Che cos'è un Data Lakehouse?
Mike Chen | Content Strategist | 1 marzo 2022

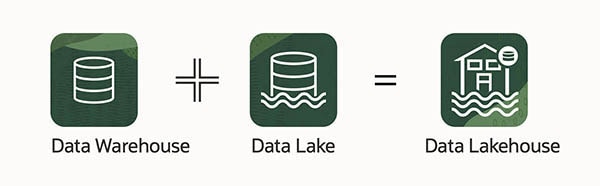
Un data lakehouse può essere definito come una moderna piattaforma di dati creata da una combinazione di un data lake e un data warehouse. In particolare, un data lakehouse prende lo storage flessibile di dati non strutturati da un data lake e le funzioni e gli strumenti di gestione dai data warehouse, quindi li implementa strategicamente insieme come un sistema più grande. Questa integrazione di due strumenti unici porta il meglio di entrambi i mondi agli utenti. Per suddividere ulteriormente un data lakehouse, è importante prima comprendere appieno la definizione dei due termini originali.
Confronto tra data lakehouse, data lake e data warehouse
Quando parliamo di un data lakehouse, ci riferiamo all'uso combinato delle attuali piattaforme di repository di dati.
- Data lake (il "lake" in lakehouse): un data lake è un repository di storage a basso costo utilizzato principalmente dai data scientist, ma anche dagli analisti aziendali, dai product manager e da altri tipi di utenti finali. Si tratta di un concetto di big data. I dati grezzi non strutturati provenienti da varie origini organizzative vengono inseriti nel lake, spesso per lo staging prima del caricamento in un data warehouse e della creazione di data set.
- Data warehouse (l'"house" in lakehouse): un data warehouse è un tipo diverso di repository di storage di un data lake in quanto un data warehouse memorizza i dati elaborati e strutturati, curati per uno scopo specifico e memorizzati in un formato specificato. Questi dati vengono in genere interrogati dagli utenti business, che utilizzano i dati preparati negli strumenti di analytics per il reporting e le proiezioni. Un data warehouse in genere include funzioni di gestione dei dati quali pulizia ed extract/load/trasform (ETL).
Quindi, in che modo un data lakehouse combina queste due idee? In generale, un data lakehouse rimuove i "muri" che dividono data lake e data warehouse. Ciò significa che i dati possono essere spostati facilmente tra lo storage a basso costo e flessibile di un data lake e viceversa, fornendo un facile accesso agli strumenti di gestione di un data warehouse per l'implementazione di schemi e governance, spesso alimentati dal machine learning e dall'intelligenza artificiale per la pulizia dei dati. Il risultato crea un repository di dati che integra la raccolta di data lake a prezzi accessibili e non strutturati e la solida preparazione di un data warehouse. Fornendo lo spazio per la raccolta da origini dati curate mentre si utilizzano strumenti e funzioni che preparano i dati per l'uso aziendale, un data lakehouse accelera i processi. In un certo senso, i data lakehouse sono data warehouse, che hanno avuto origine concettualmente all'inizio degli anni '80, riavviati per il nostro moderno mondo basato sui dati.
Caratteristiche di un data lakehouse
Avendo compreso il concetto generale di un data lakehouse, esaminiamo un po' più in profondità gli elementi specifici coinvolti. Un data lakehouse offre molte parti simili ai concetti storici di data lake e data warehouse, ma in un modo che li unisce in qualcosa di nuovo e più efficace per il mondo digitale di oggi.
Funzioni di gestione dei dati
Un data warehouse in genere offre funzioni di gestione dei dati come la pulizia dei dati, l'ETL e l'applicazione dello schema. Questi vengono introdotti in un data lakehouse come mezzo per preparare rapidamente i dati, consentendo ai dati provenienti da fonti curate di lavorare naturalmente insieme ed essere preparati per ulteriori strumenti di analisi e business intelligence (BI).
Formati di storage aperti
L'uso di formati di storage aperti e standardizzati implica che i dati provenienti da origini dati curate hanno un grande vantaggio nell'essere in grado di lavorare insieme ed essere pronti per gli analytics o il reporting.
Storage flessibile
La possibilità di separare la computazione dalle risorse di storage semplifica la scalabilità dello storage in base alle esigenze.
Supporto per lo streaming
Molte fonti di dati utilizzano lo streaming in tempo reale direttamente dai dispositivi. Un data lakehouse è progettato per supportare meglio questo tipo di ingestione in tempo reale rispetto a un data warehouse standard. Man mano che il mondo diventa più integrato con i dispositivi Internet of Things, il supporto in tempo reale sta diventando sempre più importante.
Carichi di lavoro diversi
Poiché un data lakehouse integra le funzioni sia di un data warehouse che di un data lake, è una soluzione ideale per una serie di carichi di lavoro diversi. Dal reporting aziendale ai team di data science agli strumenti di analytics, le qualità intrinseche di un data lakehouse possono supportare carichi di lavoro diversi all'interno di un'organizzazione.
Vantaggi di un data lakehouse: una piattaforma di dati moderna
Costruendo un data lakehouse, le organizzazioni possono semplificare il processo generale di gestione dei dati con una piattaforma dati unificata. Un data lakehouse può sostituire singole soluzioni togliendo i "muri" che separano più repository. Questa integrazione crea un processo end-to-end molto più efficiente rispetto alle origini dati curate. Questo crea diversi vantaggi.
- Meno amministrazione: utilizzando un data lakehouse, qualsiasi origine ad esso connessa può avere i propri dati accessibili e consolidati per l'uso, anziché estrarli da dati non elaborati e prepararsi a lavorare all'interno di un data warehouse.
- Una migliore governance dei dati: i data lakehouse semplificano e migliorano la governance consolidando le risorse e le origini dati e sono costruiti con uno schema aperto standardizzato, che consente un maggiore controllo su sicurezza, metriche, accesso basato sui ruoli e altri elementi di gestione cruciali.
- Standard semplificati: i data warehouse hanno avuto origine negli anni '80, quando la connettività era estremamente limitata, il che significa che gli standard di schema localizzati venivano spesso creati all'interno di organizzazioni, persino dipartimenti. Oggi esistono standard di schema aperti per molti tipi di dati e i data lakehouse ne traggono vantaggio incorporando più origini dati con uno schema standardizzato sovrapposto per semplificare i processi.
- Maggiore convenienza: i data lakehouse sono costruiti con un'infrastruttura che separa la computazione e lo storage, il che consente una facile aggiunta di storage senza la necessità di aumentare la potenza di calcolo. Ciò crea una scalabilità conveniente con il semplice uso dello storage dei dati a basso costo.
Mentre alcune organizzazioni creeranno un data lakehouse, altre acquisteranno un servizio cloud di data lakehouse.
Successi dei clienti: Data Lakehouse

