Maillage de données d'entreprise
Solutions, cas d'utilisation et études de cas
Qu'est-ce que le maillage de données ?
En matière de logiciel d'entreprise, le maillage de données est une nouvelle approche de réflexion sur les données reposant sur une architecture distribuée pour la gestion des données. L'idée est de rendre les données plus accessibles et disponibles pour les utilisateurs en connectant directement les propriétaires de données, les producteurs de données et les consommateurs de données. Le maillage de données permet d'améliorer les résultats commerciaux des solutions centrées sur les données et d'adopter des architectures de données modernes.
Du point de vue de l'entreprise, le maillage de données apporte de nouvelles idées à la réflexion sur les produits de données. En d'autres termes, il s'agit de considérer les données comme un produit qui exécute une tâche, par exemple, améliorer la prise de décision, aider à détecter la fraude ou aligner l'entreprise sur les changements dans le contexte de la chaîne d'approvisionnement. Pour créer des produits de données à forte valeur ajoutée, les entreprises doivent faire face aux changements de culture et de mentalité et s'engager à adopter une approche plus transversale de la modélisation de domaines d'activité.
Du côté de la technologie, le point de vue d'Oracle sur le maillage de données implique trois nouveaux aspects importants pour l'architecture orientée données :
- Des outils qui fournissent des produits de données en tant que collectes de données, événements de données et analyses de données
- Des architectures de données distribuées et décentralisées qui aident les entreprises qui choisissent de passer d'architectures monolithiques à une informatique multicloud et hybride, ou qui doivent opérer de manière décentralisée à l'échelle mondiale
- Des données en mouvement pour les entreprises qui ne peuvent pas dépendre uniquement de données centralisées, statiques et par lots, mais qui se tournent plutôt vers des registres de données orientés événements et des pipelines orientés flux en continu pour des événements de données en temps réel fournissant des analyses plus rapides
D'autres préoccupations importantes, telles que les outils en libre-service pour les utilisateurs non techniques et les puissants modèles de gouvernance des données fédérée, sont tout aussi importantes pour l'architecture du maillage de données que pour d'autres méthodes de gestion des données plus centralisées et classiques.
Un nouveau concept pour les données

Une approche de maillage de données est un changement de paradigme qui consiste à considérer les données comme un produit. Le maillage de données introduit des changements organisationnels et de processus dont les entreprises auront besoin pour gérer les données en tant qu'immobilisation tangible de l'entreprise. La perspective d'Oracle pour l'architecture du maillage de données nécessite une harmonisation sur les domaines de données organisationnels et analytiques.
Un maillage de données vise à lier les producteurs de données directement aux utilisateurs professionnels et, dans la mesure du possible, à retirer l'intermédiaire informatique des projets et les processus qui ingèrent, préparent et transforment les ressources de données.
Oracle a travaillé sur le maillage des données pour fournir à ses clients une plateforme capable de répondre à ces besoins technologiques émergents. Il s'agit notamment d'outils pour les produits de données, d'architectures décentralisées orientées événements et de modèles de transmission en continu pour les données en mouvement. Pour la modélisation de domaines de produits de données et d'autres préoccupations sociotechniques, Oracle s'aligne sur le travail effectué par l'expert du maillage de données, Zhamak Dehghani.
Les avantages du maillage de données
Investir dans un maillage de données peut offrir des avantages impressionnants, notamment :
- Une clarté totale sur la valeur des données grâce aux bonnes pratiques en matière de réflexion sur les produits de données.
- Plus de 99,999 % de disponibilité des données opérationnelles en utilisant des pipelines de données reposant sur des microservices pour la consolidation et les migrations de données.
- Cycle d'innovation 10 fois plus rapide, passant d'un ETL manuel et de traitement par lots à une transformation et un chargement continus (CTL).
- Plus de 70 % de réduction de l'ingénierie des données, des gains en CI/CD, des outils de pipeline de données sans code et en libre-service et un développement agile.
Le maillage des données est un état d'esprit, et plus encore
Le maillage des données en est encore à ses débuts en termes de maturité du marché. Bien que vous puissiez consulter divers contenus marketing sur une solution prétendant être du maillage de données, ces solutions ne correspondent souvent pas à l'approche ou aux principes fondamentaux.
Un bon maillage de données est un état d'esprit, un modèle organisationnel et une approche d'architecture de données d'entreprise comprenant des outils pour la prendre en charge. Une solution de maillage de données doit associer une réflexion sur les produits de données à une architecture de données décentralisée, une propriété des données orientée domaine, des données en mouvement distribuées, un accès en libre-service et une bonne gouvernance des données.
Un maillage de données n'est pas l'un des éléments suivants :
- Un produit fournisseur : il n'existe pas de produit logiciel de maillage de données unique.
- Un lac de données ou des data lake houses : ils sont complémentaires et peuvent faire partie d'un maillage de données plus important qui couvre plusieurs lacs, ponds et systèmes opérationnels d'enregistrement.
