Streaming – Häufig gestellte Fragen
Allgemeine Fragen
Was ist Oracle Cloud Infrastructure Streaming?
Oracle Cloud Infrastructure (OCI) Streaming bietet eine vollständig verwaltete, skalierbare und dauerhafte Messaging-Lösung für eingehende kontinuierliche Datenströme mit hohem Datenvolumen, die Sie in Echtzeit nutzen und verarbeiten können. Streaming ist in allen unterstützten Oracle Cloud Infrastructure-Regionen verfügbar. Eine Liste finden Sie auf der Seite Regionen und Availability-Domains.
Warum sollte ich Streaming verwenden?
Streaming ist ein serverloser Dienst, der das Infrastrukturmanagement entlastet – vom Netzwerk über den Storage bis hin zur Konfiguration, die zum Streamen Ihrer Daten erforderlich ist. Sie müssen sich nicht mehr um die Bereitstellung der Infrastruktur, die laufende Wartung oder Sicherheitspatches kümmern. Der Streaming-Dienst repliziert Daten synchron über drei Availability-Domains hinweg und gewährleistet so Hochverfügbarkeit und Datenbeständigkeit. In Regionen mit einer einzelnen Availability-Domain werden die Daten über drei Fehlerdomänen hinweg repliziert.
Wie kann ich Streaming verwenden?
Mit Streaming können Daten, die in Echtzeit aus Hunderten von Quellen generiert wurden, auf einfache Weise erfasst, gespeichert und verarbeitet werden. Die Anzahl der Anwendungsfälle ist nahezu unbegrenzt. Diese reichen vom Messaging bis zur Verarbeitung komplexer Daten-Streams. Im Folgenden sind einige der vielen Verwendungsmöglichkeiten von Streaming aufgeführt:
- Messaging: Verwenden Sie Streaming, um die Komponenten großer Systeme zu entkoppeln. Produzenten und Verbraucher können Streaming als asynchronen Nachrichtenbus nutzen und so unabhängig und in ihrem eigenen Tempo agieren.
- Kennzahl- und Protokollerfassung: Verwenden Sie Streaming als Alternative zu herkömmlichen Datei-Scraping-Ansätzen, um wichtige Betriebsdaten schnell für die Indizierung, Analyse und Visualisierung verfügbar zu machen.
- Erfassung von Daten zu Web- oder mobilen Aktivitäten: Verwenden Sie Streaming, um Aktivitäten von Websites oder mobilen Apps zu erfassen (z. B. Seitenaufrufe, Suchen oder andere Nutzeraktionen). Sie können diese Informationen zur Echtzeitüberwachung und -analyse sowie in Data Warehousing-Systemen für die Offline-Verarbeitung und -Berichterstellung verwenden.
- Verarbeitung von Infrastruktur- und Apps-Ereignissen: Verwenden Sie Streaming als einheitlichen Einstiegspunkt für Cloud-Komponenten, um deren Lebenszyklusereignisse für die Prüfung, das Rechnungswesen und damit verbundene Aktivitäten aufzuzeichnen.
Wie sehen die ersten Schritte mit Streaming aus?
Sie können mit der Nutzung von Streaming wie folgt beginnen:
- Erstellen Sie einen Stream mithilfe der Oracle Cloud Infrastructure-Konsole oder der CreateStream-API-Operation.
- Konfigurieren Sie Produzenten so, dass diese Nachrichten im Stream veröffentlichen. Siehe Nachrichten veröffentlichen.
- Aufbauen von Verbrauchern zum Lesen und Verarbeiten von Daten aus dem Stream. Siehe Nachrichten verarbeiten.
Alternativ können Sie auch Kafka-APIs verwenden, um einen Stream zu erstellen und diesen zu nutzen. Weitere Informationen finden Sie unter Verwenden von Streaming mit Apache Kafka.
Was sind die Service-Limits von Streaming?
Der Durchsatz von Streaming kann unbegrenzt skaliert werden, indem einem Stream Partitionen hinzugefügt werden. Bei der Verwendung von Streaming sind jedoch bestimmte Einschränkungen zu beachten:
- Die maximale Beibehaltungsfrist für Nachrichten in einem Stream beträgt sieben Tage.
- Die maximale Größe einer eindeutigen Nachricht, die in einem Stream produziert werden kann, beträgt 1 Megabyte (MB).
- Jede Partition kann einen Durchsatz von bis zu 1 MB pro Sekunde mit einer beliebigen Anzahl von Schreibanforderungen verarbeiten.
- Jede Partition kann eine maximale Gesamtdatenschreibrate von 1 MB pro Sekunde und eine Leserate von 2 MB pro Sekunde unterstützen.
Worin unterscheidet sich Streaming von einem warteschlangenbasierten Dienst?
Streaming bietet eine streambasierte Semantik. Die Stream-Semantik bietet strenge Bestellgarantien pro Partition, Wiederholbarkeit von Nachrichten, clientseitige Cursor und eine enorme horizontale Skalierbarkeit des Durchsatzes. Warteschlangen können diese Funktionen nicht bereitstellen. Warteschlangen können so gestaltet werden, dass sie bei Verwendung von FIFO-Warteschlangen Bestellgarantien bieten, jedoch nur auf Kosten eines erheblichen Leistungsaufwands.
Schlüsselkonzepte
Was ist ein Stream?
Ein Stream ist ein partitioniertes Anfügeprotokoll von Nachrichten, in das Produzentenanwendungen Daten schreiben und aus dem Verbraucheranwendungen Daten lesen können.
Was ist ein Stream Pool?
Ein Stream Pool ist eine Gruppierung, mit der Sie Streams organisieren und verwalten können. Stream Pools erleichtern die Bedienung, indem sie das Teilen von Konfigurationseinstellungen über mehrere Streams hinweg ermöglichen. Beispielsweise können Nutzer Sicherheitseinstellungen wie benutzerdefinierte Verschlüsselungsschlüssel im Stream Pool freigeben, um die Daten aller Streams im Pool zu verschlüsseln. Mit einem Stream Pool können Sie auch einen privaten Endpunkt für Streams erstellen, indem Sie den Internetzugriff auf alle Streams innerhalb eines Stream Pools beschränken. Für Kunden, welche die Kafka-Kompatibilitätsfunktion von Streaming verwenden, dient der Stream Pool als Stamm eines virtuellen Kafka-Clusters, sodass jede Aktion in diesem virtuellen Cluster auf diesen Stream Pool beschränkt werden kann.
Was ist eine Partition?
