Customer 360 for financial services

Understand your customers, learn their behaviors, and predict their needs
Financial services organizations, especially those in the consumer space, such as retail banks, credit card issuers, private wealth management firms, and insurance companies, need intelligence on their customers, markets, products, and more to run successful marketing campaigns, cross-sell and upsell, and effectively support customers throughout the relationship. Some use cases—for example, making product recommendations and predicting and responding to customer needs when resolving a satisfaction issue—require real-time intelligence. Others require gathering the right data for model learning to generate insights that can be used to improve marketing, sales, operations, and, crucially, the customer experience.
In all these use cases, customer knowledge is vital. The concept of a 360-degree view of the customer has developed significantly, evolving from a basic understanding of the many interactions a customer has with an organization to a deep, detailed understanding of each customer as an individual with unique behaviors, wants, and needs that extend beyond their financial services interactions. Today’s customers expect every interaction to be easy, convenient, and intuitive—whether they’re ordering takeout, filing an insurance claim, or opening a checking account—and they want a consistent, cohesive, seamless experience whether they’re interacting online, using an app, or in person.
Highly satisfied customers are two and a half times more likely to open new accounts or adopt new products with their existing bank than those who are merely satisfied. While banks continue to invest to meet their customers’ rising expectations, they’ve struggled to keep pace with other retail sectors, held back by legacy IT infrastructure and data siloes—and the data quality and lineage challenges they cause. Even for institutions that boast a better-than-average customer experience, typically only one-half to two-thirds of customers rate their experience as excellent.
To meet their customers’ expectations, financial services organizations must continue to address the challenges caused by siloed data in legacy infrastructure while simultaneously employing machine learning, artificial intelligence, and 360-degree customer data to shift from reactive to predictive engagement. For organizations that accomplish this, the rewards can be significant; according to a McKinsey analysis, US retail banks that ranked in the top quartile for customer experience have had meaningfully higher deposit growth over the past three years compared with their peers, thanks to their ability to attract new customers and strengthen relationships with their existing ones.