- Un catalogue de données ou de graphes : un maillage de données nécessite une implémentation physique.
- Un projet de conseil ponctuel : le maillage de données est un parcours et pas un projet unique.
- Un produit d'analyse en libre-service : les analyses en libre-service classiques, la préparation des données et la conversion des données peuvent faire partie d'un maillage de données, ainsi que d'autres architectures de données.
- Une data fabric : bien que lié conceptuellement, le concept de data fabric inclut plus largement une variété de styles d'intégration et de gestion des données, tandis que le maillage de données est plus associé à la décentralisation et aux modèles de conception orientés domaine.
En quoi le maillage des données est intéressant ?
Les architectures de données monolithiques du passé sont malheureusement complexes, coûteuses et rigides. Au cours des années, il est devenu évident que la plupart du temps et des coûts liés à la plateforme d'entreprise numérique, des applications à l'analyse, sont imputés aux efforts d'intégration. Par conséquent, la plupart des initiatives de plateforme ont échoué.
Bien que le maillage des données ne soit pas une solution miracle pour les architectures de données centralisées et monolithiques, les principes, pratiques et technologies de la stratégie de maillage des données sont conçus pour résoudre certains des objectifs de modernisation les plus urgents et non résolus pour les initiatives commerciales axées sur les données.
Voici certaines des tendances technologiques qui ont conduit à l'émergence du maillage de données en tant que solution :
- 70 à 80 % des transformations numériques échouent
- Les coûts d'exploitation des pannes de données augmentent
- La dépendance au cloud est réelle et peut devenir plus coûteuse
- Les lacs de données réussissent rarement et sont uniquement axés sur l'analyse
- L'essor des données distribuées impose la nécessité d'une architecture plus efficace et économique
- Le cloisonnement des services aggrave les problèmes de partage des données
- Les données sont le catalyseur de la compétitivité et il est essentiel de bien les gérer
Pour en savoir plus sur les raisons pour lesquelles le maillage de données est nécessaire aujourd'hui, consultez le document original de Zhamak Dehghani rédigé en 2019 : How to Move Beyond a Monolithic Data Lake to a Distributed Data Mesh.
La définition du maillage de données
La stratégie décentralisée derrière le maillage de données vise à traiter les données comme un produit en créant une infrastructure de données en libre accès pour rendre les données plus accessibles aux utilisateurs professionnels.
Axé sur les résultats
Réflexion sur les produits de données- Changement d'état d'esprit du point de vue du consommateur de données
- Les propriétaires de domaine de données sont responsables des KPI/SLA de produit de données
- Vocabulaire partagé en matière de données et de technologie de maillage
- Il n'y a plus de « données pour lesquelles on se rejette la responsabilité »
- Capturez des événements de données en temps réel directement à partir des systèmes d'enregistrement et permettez aux pipelines en libre-service de fournir des données en cas de nécessité
- Une capacité essentielle pour favoriser la décentralisation des données et des produits de données alignés sur la source
Rejette l'architecture informatique monolithique
Architecture décentralisée- Une architecture conçue pour les données, les services et les clouds décentralisés
- Conçues pour gérer tous les types d'événements, les formats et la complexité
- Traitement des flux par défaut, traitement par lots par exception
- Conçue pour responsabiliser les développeurs et connecter directement les consommateurs de données aux producteurs de données
- Sécurité, validation, provenance et transparence intégrées
Fonctionnalités Oracle pour alimenter un maillage de données
Lorsque la théorie s'oriente vers la pratique, il est nécessaire de déployer des solutions d'entreprise pour les données stratégiques. C'est là qu'Oracle peut fournir une gamme de solutions fiables pour mettre en place un maillage de données d'entreprise.
