Data Science Service
Oracle Cloud Infrastructure (OCI) Data Science is a fully managed platform for teams of data scientists to build, train, deploy, and manage machine learning (ML) models using Python and open source tools. Use a JupyterLab-based environment to experiment and develop models. Scale up model training with NVIDIA GPUs and distributed training. Take models into production and keep them healthy with ML operations (MLOps) capabilities, such as automated pipelines, model deployments, and model monitoring.

- OCI Data Science supports OpenAI's open weight models
OpenAI has announced the release of two open weight models, gpt-oss-120b and gpt-oss-20b, which can be deployed and fine-tuned in OCI Data Science.
- Simplify your work with foundation models
Deploy, fine-tune, and evaluate foundation models with OCI Data Science AI Quick Actions.
- Now available: Cohere Embed 4 on OCI Generative AI
Enhance enterprise search and retrieval-augmented generation with Cohere’s latest high performance embedding model, now accessible through OCI.
- Try OCI Data Science for free
An Oracle Cloud free trial lets you access OCI Data Science with US$300 in free cloud credit.
How does OCI Data Science work?
OCI Data Science is a comprehensive managed service designed to streamline the development, deployment, and operationalization of AI and machine learning models. Key features include Jupyter-based notebooks for experimentation, scalable MLOps tools for model deployment and monitoring, and integrated support for large language models (LLMs) through Hugging Face and other frameworks.
With robust tools for collaboration, anomaly detection, and forecasting, OCI Data Science empowers teams to deliver actionable insights efficiently and securely.
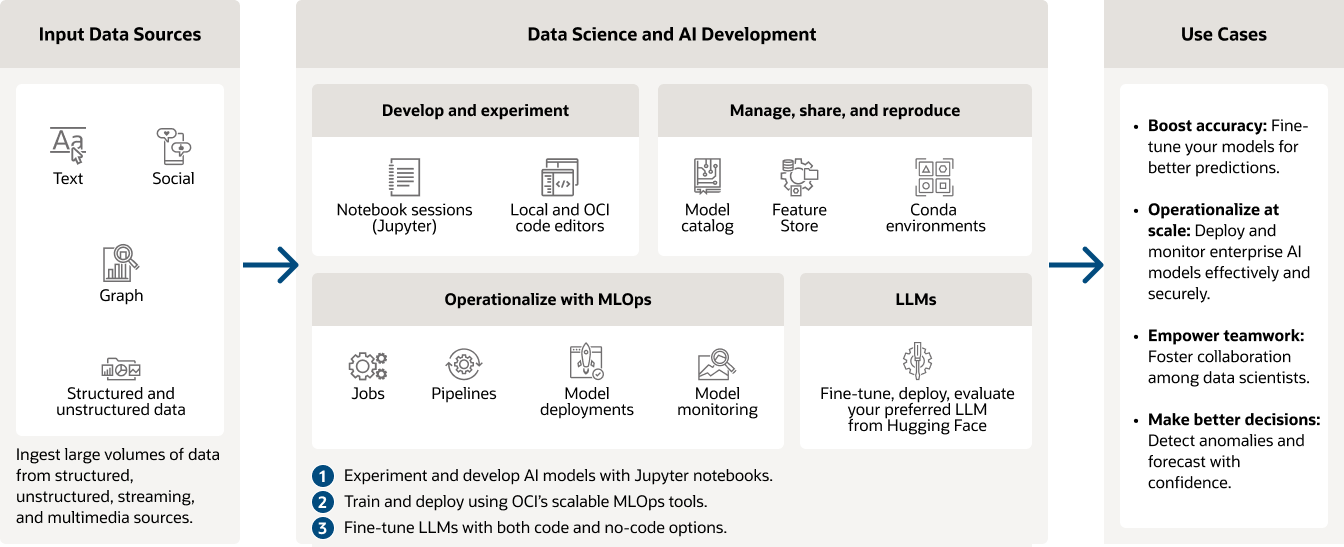
OCI Data Science use cases
Healthcare: Patient readmission risk
Identify risk factors and predict the risk of patient readmission after discharge by creating a predictive model. Use data, such as patient medical history, health conditions, environmental factors, and historic medical trends, to build a stronger model that helps provide the best care at a lower cost.
Retail: Predict customer lifetime value
Use regression techniques on data to predict future customer spend. Examine past transactions and combine historical customer data with data on trends, income levels, and even factors such as weather to build ML models that determine whether to create marketing campaigns for keeping current customers or acquiring new ones.
Manufacturing: Predictive maintenance
Build anomaly detection models from sensor data to catch equipment failures before they become a more severe issue or use forecasting models to predict end of life for parts and machinery. Increase vehicle and machinery uptime through machine learning and monitoring operations metrics.
Finance: Fraud detection
Prevent fraud and financial crimes with data science. Build a machine learning model that can identify anomalous events in real time, including fraudulent amounts or unusual types of transactions.
Why OCI Data Science?
-
High performance data science
Gain access to automated workflows for building models. Operationalize ML more easily with reusable jobs and end-to-end orchestration for the ML lifecycle. Run distributed, high performance workloads with access to lower-cost GPUs.
-
Open platform
Expect the best of ML on Oracle through major partnerships. Bring in models, data, and code in the format you need.
-
Best-in-class support
Benefit from top-tier treatment for strategic ML partnerships. Oracle’s data scientists are dedicated to ensuring your organization’s success.
OCI Data Science customer successes and partnerships




AI/machine learning reference architectures
-
Solution playbook
Learn how data is stored, used, and analyzed by a healthcare system to track a patient’s journey from diagnosis to treatment through recovery.
-
Reference architecture
Modern app development—ML and AI
Use this pattern to create ML platforms designed for data scientists.
-
Built and Deployed
Rapidly deploy an architecture to securely handle large amounts of source data to build predictive models and leverage them in rapidly developed applications.
-
Reference architecture
Enrich enterprise application data with raw data from other sources and use ML models to bring intelligence and predictive insights into business processes.