Malha de dados empresariais
Soluções, casos de uso e estudos de caso
O que é uma data mesh?
Um tópico importante em software corporativo, a data mesh (malha de dados) é uma nova abordagem para pensar em dados com base em uma arquitetura distribuída para gerenciamento de dados. A ideia é tornar os dados mais acessíveis e disponíveis para usuários corporativos, conectando diretamente proprietários, produtores e consumidores de dados. A malha de dados visa melhorar os resultados de negócios de soluções centradas em dados, bem como impulsionar a adoção de arquiteturas de dados modernas.
De um ponto de vista comercial, a data mesh apresenta novas ideias a respeito de “product thinking em dados”. Ou seja, pensar os dados como um produto que cumpre um “trabalho a ser feito”, por exemplo, para melhorar a tomada de decisões, ajudar a detectar fraudes ou alertar o negócio sobre mudanças nas condições da cadeia de suprimentos. Para criar produtos de dados de alto valor, as empresas devem abordar mudanças de cultura e mentalidade e se comprometer com uma abordagem mais multifuncional para modelagem de domínio de negócios.
Do lado da tecnologia, a visão da Oracle sobre a malha de dados envolve três novas áreas de foco importantes para a arquitetura orientada a dados:
- Ferramentas que oferecem produtos para dados, como coletas, eventos e análises de dados
- Arquiteturas de dados distribuídas e descentralizadas que ajudam as organizações que optam por se afastar das arquiteturas monolíticas em direção à computação em várias nuvens e em nuvem híbrida ou que devem operar de maneira globalmente descentralizada
- Dados em movimento para organizações que não podem depender apenas de dados centralizados, estáticos e orientados a lotes e, em vez disso, migram para registros de dados orientados a eventos e pipelines centrados em streaming para eventos de dados em tempo real que fornecem análises mais oportunas
Outras preocupações importantes, como ferramentas de autoatendimento para usuários não técnicos e modelos fortes de governança de dados federados, são tão importantes para a arquitetura de malha de dados quanto para outras arquiteturas mais centralizadas e metodologias clássicas de gerenciamento de dados.
Um novo conceito de dados

Um abordagem de data mesh é uma mudança de paradigma para pensar nos dados como um produto. A malha de dados apresenta mudanças organizacionais e de processo que as empresas precisarão para gerenciar dados como um ativo de capital tangível do negócio. A perspectiva da Oracle para a arquitetura de malha de dados exige alinhamento entre os domínios de dados analíticos e organizacionais.
Uma malha de dados visa vincular os produtores de dados diretamente aos usuários de negócios e, na medida do possível, remover o intermediário de TI dos projetos e processos que ingerem, preparam e transformam recursos de dados.
O foco da Oracle na malha de dados tem sido fornecer uma plataforma para nossos clientes que possam atender a esses requisitos de tecnologia emergentes. Isso inclui ferramentas para produtos de dados; arquiteturas descentralizadas e orientadas a eventos; e padrões de streaming para dados em movimento. Para modelagem de domínio de produto de dados e outras preocupações sociotécnicas, a Oracle se alinha com o trabalho que está sendo feito pelo líder de pensamento em malha de dados, Zhamak Dehghani.
Benefícios de uma data mesh
Investir em uma data mesh pode trazer benefícios incríveis, como:
- Total clareza sobre o valor dos dados por meio da aplicação de práticas recomendadas de product thinking dos dados.
- Mais de 99,999% de disponibilidade de dados operacionais usando pipelines baseados em microsserviços para consolidação e migração de dados.
- Ciclos de inovação 10 vezes mais rápidos, mudando de ETL manual e orientado a lote para transformação e carregamento contínuos (CTL).
- Redução de mais de 70% na engenharia de dados, ganhos em CI/CD, ferramentas de pipeline de dados sem código e de autoatendimento e desenvolvimento ágil.
