Big Data platform
Seamlessly scale and run Apache Spark, Hive, Trino, Flink, and more. Discover the power of easy development and visualization through Data Science notebooks, leveraging familiar open source tools, all at an exceptional price-to-performance ratio.
Discover OCI Big Data platform capabilities
-
![]()
Open source upstream services
Comprehensive portfolio of open source components, such as Hadoop and Spark.
-
![]()
Fully managed, autoscaling, and elastic
Focus on your data and your code and we take care of the rest.
-
![]()
Migrate easily and modernize
Open source projects are easy to spin up, and we keep you up to date with latest innovations.
-
![]()
Integrated natively in OCI
Leverage all the Oracle Cloud Infrastructure (OCI) services effortlessly and expand.
-
![]()
Enterprise-grade security
More than 30 compliance certifications ensuring your data protection.
-
![]()




Data is the raw material for machine learning. Find out how to use machine learning in the cloud with the data you already have.
Big data clusters can easily be migrated to OCI. Discover the guidelines on our migration hub.
Bring all your data together with a data lake
-
Complete, integrated solution
Deploy a complete, integrated solution, including data management, data integration, and data science, so analytics teams can maximize the value of enterprise data. Customers ingest any data via batch, streaming, or real-time processes and store it in data warehouses or data lakes as needed. Teams then catalog and apply governance to the data so they can use it for analyses, visualizations, and machine learning models. IT teams leverage consistent security policies across data warehouses and data lakes.
-
Easy to manage and operate
Increase developer productivity with a fully managed, serverless, Apache Spark cluster that is accessible via APIs. Each cluster is automatically provisioned, secured, and shut down to reduce developer workloads. Customers can deploy fully managed Hadoop clusters of any size or shape, then add security and high availability with a single click.
-
Deploy in Oracle Cloud data centers or customer data centers
Deploy Oracle big data services wherever needed to satisfy customer data residency and latency requirements. Big data services, along with all other Oracle Cloud Infrastructure services, can be utilized by customers in the Oracle public cloud, or deployed in customer data centers as part of an Oracle Dedicated Region Cloud@Customer environment.
Migrate your big data workload to OCI—and save.
Smoothly transition to the cloud with OCI Big Data services. Our comprehensive, proven approach supports a hassle-free migration, whether you're using existing data lakes, Spark, Hadoop, Flink, Hive, or other Hadoop components. Migrate to OCI without the need for extensive configuration or integration and with minimal impact on your current environment. Benefit from detailed, step-by-step resources and expert guidance from Oracle's dedicated engineers and partners, ensuring a seamless shift to the cloud.
Move Your Environment To OCI Big Data with Apache Hadoop
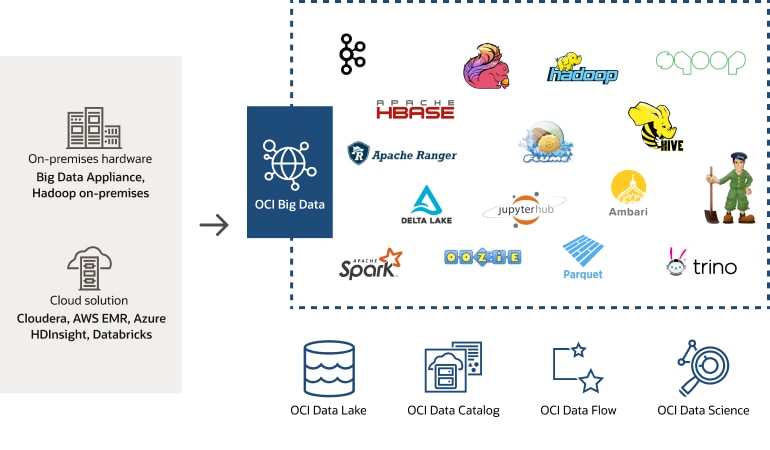
- Fully managed: We support and manage Apache Hadoop and Spark ecosystems so that you can run and scale your big data workload in the cloud.
- Easy migration: Migrate your workload to OCI and keep your familiar open source tools at an exceptional price-to-performance ratio.
- Seamless integration: Get a unified experience for all your data applications in OCI and leverage Oracle Modern Data Platform.
