 Database
技術記事
Ask Tom
Database
技術記事
Ask Tom
2014年1/2月 |
テクノロジー:Ask Tom
Oracle Database 12cについて:パート3
Tom Kyte著
オラクルの技術者が、パーティションの改良点、問合せ計画の適応、統計収集の最適化について説明します。
Ask Tomの各コラムでは通常、過去2か月の間にユーザーが投稿した質問を3つか4つ取り上げて、それらの質問に回答しています。しかし、前回、前々回と以後2回のコラムでは、Oracle Database 12cの重要な機能のいくつかについて説明します。これらの重要な機能はすべて、2012年にサンフランシスコで開催されたOracle OpenWorldで筆者が行ったプレゼンテーション"12 Things About Oracle Database 12c"で取り上げたものです(このプレゼンテーションのスライドは、asktom.oracle.comのFilesタブで公開しています)。1回目のコラムでは、Oracle Database 12cの最初の3つの機能(改善されたデフォルト値、より大きなデータ型、上位Nの問合せ)について説明しました。前回は、新しい行パターン・マッチングについて説明し、一時表のUNDOがOracle Database 12cでどのように変わったかを説明しました。今回は、パーティション化の改良点、適応型実行計画、強化された統計機能ついて取り上げます。
パーティション化の改良点
パーティション化が最初に導入されたのはOracle8 Databaseで、1997年まで遡ります。その後16年間で多くのパーティション化機能が追加されましたが、Oracle Database 12cでも相当数の機能が追加されています。ここでは、Oracle Database 12cのパーティション化に関する5つの新機能について取り上げます。パーティション化や関連用語に精通していない場合は、まず"Partition Decisions"(Arup Nanda著)を読むことをお勧めします。この記事は、日常業務でパーティション化を使用しない人を対象として、パーティション化の概要を分かりやすく説明しています。
Oracle Database 12cのパーティション化に関する1つ目の新機能は、非同期グローバル索引メンテナンスです。グローバル索引とは、定義されている表とは異なるルールでパーティション化されたパーティション表に対する索引です。たとえば、ORDER_DATEという日付型の列によってレンジ・パーティション化されたORDERSという表があるとします。そのORDERS表内の特定の列(例:CUSTOMER_NAME)に対して索引を設定する場合、通常、このCUSTOMER_NAME索引はグローバル索引となります。この場合のグローバル索引は、単一パーティションに対して設定される場合もあれば、CUSTOMER_NAMEに基づいたレンジまたはハッシュによってパーティション化される場合もあります。Oracle Database 11g Release 2やそれ以前のバージョンでもっとも古いORDERS表パーティションを削除した場合、このグローバル索引はすぐに利用できなくなるか(利用可能にするために再構築が必要でした)、または、DROPパーティション・コマンドの実行時にメンテナンスを行う必要がありましたが、索引をメンテナンスする場合にも、DROPパーティション・コマンドの実行はすぐに終了せず、数時間かかることもありました。
Oracle Database 12cでは、この両方について最適化されています。DROPパーティション・コマンドの実行はすぐに完了し、DROP操作中に索引メンテナンスは実行されず(削除対象のパーティションを指し示す索引エントリはグローバル索引内に維持され)索引は利用可能な状態を維持します。DROPパーティション・コマンドの実行が完了した後、グローバル索引のスキャン時には、削除された(または切り捨てられた)パーティションを指し示すエントリは無視されます。後で、個別のトランザクションにより索引をクリーンアップし、削除された"孤立状態"の索引エントリを削除して、領域を回収できます。このクリーンアップ処理は、DBAが手動で起動することも、通常のメンテナンス期間にジョブとして自動的に実行することもできます。いずれの場合でも、パーティションの削除または切捨てが即座に完了し、索引は常に利用可能な状態になり、索引のメンテナンスは延期されます。
次に紹介するパーティション化の新機能は、インターバル・パーティション化を使用している表で参照パーティション化を使用できるというものです。参照パーティション化とインターバル・パーティション化は、いずれもOracle Database 11gで導入された機能です(インターバル・パーティション化と参照パーティション化について詳しくは、"More Partitioning Choices"(Arup Nanda著)を参照してください)。しかし、これら2つのパーティション化を同時に使用することは不可能でした。Oracle Database 12cではその制約が取り払われています。
たとえば、次のようなORDERS表があるとします。
SQL> create table orders
2 (
3 order# number primary key,
4 order_date date,
5 data varchar2(3)
6 )
7 enable row movement
8 partition by range(order_date)
9 interval (numtodsinterval(1,'day'))
10 (partition p0 values less than
11 (to_date('01-jan-2013',
'dd-mon-yyyy'))
12 )
13 /
Table created.