Créer et partager des produits de données
- Les collections de données multi-modèles avec la base de données convergée d'Oracle permettent de proposer des produits de données changeant de forme aux formats requis par les consommateurs de données
- Produits de données en libre-service comme applications ou API, avec Oracle APEX Application Development et Oracle REST Data Services pour un accès et un partage simples de toutes les données
- Point d'accès unique pour les requêtes SQL ou la virtualisation des données avec Oracle Cloud SQL et Big Data SQL
- Produits de données pour le machine learning avec la plateforme de science des données d'Oracle, Oracle Cloud Infrastructure (OCI) Data Catalog et la plateforme de données cloud d'Oracle pour les data lake houses
- Produits de données harmonisés avec la source en tant qu'événements en temps réel, alertes de données et services d'événements de données brutes avec Oracle Stream Analytics
- Produits de données en libre-service harmonisés avec le client dans une solution Oracle Analytics Cloud complète
Exploitez une architecture de données décentralisée
- CI/CD de type service de maillage agile pour les conteneurs de données utilisant des bases de données enfichables Oracle avec Kubernetes, Docker ou natives du cloud avec Autonomous Database
- Synchronisation des données entre régions, multiclouds et cloud hybrides avec les microservices Oracle GoldenGate et Veridata, pour une topologie Fabric de transactions actif-actif fiable
- Exploitez la plupart des événements de données liés aux applications, aux processus métier et à l'Internet des objets (IoT) avec Oracle Integration Cloud et Oracle Internet of Things Cloud
- Utilisez les files d'attente d'événements Oracle GoldenGate ou Oracle Transaction Manager for Microservices pour le sourcing d'événements de microservices ou l'inclusion en temps réel à Kafka et aux lacs de données
- Apportez des modèles de conception décentralisés axés sur le domaine à votre maillage de services avec Oracle Verrazzano, Helidon et Graal VM
3 attributs principaux d'un maillage de données
Le maillage de données est plus qu'un simple mot technologique à la mode. Il s'agit d'un nouvel ensemble de principes, de pratiques et de capacités technologiques qui rendent les données plus accessibles et plus faciles à explorer. Le concept de maillage des données se distingue des anciennes générations d'approches et d'architectures d'intégration des données en encourageant le passage des architectures de données d'entreprise géantes et monolithiques du passé à une architecture moderne, distribuée et décentralisée axée sur les données, tournée vers l'avenir. Le concept de maillage de données repose sur les attributs principaux suivants :
1.Réflexion sur les produits de données
La première étape la plus importante à suivre pour mettre en place un maillage de données est d'adopter une nouvelle façon de penser. La volonté d'inclure les pratiques acquises en matière d'innovation est le tremplin vers une modernisation réussie de l'architecture de données.
En voici les domaines :
- Le design thinking, une méthodologie éprouvée pour résoudre les problèmes non résolus, appliquée aux domaines de données d'entreprise pour la création de produits de données exceptionnels
- La théorie « Jobs to be done », appliquant une innovation centrée sur le client dont le processus est axé sur les résultats pour s'assurer que les produits de données d'entreprise résolvent des problèmes commerciaux concrets

Les méthodologies de design thinking apportent des techniques éprouvées qui aident à briser les cloisons des services au sein de l'entreprise qui bloquent fréquemment l'innovation transversale. La théorie « Jobs to be done » est la base essentielle pour concevoir des produits de données qui répondent à des objectifs spécifiques des consommateurs finaux - ou à des travaux à effectuer - elle définit le but du produit.
Bien que l'approche des produits de données ait initialement émergé de la communauté de la data science, elle est maintenant appliquée à tous les aspects de la gestion des données. Au lieu de créer des architectures technologiques monolithiques, le maillage de données se concentre sur les consommateurs de données et les résultats commerciaux.
Bien que la réflexion sur les produits de données puisse s'appliquer à d'autres architectures de données, il s'agit d'une partie essentielle d'un maillage de données. Si vous souhaitez accéder à des exemples pragmatiques sur l'application de la réflexion sur les produits de données, l'équipe d'Intuit a rédigé une analyse détaillée de leurs expériences.
Produits de données
Les produits de toute nature, des matières premières aux articles de votre magasin local, sont produits en tant qu'actifs de valeur, destinés à être consommés et ont un travail spécifique à faire. Les produits de données peuvent prendre diverses formes, selon le domaine d'activité ou le problème à résoudre, et peuvent inclure :
- Analyses : rapports et tableaux de bord historiques/en temps réel
- Ensembles de données : collectes de données dans différentes formes/formats
- Modèles : objets de domaine, modèles de données, fonctionnalités de machine learning
- Algorithmes : modèles de ML, scoring, règles métier
- Services de données et API : documents, charges utiles, API REST, etc.
Un produit de données est créé pour la consommation, généralement détenu en dehors du service informatique et nécessite le suivi d'attributs supplémentaires, tels que :
- Carte des parties prenantes : qui possède, créé et utilise ce produit ?
- Packaging et documentation : comment ce produit est-il utilisé ? Comment est-il étiqueté ?
- Objectif et valeur : quelle est la valeur implicite/explicite du produit ? Existe-t-il un amortissement dans le temps ?
- Qualité et cohérence : quels sont les indicateurs clés de performances et les contrats de niveau de service d'utilisation ? Est-ce vérifiable ?
- Provenance, cycle de vie et gouvernance : les données sont-elles fiables et explicables ?
2. Architecture décentralisée des données

Les systèmes informatiques décentralisés sont une réalité moderne, et avec l'essor des applications SaaS et de l'infrastructure de cloud public (IaaS), la décentralisation des applications et des données est appelé à durer. Les architectures logicielles d'applications passent de monolithes centralisés du passé aux microservices distribués (un maillage de services). L'architecture des données suivra la même tendance vers la décentralisation, les données devenant plus distribuées sur une plus grande variété de sites physiques et sur de nombreux réseaux. Nous appelons cela un maillage de données.
Qu'est-ce qu'un maillage ?
Un maillage est une topologie de réseau qui permet à un grand groupe de noeuds non hiérarchiques de collaborer.