Eine Partition ist eine Grunddurchsatz-Leistungseinheit, die eine horizontale Skalierung sowie Parallelität von Produktion und Verarbeitung bei einem Stream ermöglicht. Eine Partition bietet eine Kapazität von 1 MB/s für die Dateneingabe und 2 MB/s für die Datenausgabe. Wenn Sie einen Stream erstellen, müssen Sie die Anzahl der benötigten Partitionen auf Basis der Durchsatzanforderungen Ihrer Anwendung spezifizieren. Sie können beispielsweise einen Stream mit 10 Partitionen erstellen. In diesem Fall können Sie einen Durchsatz von 10 MB/s bei der Eingabe und 20 MB/s bei der Ausgabe aus einem Stream erreichen.
Was ist eine Nachricht?
Eine Nachricht ist eine base64-codierte Dateneinheit, die in einem Stream gespeichert ist. Die maximale Größe einer Nachricht, die Sie für eine Partition in einem Stream produzieren können, beträgt 1 MB.
Was ist ein Schlüssel?
Ein Schlüssel ist eine Kennung, mit der verwandte Nachrichten gruppiert werden. Nachrichten mit demselben Schlüssel werden in die selbe Partition geschrieben. Streaming stellt sicher, dass jeder Verbraucher einer bestimmten Partition die Nachrichten dieser Partition immer in genau derselben Reihenfolge liest, in der sie geschrieben wurden.
Was ist ein Produzent?
Ein Produzent ist eine Clientanwendung, die Nachrichten in einen Stream schreiben kann.
Was ist ein Verbraucher und eine Verbrauchergruppe?
Ein Verbraucher ist eine Clientanwendung, die Nachrichten aus einem oder mehreren Streams lesen kann. Eine Verbrauchergruppe ist ein Satz von Instanzen, der Nachrichten von allen Partitionen in einem Stream koordiniert. Zu jedem bestimmten Zeitpunkt können die Nachrichten von einer bestimmten Partition nur von einem einzelnen Verbraucher in der Gruppe gelesen werden.
Was ist ein Cursor?
Ein Cursor ist ein Zeiger auf eine Position in einem Stream. Diese Position kann ein Zeiger auf einen bestimmten Offset, eine bestimmte Zeit in einer Partition oder den aktuellen Ort einer Gruppe sein.
Was ist ein Offset?
Jede Nachricht in einer Partition verfügt über eine Kennung, die als Offset bezeichnet wird. Verbraucher können Nachrichten beginnend bei einem bestimmten Offset und von jedem ausgewählten Offset aus lesen. Verbraucher können auch den zuletzt verarbeiteten Offset bestätigen, damit sie ihre Arbeit fortsetzen können, ohne eine Nachricht erneut wiederzugeben oder auszulassen, wenn sie anhalten und dann neu starten.
Sicherheit
Wie sicher sind meine Daten, wenn ich Oracle Cloud Infrastructure Streaming verwende?
Streaming stellt standardmäßig Datenverschlüsselung zur Verfügung, sowohl im Ruhezustand als auch während der Übertragung. Streaming ist vollständig in das Oracle Cloud Infrastructure Identity and Access Management (IAM) integriert. Dadurch können Sie mithilfe von Zugriffsrichtlinien Nutzern und Nutzergruppen selektiv Berechtigungen erteilen. Wenn Sie REST-APIs verwenden, können Sie Ihre Daten auch sicher von Streaming über SSL-Endpunkte mit dem HTTPS-Protokoll übertragen (PUT) und abrufen (GET). Darüber hinaus bietet Streaming eine vollständige Isolierung von Daten auf Tenant-Ebene, ohne dass es Probleme mit „lauten Nachbarn“ gibt.
Kann ich meinen eigenen Satz an Hauptschlüsseln verwenden, um die Daten in Streams zu verschlüsseln?
Streaming-Daten werden sowohl im Ruhezustand als auch während der Übertragung verschlüsselt. Dabei wird zugleich die Nachrichtenintegrität gewährleistet. Sie können Oracle die Verschlüsselung verwalten lassen oder Oracle Cloud Infrastructure Vault verwenden, um Ihre eigenen Verschlüsselungsschlüssel sicher zu speichern und zu verwalten, falls Sie bestimmte Compliance- oder Sicherheitsstandards erfüllen müssen.
Welche Sicherheitseinstellungen eines Stream Pools kann ich nach seiner Erstellung bearbeiten?
Sie können die Datenverschlüsselungseinstellungen des Stream Pools jederzeit bearbeiten, wenn Sie zwischen „Verschlüsselung bereitgestellt durch Oracle Schlüssel“ und „Verschlüsselung mit kundenverwalteten Schlüsseln“ wechseln möchten. Streaming erlegt Ihnen keinerlei Beschränkungen auf, wie oft diese Aktivität ausgeführt werden kann.
Wie verwalte und kontrolliere ich den Zugriff auf meinen Stream?
Streaming ist vollständig in Oracle Cloud Infrastructure IAM integriert. Jedem Stream ist einer Abteilung zugeordnet. Nutzer können rollenbasierte Zugriffssteuerungsrichtlinien festlegen, mit denen detaillierte Regeln auf Tenant- oder Abteilungsebene sowie auf der Ebene eines einzelnen Streams beschrieben werden können.
Die Zugriffs-Policy ist in der Form „Genehmige <Subjekt> zu <Verb> <Ressourcen-Typ> an <Ort> wo <Bedingungen>“ spezifiziert.
Welchen Authentifizierungsmechanismus müssen Kafka-Nutzer bei Streaming verwenden?
Die Authentifizierung beim Kafka-Protokoll verwendet Authentifizierungstoken und den SASL/PLAIN-Mechanismus. Sie können Token auf der Nutzerdatenseite der Konsole generieren. Für weitere Informationen siehe Arbeiten mit Auth-Token. Wir empfehlen, dass Sie eine dedizierte Gruppe/einen dedizierten Nutzer erstellen und dieser Gruppe/diesem Nutzer die Berechtigung zum Verwalten von Streams in der entsprechenden Abteilung oder Tenancy erteilen. Anschließend können Sie ein Auth-Token für den von Ihnen erstellten Nutzer generieren und in Ihrer Kafka-Clientkonfiguration verwenden.
Kann ich von meinem Virtual Cloud Network (VCN) aus privat auf Streaming-APIs zugreifen, ohne öffentliche IP-Adressen zu verwenden?