Oracle Database 12cでは、親表(ORDERS)のパーティション化方式を参照する子表(LINE_ITEMS)を問題なく作成できます。
SQL> create table line_items
2 ( order# number not null,
3 line# number,
4 data varchar2(3),
5 constraint c1_pk
primary key(order#,line#),
6 constraint c1_fk_p
foreign key(order#)
references orders
7 on delete cascade
8 )
9 enable row movement
10 partition by reference(c1_fk_p)
11 /
Table created.
この親子の関係をもとに、さらに別のパーティション化の新機能を紹介しましょう。それは、親表/子表に対するCASCADE DROP操作およびCASCADE TRUNCATE操作の実行機能です。
以前は、このORDERS表内の特定のパーティションを切り捨てる(または削除する)場合、その前に子表の対応するパーティションを切り捨てる(または削除する)必要がありました。つまり、すべての子表の表パーティションを切り捨てて(削除して)、参照整合性制約の連鎖を最終的に親まで辿る必要がありました。この操作のためには、個別の複数のSQL文を作成し、それぞれの文でコミットを実行することが求められました。そのため、親子階層のパーティションの切捨て/削除ではエラーが多少発生しやすく、本来必要のない難しさが伴いました(さらに、この切捨て/削除によって、短時間、論理的に一貫しない状態にもなりました)。
Oracle Database 12cでは、1つのコマンドによりCASCADE DROPまたはCASCADE TRUNCATEを実行できます。たとえば、次のようにORDERS表とLINE_ITEMS表にデータを追加し、親表のパーティションを検索します。
SQL> insert into
orders(order#,order_date,data)
2 values ( 1, to_date(
'15-mar-2013' ), 'xxx' );
1 row created.
SQL> insert into
line_items(order#,line#,data)
2 values ( 1, 1, 'yyy' );
1 row created.
SQL> commit;
Commit complete.
SQL> select partition_name
2 from user_tab_partitions
3 where table_name = 'ORDERS'
4 and partition_name like 'S%';
PARTITION_NAME
————————————————————
SYS_P853
この状態で、親の表パーティションを切り捨てようとすると、親パーティションと子パーティションの間にリンクがあることが示されます。
SQL> alter table orders truncate
partition SYS_P853;
alter table orders truncate partition
SYS_P853
*
ERROR at line 1:
ORA-02266: unique/primary keys in table
referenced by enabled foreign keys
この切捨て操作は、切り捨てようとしたデータを参照している子データがあるために失敗します。ここで、新しいCASCADEオプションを適用します。
SQL> alter table orders truncate partition SYS_P853 cascade; Table truncated.
そうすれば、切捨てが成功し、実際に親パーティションに加えて子パーティションも切り捨てられます(注意点として、データが意図せず削除されることのないように、このカスケード機能を使用するには、外部キー制約に対してON DELETE CASCADEと定義している必要があります)。パーティションの交換でも同様のオプションが用意されています。1つのコマンドにより、表パーティションの親子階層全体でパーティションを交換できます。たとえば、リスト1のように、ステージング表にデータをロードします。
コード・リスト1:パーティション交換の準備:ステージング表へのデータのロード
SQL> create table orders_tmp 2 ( 3 order# number primary key, 4 order_date date, 5 data varchar2(3) 6 ); Table created. SQL> create table line_items_tmp 2 ( order# number not null, 3 line# number, 4 data varchar2(3), 5 constraint c1_tmp_pk primary key(order#,line#), 6 constraint c1_tmp_fk_p foreign key(order#) references orders_tmp 7 on delete cascade 8 ); Table created. SQL> insert into orders_tmp (order#,order_date,data) 2 values (100,to_date(‘31-dec-2012','dd-mon-yyyy'),'abc'); 1 row created. SQL> insert into line_items_tmp (order#,line#,data) 2 values (100,1,'def'); 1 row created. SQL> commit; Commit complete.
この状態で新しいCASCADEオプションを使用すれば、ORDERSとORDERS_TMPのデータ交換、およびLINE_ITEMSとLINE_ITEMS_TMPのデータ交換を1つのコマンドで実行できます。
SQL> alter table orders
2 exchange partition p0
3 with table orders_tmp
4 cascade;
Table altered.