Voici quelques exemples courants de technologie :
- WiFiMesh : de nombreux noeuds travaillent ensemble pour une meilleure couverture
- ZWave/Zigbee : réseaux de dispositifs domestiques intelligents à faible énergie
- Maillage 5G : connexions de cellules plus fiables et résilientes
- Starlink : maillage par satellite à large bande à l'échelle mondiale
- Maillage de services : moyen de fournir des contrôles unifiés sur les microservices décentralisés (logiciels applicatifs)
Le maillage de données est aligné sur ces concepts de maillage et fournit un moyen décentralisé de distribuer des données sur des réseaux virtuels/physiques et sur de grandes distances. Les architectures monolithiques d'intégration de données héritées, telles que les outils ETL et de fédération de données, et plus récemment encore, les services de cloud public, tels qu'AWS Glue, nécessitent une infrastructure hautement centralisée.
Une solution complète de maillage de données doit pouvoir fonctionner dans une structure multicloud, couvrant potentiellement les systèmes sur site, les clouds publics multiples et même les réseaux périphériques.
Sécurité distribuée
Dans un monde où les données sont fortement distribuées et décentralisées, le rôle de la sécurité de l'information est primordial. Contrairement aux systèmes monolithes très centralisés, les systèmes distribués doivent déléguer les activités nécessaires pour authentifier et autoriser différents utilisateurs à différents niveaux d'accès. Il est difficile de déléguer en toute sécurité la responsabilité sur les réseaux.
Voici quelques remarques à prendre en compte :
- Chiffrement au repos : données/événements écrits dans le stockage
- Authentification distribuée : pour les services et les banques de données, tels que mTLS, les certificats, SSO, les banques de clés secrètes et les coffres de données
- Chiffrement en mouvement : données/événements circulant en mémoire
- Gestion des identités : services de type LDAP/IAM, interplates-formes
- Autorisations distribuées : pour que les adresses de service protègent les données
Par exemple : Open Policy Agent (OPA) sidecar pour placer le point de décision de stratégie (PDP) dans le cluster container/K8S où l'adresse de microservice est traitée. LDAP/IAM peut être n'importe quel service compatible JWT. - Masquage déterministe : pour brouiller les informations d'identification personnelle de manière fiable et cohérente
La sécurité au sein de n'importe quel système informatique peut être complexe, et il est encore plus difficile de fournir une haute sécurité au sein des systèmes distribués. Il s'agit toutefois de problèmes pouvant être résolus.
Domaines de données décentralisés
Un principe fondamental du maillage de données est la notion de distribution de la propriété et de la responsabilité. La bonne pratique consiste à fédérer la propriété des produits et des domaines de données avec les personnes d'une entreprise qui sont les plus proches des données. En pratique, cela peut s'aligner sur des données source (par exemple, des sources de données brutes, telles que les systèmes opérationnels d'enregistrement/applications) ou sur des données analytiques (par exemple, typiquement des données composites ou agrégées formatées pour une utilisation facile par les consommateurs de données). Dans les deux cas, les producteurs et les consommateurs des données s'harmonisent souvent sur les unités opérationnelles plutôt que sur les organisations informatiques.
Les anciennes méthodes d'organisation des domaines de données tombent régulièrement dans le piège de s'aligner sur les solutions technologiques, telles que les outils ETL, les data warehouses, les data lakes ou l'organisation structurelle d'une entreprise (ressources humaines, marketing et autres secteurs d'activité). Il serait préférable lorsqu'un problème métier survient, que les domaines de données s'alignent sur la portée du problème en cours de résolution, au contexte d'un processus métier particulier ou à la famille d'applications dans un domaine de problème spécifique. Dans les grandes entreprises, ces domaines de données sont généralement répartis entre les organisations internes et les empreintes technologiques.
La décomposition fonctionnelle des domaines de données est prioritaire dans le maillage de données. Diverses méthodologies de décomposition des données pour la modélisation de domaines peuvent être adaptées à l'architecture du maillage de données, y compris la modélisation classique du data warehouse (comme Kimball et Inmon) ou la modélisation du coffre-fort de données, mais la méthodologie la plus courante actuellement testée dans l'architecture du maillage de données est la conception pilotée par domaine (DDD). L'approche DDD est née de la décomposition fonctionnelle des microservices et s'applique maintenant dans un contexte de maillage de données.
3.Données dynamiques en mouvement
Oracle a permis de mettre en avant l'importance des données en mouvement en tant qu'ingrédient clé d'un maillage de données moderne. Les données en mouvement sont essentielles pour sortir le maillage des données de l'univers historique du traitement par lots centralisé et monolithique. Les capacités des données en mouvement répondent à plusieurs questions fondamentales relatives au maillage de données, telles que :
- Comment accéder aux produits de données harmonisés avec la source en temps réel ?
- Quels outils peuvent fournir les moyens de distribuer des transactions de données fiables sur un maillage de données physiquement décentralisé ?
- Lorsque je dois rendre les événements de données disponibles en tant qu'API de produit de données, que puis-je utiliser ?
- Pour les produits de données analytiques qui doivent être constamment à jour, comment puis-je m'aligner sur les domaines de données et garantir la confiance et la validité ?