Private Endpunkte beschränken den Zugriff auf ein spezifisches Virtual Cloud Network (VCN) innerhalb Ihrer Tenancy, sodass auf deren Streams nicht über das Internet zugegriffen werden kann. Private Endpunkte ordnen dem Stream Pool eine private IP-Adresse innerhalb eines VCN zu, sodass der Streaming-Verkehr nicht das Internet durchqueren muss. Um einen privaten Endpunkt für das Streaming zu erstellen, benötigen Sie bei der Generierung des Stream Pools Zugriff auf ein VCN mit einem privaten Subnetz. Für weitere Informationen siehe Informationen zu privaten Endpunkten und VCNs und Subnetze.
Integrationen
Wie verwende ich Oracle Cloud Infrastructure Streaming mit Oracle Cloud Infrastructure Object Storage?
Sie können den Inhalt eines Streams direkt in einen Object Storage-Bucket schreiben, um die Daten im Stream für die Langzeitspeicherung beizubehalten. Dies lässt sich erreichen, indem Sie Kafka Connect für S3 mit Streaming verwenden. Weitere Informationen finden Sie im Blogeintrag Veröffentlichen im Object Storage vom Oracle Streaming Service aus.
Wie verwende ich Streaming mit Oracle Autonomous AI Database?
Sie können Daten aus einer Tabelle in einer Oracle Autonomous AI Transaction Processing-Instanz erfassen. Weitere Informationen finden Sie im Blogbeitrag Verwenden von Kafka Connect mit dem Oracle Streaming Service und Autonomous DB.
Wie verwende ich Streaming mit Micronaut?
Sie können die Kafka-SDKs verwenden, um Streaming-Nachrichten zu produzieren und zu verarbeiten. Dabei können Sie die integrierte Unterstützung von Micronaut für Kafka verwenden. Weitere Informationen finden Sie im Blogbeitrag Einfaches Messaging mit dem Support von Micronaut für Kafka und dem Oracle Streaming Service.
Wie verwende ich Streaming, um IoT-Daten von MQTT-Brokern aufzunehmen?
Weitere Informationen finden Sie im Blogbeitrag Aufnahme von IoT-Daten von MQTT-Brokern in den OCI-Oracle Streaming Service, OCI-Kafka Connect Harness und Oracle Kubernetes Engine.
Ist Oracle GoldenGate for Big Data mit Streaming kompatibel?
Oracle GoldenGate for Big Data ist jetzt für die Integration in Streaming zertifiziert. Weitere Informationen finden Sie unter Herstellen einer Verbindung zum Oracle Streaming Service in der Dokumentation zu Oracle GoldenGate for Big Data.
Gibt es eine Möglichkeit, Daten direkt von Streaming in Oracle Autonomous AI Data Lakehouse aufzunehmen?
Sie müssen Kafka JDBC Sink Connect verwenden, um Streaming-Daten direkt in Oracle Autonomous AI Lakehouse zu transportieren.
- Der Blogbeitrag Verwendung von Kafka Connect mit dem Oracle Streaming Service und Autonomous DB erläutert, wie ein Kafka Connect Source-Connector verwendet wird, der Daten aus dem Oracle Autonomous AI Lakehouse in Streams überträgt. Sie benötigen das Gegenteil, einen Sink-Konnektor.
- Der Blogbeitrag OSS-Daten in das ADW in nahezu Echtzeit übertragen erläutert, wie Sie eine externe Tabelle mit einem Objektspeicherpfad verwenden, um Daten in das Oracle Autonomous AI Lakehouse zu übertragen.
Tarife
Wie wird mir die Nutzung von Oracle Cloud Infrastructure Streaming berechnet?
Beim Streaming wird eine einfache Pay-as-you-use-Preisgestaltung verwendet. Dadurch ist sichergestellt, dass Sie nur für die von Ihnen genutzten Ressourcen bezahlen. Die Preisdimensionen umfassen
- GET/PUT-Anforderungspreis – Gigabyte übertragener Daten
- Preis für Speicher (basierend auf den genutzten Stunden des Aufbewahrungszeitraums): Gigabyte Speicher pro Stunde
Die neuesten Preisinformationen finden Sie auf der OCI Streaming-Seite.
Wird mir die Bereitstellung in Rechnung gestellt, auch wenn ich den Dienst gar nicht nutze?
Das branchenführende Preismodell von Streaming stellt sicher, dass Sie nur dann zahlen, wenn Sie den Service innerhalb der Standard-Servicelimits nutzen.
Fällt eine zusätzliche Gebühr für das Verschieben von Daten in Streaming oder aus Streaming heraus an?
Streaming berechnet für das Verschieben von Daten in den Dienst oder aus ihm heraus keine zusätzlichen Kosten. Darüber hinaus können Nutzer von der Leistung des Service Connector Hub profitieren, um Daten ohne zusätzlichen Aufpreis serverlos zu Streaming oder aus Streaming heraus zu verschieben.
Gibt es ein kostenloses Kontingent für Streaming?
Streaming steht momentan nicht für kostenlose Kontingente zur Verfügung.
Verwaltung von Oracle Cloud Infrastructure-Streams
Welche IAM-Berechtigungen benötige ich, um auf Streaming zuzugreifen?
Mit der Identitäts- und Zugriffsverwaltung können Sie kontrollieren, wer Zugriff auf Ihre Cloud-Ressourcen hat. Um Oracle Cloud Infrastructure-Ressourcen verwenden zu können, müssen Sie innerhalb einer von einem Administrator geschriebenen Richtlinie den erforderlichen Zugriffstyp erhalten – unabhängig davon, ob Sie die Konsole oder die REST-API mit einem SDK, CLI oder mit anderen Tools verwenden. Zugriffsrichtlinien werden in der Form:
Allow <subject> to <verb> <resource-type> in <location> where <conditions>
Die Richtlinie kann von Administratoren einer Tenancy verwendet werden
Allow group StreamAdmins to manage streams in tenancy
wodurch es einer festgelegten Gruppe von Stream-Administratoren ermöglicht wird, alle Funktionen von Streaming zu nutzen, sei es nun das Erstellen, Aktualisieren, Auflisten oder Löschen von Streams und ihrer zugehörigen Ressourcen. Sie können jedoch immer auch detailliertere Richtlinien angeben, sodass nur ausgewählte Nutzer in einer Gruppe berechtigt sind, eine bestimmte Teilmenge von Aktivitäten auszuführen, die für einen bestimmten Stream möglich sind. Wenn Sie mit Richtlinien noch nicht vertraut sind, sollten Sie Erste Schritte mit Richtlinien und Gemeinsame Richtlinien lesen. Tiefergehende Informationen zum Schreiben von Richtlinien für das Streaming finden Sie unter Details zum Streaming-Dienst in der IAM-Richtlinienreferenz.