SQL> select * from orders;
ORDER# ORDER_DAT DAT
————————— ————————— ————
100 31-DEC-12 abc
SQL> select * from line_items;
ORDER# LINE# DAT
————————— ————————— ————
100 1 def
個別の複数のデータ定義言語(DDL)文を使用しなくても、1つの原子的なDDL文でパーティションを交換できます。
次に紹介するOracle Database 12cのパーティション化の改良点は、1つのDDL文で複数のパーティション操作を実行できることです。この機能により、1つのパーティションを複数のパーティションに分割する操作や、複数のパーティションを1つのパーティションにマージする操作を1つのDDL文で実行できます。以前は、1つのパーティションを4つのパーティションに分割する場合に、3つの分割文を実行する必要がありました。この実行には、大量のデータの読取り、再読取り、書込み、再書込みが伴いました。現在は、そのような複数のパーティション操作を1つの原子的なDDL文で実行できます。
パーティション化の改良点として最後に紹介する機能は、新しいALTER TABLE MOVE PARTITIONコマンドによってオンラインでパーティションを移動できることです。また、このコマンドはグローバル索引を透過的にメンテナンスして、停止時間のない100%のデータ可用性を実現します。これらの新機能について詳しくは、Oracle Database VLDBおよびパーティショニング・ガイド 12cリリース1 (12.1)を参照してください。
適応型問合せ計画
Oracle Database 12cの適応型問合せ計画とは、実行中に"考えを変える"可能性のある計画です。たとえば、オプティマイザは、表により生成される行数の見積もりに基づいて、2つの表の結合にネステッド・ループ結合を使用するのが最適だと考えているとします。しかし、オプティマイザが選択した駆動表は予想よりも大幅に多い行を返すことが実行時に判明しました。この場合、Oracle Database 12cでは、問合せ計画を適応させ、変更して、ネステッド・ループ結合からハッシュ結合へと切り替えることができます。
オラクルの"オプティマイザ・レディ"として知られるMaria ColganがOracle Optimizerブログで、"What’s New in 12c: Adaptive Joins"という優れた記事を投稿しています。この記事の抜粋を、当コラムの補足の"適応型結合"に掲載します。
適応型問合せ計画について詳しくは、このビデオを参照してください。機能の説明とデモンストレーションを確認できます。また、Oracle Database SQLチューニング・ガイド 12cリリース1 (12.1)においてもこの機能について言及しています。
統計機能の改良点
Oracle Database 12cでは統計機能に対して多くの改良が加えられました。ここで紹介するのは、データ・ロード中の統計情報生成(オンライン統計収集)、グローバル一時表のセッション・プライベート統計の2つです。
オンライン統計収集:Oracle Database 10g以降、索引の作成時や再構築時には常に、索引に関する統計情報が自動的に収集されます(データ・ロードの直後に索引の再構築または作成を行う場合に、レポート・データベースやウェアハウス・データベース内の索引に関する統計情報を収集する必要がないのです)。この動作については次の例で簡単に確認できます(STAGE表は、ALL_OBJECTSビューの単なるコピーです)。
SQL> create table t
2 as
3 select *
4 from stage
5 where 1=0;
Table created.
SQL> create index t_idx on t(object_id);
Index created.
SQL> alter index t_idx unusable;
Index altered.
SQL> insert /*+ append */ into t
2 select *
3 from stage;
87814 rows created.
SQL> alter index t_idx rebuild;
Index altered.