Ces questions ne sont pas seulement une question de détails d'implémentation, elles sont d'une importance centrale pour l'architecture de données elle-même. Une conception orientée domaine pour les données statiques utilisera des techniques et des outils différents d'un processus dynamique de données en mouvement de la même conception. Par exemple, dans les architectures de données dynamiques, le registre de données est la source centrale d'informations fiables pour les événements de données.
Livres de données orientés événements

Les livres sont un composant fondamental du fonctionnement d'une architecture de données distribuée. Comme pour un livre comptable, un livre de données enregistre les transactions au fur et à mesure.
Lorsque nous distribuons le livre, les événements de données deviennent réexécutables dans n'importe quel emplacement. Certains livres ressemblent un peu à un enregistreur de vol d'avion utilisé pour la haute disponibilité et la reprise après sinistre.
Contrairement aux banques de données centralisées et monolithiques, les livres distribués sont spécialement conçus pour assurer le suivi des événements atomiques et/ou des transactions qui surviennent dans d'autres systèmes (externes).
Un maillage de données n'est pas qu'un seul type de livre. En fonction des cas d'utilisation et des exigences, un maillage de données peut utiliser différents types de livres de données basés sur les événements, notamment :
- Livre d'événements à usage général, tel que Kafka ou Pulsar
- Livre d'événements de données : outils de CDC/réplication distribués
- Middleware de messagerie, notamment ESB, MQ, JMS et AQ
- Livre de blockchain pour des transactions sécurisées, immuables et multipartites
Ensemble, ces livres peuvent agir comme une sorte de journal d'événements durable pour l'ensemble de l'entreprise, fournissant une liste d'événements de données en cours d'exécution sur les systèmes d'enregistrement et d'analyse.
Flux de données multi-langage

Les flux de données multi-langage n'ont jamais été aussi présents. Ils varient en fonction des types d'événement, des données traitées et de la sémantique des transactions. Un maillage de données doit prendre en charge les types de flux nécessaires pour divers workloads de données d'entreprise.
Evénements simples :
Base64 / Evénements JSON-bruts, sans schéma
- Evénements de télémétrie brute dispersés
Evénements de journalisation d'application de base/Internet of Things (IoT) :
- JSON/Protobuf : peut avoir un schéma
- Protocoles spécifiques à MQTT-IoT
Evénements de processus métier d'application :
- Evénements SOAP/REST-XML/XSD, JSON
- B2B : protocoles et normes d'échange
Evénements/transactions de données :
- Enregistrements de modification logique : LCR, SCN, URID
- Limites cohérentes : validations et opérations
Traitement de flux de données
Le traitement de flux consiste à manipuler les données dans un flux d'événements. Contrairement aux fonctions lambda, le processeur de flux maintient l'état des flux de données dans une fenêtre de temps et peut appliquer des requêtes analytiques beaucoup plus avancées sur les données.
- Seuils, alertes et surveillance de la télémétrie
- Fonctions RegEx, mathématiques/logiques et concaténation
- Enregistrement par enregistrement, substitutions et masquage
Filtrage des données de base :
ETL simple :
CEP et ETL complexe :
- Traitement d'événements complexes (CEP)
- Traitement DML (ACID) et groupes de tuples
- Agrégats, recherches, jointures complexes
Analyse de flux :
- Analyses de séries temporelles et fenêtres de temps personnalisées
- Géospatial, machine learning et IA intégrée
Autres attributs et principes importants
Bien sûr, il existe plus de trois attributs d'un maillage de données. Nous nous sommes concentrés sur les trois points ci-dessus comme un moyen d'attirer l'attention sur les attributs qu'Oracle pense être certains des aspects nouveaux et uniques de l'approche innovante du maillage de données.
Les autres attributs importants du maillage de données sont les suivants :
- Outils en libre-service : le maillage des données rejoint la tendance générale de la gestion des données vers le libre-service. Les développeurs citoyens devront de plus en plus être issus des rangs des propriétaires de données.
- Gouvernance des données : le maillage des données a également adopté la tendance de longue date vers un modèle de gouvernance fédérée plus formalisé, tel que défendu par les directeurs des données, les architectes de données et les fournisseurs de catalogues de données depuis de nombreuses années.
- Utilisabilité des données : conformément aux principes du maillage de données, il existe de nombreux travaux de base pour s'assurer que les produits de données sont hautement utilisables. Les principes applicables aux produits de données concerneront les données qui sont précieuses, utilisables et susceptibles d'être partagées.
7 cas d'utilisation du maillage de données
Un maillage de données réussi satisfait les cas d'utilisation pour les domaines de données opérationnels et analytiques. Les sept cas d'utilisation suivants illustrent l'étendue des fonctionnalités qu'un maillage de données apporte aux données d'entreprise.
En intégrant les données et analyses opérationnelles en temps réel, les entreprises peuvent prendre de meilleures décisions opérationnelles et stratégiques.MIT Sloan School of Management
1. Modernisation des applications
Au-delà de la migration directe des architectures de données monolithiques vers le cloud, de nombreuses entreprises cherchent également à supprimer leurs anciennes applications centralisées et à passer à une architecture applicative de microservices plus moderne.