Wie kann ich die Bereitstellung von Streams skalierbar automatisieren?
Sie können einen Stream und alle zugehörigen Komponenten wie IAM-Richtlinien, Partitionen, Verschlüsselungseinstellungen usw. mithilfe von Oracle Cloud Infrastructure Resource Manager oder dem Terraform-Anbieter für die Oracle Cloud Infrastructure bereitstellen. Informationen zum Terraform-Anbieter finden Sie unter Terraform-Thema zum Streaming-Dienst.
Wie bestimme ich die Anzahl der benötigten Partitionen?
Wenn Sie einen Stream erstellen, müssen Sie angeben, wie viele Partitionen der Stream haben soll. Der erwartete Durchsatz Ihrer Anwendung kann Ihnen dabei helfen, die Anzahl der Partitionen für Ihren Stream zu bestimmen. Multiplizieren Sie die durchschnittliche Nachrichtengröße mit der maximalen Anzahl der pro Sekunde geschriebenen Nachrichten, um Ihren erwarteten Durchsatz abzuschätzen. Da eine einzelne Partition auf eine Schreibrate von 1 MB pro Sekunde begrenzt ist, erfordert ein höherer Durchsatz zusätzliche Partitionen, um eine Drosselung zu vermeiden. Damit Sie Anwendungsspitzen besser verwalten können, empfehlen wir, Partitionen zuzuweisen, die geringfügig über Ihrem maximalen Durchsatz liegen.
Wie erstelle und lösche ich Partitionen in einem Stream?
Sie können bei der Generierung eines Streams Partitionen entweder in der Konsole oder programmgesteuert erstellen.
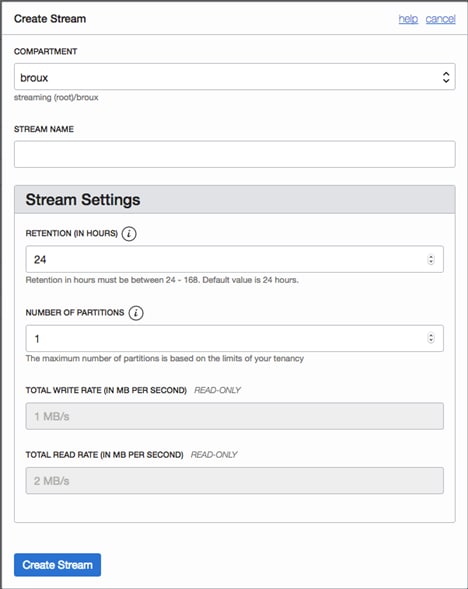
Benutzeroberfläche der Konsole:
Programmgesteuert:
Einen Stream erstellen
CreateStreamDetails streamDetails =
CreateStreamDetails.builder()
.compartmentId(compartmentId)
.name(streamName)
.partitions(partitions)
.build();
Ein detaillierteres Beispiel wird mit dem SDK zur Verfügung gestellt.
Streaming verwaltet die Partitionen intern, sodass Sie sich nicht mit der Verwaltung befassen müssen. Ein Nutzer kann eine Partition nicht direkt löschen. Wenn Sie einen Stream löschen, werden alle diesem Stream zugeordneten Partitionen ebenfalls gelöscht.
Was ist der Mindestdurchsatz, den ich für einen Stream anfordern kann?
Der Durchsatz eines Oracle Cloud Infrastructure-Streams wird durch eine Partition definiert. Eine Partition ermöglicht eine Dateneingabe von 1 MB pro Sekunde und eine Datenausgabe von 2 MB pro Sekunde.
Was ist der maximale Durchsatz, den ich für einen Stream anfordern kann?
Der Durchsatz eines Oracle Cloud Infrastructure-Streams kann durch Hinzufügen weiterer Partitionen erhöht werden. Es gibt keine theoretischen Obergrenzen für die Anzahl der Partitionen, die ein Stream enthalten kann. Für jede Oracle Cloud Infrastructure-Tenancy gilt jedoch bei Universal Credits-Konten ein Standardpartitionslimit von 5. Wenn Sie mehr Partitionen benötigen, können Sie aber jederzeit eine Erhöhung des Servicelimits anfordern.
Wie kann ich mithilfe der Oracle Cloud Infrastructure-Konsole die Servicelimits für meine Tenancy erhöhen?
Sie können mit den folgenden Schritten eine Erhöhung des Servicelimits anfordern:
- Öffnen Sie in der oberen rechten Ecke der Konsole das Nutzer-Menü und klicken Sie auf Tenancy:<tenancy_name>.
![]()
- Klicken Sie auf Service Limits und dann auf Erhöhung des Service-Limits anfordern.
![]()
- Füllen Sie das Formular aus, indem Sie Andere bei Servicekategorie und Andere Limits bei Ressource auswählen. Fordern Sie bei Grund für die Anfrage an, die Anzahl der Partitionen für den Streaming-Dienst in Ihrer Tenancy zu erhöhen.
Was sind einige der Best Practices für die Verwaltung von Streams?
Hier stellen wir Ihnen einige bewährte Methoden vor, die Sie beim Erstellen eines Streams berücksichtigen sollten:
- Stream-Namen sollten innerhalb eines Stream Pools eindeutig sein. Dies bedeutet, dass Sie zwei Streams mit demselben Namen nur dann in derselben Abteilung erstellen können, wenn sich diese in unterschiedlichen Stream Pools befinden.
- Nach der Erstellung eines Streams können Sie die Anzahl der in diesem enthaltenen Partitionen nicht mehr ändern. Wir empfehlen Partitionen zuzuweisen, die geringfügig höher sind als Ihr maximaler Durchsatz. Dies kann bei der Verwaltung von Anwendungsspitzen hilfreich sein.
- Die Beibehaltungsfrist eines Streams kann nach seiner Erstellung nicht mehr geändert werden. Standardmäßig werden Daten 24 Stunden lang in einem Stream gespeichert. Dies kann jedoch so konfiguriert werden, dass die Daten zwischen 24 und 168 Stunden beibehalten werden. Die in einem Stream gespeicherte Datenmenge hat keinen Einfluss auf die Leistung des Streams.
Produzieren von Nachrichten für einen Oracle Cloud Infrastructure-Stream
Wie produziere ich Nachrichten für einen Stream?
