Automatiser les tâches en toute sécurité avec la RAG et un choix de LLM

Introduction
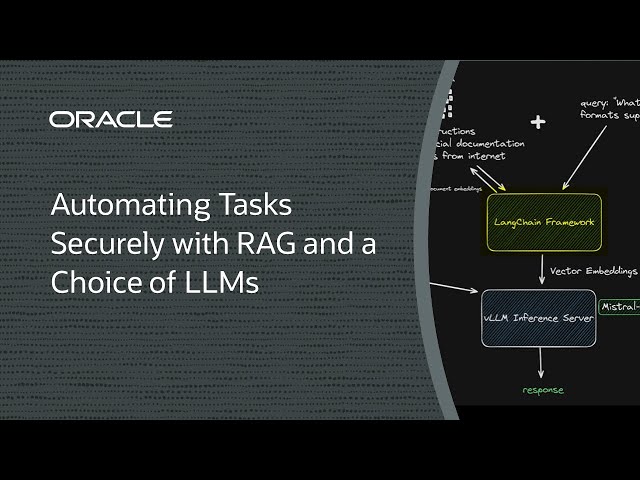
Dans l'effort de rationaliser les tâches répétitives ou de les automatiser entièrement, pourquoi ne pas faire appel à l'IA ? L'utilisation d'un modèle de base pour automatiser les tâches répétitives peut sembler attrayante, mais elle peut mettre en péril les données confidentielles. La génération augmentée par récupération (RAG) est une alternative au réglage fin, en gardant les données d'inférence isolées du corpus d'un modèle.
Nous voulons garder nos données d'inférence et notre modèle séparés, mais nous voulons également un choix dans lequel le grand modèle de langage (LLM) que nous utilisons et un GPU puissant pour l'efficacité. Imaginez si vous pouviez faire tout cela avec un seul GPU !
Dans cette démo, nous allons montrer comment déployer une solution RAG à l'aide d'un seul GPU NVIDIA A10, d'une structure open source telle que LangChain, LlamaIndex, Qdrant ou vLLM et d'un LLM léger de 7 milliards de paramètres de Mistral AI. C'est un excellent équilibre entre prix et performances et permet de séparer les données d'inférence tout en les mettant à jour si nécessaire.
Démonstration
Prérequis et configuration
- Compte Oracle Cloud : page d'inscription
- Instance de calcul de GPU Oracle : documentation
- LlamaIndex : documentation
- LangChain : documentation
- vLLM : documentation
- Qdrant : documentation