Mais les monolithes d'applications héritées dépendent généralement de bases de données massives, ce qui soulève la question de savoir comment mettre en œuvre le plan de migration pour réduire les perturbations, les risques et les coûts. Un maillage de données peut fournir une capacité informatique opérationnelle importante aux clients qui effectuent des transitions par étapes entre une architecture monolithique et une architecture maillée. Par exemple :
- Déchargement par sous-domaine des transactions de base de données, tel que le filtrage des données par « contexte limité »
- Réplication bidirectionnelle des transactions pour les migrations progressives
- Synchronisation interplate-forme, par exemple mainframe vers DBaaS
Dans le jargon des architectes de microservices, cette approche utilise une boîte d'envoi de transaction bidirectionnelle pour activer le modèle Figuier étrangleur, un contexte limité à la fois.
2. Disponibilité et continuité des données

Les applications stratégiques nécessitent des KPI et des contrats de niveau de service très élevés en ce qui concerne la résilience et la continuité. Que ces applications soient monolithiques, de microservices ou intermédiaires, elles ne peuvent pas tomber en panne.
Pour les systèmes stratégiques, un modèle de données distribué à cohérence éventuelle n'est généralement pas acceptable. Toutefois, ces applications doivent fonctionner dans de nombreux datacenters. Cela soulève la question de la continuité d'activité : « Comment exécuter mes applications sur plusieurs datacenters tout en garantissant des données correctes et cohérentes ? »
Que les architectures monolithiques utilisent des ensembles de données distribués ou que les microservices soient configurés pour la haute disponibilité intersite, le maillage de données offre des données correctes et à grande vitesse, quelle que soit la distance.
Un maillage de données peut fournir la base pour des données décentralisées, mais 100 % correctes sur tous les sites. Par exemple :
- Transactions logiques à très faible latence (interplate-forme)
- Garanties compatibles ACID de données correctes
- Résolution des conflits multiactive et bidirectionnelle
3. Boîte d'envoi de transaction et de sourcing d'événements


Une plateforme moderne de type maillage de services utilise des événements pour l'échange de données. Plutôt que de dépendre du traitement par lots au niveau des données, les données traitées circulent en permanence lorsque des événements se produisent dans l'application ou la banque de données.
Pour certaines architectures, les microservices doivent mutuellement échanger des charges utiles de données. D'autres modèles nécessitent un échange entre des applications monolithiques ou des banques de données. La question suivante se pose : « Comment échanger de manière fiable les charges utiles de données des microservices entre mes applications et banques de données ? »
Un maillage de données peut fournir la technologie de base pour l'échange de données centré sur les microservices. Par exemple :
- Du microservice au microservice au sein d'un même contexte
- Du microservice au microservice dans tous les contextes
- Monolithe vers/depuis le microservice
Les modèles de microservices, tels que le sourcing d'événements, le CQRS et les boîtes d'envoi de transactions, sont des solutions couramment comprises. Un maillage de données fournit les outils et les structures permettant de rendre ces modèles répétitifs et fiables à grande échelle.
4. Intégration basée sur les événements
Au-delà des modèles de conception de microservices, le besoin d'intégration d'entreprise s'étend à d'autres systèmes informatiques, tels que les bases de données, les processus métier, les applications et les appareils physiques de tous types. Un maillage de données constitue la base de l'intégration des données en mouvement.
Les données en mouvement sont généralement basées sur les événements. Une action utilisateur, un événement de périphérique, une étape de processus ou une validation de banque de données peuvent tous lancer un événement avec une charge utile de données. Ces données utiles sont cruciales pour l'intégration des systèmes Internet des objets (IoT), des processus métier et des bases de données, des data warehouses et des data lakes.
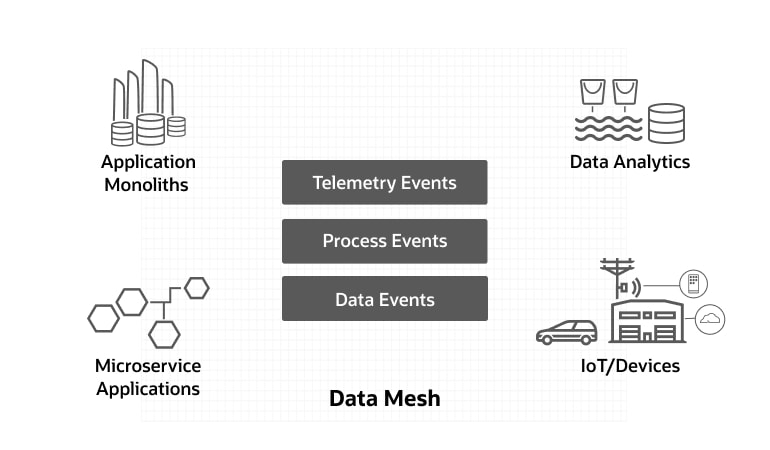
Un maillage de données fournit la technologie de base pour une intégration en temps réel dans l'ensemble de l'entreprise. Par exemple :
- Connexion d'événements réels relatifs aux appareils aux systèmes informatiques
- Intégration des processus métier dans les systèmes ERP
- Alignement des bases de données opérationnelles avec les banques de données analytiques
Les grandes entreprises disposeront naturellement d'un mélange d'anciens et de nouveaux systèmes, de monolithes et de microservices, de banques de données opérationnelles et analytiques. Un maillage de données peut aider à unifier ces ressources à partir de différents domaines commerciaux et de données.