Sobald ein Stream erstellt wurde und sich im Status „Aktiv“ befindet, können Sie mit der Produktion von Nachrichten beginnen. Sie können entweder über die Konsole oder über die API für einen Stream produzieren.
Für die Konsole: Wechseln Sie auf der Konsole zum Abschnitt „Streaming-Dienst“, der sich in der Registerkarte Lösungen und Plattform > Analysen befindet. Wenn Sie bereits Streams erstellt haben, wählen Sie einen Stream in einer Abteilung aus und navigieren Sie zur Seite „Stream-Details“. Klicken Sie in der Konsole auf die Schaltfläche „Testnachricht produzieren“. Dadurch wird der Nachricht nach dem Zufallsprinzip ein Partitionsschlüssel zugewiesen. Anschließend wird die Nachricht in eine Partition im Stream geschrieben. Sie können diese Nachricht im Abschnitt Aktuelle Nachrichten anzeigen, indem Sie auf die Schaltfläche Nachrichten laden klicken.
Für APIs: Sie können entweder Oracle Cloud Infrastructure Streaming-APIs oder Kafka-APIs verwenden, um einen Stream zu erstellen. Die Nachricht wird auf einer Partition im Stream veröffentlicht. Wenn mehr als eine Partition vorhanden ist, geben Sie einen Schlüssel an, um auszuwählen, an welche Partition die Nachricht gesendet werden soll. Wenn Sie keinen Schlüssel spezifizieren, weist Streaming für Sie einen zu, indem es eine UUID generiert und die Nachricht an eine zufällige Partition sendet. Dadurch wird sichergestellt, dass Nachrichten ohne Schlüssel gleichmäßig auf alle Partitionen verteilt sind. Es wird jedoch empfohlen, immer einen Nachrichtenschlüssel anzugeben, damit Sie die Partitionierungsstrategie für Ihre Daten explizit steuern können.
Beispiele zum Produzieren von Nachrichten für einen Stream mithilfe von Streaming-SDKs finden Sie in der Dokumentation.
Woher weiß ich, welche Partition ein Produzent verwenden wird?
Wenn die Oracle Cloud Infrastructure-APIs zum Produzieren einer Nachricht verwendet werden, wird die Partitionierungslogik durch Streaming gesteuert. Dies wird als serverseitige Partitionierung bezeichnet. Als Nutzer wählen Sie auf der Grundlage des Schlüssels aus, an welche Partition gesendet werden soll. Der Schlüssel wird gehasht und der resultierende Wert wird verwendet, um die Partitionsnummer zu bestimmen, an welche die Nachricht gesendet werden soll. Nachrichten mit demselben Schlüssel werden an dieselbe Partition gesendet. Nachrichten mit unterschiedlichen Schlüsseln werden ggf. an unterschiedliche Partitionen oder an dieselben Partitionen gesendet.
Wenn Sie jedoch Kafka-APIs verwenden, um einen Stream zu erstellen, wird die Partitionierung vom Kafka-Client gesteuert, und der Partitionierer im Kafka-Client ist für die Partitionierungslogik verantwortlich. Dies wird als clientseitige Partitionierung bezeichnet.
Wie generiere ich einen effektiven Partitionsschlüssel?
Um eine gleichmäßige Verteilung von Nachrichten sicherzustellen, benötigen Sie einen effektiven Wert für Ihre Nachrichtenschlüssel. Berücksichtigen Sie für dessen Erstellung die Selektivität und Kardinalität Ihrer Streaming-Daten.
- Kardinalität: Berücksichtigen Sie die Gesamtzahl der eindeutigen Schlüssel, die je nach Anwendungsfall potenziell generiert werden könnten. Eine höhere Schlüsselkardinalität bedeutet im Allgemeinen eine bessere Verteilung.
- Selektivität: Berücksichtigen Sie die Anzahl der Nachrichten mit jedem Schlüssel. Höhere Selektivität bedeutet mehr Nachrichten pro Schlüssel, was zu Hotspots führen kann.
Streben Sie immer eine hohe Kardinalität und eine geringe Selektivität an.
Wie stelle ich sicher, dass die Nachrichten in derselben Reihenfolge an die Verbraucher geliefert werden, in der sie produziert wurden?
Streaming garantiert linearisierbare Lese- und Schreibvorgänge innerhalb einer Partition. Wenn Sie sicherstellen möchten, dass Nachrichten mit demselben Wert auf dieselbe Partition verschoben werden, sollten Sie für diese Nachrichten denselben Schlüssel verwenden.
Wie kann sich die Nachrichtengröße auf den Durchsatz meines Streams auswirken?
Eine Partition bietet eine Dateneingaberate von 1 MB/s und unterstützt bis zu 1.000 PUT-Nachrichten pro Sekunde. Wenn die Datensatzgröße geringer als 1 KB ist, beträgt die tatsächliche Dateneingaberate einer Partition daher weniger als 1 MB/s und wird durch die maximale Anzahl von PUT-Nachrichten pro Sekunde begrenzt. Aus den folgenden Gründen empfehlen wir, dass Sie Nachrichten stapelweise produzieren:
- Dies reduziert die Anzahl der an den Dienst gesendeten PUT-Anforderungen, wodurch eine Drosselung vermieden wird.
- Es ermöglicht einen besseren Durchsatz.
Die Größe eines Nachrichten-Batches sollte 1 MB nicht überschreiten. Wird über dieses Limit hinausgegangen, wird der Drosselmechanismus ausgelöst.
Wie gehe ich mit Nachrichten um, die größer als 1 MB sind?
Sie können entweder die Blockerstellung nutzen oder die Nachricht mithilfe von Oracle Cloud Infrastructure Object Storage senden.
- Chunking: Sie können große Nutzdaten in mehrere kleinere Blöcke aufteilen, die der Streaming-Dienst dann akzeptieren kann. Die Blöcke werden im Dienst auf dieselbe Weise gespeichert wie normale (nicht in Blöcke aufgeteilte) Nachrichten. Der einzige Unterschied besteht darin, dass der Verbraucher die Blöcke behalten und zur Nachricht kombinieren muss, sobald alle Blöcke gesammelt wurden. Die Blöcke in der Partition können mit normalen Nachrichten vermischt werden.
- Object Storage: Große Nutzdaten werden im Object Storage abgelegt und nur der Zeiger auf diese wird übertragen. Der Empfänger erkennt diese Art von Zeigernutzdaten, liest die Daten transparent aus dem Object Storage und stellt sie dem Endnutzer bereit.