SQL> select num_rows, last_analyzed
2 from user_indexes
3 where index_name = 'T_IDX';
NUM_ROWS LAST_ANALYZED
————————— ———————————————————
87814 26-SEP-13
この例のUSER_INDEXESに対する問合せから分かるように、この索引には有効な統計情報が収集されています。Oracle Database 12cでの新機能は、データのロード先のセグメントが最初に空である(作成または切捨ての直後である)場合の表についても、統計情報が自動的に収集されることです。この例では、データ・ロード中の表は空であったため、Oracle Database 12cでは表自体の基本的な統計情報も収集されます。
SQL> select num_rows, last_analyzed
2 from user_tables
3 where table_name = 'T';
NUM_ROWS LAST_ANALYZED
—————————— ———————————————————
87814 26-SEP-13
さらに、このロードで生成された問合せ計画を確認すると、Oracle Database 12cでは新しいステップが追加されています。
Row Source Operation
—————————————————————————————————————
LOAD AS SELECT …
OPTIMIZER STATISTICS GATHERING …
TABLE ACCESS FULL STAGE …
新しいステップのOPTIMIZER STATISTICS GATHERINGは、このロード中に統計情報が生成されたことを示します。これで、この表に関する基本統計はすべて収集されましたが、ヒストグラムなどの非デフォルト統計は含まれません。この理由として、ヒストグラムの作成には追加のデータ・スキャンが必要になることが挙げられます。オンライン統計収集機能は、データ・ロードに影響を及ぼすとしても最小限に抑えるように実装されました。幸いにも、ヒストグラムだけであれば、すでに生成した基本的な統計情報を再生成しなくても容易に収集できます。そのために、まずは列の使用状況の情報を用意します(列の使用状況の情報について詳しくは、"On Joins and Query Plans"の"Why Does My Plan Change?"の項を参照してください)。そのためには、いくつかの代表的な問合せを実行します。この問合せでは、条件内で、実際の問合せ内での利用を予定している列を参照します。次に例を示します。
SQL> select count(*)
2 from t
3 where owner = 'SCOTT';
COUNT(*)
——————————————
11
これで、問合せではWHERE句でOWNER列が使用されるとデータベースが認識しました。そのため、次にデフォルトのMETHOD_OPT設定を使用して統計情報を収集する際には、データベースはこのOWNER列を調査して、新しいヒストグラム生成の候補となるかを確認します。この例では、OWNER列はヒストグラムの候補になります。OWNER列に含まれるデータ値が偏っているからです。つまり、SYSユーザーが多くのオブジェクトを所有するのに対して、SCOTTはほとんど所有していません。統計収集プロセスでは最初に、OWNER列に基本的な列統計情報のみがあることを確認します。
SQL> select count(*)
2 from user_tab_histograms
3 where table_name = 'T'
4 and column_name = 'OWNER';
COUNT(*)
——————————————
2
次に、GATHER AUTOオプションを使用して統計情報を収集します。この結果、今存在しない統計情報のみが追加されます。すでに存在する統計情報は生成されません。
SQL> begin 2 dbms_stats.gather_table_stats 3 ( user, 'T', 4 OPTIONS => 'GATHER AUTO' ); 5 end; 6 / PL/SQL procedure successfully completed.
OWNER列に対してヒストグラムが生成されたことを確認できます。
SQL> select count(*)
2 from user_tab_histograms
3 where table_name = 'T'
4 and column_name = 'OWNER';
COUNT(*)
——————————————
22
以上で、Oracle Database 12cでは、索引だけではなく表についてもオンライン統計情報を収集できることが分かりました。アップグレード時にはぜひ、統計の収集方法を見直してください。一部の表について、統計収集が不要になる可能性があります。
Oracle Database 12cのオンライン統計収集について詳しくは、Oracle Database 12c: Enhanced Optimizer Statistics with Tom Kyteのビデオを参照してください。
グローバル一時表のセッション・プライベート統計情報:今回のコラムの最後に紹介する新機能は、グローバル一時表を生成するセッションにのみ存在する、グローバル一時表に関する統計情報を収集する機能です。グローバル一時表に関する代表的な統計情報を管理することは、控えめに言っても困難でした。すべてのセッションで(多くの場合はすべてのトランザクションでさえも)、他のセッションやトランザクションとはまったく異なるデータセットが使用され、オプティマイザに対してどのようなデータであるかを伝えるための統計情報の収集に問題があったからです。セッションやトランザクションはすべて異なります。
そこで、これらの一時表について、セッション・プライベート統計を取り入れます。デフォルトで、Oracle Database 12cの各セッションにはグローバル一時表に関する固有の統計情報セットが生成されます。オプティマイザはこの情報を使用してカーディナリティを正しく見積もり、適切な計画を導き出すことができます。
この動作を検証するために、グローバル一時表を生成し、その後の問合せの"IN"句でこの一時表を使用します。この例では、データベースに対して実行されるアプリケーションにより、数行のデータをグローバル一時表に配置した後、WHERE句でそのデータを使用して別の表からデータを取得します。この場合によく起きる問題は、同じグローバル一時表に数行しか配置しないセッションもあれば、大量の行を配置するセッションもあることです。これらの別々のケースに対応する2種類の計画を作成したいのですが、オプティマイザが一方の統計情報セット(上記のいずれかのケースのみを表すもの)しか把握しなければ、1つの計画しか作成できないことになります。これが、セッション・プライベート統計機能が解決しようとしている問題です。
まず、グローバル一時表と問合せ対象の表を作成します。
SQL> create 2 global temporary 3 table gtt 4 ( x int ) 5 on commit delete rows 6 / Table created. SQL> create table t 2 as 3 select * 4 from stage; Table created. SQL> alter table t 2 add constraint 3 t_pk primary key 4 (object_id); Table altered.