A data mesh é um mindset e muito mais
A maturidade mercadológica da data mesh ainda está em suas fases iniciais. Portanto, embora você possa ver uma variedade de conteúdo de marketing sobre uma solução que afirma ser “malha de dados”, muitas vezes essas chamadas soluções de malha de dados não se encaixam na abordagem ou nos princípios principais.
Uma malha de dados adequada é um mindset, um modelo organizacional e uma abordagem de arquitetura de dados corporativos com ferramentas de suporte. Uma solução de malha de dados deve ter uma combinação de pensamento de produto de dados, arquitetura de dados descentralizada, propriedade de dados orientada para o domínio, dados em movimento distribuídos, acesso de autoatendimento e forte governança de dados.
Uma data mesh não é:
- Um produto do fornecedor: não existe um software de data mesh.
- Um data lake ou data lakehouses: são complementares e podem fazer parte de uma malha de dados maior que abrange vários lagos, lagoas e sistemas operacionais de registro.
- Um catálogo ou gráfico de dados: Uma data mesh precisa de implementação física.
- Um projeto de consultoria única: a data mesh é uma jornada, não um projeto único.
- Um produto de análise de autoatendimento: análise de autoatendimento clássica, preparação de dados e organização de dados podem fazer parte de uma malha de dados, bem como de outras arquiteturas de dados.
- Um data fabric (tecido de dados): embora relacionado conceitualmente, o conceito de malha de dados é mais amplamente inclusivo de uma variedade de estilos de integração e gerenciamento de dados, enquanto a malha de dados está mais associada à descentralização e aos padrões de design orientados por domínio.
Por que escolher data mesh?
A triste verdade é que as arquiteturas de dados monolíticas do passado são complicadas, caras e inflexíveis. Com o passar dos anos, ficou claro que a maior parte do tempo e dos custos da plataforma de negócios digital, de aplicações a análises, são investidos em esforços de integração. Como resultado, boa parte das iniciativas de plataforma acabam falhando.
Embora a malha de dados não seja uma bala de prata para arquiteturas de dados centralizadas e monolíticas, os princípios, práticas e tecnologias da estratégia de malha de dados são projetados para resolver alguns dos objetivos de modernização mais urgentes e não abordados para iniciativas de negócios orientadas por dados.
Algumas das tendências em tecnologias que elevaram a necessidade de uma data mesh como solução incluem:
- 70-80% das transformações digitais não são bem-sucedidas
- Os custos operacionais com falta de dados estão crescendo
- As cláusulas de fidelidade para a nuvem são reais e podem ficar cada vez mais caras
- Os data lakes raramente são bem-sucedidos e estão focados apenas nas análises
- O aumento dos dados distribuídos está forçando uma arquitetura mais eficaz, eficiente e econômica
- Os silos organizacionais pioram os problemas de compartilhamento de dados
- Os dados são um catalisador para a vantagem competitiva, além de ser crucial para seu bom gerenciamento
Para saber mais sobre por que a malha de dados é necessária hoje, leia o artigo original de 2019 escrito por Zhamak Dehghani: How to Move Beyond a Monolithic Data Lake to a Distributed Data Mesh.
Definição de data mesh
A estratégia descentralizada por trás da malha de dados visa tratar os dados como um produto, criando uma infraestrutura de dados de autoatendimento para tornar os dados mais acessíveis aos usuários corporativos.
Focado em resultados
Product thinking em dados- Mudança de mindset para o ponto de vista do consumidor sobre os dados
- Os proprietários de domínio de dados são responsáveis por KPIs/SLAs de produtos de dados
- Mesmo domínio de dados e malha de tecnologia semântica para tudo
- Sem mais “jogar dados para o alto”
- Capture eventos de dados em tempo real diretamente de sistemas de registro e habilite pipelines de autoatendimento para fornecer dados quando necessário
- Um recurso essencial para habilitar dados descentralizados e produtos de dados alinhados à origem
Rejeita arquitetura de TI monolítica
Arquitetura descentralizada- Uma arquitetura criada para dados, serviços e nuvem descentralizados
- Projetado para suportar todos os tipos de eventos, formatos e complexidades
- Processamento de fluxo por padrão, processamento em lote por exceção
- Criado para capacitar os desenvolvedores e conectar diretamente os consumidores de dados aos produtores de dados
- Segurança, validação, procedência e transparência integradas
Recursos oferecidos pela Oracle para impulsionar uma data mesh
Quando a teoria passa para a prática, é necessário implementar soluções de classe empresarial para dados de missão crítica; é aí que a Oracle pode fornecer uma variedade de soluções confiáveis para potencializar uma malha de dados corporativa.