Was passiert, wenn ich mit einer höheren Geschwindigkeit produziere, als es eine Partition zulässt?
Wenn ein Produzent mit einer Rate von mehr als 1 MB pro Sekunde produziert, wird die Anforderung gedrosselt und die Fehlermeldung 429, Zu viele Anfragen wird an den Client zurückgesendet, um zu signalisieren, dass zu viele Anforderungen pro Sekunde pro Partition empfangen werden.
Verarbeiten von Nachrichten aus einem Oracle Cloud Infrastructure-Stream
Wie lese ich Daten aus einem Stream?
Ein Verbraucher ist eine Entität, die Nachrichten aus einem oder mehreren Streams liest. Diese Entität kann alleine existieren oder Teil einer Verbrauchergruppe sein. Um Nachrichten zu verarbeiten, müssen Sie einen Cursor erstellen und diesen dann zum Lesen von Nachrichten verwenden. Ein Cursor zeigt auf eine Position in einem Stream. Diese Position kann ein bestimmter Offset oder eine bestimmte Zeit in einer Partition oder im aktuellen Ort einer Gruppe sein. Abhängig von der Position, von der Sie lesen möchten, stehen verschiedene Cursortypen zur Verfügung:TRIM_HORIZON, AT_OFFSET, AFTER_OFFSET, AT_TIME und LATEST.
Weitere Informationen finden Sie in der Dokumentation zum Verarbeiten von Nachrichten.
Wie viele Nachrichten kann ich zu einem jeweiligen Zeitpunkt maximal aus einem Stream verarbeiten?
Die Methode getLimit( ) der GetMessageRequest-Klasse gibt die maximale Anzahl von Nachrichten zurück. Sie können einen beliebigen Wert bis zu 10.000 angeben. Standardmäßig gibt der Dienst so viele Nachrichten wie möglich zurück. Berücksichtigen Sie Ihre durchschnittliche Nachrichtengröße, um zu vermeiden, dass der Durchsatz im Stream überschritten wird. Die Batch-Größen des Streaming-Dienstes GetMessages basieren auf der durchschnittlichen Nachrichtengröße, die für den jeweiligen Stream produziert wurde.
Wie vermeide ich doppelte Nachrichten an meine Verbraucher?
Streaming bietet Verbrauchern eine „Mindestens ein Mal“-Übermittlungssemantik. Wir empfehlen, dass sich Verbraucheranwendungen um Duplikate kümmern. Wenn beispielsweise eine zuvor inaktive Instanz der Verbrauchergruppe wieder der Gruppe beitritt und Nachrichten verarbeitet, die nicht von der zuvor zugewiesenen Instanz festgeschrieben wurden, besteht die Gefahr, dass Duplikate verarbeitet werden.
Woher weiß ich, ob ein Verbraucher in Rückstand zu geraten droht?
Ein Verbraucher gerät in Rückstand, wenn Sie schneller produzieren, als Sie verarbeiten können. Sie können anhand des Zeitstempels der Nachricht feststellen, ob Ihr Verbraucher in Verzug gerät. Wenn der Verbraucher in Rückstand gerät, sollten Sie einen neuen Verbraucher erzeugen, der einige der Partitionen des ersten Verbrauchers übernimmt. Wenn Sie auf einer einzelnen Partition in Verzug geraten, können Sie keine Wiederherstellung durchführen.
Ziehen Sie die folgenden Optionen in Erwägung:
- Erhöhen Sie die Anzahl der Partitionen im Stream.
- Wenn das Problem durch einen Hotspot verursacht wird, ändern Sie die Nachrichtenschlüsselstrategie.
- Reduzieren Sie die Nachrichtenverarbeitungszeit oder bearbeiten Sie Anforderungen parallel.
Wenn Sie wissen möchten, wie viele Nachrichten in einer bestimmten Partition noch verarbeitet werden müssen, verwenden Sie einen Cursor vom Typ LATEST, rufen Sie den Offset der nächsten veröffentlichten Nachricht ab und erstellen Sie das Delta mit dem Offset, den Sie gerade verarbeiten. Da wir keinen dichten Offset haben, können Sie nur eine grobe Schätzung erhalten. Wenn Ihr Produzent jedoch die Produktion einstellt, können Sie diese Informationen nicht abrufen, da Sie niemals den Offset der nächsten veröffentlichten Nachricht erhalten.
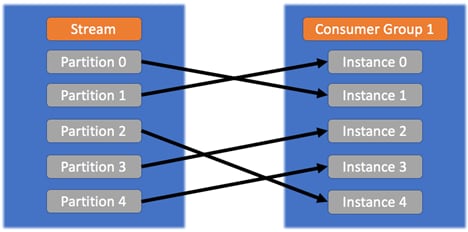
Wie funktionieren Verbrauchergruppen?
Verbraucher können so konfiguriert werden, dass sie Nachrichten als Teil einer Gruppe verarbeiten. Stream-Partitionen werden auf Mitglieder einer Gruppe verteilt, sodass Nachrichten von einer einzelnen Partition nur an einen einzelnen Verbraucher gesendet werden. Für Partitionszuweisungen wird ein Rebalancing durchgeführt, wenn sich Verbraucher der Gruppe anschließen oder diese verlassen. Weitere Informationen finden Sie in der Dokumentation zu Verbrauchergruppen.
Warum sollte ich Verbrauchergruppen verwenden?
Verbrauchergruppen bieten folgende Vorteile:
- Jede Instanz in einer Verbrauchergruppe empfängt Nachrichten von einer oder mehreren Partitionen, die ihr „automatisch“ zugewiesen werden. Diese Nachrichten werden von anderen Instanzen (die unterschiedlichen Partitionen zugewiesen sind) nicht empfangen. Auf diese Weise können wir die Anzahl der Instanzen bis zur Anzahl der Partitionen hochskalieren, wobei dann eine Instanz nur noch eine Partition liest. In diesem Fall befindet sich eine neue Instanz, die der Gruppe beitritt, im Ruhezustand, ohne einer Partition zugewiesen zu sein.
- Über Instanzen als Teil von verschiedenen Verbrauchergruppen zu verfügen, bedeutet, ein Muster zum Veröffentlichen/Abonnieren bereitzustellen, in dem die Nachrichten von verschiedenen Verbrauchergruppen-Partitionen an alle Instanzen in den verschiedenen Gruppen gesendet werden.