Oracle data platform unlocks the full potential of your data
- Combine transactional and analytical data—avoid silos.
- Leverage Oracle IaaS to Oracle SaaS, or anything in between—select the amount of control desired.
- Bring any kind of data to the platform—we break the barrier between structured and unstructured data.
- Explore the power of OCI and its openness to other cloud service providers—we meet you where you are.
- Use leading Oracle Analytics Cloud reporting or any third-party analytical application—OCI is open.
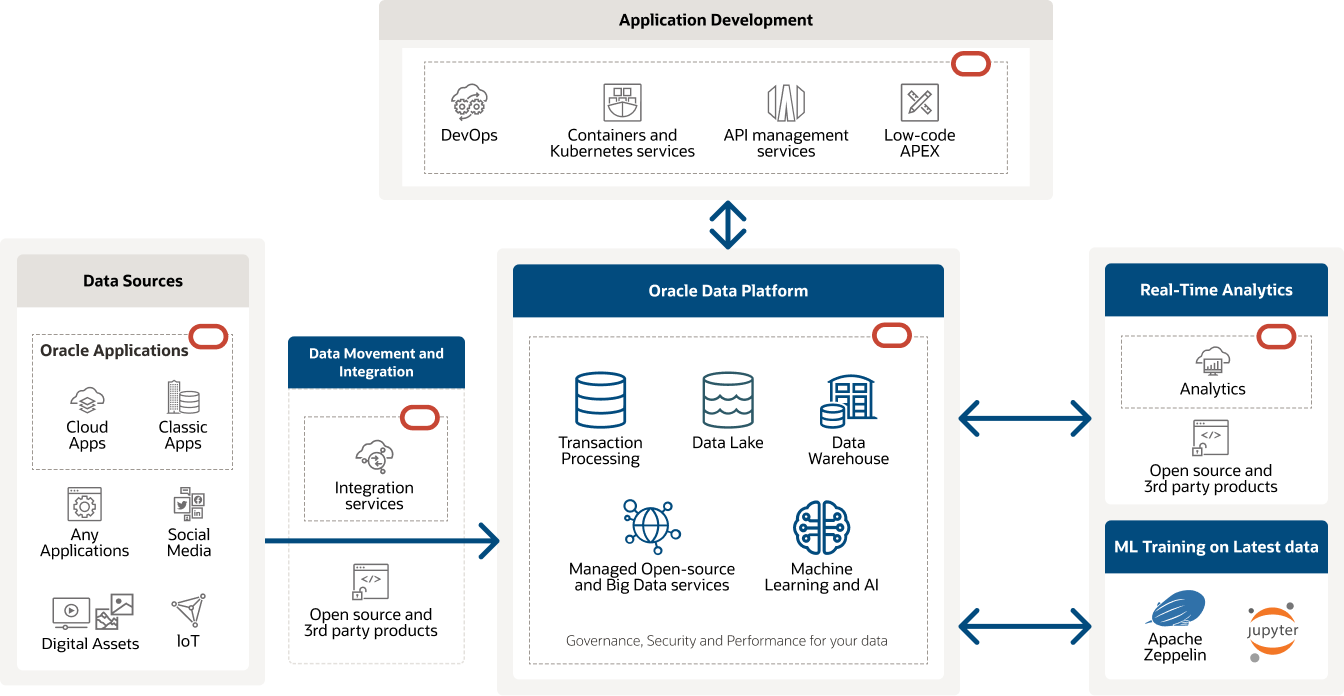 The diagram shows the Oracle data platform with data sources, data movement services such as integration services, the core of the Oracle modern data platform, and possible outcome and application development services.
The diagram shows the Oracle data platform with data sources, data movement services such as integration services, the core of the Oracle modern data platform, and possible outcome and application development services. See how our customers are using Big Data



Big Data services from Oracle
-
Data motion and integration
-
Connect and extend analytical applications with real-time consistent transactional data, efficient batch loads, and streaming data.
- OCI Data Integration
Simplify your complex data extract, transform, and load processes (ETL/E-LT) into data lakes and warehouses for data science and analytics with a no-code data flow designer. - Oracle Data Integrator
Data Integrator provides advanced data migration for extract, transform, and load. Oracle Data Integrator is optimized for Oracle cloud databases as well as on-premises databases. - Oracle GoldenGate
Oracle GoldenGate enables high-availability, real-time data integration, change data capture, data replication, transformations, and verification between operational and analytical enterprise systems. - OCI Streaming
Streaming provides out-of-the-box integrations for hundreds of third-party products across categories such as DevOps, databases, big data, and SaaS applications.