Crie e compartilhe produtos de dados
- Coletas de dados multimodelo com o banco de dados convergente da Oracle possibilitam a existência de produtos de dados de "mudança de forma" nos formatos exigidos pelos consumidores de dados
- Produtos de dados de autoatendimento como aplicações ou APIs, usando o Oracle APEX Application Development e o Oracle REST Data Services para fácil acesso e compartilhamento de todos os dados
- Ponto único de acesso às consultas do SQL ou virtualização de dados com Oracle Cloud SQL e Big Data SQL
- Produtos de dados para machine learning com a plataforma de ciência de dados da Oracle, catálogo de dados da Oracle Cloud Infrastructure (OCI) e plataforma de dados em nuvem da Oracle para data lakehouses
- Produtos de dados alinhados à origem como eventos em tempo real, alertas de dados e serviços de eventos de dados brutos com o Oracle Stream Analytics
- Produtos de dados alinhados ao consumidor de autoatendimento em uma solução Oracle Analytics Cloud abrangente
Opere uma arquitetura de dados descentralizada
- CI/CD ágil, estilo 'malha de serviço' para contêineres de dados usando bancos de dados conectáveis Oracle com Kubernetes, Docker ou nativo em nuvem com Autonomous Database
- Sincronização de dados entre regiões, várias nuvens e nuvem híbrida com microsserviços Oracle GoldenGate e Veridata, para uma malha de transação ativa-ativa confiável
- Acesse a maioria dos dados de eventos das aplicações, processos de negócios e da Internet das Coisas (IoT) com a Oracle Integration Cloud e Oracle Internet of Things Cloud
- Use o Oracle GoldenGate ou o Oracle Transaction Manager para filas de eventos de microsserviços para fornecimento de eventos de microsserviços ou ingestão em tempo real para Kafka e data lakes
- Traga padrões de design orientados por domínio descentralizado para sua malha de serviço com Oracle Verrazzano, Helidon e Graal VM
3 atributos principais de uma malha de dados
A malha de dados é mais do que apenas uma nova palavra da moda tecnológica. É um conjunto emergente de princípios, práticas e recursos de tecnologia que tornam os dados mais acessíveis e detectáveis. O conceito de malha de dados se distingue das gerações anteriores de abordagens e arquiteturas de integração de dados, incentivando uma mudança das arquiteturas gigantes e monolíticas de dados corporativos do passado para uma arquitetura moderna, distribuída e descentralizada orientada a dados do futuro. A base do conceito de malha de dados envolve os seguintes atributos principais:
1. Product thinking para dados
Uma mudança no mindset é o primeiro passo mais importante em direção a uma malha de dados. A disposição de adotar as práticas aprendidas de inovação é o trampolim para a modernização bem-sucedida da arquitetura de dados.
Essas áreas de prática aprendidas incluem:
- Design thinking — uma metodologia comprovada para resolver "problemas perversos", aplicada a domínios de dados corporativos para criar ótimos produtos de dados
- Teoria do trabalho a ser feito——aplicando uma inovação focada no cliente e um processo de inovação orientado a resultados para garantir que os produtos de dados corporativos resolvam problemas reais de negócios

As metodologias de design thinking trazem técnicas comprovadas que ajudam a quebrar os silos organizacionais que frequentemente bloqueiam a inovação multifuncional. A teoria das tarefas a serem feitas é a base crítica para projetar produtos de dados que atendam às metas específicas do consumidor final – ou tarefas a serem feitas – ela define a finalidade do produto.