Make your customer knowledge count with machine learning
The following architecture demonstrates how Oracle Data Platform is built to help financial services organizations apply advanced analytics, machine learning, and artificial intelligence to all the available data to provide the necessary insights to create highly relevant, in-the-moment, personalized customer experiences. This enables them to focus on proactive engagement, helping them flawlessly execute every touchpoint across the entire customer lifecycle, from shopping and account opening to onboarding, relationship expansion, and service delivery or insurance claims processing.
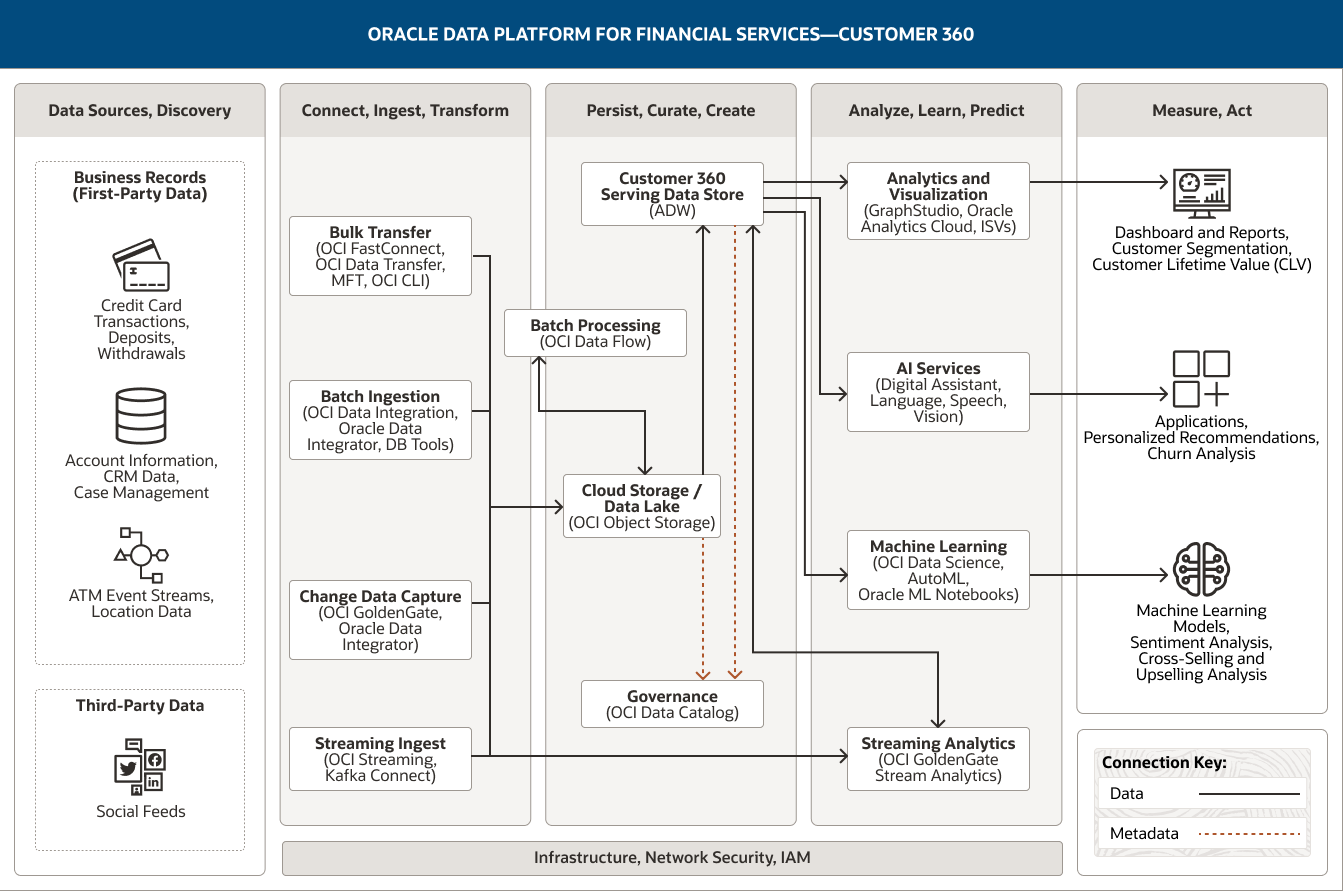
This image shows how Oracle Data Platform for financial services can be used to support a 360-degree view of customer activities. The platform includes the following five pillars:
- 1.Data Sources, Discovery
- 2.Connect, Ingest, Transform
- 3.Persist, Curate, Create
- 4.Analyze, Learn, Predict
- 5.Measure. Act
The Data Sources, Discovery pillar includes two categories of data.
- 1. Business records (first-party data) comprises credit card transactions, deposits, withdrawals, account information, CRM data, case management data, ATM event streams, and location data.
- 2. Third-party data includes social feeds.
The Connect, Ingest, Transform pillar comprises four capabilities.
- 1. Bulk transfer uses OCI FastConnect, OCI Data Transfer, MFT, and OCI CLI.
- 2. Batch ingestion uses OCI Data Integration, Oracle Data Integrator, and DB tools.
- 3. Change data capture uses OCI GoldenGate and Oracle Data Integrator.
- 4. Streaming ingest uses OCI Streaming and Kafka Connect.
All four capabilities connect unidirectionally into the cloud storage/data lake capability within the Persist, Curate, Create pillar.
Additionally, streaming ingest is connected to stream processing within the Analyze, Learn, Predict pillar.
The Persist, Curate, Create pillar comprises four capabilities.
- 1. The customer 360 serving data store uses Autonomous Data Warehouse and Exadata Cloud Service.
- 2. Cloud storage/data lake uses OCI Object Storage.
- 3. Batch processing uses OCI Data Flow.
- 4. Governance uses OCI Data Catalog.
These capabilities are connected within the pillar. Cloud storage/data lake is unidirectionally connected to the serving data store; it is also bidirectionally connected to batch processing.