-
Big Data and Data Lake
-
Meet your big data needs in an open-source platform
- OCI Big Data
OCI Big Data is a Hadoop-based data lake service to store and analyze large amounts of raw customer data. A managed service, OCI Big Data comes with a fully integrated stack that includes both open source and Oracle value-added tools that simplify your IT operations. - OCI Data Flow
Data Flow is a fully managed Apache Spark service to perform processing tasks on extremely large datasets without infrastructure to deploy or manage. This enables rapid application delivery because developers can focus on app development, not infrastructure management. - OCI Data Catalog
Data Catalog helps data professionals across the organization search, explore, and govern data using an inventory of enterprisewide data assets. - OCI Object Storage
Object Storage enables customers to store any type of data in its native format. This is ideal for building modern applications that require scale and flexibility.
-
AI and machine learning
-
Gain insights from data with prebuilt AI models, or create your own.
- OCI AI Services
AI Services is a collection of services with prebuilt machine learning models that make it easier for developers to apply AI to applications and business operations. The models can be custom-trained for more accurate business results. - OCI Data Science
Rapidly build, train, deploy, and manage machine learning models with a data science service built for teams. - Machine Learning in Oracle Database
Machine Learning in Oracle Database supports data exploration, preparation, and machine learning modeling at scale. - MySQL HeatWave AutoML
MySQL HeatWave AutoML includes everything users need to build, train, deploy, and explain machine learning models within MySQL HeatWave, at no additional cost.
Big data architectures on OCI
Oracle expands cloud services with new open source data management solutions
Carter Shanklin, Senior Director, Product Management
Oracle Cloud Infrastructure (OCI) is excited to announce three new managed open source data management cloud services and three significant enhancements to existing ones. These services offer a wide range of capabilities to help organizations of all sizes enhance their data operations.
Featured big data blogs
- September 19, 2023 Oracle welcomes customers to OCI Data Lake public in early access
- September 19, 2023 Introducing OCI Data Flow SQL endpoints
Get started with OCI Big Data platform
Try Always Free cloud services and get a 30-day trial
Oracle offers a Free Tier with no time limits on a selection of services, including Autonomous Data Warehouse, OCI Compute, and Oracle Storage products, as well as US$300 in free credits to try additional cloud services. Get the details and sign up for your free account today.
-
What's included with Oracle Cloud Free Tier?
- Always Free
- Two Autonomous AI Database instances, 20 GB each
- Compute VMs
- 100 GB block volume
- 10 GB object storage
Learn with a hands-on lab
The best way to learn is to try it yourself. Try this free data lake workshop, which demonstrates a typical usage scenario and highlights some of the tools you can use to build a data lake.
-
Access the Data Lake using Autonomous AI Database and Data Catalog
The labs in this workshop walk you through the steps you need to access a data lake created with Oracle Object Storage buckets by using Oracle Autonomous AI Database and OCI Data Catalog.
Start data lake access lab -
Get Started with Oracle Big Data Service
Learn how to create and monitor a highly available Hadoop cluster using Big Data Service and OCI. You’ll also add Oracle Cloud SQL to the cluster and access the utility and master node, and learn how to use Cloudera Manager and Hue to access the cluster directly in a web browser.
Start the data lake lab -
Learn analytics and machine learning with Red Bull Racing
Use analytics and machine learning to analyze 70 years of racing data. Find out what makes some races so exciting you can’t look away while others are more predictable.
Start the data analytics lab -
Get started with Oracle Cloud Infrastructure Anomaly Detection
Discover how to use OCI Anomaly Detection to create customized machine learning models. You’ll take data uploaded by users, use a specialized algorithm to train a model, and deploy the model into the cloud environment to detect anomalies.
Start the anomaly detection lab now
Contact sales
Interested in learning more about a data lake? Let one of our experts help.
-
They can answer questions such as
- How do I get started with a data lake on Oracle?
- What can I do with a data lake that I can’t do with a data warehouse?
- How can my business benefit from a data lake?