Embora a abordagem do produto de dados tenha surgido inicialmente da comunidade de ciência de dados, agora está sendo aplicada a todos os aspectos do gerenciamento de dados. Em vez de construir arquiteturas de tecnologia monolíticas, a malha de dados se concentra nos consumidores de dados e nos resultados de negócios.
Embora o pensamento do produto de dados possa ser aplicado a outras arquiteturas de dados, é uma parte essencial de uma malha de dados. Para exemplos pragmáticos de como aplicar o pensamento de produto de dados, a equipe da Intuit escreveu uma análise detalhada de suas experiências.
Produtos de dados
Produtos de qualquer tipo – de commodities brutas a itens em sua loja local – são produzidos como ativos de valor, destinados a serem consumidos e têm um trabalho específico a ser feito. Os produtos de dados podem assumir várias formas, dependendo do domínio de negócios ou do problema a ser resolvido, e podem incluir:
- Análises avançadas — relatórios e painéis históricos/em tempo real
- Conjuntos de dados — coletas de dados em diferentes formas/formatos
- Modelos: objetos de domínio, modelos de dados, recursos de machine learning (ML)
- Algoritmos — modelos de ML, pontuação, regras de negócios
- Serviços de dados e APIs — documentos, cargas úteis, tópicos, APIs REST e muito mais
Um produto de dados é criado para consumo, normalmente de propriedade fora da TI e requer rastreamento de atributos adicionais, como:
- Mapa das partes interessadas—Quem é o proprietário cria e consome este produto?
- Embalagem e documentação—Como é consumido? Como funciona a rotulação?
- Propósito e valor—Qual é o valor implícito/explícito do produto? Há depreciação ao longo do tempo?
- Qualidade e consistência—Quais são os KPIs e SLAs de uso? É verificável?
- Proveniência, ciclo de vida e governança—Existe confiança e explicabilidade dos dados?
2. Arquitetura descentralizada de dados

Os sistemas de TI descentralizados são uma realidade moderna e, com o surgimento de aplicativos SaaS e infraestrutura de nuvem pública (IaaS), a descentralização de aplicações e dados chegou para ficar. As arquiteturas de software de aplicações estão mudando dos monólitos centralizados do passado para os microsserviços distribuídos (uma malha de serviço). A arquitetura de dados seguirá a mesma tendência de descentralização, com os dados se tornando mais distribuídos em uma variedade maior de locais físicos e em muitas redes. Chamamos isso de malha de dados.
O que é malha de dados?
Uma malha é uma topologia de rede que permite que um grande grupo de nós não hierárquicos trabalhem juntos de forma colaborativa.
Alguns exemplos comuns em tecnologia incluem:
- WiFiMesh—muitos nós trabalhando juntos para melhor cobertura
- ZWave/Zigbee—redes de dispositivos domésticos inteligentes de baixo consumo de energia
- Malha 5G—conexões celulares mais confiáveis e resilientes
- Starlink — malha de banda larga via satélite em escala global
- Malha de serviço — uma maneira de fornecer controles unificados sobre microsserviços descentralizados (software de aplicativo)
A malha de dados está alinhada a esses conceitos de malha e fornece uma maneira descentralizada de distribuição de dados em redes virtuais/físicas e em grandes distâncias. Arquiteturas monolíticas de integração de dados herdadas, como ETL e ferramentas de federação de dados, e ainda mais recentemente, serviços de nuvem pública, como AWS Glue, exigem uma infraestrutura altamente centralizada.
Uma solução completa de malha de dados deve ser capaz de operar em uma estrutura multicloud, abrangendo potencialmente desde sistemas locais, várias nuvens públicas e até redes de borda.