次に、グローバル一時表にデータをロードして、どのような統計情報が存在するかを確認します。
SQL> insert into gtt 2 select object_id 3 from t 4 where rownum <= 5; 5 rows created. SQL> select scope, num_rows 2 from user_tab_statistics 3 where table_name = 'GTT'; SCOPE NUM_ROWS ——————— —————————— SHARED
まだ統計情報はないため、収集します。
SQL> begin 2 dbms_stats.gather_table_stats 3 ( user, 'GTT' ); 4 end; 5 / PL/SQL procedure successfully completed. SQL> select scope, num_rows 2 from user_tab_statistics 3 where table_name = 'GTT'; SCOPE NUM_ROWS ——————— ————————————— SHARED SESSION 5
このグローバル一時表のセッション統計情報が生成されました。このセッション統計情報は"共有(SHARED)"されていません。つまり、このセッションにとってプライベートです。また、このセッション統計情報は、表にロードされたデータを正確に表しています。
リスト2に示す問合せでこのグローバル一時表を使用すると、オプティマイザは有効な代表的統計情報に基づいて最適な計画を見つけ出します。
コード・リスト2:グローバル一時表とセッション・プライベート統計情報の使用
SQL> select *
2 from t
3 where object_id in
4 (select x from gtt);
———————————————————————————————————————————————————————————————————————————————
| Id | Operation | Name | Rows| Bytes|Cost (%CPU)| Time |
———————————————————————————————————————————————————————————————————————————————
| 0 | SELECT STATEMENT | | 5| 550| 5 (0)| 00:00:01|
| 1 | NESTED LOOPS | | | | | |
| 2 | NESTED LOOPS | | 5| 550| 5 (0)| 00:00:01|
| 3 | SORT UNIQUE | | 5| 15| 2 (0)| 00:00:01|
| 4 | TABLE ACCESS FULL | GTT | 5| 15| 2 (0)| 00:00:01|
|* 5 | INDEX UNIQUE SCAN | T_PK | 1| | 0 (0)| 00:00:01|
| 6 | TABLE ACCESS BY INDEX ROWID| T | 1| 107| 1 (0)| 00:00:01|
———————————————————————————————————————————————————————————————————————————————
Predicate Information (identified by operation id):
—————————————————————————————————————————————————————————————————————————————
5 - access("OBJECT_ID"="X")
Note
———————
- this is an adaptive plan
- Global temporary table session private statistics used
次に、別のセッションを実行し、まったく異なるデータをこのグローバル一時表にロードし、問合せを実行して、結果を確認します(リスト3)。
コード・リスト3:別のセッションでの異なるデータのロードで別の計画を使用
SQL> connect /
Connected.
SQL> insert into gtt
2 select object_id
3 from stage;
87813 rows created.