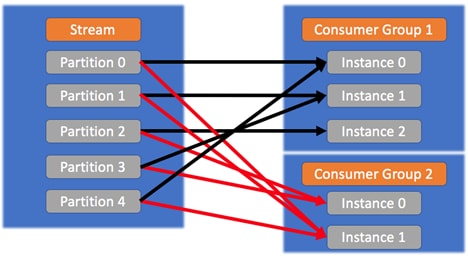
Innerhalb derselben Verbrauchergruppe sind die Regeln so, wie sie in der folgenden Abbildung gezeigt werden:![]()
In verschiedenen Gruppen erhalten die Instanzen dieselben Nachrichten, wie in der folgenden Abbildung gezeigt:
![]()
Dies ist nützlich, wenn die Nachrichten in einer Partition für verschiedene Anwendungen von Interesse sind, die sie auf unterschiedliche Weise verarbeiten. Alle interessierten Anwendungen sollten dieselben Nachrichten von der Partition erhalten. - Wenn eine Instanz einer Gruppe beitritt und genügend Partitionen verfügbar sind (d. h., das Limit einer Instanz pro Partition wurde nicht erreicht), wird ein Rebalancing gestartet. Die Partitionen werden den aktuellen Instanzen sowie der neuen Instanz neu zugewiesen. Wenn eine Instanz eine Gruppe verlässt, werden die Partitionen ebenso den verbleibenden Instanzen entsprechend zugewiesen.
- Offset-Commits werden automatisch verwaltet.
Gibt es ein Limit dafür, wie viele Verbrauchergruppen ich pro Stream haben kann?
Es besteht ein Limit von 50 Verbrauchergruppen pro Stream. Verbrauchergruppen sind vorübergehend. Sie verschwinden, wenn sie nicht für die Beibehaltungsfrist des Streams verwendet werden.
Welche Zeitüberschreitungen muss ich bei der Verwendung von Verbrauchern und Verbrauchergruppen beachten?
Für die folgenden Komponenten des Streaming-Dienstes sind Zeitüberschreitungen relevant:
- Cursor: Solange Sie weiterhin Nachrichten verarbeiten, müssen Sie keinen Cursor erstellen. Wenn die Nachrichtenverarbeitung länger als 5 Minuten anhält, muss der Cursor neu erstellt werden.
- Instanz: Wenn eine Instanz länger als 30 Sekunden keine Nachrichten mehr verarbeitet, wird sie aus der Verbrauchergruppe entfernt und ihre Partition wird einer anderen Instanz zugewiesen. Dies wird als Rebalancing bezeichnet.
Was ist Rebalancing innerhalb einer Verbrauchergruppe?
Rebalancing ist der Prozess, bei dem sich eine Gruppe von Instanzen, die zur selben Verbrauchergruppe gehören, koordiniert, um einen sich gegenseitig ausschließenden Satz von Partitionen zu besitzen, der zu einem bestimmten Stream gehört. Am Ende einer erfolgreichen Rebalancing-Operation für eine Verbrauchergruppe gehört jede Partition innerhalb des Streams einer einzelnen oder mehreren Verbraucherinstanzen innerhalb der Gruppe an.
Was löst eine Rebalancing-Aktivität innerhalb einer Verbrauchergruppe aus?
Wenn eine Instanz einer Verbrauchergruppe inaktiv wird, weil sie entweder länger als 30 Sekunden keinen Heartbeat sendet oder der Prozess beendet wird, wird innerhalb der Verbrauchergruppe ein Rebalancing ausgelöst. Dies geschieht, um die zuvor von der inaktiven Instanz verarbeiteten Partitionen unter Kontrolle zu halten und sie einer aktiven Instanz neu zuzuweisen. Wenn eine Instanz einer zuvor inaktiven Verbrauchergruppe der Gruppe beitritt, wird ebenso ein Rebalancing ausgelöst, um eine Partition zuzuweisen, mit deren Verarbeitung begonnen werden kann. Der Streaming-Dienst bietet keine Garantie, dass eine Instanz bei erneutem Beitritt zu einer Gruppe derselben Partition zugewiesen wird.
Wie erfolgt die Wiederherstellung nach einem Verbraucherausfall?
Zur Wiederherstellung nach einem Ausfall müssen Sie den Offset der zuletzt verarbeiteten Nachricht für jede Partition speichern, damit Sie diese Nachricht bei einem eventuellen Neustart Ihres Verbrauchers zum Starten der Verarbeitung verwenden können.
Hinweis: Speichern Sie den Cursor nicht. Er läuft nach 5 Minuten ab.
Wir stellen keinerlei Empfehlungen zum Speichern des Offsets der zuletzt verarbeiteten Nachricht zu Verfügung, daher können Sie jede beliebige Methode verwenden. Sie können den Cursor beispielsweise in einem anderen Stream, in einer Datei auf einer VM oder einem Object Storage-Bucket speichern. Lesen Sie beim Neustart Ihres Verbrauchers den Offset der zuletzt verarbeiteten Nachricht und erstellen Sie dann einen Cursor vom Typ AFTER_OFFSET. Geben Sie den Offset, den Sie gerade erhalten haben, an.
Kafka-Kompatibilität für Oracle Cloud Infrastructure Streaming
Wie integriere ich meine vorhandene Kafka-Anwendung in Streaming?
Der Streaming-Dienst bietet einen Kafka-Endpunkt, der von Ihren vorhandenen Apache Kafka-basierten Anwendungen verwendet werden kann. Es ist nur eine Konfigurationsänderung erforderlich, um eine vollständig verwaltete Kafka-Erfahrung zu erzielen. Die Kafka-Kompatibilität von Streaming bietet eine Alternative zum Ausführen Ihres eigenen Kafka-Clusters. Streaming unterstützt Apache Kafka 1.0 und neuere Client-Versionen und ist mit Ihren vorhandenen Kafka-Anwendungen, -Tools und -Frameworks kompatibel.
Welche Konfigurationsänderungen müssen vorgenommen werden, damit meine vorhandene Kafka-Anwendung mit Streaming interagieren kann?
Kunden mit vorhandenen Kafka-Anwendungen können auf Streaming migrieren, indem sie einfach die folgenden Parameter ihrer Kafka-Konfigurationsdatei ändern.
security.protocol: SASL_SSL
sasl.mechanism: PLAIN
sasl.jaas.config: org.apache.kafka.common.security.plain.PlainLoginModule required username="{username}" password="{pwd}"; bootstrap.servers: kafka.streaming.{region}.com:9092 # Application settings
topicName: [streamOcid]
Wie verwende ich Kafka Connect mit Streaming?