Segurança distribuída
Em um mundo onde os dados são altamente distribuídos e descentralizados, o papel da segurança da informação é primordial. Ao contrário dos monólitos altamente centralizados, os sistemas distribuídos devem delegar as atividades necessárias para autenticar e autorizar vários usuários a diferentes níveis de acesso. Delegar confiança com segurança entre redes é difícil de fazer bem.
Algumas considerações incluem:
- Criptografia em repouso — como dados/eventos gravados no armazenamento
- Autenticação distribuída — para serviços e armazenamentos de dados, como mTLS, certificados, SSO, armazenamentos secretos e cofres de dados
- Criptografia em movimento — como dados/eventos que estão fluindo na memória
- Gerenciamento de identidade — serviços do tipo LDAP/IAM, multiplataforma
- Autorizações distribuídas—para endpoints de serviço redigirem dados
Por exemplo:Open Policy Agent (OPA) sidecar para colocar a política ponto de decisão (PDP) no cluster de contêiner/K8S em que o endpoint de microsserviço está processando. O LDAP/IAM pode ser qualquer serviço habilitado para JWT. - Mascaramento determinístico — para ofuscar dados de PII de maneira confiável e consistente
A segurança em qualquer sistema de TI pode ser difícil, e é ainda mais difícil fornecer alta segurança em sistemas distribuídos. No entanto, esses problemas são solucionáveis.
Domínios descentralizados de dados
Um princípio central da malha de dados é a noção de distribuição de propriedade e responsabilidade. A melhor prática é federar a propriedade de produtos de dados e domínios de dados para as pessoas em uma organização que estão mais próximas dos dados. Na prática, isso pode se alinhar aos dados de origem (por exemplo, fontes de dados brutos, como os sistemas operacionais de registro/aplicações) ou aos dados analíticos (por exemplo, dados tipicamente compostos ou agregados formatados para facilitar o consumo pelos consumidores de dados). Em ambos os casos, os produtores e consumidores dos dados geralmente estão alinhados às unidades de negócios e não às organizações de TI.
As formas antigas de organizar domínios de dados muitas vezes caem na armadilha de se alinhar com as soluções tecnológicas, como ferramentas de ETL, data warehouses, data lakes ou a organização estrutural de uma empresa (recursos humanos, marketing e outras linhas de negócios). No entanto, para um determinado problema de negócios, os domínios de dados geralmente são mais bem alinhados ao escopo do problema que está sendo resolvido, ao contexto de um processo de negócios específico ou à família de aplicações em uma área de problema específica. Em grandes organizações, esses domínios de dados geralmente atravessam as organizações internas e as pegadas de tecnologia.
A decomposição funcional dos domínios de dados assume uma prioridade elevada e de primeira classe na malha de dados. Várias metodologias de decomposição de dados para modelagem de domínio podem ser adaptadas à arquitetura de malha de dados, incluindo modelagem clássica de data warehouse (como Kimball e Inmon) ou modelagem de cofre de dados, mas a metodologia mais comum atualmente sendo testada na arquitetura de malha de dados é o design orientado a domínio (DDD ). A abordagem DDD surgiu da decomposição funcional de microsserviços e agora está sendo aplicada em um contexto de malha de dados.
3. Dados dinâmicos em movimento
Uma área importante em que a Oracle acrescentou à discussão da malha de dados é elevar a importância dos dados em movimento como um ingrediente-chave para uma malha de dados moderna. Dados em movimento são fundamentalmente essenciais para tirar a malha de dados do mundo legado do processamento monolítico, centralizado e em lote. Os recursos de dados em movimento respondem a várias perguntas principais da malha de dados, como:
- Como podemos acessar produtos de dados alinhados à origem em tempo real?
- Quais ferramentas podem fornecer os meios para distribuir transações de dados confiáveis em uma malha de dados fisicamente descentralizada?
- Quando preciso disponibilizar eventos de dados como APIs de produtos de dados, o que posso usar?
- Para produtos de dados analíticos que devem estar continuamente atualizados, como eu me alinharia aos domínios de dados e garantiria confiança e validade?