5. Ingestion en continu (pour l'analytique)

Les banques de données analytiques peuvent inclure des data marts, des data warehouses, des cubes OLAP, des data lakes et des technologies de data lakehouse.
En règle générale, il n'existe que deux moyens d'importer des données :
- Chargement par lots/micro-lots sur un planificateur de temps
- Ingestion de flux : chargement continu d'événements de données
Un maillage de données constitue la base d'une fonctionnalité d'ingestion de flux de données. Par exemple :
- Evénements de données provenant de bases de données ou de banques de données
- Evénements d'appareil provenant de la télémétrie d'appareils physiques
- Journalisation des événements d'application ou des transactions métier
L'inclusion d'événements par flux peut réduire l'impact sur les systèmes sources, améliorer la fidélité des données (important pour la data science) et permettre des analyses en temps réel.
6. Flux de données en continu

Une fois ingérés dans les banques de données analytiques, il est généralement nécessaire que les pipelines de données préparent et transforment les données sur différentes phases ou zones de données. Ce processus d'amélioration des données est souvent nécessaire pour les produits de données analytiques en aval.
Un maillage de données peut fournir une couche de pipeline de données gérée de manière indépendante qui fonctionne avec les banques de données analytiques, afin de fournir les services de base suivants :
- Détection et préparation des données en libre-service
- Gouvernance des ressources de données dans tous les domaines
- Préparation et transformation des données vers les formats de produits de données requis
- Vérification des données par une stratégie garantissant la cohérence
Ces pipelines de données doivent pouvoir fonctionner sur différentes banques de données physiques (telles que des data marts, warehouses ou lakes) ou en tant que flux de données de propagation au sein de plateformes de données analytiques prenant en charge les flux de données, telles qu'Apache Spark et d'autres technologies de data lakehouse.
7. Analyses de flux

Les événements se déroulent en permanence. L'analyse des événements d'un flux peut être cruciale pour comprendre ce qui se passe d'un moment à un autre.
Ce type d'analyse basée sur des séries temporelles des flux d'événements en temps réel peut être important pour les données d'appareils IoT réels et pour comprendre ce qui se passe dans vos data centers informatiques ou dans les transactions financières, telles que la surveillance de la fraude.
Un maillage de données complet comprend les fonctionnalités de base permettant d'analyser des événements de toutes sortes, dans de nombreux types de fenêtres temporelles d'événement. Par exemple :
- Analyse de flux d'événements simple (événements Web)
- Surveillance de l'activité de l'entreprise (événements SOAP/REST)
- Traitement d'événements complexes (corrélation multi-flux)
- Analyse des événements de données (sur les transactions de base de données/ACID)
Comme les pipelines de données, les analyses de diffusion en continu peuvent s'exécuter dans une infrastructure de data lakehouse établie, ou encore séparément, en tant que services natifs du cloud.
Atteignez une valeur maximale en exploitant un maillage commun sur l'ensemble du domaine de données
Ceux qui sont à la pointe de l'intégration des données recherchent l'intégration de données opérationnelles et analytiques en temps réel à partir d'un ensemble diversifié de banques de données résilientes. Les innovations ont été constantes et rapides à mesure que l'architecture de données évolue dans les analyses de flux de données. La haute disponibilité opérationnelle a conduit à des analyses en temps réel, et l'automatisation de l'ingénierie des données simplifie la préparation des données, permettant ainsi aux data scientists et aux analystes de disposer d'outils en libre accès.
Récapitulatif des cas d'utilisation du maillage de données

Créer un maillage opérationnel et analytique sur l'ensemble du parc de données
Mettre toutes ces fonctionnalités de gestion de données au service d'une architecture unifiée aura un impact sur chaque consommateur de données. Un maillage de données contribuera à l'amélioration de vos systèmes globaux d'enregistrement et d'engagement afin de fonctionner de manière fiable en temps réel, en harmonisant ces données en temps réel avec les responsables des branches d'activité, les data scientists et vos clients. Il simplifie également la gestion des données pour vos applications de microservices de nouvelle génération. À l'aide de méthodes et d'outils analytiques innovants, vos utilisateurs finaux, analystes et data scientists seront encore plus réactifs face à la demande des clients et aux menaces concurrentielles. Pour lire un exemple bien documenté, consultez les objectifs et résultats d'Intuit.