SQL> select *
2 from t
3 where object_id in
4 (select x from gtt);
———————————————————————————————————————————————————————————————————————————
| Id | Operation | Name | Rows | Bytes |Cost (%CPU)| Time |
———————————————————————————————————————————————————————————————————————————
| 0 | SELECT STATEMENT | | 87813 | 10M| 924 (1)| 00:00:01 |
|* 1 | HASH JOIN | | 87813 | 10M| 924 (1)| 00:00:01 |
| 2 | SORT UNIQUE | | 104K| 1331K| 40 (3)| 00:00:01 |
| 3 | TABLE ACCESS FULL| GTT | 104K| 1331K| 40 (3)| 00:00:01 |
| 4 | TABLE ACCESS FULL | T | 87813 | 9175K| 384 (1)| 00:00:01 |
———————————————————————————————————————————————————————————————————————————
Predicate Information (identified by operation id):
———————————————————————————————————————————————————————————————————————————
1 - access("OBJECT_ID"="X")
Note
———————
- dynamic statistics used: dynamic sampling (level=2)
- this is an adaptive plan
この新しいセッションでは、オプティマイザで統計情報が見つからなかったため、動的サンプリングを利用して統計情報を生成しています。今回は一時表に5行を大幅に超えるデータがあったため、より適切な別の計画が選択されました。この例は、最初のセッションの統計情報が"消えた"こと、つまりその統計情報は最初のセッションにとってのプライベート情報であったことも示しています。
これまでに、オプティマイザに対して代表的統計情報を提供する手段として、統計収集と動的サンプリングの2種類の方法があることが分かりました。3つ目の方法として、統計情報を直接設定できます。たとえば、挿入操作を実行した直後の開発者は、ロードされたデータ量を把握しています。この情報をオプティマイザに提供できるのは、この開発者だけです。例として、グローバル一時表に300行のデータをロードした直後に、リスト4に示す統計情報を設定します。オプティマイザは追加された統計情報を使用して問合せを最適化するため、結果的に再度異なる計画が使用されることになります。
コード・リスト4:統計情報の直接設定と、使用したセッション・プライベート統計情報の確認
SQL> begin
2 dbms_stats.set_table_stats
3 ( user, 'GTT', numrows => 300 );
4 end;
5 /
PL/SQL procedure successfully completed.
SQL> set autotrace traceonly explain
SQL> select *
2 from t
3 where object_id in
4 (select x from gtt);
——————————————————————————————————————————————————————————————————————————————
| Id | Operation | Name| Rows| Bytes|Cost (%CPU)| Time |
——————————————————————————————————————————————————————————————————————————————
| 0 | SELECT STATEMENT | | 9| 1080| 38 (0)| 00:00:01|
| 1 | NESTED LOOPS | | | | | |
| 2 | NESTED LOOPS | | 9| 1080| 38 (0)| 00:00:01|
| 3 | SORT UNIQUE | | 300| 3900| 29 (0)| 00:00:01|
| 4 | TABLE ACCESS FULL | GTT | 300| 3900| 29 (0)| 00:00:01|
|* 5 | INDEX UNIQUE SCAN | T_PK| 1| | 0 (0)| 00:00:01|
| 6 | TABLE ACCESS BY INDEX ROWID| T | 1| 107| 1 (0)| 00:00:01|
——————————————————————————————————————————————————————————————————————————————
Predicate Information (identified by operation id):
—————————————————————————————————————————————————————————————————————————————
5 - access("OBJECT_ID"="X")
Note
———————
- this is an adaptive plan
- Global temporary table session private statistics used
オプティマイザの新機能一覧やその他の情報について詳しくは、Oracle Database新機能ガイド 12cリリース1 (12.1)を参照してください。
適応型結合
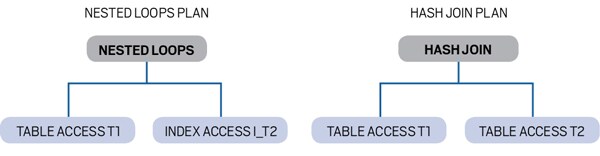