One capability connects into the Analyze, Learn, Predict pillar: The serving data store connects unidirectionally to the analytics and visualization, AI services, and machine learning capabilities and bidirectionally to the streaming analytics capability.
The Analyze, Learn, Predict pillar comprises four capabilities.
- 1. Analytics and visualization uses Oracle Analytics Cloud, GraphStudio, and ISVs.
- 2. AI services uses Oracle Digital Assistant, OCI Language, OCI Speech, and OCI Vision.
- 3. Machine learning uses OCI Data Science, Auto ML, and Oracle Machine Learning Notebooks.
- 4. Streaming analytics uses OCI GoldenGate Stream Analytics.
The Measure, Act pillar comprises three consumers: dashboards and reports, applications, and machine learning models.
Dashboard & Reports comprises Customer Segmentation, and Customer Lifetime Value (CLV)
Applications comprises Personalized Recommendations and Churn Analysis
Machine Learning Models comprises Sentiment Analysis, Cross-Selling and Upselling Analysis
The three central pillars—Ingest, Transform; Persist, Curate, Create; and Analyze, Learn, Predict—are supported by infrastructure, network, security, and IAM.
There are three main ways to inject data into an architecture to enable financial services organisations to create a 360-degree view of their customers.
- To start our process, we need to ingest our customer transactions. Transactional data includes deposits and withdrawals; this data is highly structured and mastered in core banking or operational applications and systems. These datasets often comprise large volumes of often on-premises data, and in most cases, batch ingestion following source processing is typically most efficient. This data is generally ingested on a specific schedule, such as hourly at 30 minutes past the hour or daily at 2 p.m. (occasionally periods will be longer than this for complex processes).
- Customer data from customer relationship and experience systems usually requires little transformation or aggregation during ingestion and may be handled purely via a change data capture process to capture changes to datasets initially loaded in bulk. Further data can be sourced from operational systems, web clicks, social media feeds, and third-party customer data feeds.
- Streaming ingestion will be used to ingest data read from beacons in branch locations through IoT, machine-to-machine communications, and other means. Video imaging can also be consumed this way. Additionally, in this example, we intend to analyze and rapidly respond to consumer sentiment by analyzing social media messages, responses to first-party posts, and trending messages. Social media (application) messages/events will be ingested with the option to perform some basic transformation/aggregation before storing the data in cloud storage or a data lake. Additional stream analytics can be used to identify correlating consumer events and behavior, and identified patterns can be fed back (manually) for OCI Data Science to examine the raw data.
Data persistence and processing is built on three (optionally four) components.
- Ingested raw data is stored in cloud storage. We will use OCI Data Flow for the batch processing of this now persisted streamed data, such as tweets (JSON), location data, sensor data from beacons and apps, geo-mapping data, and product reference data. These processed datasets are returned to cloud storage for onward persistence, curation, and analysis and ultimately for loading in optimized form to the serving data store. Alternatively, depending on architectural preference, this can be accomplished with OCI Big Data Service as a managed Hadoop cluster.
- We have now created processed datasets ready to be persisted in optimized relational form for curation and query performance in the serving data store. This will enable us to identify and return the top trending product and consumer hashtags, which can be enriched with location, inventory, and product data from enterprise systems.
The ability to analyze, learn, and predict is built on two technologies.
- Analytics and visualization services deliver
descriptive analytics (describes current trends with histograms and
charts), predictive analytics (predicts future events, identifies
trends, and determines the probability of uncertain outcomes), and
prescriptive analytics (proposes suitable actions, leading to optimal
decision-making), enabling financial services institutions to answer
questions such as
- Does our upsell activity align with campaign predictions and has customer engagement activity changed as a result?
- What products are driving the most customer engagement? How do they compare with the best-selling products and services in a division or department?
- Are we seeing “channel fatigue,” and, if so, is it causing customers to disengage with the channel?
- Alongside the use of advanced analytics, machine learning models are developed, trained, and deployed. These models can be accessed via APIs, deployed within the serving data store, or embedded as part of the OCI GoldenGate streaming analytics pipeline.