Bénéficiez d'un maillage de données sur les projets ponctuels
Lorsque vous adoptez une nouvelle mentalité sur les produits de données et votre modèle opérationnel, il est important de développer votre expérience de chacune de ces technologies. Dans votre parcours de maillage de données, vous pouvez obtenir des avantages incrémentiels en faisant évoluer votre architecture de données rapide vers les analyses de flux de données, en convertissant vos investissements opérationnels à haute disponibilité en analyses en temps réel et en fournissant des analyses en temps réel et en libre-service à vos data scientists et analystes de données.
Comparaison et opposition
| Structure de données | Intégration du développement d'applications | Banque de données analytique | |||||
|---|---|---|---|---|---|---|---|
| Maillage de données | Data integration | Catalogue de métadonnées | Microservices | Messagerie | Data lakehouse | DW distribué | |
| Personnes, processus et méthodes : | |||||||
| Orientation produits de données | disponible |
disponible |
disponible |
1/4 offres |
1/4 offres |
3/4 offres |
3/4 offres |
| Attributs d'architecture technique : | |||||||
| Architecture distribuée | disponible |
1/4 offres |
3/4 offres |
disponible |
disponible |
1/4 offres |
3/4 offres |
| Livres basés sur les événements | disponible |
non disponible |
1/4 offres |
disponible |
disponible |
1/4 offres |
1/4 offres |
| Support ACID | disponible |
disponible |
non disponible |
non disponible |
3/4 offres |
3/4 offres |
disponible |
| Orienté flux | disponible |
1/4 offres |
non disponible |
non disponible |
1/4 offres |
3/4 offres |
1/4 offres |
| Axé sur les données analytiques | disponible |
disponible |
disponible |
non disponible |
non disponible |
disponible |
disponible |
| Axé sur les données opérationnelles | disponible |
1/4 offres |
disponible |
disponible |
disponible |
non disponible |
non disponible |
| Maillage physique et logique | disponible |
disponible |
non disponible |
1/4 offres |
3/4 offres |
3/4 offres |
1/4 offres |
Résultats commerciaux
Avantages globaux
Cycles d'innovation plus rapides et axés sur les données
Réduction des coûts pour les opérations de données stratégiques
Résultats opérationnels
Fluidité des données multicloud
: libérez le capital de données pour qu'il circule librement
Partage de données en temps réel
- Ops-vers-Ops et Ops-vers-analyses
Services de données basés sur la localisation et la périphérie
- corréler les événements de données/d'appareils IRL
Échange de données de microservices de confiance
- sourcing d'événements avec des données correctes
- DataOps et CI/CD pour les données
Continuité ininterrompue
- >99,999 % de contrats de niveau de service disponibles
- migrations vers le cloud
Résultats analytiques
Automatiser et simplifier les produits de données
- Jeux de données multimodèles
Analyse des données de séries temporelles
- Deltas/enregistrements modifiés
- Fidélité événement par événement
Éliminer les copies complètes des données pour la banque de données opérationnelle
- Livres et pipelines basés sur les journaux
Data lakes et warehouses distribués
- Hybride/multicloud/global
- Intégration en continu/ETL
Analyses prédictives
- Monétisation des données, nouveaux services de données pour les ventes
Conclusion
La transformation numérique est extrêmement difficile et, malheureusement, la plupart des entreprises n'y parviendront pas. Au fil des années, la technologie, la conception logicielle et l'architecture de données sont de plus en plus distribuées, à mesure que les techniques modernes s'éloignent des styles très centralisés et monolithiques.
Le maillage de données est un nouveau concept pour les données, un changement délibéré vers des événements de données hautement distribués et en temps réel, par opposition au traitement de données monolithique, centralisé et par lots. Le maillage des données est avant tout une nouvelle façon de penser culturelle qui met en avant les besoins des consommateurs de données. Il s'agit également d'une évolution technologique, d'une amélioration des plateformes et des services qui permettent une architecture de données décentralisée.
Les cas d'utilisation du maillage de données englobent à la fois les données opérationnelles et les données analytiques, ce qui constitue une différence essentielle par rapport aux data lakes/lakehouses et aux data warehouses conventionnels. Cette harmonisation des domaines de données opérationnels et analytiques est un facteur essentiel de la nécessité de favoriser un libre accès accru pour le consommateur de données. La technologie moderne de plateforme de données peut aider à éliminer l'intermédiaire en connectant les producteurs de données directement aux consommateurs de données.
Oracle est depuis longtemps le leader du secteur en matière de solutions de données critiques et a déployé certaines des fonctionnalités les plus modernes pour renforcer un maillage de données fiable :
- Infrastructure Oracle Generation 2 Cloud avec plus de 33 régions actives
- Base de données multimodèle pour les produits de données modulables aux formats requis
- Livre d'événements de données basé sur les microservices pour toutes les banques de données
- Traitement de flux multicloud pour des données sécurisées en temps réel
- Plateforme d'API, AppDev moderne et outils en libre accès
- Analyses, visualisation des données et data sciences natives du cloud native