Sichere Automatisierung von Aufgaben mit RAG und einer Auswahl an LLMs

Einführung
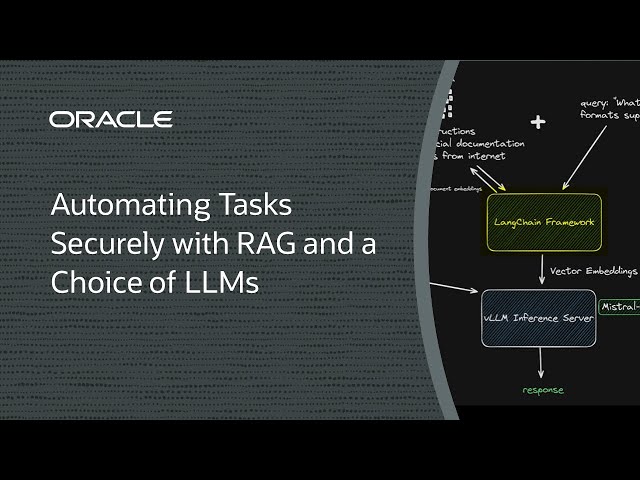
Um sich wiederholende Aufgaben zu optimieren oder vollständig zu automatisieren, warum sollten Sie nicht die Hilfe von KI in Anspruch nehmen? Die Verwendung eines Basismodells zur Automatisierung sich wiederholender Aufgaben mag ansprechend klingen, kann jedoch vertrauliche Daten gefährden. Die Retrieval-Augmented Generation (RAG) ist eine Alternative zur Feinabstimmung, bei der Inferenzdaten aus dem Korpus eines Modells isoliert bleiben.
Wir wollen unsere Inferenzdaten und unser Modell getrennt halten – aber wir wollen auch eine Wahl, bei der wir ein großes Sprachmodell (LLM) verwenden, und eine leistungsstarke GPU für Effizienz. Stellen Sie sich vor, Sie könnten all dies mit nur einer GPU tun!
In dieser Demo zeigen wir, wie Sie eine RAG-Lösung mit einer einzelnen NVIDIA A10-GPU bereitstellen, einem Open-Source-Framework wie LangChain, LlamaIndex, Qdrant oder vLLM und einem leichten 7-Milliarden-Parameter-LLM von Mistral AI. Es ist ein ausgezeichnetes Gleichgewicht von Preis und Leistung und hält Inferenzdaten getrennt, während die Daten nach Bedarf aktualisiert werden.
Demo
Voraussetzungen und Setup
- Oracle Cloud-Account – Anmeldeseite
- Oracle GPU-Compute-Instanz – Dokumentation
- LlamaIndex – Dokumentation
- LangChain – Dokumentation
- vLLM – Dokumentation
- Qdrant – Dokumentation