Um Ihre Kafka-Konnektoren mit Streaming zu verwenden, müssen Sie mithilfe der Konsole oder der Befehlszeilenschnittstelle (CLI) eine Kafka Connect-Konfiguration erstellen. Die Streaming-API bezeichnet so eine Konfiguration als Harness. Kafka Connect-Konfigurationen, die in einer bestimmten Abteilung erstellt wurden, funktionieren nur bei Streams in derselben Abteilung. Sie können mehrere Kafka-Konnektoren mit derselben Kafka Connect-Konfiguration verwenden. In Fällen, in denen Streams in separaten Abteilungen produziert oder verarbeitet werden müssen oder in denen mehr Kapazität erforderlich ist, um zu vermeiden, dass die Kafka Connect-Konfiguration die Drosselungslimits überschreitet (z. B. zu viele Konnektoren oder Konnektoren mit zu vielen Mitarbeitern), können Sie weitere Kafka Connector-Konfigurationen erstellen.
Welche Integrationen mit Produkten von Erstanbietern oder Drittanbietern ermöglicht Streaming?
Dank der Kafka Connect-Kompatibilität von Streaming können Sie von den vielen vorhandenen Konnektoren von Erst- und Drittanbietern profitieren, um Daten von Ihren Quellen zu Ihren Zielen zu verschieben. Zu den Kafka-Konnektoren für Oracle Produkte gehören:
- Oracle Cloud Infrastructure Object Storage (Verwendet Kafka Connect für S3)
- Kafka Connect Amazon S3-Source-Konnektor für Produzenten
- Kafka Connect Amazon S3-Sink-Konnektor für Verbraucher
- Oracle Integration Cloud
- Oracle AI Database (mit Kafka Connect JDBC)
- Oracle GoldenGate
Eine vollständige Liste der Kafka-Source- und Sink-Konnektoren von Drittanbietern finden Sie im offiziellen Confluent Kafka Hub.
Überwachung von Oracle Cloud Infrastructure-Streams
Wo kann ich meinen Stream überwachen?
Streaming ist vollständig in Oracle Cloud Infrastructure Monitoring integriert. Wählen Sie in der Konsole den Stream aus, den Sie überwachen möchten. Navigieren Sie auf der Seite Stream-Details zum Abschnitt Ressourcen und klicken Sie auf Überwachungsdiagramme erstellen, um Produzentenanfragen zu überwachen. Oder klicken Sie auf Überwachungsdiagramme verarbeiten, um die verbraucherseitigen Metriken zu überprüfen. Die Metriken sind nur auf Stream-Ebene und nicht auf Partitionsebene verfügbar. Eine Beschreibung der unterstützten Streaming-Metriken finden Sie in der Dokumentation.
Welche Statistiken sind bei der Überwachung von Streaming verfügbar?
Jede in der Konsole verfügbare Skala enthält die folgenden Statistiken:
- Rate, Summe und Mittelwert
- Minimum, Maximum und Anzahl
- P50, P90, P95, P99 und P99,9
Diese Statistiken werden für die folgenden Zeitintervalle angeboten:
- Automatisch
- 1 Minute
- 5 Minuten
- 1 Stunde
Für welche Metriken sollte ich typischerweise Alarme einstellen?
Erwägen Sie für Produzenten Alarme für die folgenden Metriken festzulegen:
- Put-Nachrichtenlatenz: Eine Erhöhung der Latenz bedeutet, dass die Veröffentlichung der Nachrichten länger dauert, was auf Netzwerkprobleme hinweisen kann.
- Gesamtdurchsatz der Put-Nachrichten:
- Eine bedeutende Erhöhung des Gesamtdurchsatzes könnte darauf hinweisen, dass das Limit von 1 MB pro Sekunde pro Partition erreicht wird und dieses Ereignis den Drosselungsmechanismus auslöst.
- Ein deutlicher Rückgang könnte bedeuten, dass der Client-Produzent ein Problem hat oder im Begriff ist anzuhalten.
- Gedrosselte Put-Nachrichtendatensätze: Es ist wichtig, benachrichtigt zu werden, wenn Nachrichten gedrosselt werden.
- Nicht erfolgreiche Put-Nachrichten: Es ist wichtig, benachrichtigt zu werden, wenn Put-Nachrichten fehlschlagen, damit das Ops-Team die Gründe ermitteln kann.
Erwägen Sie für Verbraucher, dieselben Alarme basierend auf den folgenden Metriken einzustellen:
- Get-Nachrichtenlatenz
- Gesamtdurchsatz der Get-Nachrichten
- Gedrosselte Get-Nachrichtenanforderungen
- Nicht erfolgreiche Get-Nachrichten
Woher weiß ich, dass mein Stream fehlerfrei ist?
Ein Stream ist fehlerfrei, wenn er sich in einem aktiven Zustand befindet. Wenn Sie Nachrichten für Ihren Stream produzieren können und eine erfolgreiche Antwort erhalten, ist der Stream fehlerfrei. Nachdem Daten im Stream produziert wurden, können Verbraucher für die Dauer der konfigurierten Beibehaltungsfrist auf diese zugreifen. Wenn API-Aufrufe zum Abrufen von Nachrichten erhöhte interne Serverfehler zurückgeben, ist der Dienst nicht fehlerfrei.
Ein fehlerfreier Stream wird auch durch fehlerfreie Kennzahlen gekennzeichnet:
- Put Messages Latency ist niedrig.
- Put Messages Total Throughput liegt bei 1 MB pro Sekunde pro Partition.
- Put Messages Throttled Records liegt nahe 0.
- Put Messages Failure liegt nahe 0.
- Get Messages Latency ist niedrig.
- Get Messages Total Throughput liegt bei 2 MB pro Sekunde pro Partition.
- Get Messages Throttled Requests liegt nahe 0.
- Get Messages Failure liegt nahe 0.
Wann werden Nachrichten in einem Stream gedrosselt?
Durch Drosselung wird angezeigt, dass der Stream keine neuen Lese- oder Schreibvorgänge mehr verarbeiten kann. Der Drosselmechanismus wird aktiviert, wenn die folgenden Schwellenwerte überschritten werden:
- Get-Nachrichten: Fünf Aufrufe pro Sekunde oder 2 MB pro Sekunde pro Partition
- Put-Nachrichten: 1 MB pro Sekunde pro Partition
- Verwaltungs- und Steuerebenenoperationen wie CreateCursor, ListStream usw. : Fünf Aufrufe pro Sekunde pro Stream
Wo finde ich die Liste der API-Fehler?
Details zu den API-Fehlern finden Sie in der Dokumentation.