この補足は、"What’s New in 12c: Adaptive Joins"(Maria Colgan著)からの抜粋です。 適応型結合の目標は、最初の実行時に不適切な計画によって致命的な振る舞いになることを防止することです。オプティマイザのカーディナリティの見積もりが誤っていたことを実行時に検出した場合、その場で一部の計画の選択肢をより適切なオプションに変更できます。実行中に計画を完全に変更することは不可能ですが、結合方式などの一部の局所的な決定については変更可能です。この記事では、適応型計画に関連する概念と用語について紹介した後、例を詳しく見ていきます。 概念と用語適応型計画では、実行時の条件がオプティマイザの見積もりと異なる場合に、計画内の一部の決定を実行時まで先延ばしできます。この概念の説明のために、結合方式が適応される、単純な2表の結合の計画について考えます。次の図に、この計画の2つのオプションを示します。
適応型計画はデフォルト計画と、そのデフォルト計画の各部に対する代替的手段により構成されます。デフォルト計画とは、現在の統計情報に基づいてオプティマイザにより選択される計画です。この例の結合では、ネステッド・ループの計画がデフォルトで、ハッシュ結合が代替的手段であるとします。計画の各部の代替的手法はサブ計画と呼ばれます。サブ計画とは、ある計画内の、関連する一連の操作のことです。この図では、左側のサブ計画はネステッド・ループ操作と索引スキャンで構成され、右側の代替的なサブ計画は、ハッシュ結合と表スキャンで構成されます。この計画は、適応可能な決定ごとに、2つ以上の代替的なサブ計画で構成されます。実行中、適応型計画解決と呼ばれるプロセスにおいて、いずれかの代替的な手法が選択されます。適応型計画解決は、計画の1回目の実行時に発生します。一度計画が解決されると、その後の実行では同じ計画が使用されます。 計画を解決するために、実行時のさまざまな時点で統計情報が収集されます。実行時のある部分で収集された統計情報は、後で実行される計画の各部を解決するために使用されます。たとえば、表T1のスキャン中に統計情報を収集でき、その統計情報に基づいて、T1とT2の結合に適した結合方式を選択できます。統計情報は、"統計コレクタ"により収集されます。T1からT2への結合とT1のスキャンは通常パイプライン化されるため、統計情報を収集し、選択すべき結合方式を解決し、結合を実行するためにはバッファリングが必要になります。一部の計画の決定は、行バッファリングなしで適応可能ですが、適応型結合ではバッファリング統計コレクタが必要になります。 オプティマイザは、収集すべき統計情報と、統計情報の各値に対して計画をどのように解決すべきかを判断します。オプティマイザは、変曲点を計算します。変曲点とは、計画の2つの選択肢の適合性が同一になる統計値です。たとえば、T1のスキャンにより生成される行数が10未満であればネステッド・ループ結合が最適で、T1のスキャンにより生成される行数が10以上であればハッシュ結合が最適となる場合、これら2つの計画の変曲点は10です。オプティマイザがこの変曲点の値を計算して、10行をバッファリングしてカウントするようにバッファリング統計コレクタを設定します。スキャンによって10行以上生成される場合は、この結合方式はハッシュ結合として解決され、10行未満の場合は、ネステッド・ループ結合として解決されます。 この解決によって選択された計画は最終計画と呼ばれます。オプティマイザが(見積もりに基づいて)選択する予定の計画がデフォルト計画です。サブ計画のすべてのオプションによるすべての操作を実際に格納した物理的な計画は、全体計画と呼ばれます。計画が解決されると、計画のハッシュ値が計画の新しい選択肢を示すように変更されます。計画の解決時には、計画表示API(DBMS_XPLAN内にあるもの)によって表示される計画も変更されます。あらゆる時点で、解決済みの計画の決定もあれば、未解決の計画の決定もあります。未解決の計画の選択肢については、計画表示APIを使用すると、オプティマイザによって(見積もりに基づいて)予定される計画が示されます。 EXPLAIN PLANにより問合せ計画を生成したときには、適応型サブ計画のいずれも解決されていないため、DBMS_XPLAN.DISPLAYによって計画を表示したときには、デフォルト計画が表示されます。たとえば、オプティマイザがネステッド・ループ結合を最適解と考えている場合は、EXPLAIN PLANおよびDBMS_XPLAN.DISPLAYで、次のようにネステッド・ループ結合計画が表示されます。 —————————————————————————————————————————————— | Id | Operation | Name | Rows | Bytes | —————————————————————————————————————————————— | 0 | SELECT STATEMENT | | 20 | 280 | | 1 | NESTED LOOPS | | 20 | 280 | | 2 | TABLE ACCESS FULL| T1 | 10000| 107K | | *3| INDEX UNIQUE SCAN| T2_PK| 1 | 3 | —————————————————————————————————————————————— ここで、この計画が実行時にハッシュ結合へと解決されたとすると、DBMS_XPLAN.DISPLAY_CURSORによって表示される計画にはハッシュ結合および全表スキャンで構成される最終計画が示されます。 ——————————————————————————————————————————————— | Id | Operation | Name | Rows | Bytes | ——————————————————————————————————————————————— | 0 | SELECT STATEMENT | | | | | *1| HASH JOIN | | 20 | 280 | | 2 | TABLE ACCESS FULL | T1 | 10000| 107K | | 3 | TABLE ACCESS FULL | T2 | 20 | 60 | ———————————————————————————————————————————————
|
次のステップ
その他の記事、書籍
|
Tom Kyteは、オラクルのServer Technologies部門に籍を置くデータベース・エバンジェリストで、1993年からオラクルに勤務しています。Expert Oracle Database Architecture(Apress、2005年/2010年)、Effective Oracle by Design(Oracle Press、2003)などの著書があります。