- Our curated, tested, and high-quality data and models can have governance rules and policies applied and can be exposed as a data product (API) within a data mesh architecture for distribution across the financial services organization.
Meet customer expectations with automated intelligence
By leveraging all the available data across each customer’s lifecycle—including structured, semistructured, and unstructured data—and applying advanced big data analytics, machine learning, and AI to a complete record of previous customer interactions, financial services organizations can
- Design and provide highly relevant, in-the-moment, personalized customer experiences.
- Incorporate second- and third-party data to improve the customer experience and use analytics to predict (and influence) customer behavior.
- Use AI to recommend next-best actions, delivering more consistent customer interactions and refined customer outcomes.
- Evolve advisory and sales activities from being reactive to being proactive by leveraging robo-advisors both to provide self-service tools and to help employees serve customers better.
- Understand each customer’s history, anticipate their needs, and ensure their experience, at each stage of the customer lifecycle, exceeds their expectations.
Related resources
-
Use case
Risk calculations and regulatory reporting
Learn how Oracle Data Platform for financial services can help you reduce risk and improve regulatory compliance in this use case.
-
Use case
Improve financial services operations and performance
Learn how to manage financial services operations more efficiently using a data platform that helps improve performance with machine learning.
-
Use case
Fraud prevention and anti–money laundering
Learn how Oracle Data Platform for financial services can help you reduce risk and improve fraud detection and compliance in this use case.
Get started
Try 20+ Always Free cloud services, with a 30-day trial for even more
Oracle offers a Free Tier with no time limits on more than 20 services such as Autonomous AI Database, Arm Compute, and Storage, as well as US$300 in free credits to try additional cloud services. Get the details and sign up for your free account today.
-
What’s included with Oracle Cloud Free Tier?
- Two Autonomous AI Database instances, 20 GB each
- AMD and Arm Compute VMs
- 200 GB total block storage
- 10 GB object storage
- 10 TB outbound data transfer per month
- 10+ more Always Free services
- US$300 in free credits for 30 days for even more
Learn with step-by-step guidance
Experience a wide range of OCI services through tutorials and hands-on labs. Whether you're a developer, admin, or analyst, we can help you see how OCI works. Many labs run on the Oracle Cloud Free Tier or an Oracle-provided free lab environment.
-
Get started with OCI core services
The labs in this workshop cover an introduction to Oracle Cloud Infrastructure (OCI) core services including virtual cloud networks (VCN) and compute and storage services.
Start OCI core services lab now -
Autonomous AI Database quick start
In this workshop, you’ll go through the steps to get started using Oracle Autonomous AI Database.
Start Autonomous AI Database quick start lab now -
Build an app from a spreadsheet
This lab walks you through uploading a spreadsheet into an Oracle Database table, and then creating an application based on this new table.
Start this lab now
Explore over 150 best practice designs
See how our architects and other customers deploy a wide range of workloads, from enterprise apps to HPC, from microservices to data lakes. Understand the best practices, hear from other customer architects in our Built & Deployed series, and even deploy many workloads with our "click to deploy" capability or do it yourself from our GitHub repo.
Popular architectures
- Apache Tomcat with MySQL Database Service
- Oracle Weblogic on Kubernetes with Jenkins
- Machine-learning (ML) and AI environments
- Tomcat on Arm with Oracle Autonomous AI Database
- Log analysis with ELK Stack
- HPC with OpenFOAM
See how much you can save on OCI
Oracle Cloud pricing is simple, with consistent low pricing worldwide, supporting a wide range of use cases. To estimate your low rate, check out the cost estimator and configure the services to suit your needs.
Experience the difference:
- 1/4 the outbound bandwidth costs
- 3X the compute price-performance
- Same low price in every region
- Low pricing without long-term commitments
Contact sales
Interested in learning more about Oracle Cloud Infrastructure? Let one of our experts help.
-
They can answer questions like:
- What workloads run best on OCI?
- How do I get the most out of my overall Oracle investments?
- How does OCI compare to other cloud computing providers?
- How can OCI support your IaaS and PaaS goals?