHIVE 848
EHCC_QUERY 1280
Comparação entre EHCC e no-EHCC:
SQL> select table_name,compression,compress_for
from user_tables
where table_name in ('EHCC_ARCHIVE', 'EHCC_QUERY', 'EHCC_NOCOMPRESS');
TABLE_NAME COMPRESS COMPRESS_FOR
------------ --------------- -------------------------
EHCC_ARCHIVE ENABLED ARCHIVE HIGH EHCC_QUERY
ENABLED QUERY HIGH EHCC_NOCOMPRESS DISABLED
Descomprimir uma tabela:
SQL> ALTER TABLE EHCC_QUERY MOVE NOCOMPRESS PARALLEL;
Table altered.
SQL> ALTER TABLE EHCC_ARCHIVE MOVE NOCOMPRESS PARALLEL;
Table altered.
Verificando os resultados de descompressão:
SQL> SELECT segment_name,sum(bytes)/1024/1024 Size_MB
FROM user_segments
WHERE segment_name in ('EHCC_QUERY','EHCC_ARCHIVE')
GROUP BY segment_name;
SEGMENT_NAME Size_MB
------------------------------------------------------------
EHCC_ARCHIVE 22947
EHCC_QUERY 22942
Mostrando que o número de registros dentro de tabelas não foi alterado:
SQL>SELECT COUNT(*) FROM EHCC_NOCOMPRESS;
COUNT(*) ---------------- 102938023
SQL> SELECT COUNT(*) FROM EHCC_QUERY;
COUNT(*) ---------------- 102938023
SQL> SELECT COUNT(*) FROM EHCC_ARCHIVE;
COUNT(*) ---------------- 102938023
Resultados
Compressão:
| Método de Compressão | Nome da Tabela | Tamanho (MB) | Tempo de criação (HH:MM:SI) |
| Sem compressão | EHCC_NOCOMRESS | 25487.0625 | |
| Query High | EHCC_QUERY | 1280 | 00:10:45.01 |
| Archive High | EHCC_ARCHIVE | 848 | 00:40:32.26 |
Descompressão:
| Nome da Tabela | Tamanho(MB) | Tempo de descompressão (HH:MM:SI) |
| EHCC_QUERY | 22942 | 00:03:08.42 |
| EHCC_ARCHIVE | 22947 | 00:02:57.58 |
Alex Zaballa, formado em Análise de Sistemas, é especialista em Banco de Dados Oracle com sólidos conhecimentos em Servidores de Aplicação e Sistemas Operacionais; trabalha com Oracle há 15 anos, é ORACLE ACE, certificado OCM Database 11G e conta com mais de 100 outras certificações em produtos da Oracle. Desde 2007 é funcionário da empresa Júpiter em Angola, alocado em um projeto no Ministério das Finanças. Alex também é fundador do Grupo de Usuários Oracle de Angola (GUOA) e membro do time OraWorld.
Yenugula Venkata Ravikumar é um DBA com mais de 15 anos de experiencia com Oracle e em ambientes de alta disponibilidade (RAC, Data Guard, dentre outros), tuning e desempenho, migrações, backup e recover, Oracle Exadata X2 e X3, é Expert em sistemasoperacionais tais como como AIX, HP-UX e Linux. Já participou como conferencista de Oracle pela India, ode mora atualmente. Obteve o titulo de "Oracle Certified Master (OCM 10g)" em 2009.
Este artigo foi revisto pela equipe de produtos Oracle e está em conformidade com as normas e práticas para o uso de produtos Oracle.