Experian ha migliorato le prestazioni del 40% e ridotto i costi del 60% quando ha spostato i carichi di lavoro critici di dati da altri cloud a una data lakehouse su OCI, accelerando l'elaborazione dei dati e l'innovazione dei prodotti ed espandendo al contempo le opportunità di credito in tutto il mondo.
Generali Group è una compagnia assicurativa italiana con una delle più grandi basi clienti al mondo. Generali disponeva di numerose fonti di dati, sia da Oracle Cloud HCM che da altre fonti locali e regionali. Il processo decisionale HR e il coinvolgimento dei dipendenti stavano incontrando ostacoli, e l'azienda cercava una soluzione per migliorare l'efficienza. L'integrazione di Oracle Autonomous Data Warehouse con le origini dati di Generali, la rimozione dei silos e la creazione di un'unica risorsa per tutte le analisi HR. Ciò ha migliorato l'efficienza e aumentato la produttività del personale HR, consentendo loro di concentrarsi sulle attività a valore aggiunto piuttosto che sul tasso di abbandono della generazione dei report.

Uno dei principali fornitori di rideshare al mondo, Lyft doveva gestire 30 diversi sistemi finanziari separati. Questa separazione ha ostacolato la crescita dell'azienda e rallentato i processi. Integrando Oracle Cloud ERP e Oracle Cloud EPM con Oracle Autonomous Data Warehouse, Lyft è stato in grado di consolidare finance, operations e analytics in un unico sistema. Questo ha ridotto i suoi tempi di chiudere finanziaria del 50%, con il potenziale per un ulteriore processo di semplificazione. Ciò consente anche di risparmiare sui costi riducendo le ore di inattività.

Agroscout è uno sviluppatore software che aiuta gli agricoltori a massimizzare le colture sane e sicure. Per aumentare la produzione alimentare, Agroscout ha utilizzato una rete di droni per sondare colture per scovare insetti o malattie. L'organizzazione aveva bisogno di un modo efficiente per consolidare i dati e elaborarli per identificare i segni di pericolo delle colture. Grazie Oracle Object Storage Data Lake, i droni hanno caricato direttamente le colture. I modelli di machine learning sono stati creati con OCI Data Science per elaborare le immagini. Il risultato è stato un processo notevolmente migliorato che ha permesso una risposta rapida per aumentare la produzione alimentare.
Scopri perché OCI è il posto migliore per creare un lakehouse
Con ogni giorno che passa, sempre più fonti di dati inviano maggiori volumi di dati in tutto il mondo. Per qualsiasi organizzazione, questa combinazione di dati strutturati e non strutturati continua a essere una sfida. I data lakehouse collegano, mettono in correlazione e analizzano questi vari output in un unico sistema gestibile.