Essas questões não são apenas uma questão de “detalhes de implementação”, elas são de importância central para a própria arquitetura de dados. Um projeto orientado por domínio para dados estáticos usará técnicas e ferramentas diferentes de um processo dinâmico de dados em movimento do mesmo projeto. Por exemplo, em arquiteturas de dados dinâmicas, o registro de dados é a fonte central da verdade para eventos de dados.
Razões-gerais de dados orientados a eventos

Os livros-razão são um componente fundamental para fazer uma arquitetura de dados distribuída funcionar. Assim como em um livro de contabilidade, um livro de dados registra as transações à medida que elas acontecem.
Quando distribuímos o livro-razão, os eventos de dados tornam-se “repetitíveis” em qualquer local. Alguns livros são um pouco como um gravador de voo de avião usado para alta disponibilidade e recuperação de desastres.
Ao contrário dos armazenamentos de dados centralizados e monolíticos, os ledgers distribuídos são criados especificamente para acompanhar eventos atômicos e/ou transações que ocorrem em outros sistemas (externos).
Uma malha de dados não é apenas um único tipo de razão-geral. Dependendo dos casos de uso e requisitos, uma malha de dados pode fazer uso de diferentes tipos de registros de dados orientados a eventos, incluindo o seguinte:
- Registro de eventos de uso geral—como Kafka ou Pulsar
- Registo de eventos de dados—ferramentas de CDC/replicação distribuídas
- Middleware de mensagens, incluindo ESB, MQ, JMS e AQ
- Lista de blockchain — para transações seguras, imutáveis e com várias partes
Juntos, esses registros podem atuar como uma espécie de log de eventos durável para toda a empresa, fornecendo uma lista contínua de eventos de dados que ocorrem em sistemas de registro e sistemas de análise.
Fluxos de dados poliglotas

Os fluxos de dados poliglotas são mais prevalentes do que nunca. Eles variam de acordo com os tipos de eventos, cargas úteis e semânticas de transação diferentes. Uma malha de dados deve oferecer suporte aos tipos de fluxo necessários para uma variedade de cargas de trabalho de dados corporativos.
Eventos simples:
- Base64 / JSON — eventos brutos e sem esquema
- Telemetria bruta — eventos esparsos
Registro de aplicativos básicos/eventos da Internet das Coisas (IoT):
- JSON/Protobuf— pode ter esquema
- MQTT—IoT- protocolos específicos
Eventos do processo de negócios do aplicativo:
- eventos SOAP/REST — XML/XSD, JSON
- B2B — protocolos e padrões de intercâmbio
Eventos/transações de dados:
- Registros de alterações lógicas—LCR, SCN, URID
- Limites consistentes—confirmações versus operações
Processamento de dados de fluxos
O processamento de fluxo é como os dados são manipulados em um fluxo de eventos. Ao contrário das “funções lambda”, o processador de fluxo mantém o estado dos fluxos de dados em uma determinada janela de tempo e pode aplicar consultas analíticas muito mais avançadas nos dados.
- Limites, alertas e monitoramento de telemetria
- Funções RegEx, operações matemáticas/lógicas e concatenação
- Registro a registro, substituições e mascaramento
Filtragem básica de dados:
ETL simples:
PCE e ETL complexo:
- Processamento complexo de eventos (PCE)
- Processamento DML (ACID) e grupos de tuplas
- Agregados, pesquisas e junções complexas
Análise de streaming:
- Análise de séries temporais e janelas de tempo personalizadas
- Geoespacial, machine learning e IA incorporada
Outros atributos e princípios importantes
Claro, existem mais do que apenas três atributos de uma malha de dados. Nós nos concentramos nos três acima como uma forma de chamar a atenção para os atributos que a Oracle acredita serem alguns dos aspectos novos e exclusivos da abordagem de malha de dados moderna emergente.
Outros atributos importantes da malha de dados incluem:
- Ferramentas de autoatendimento — a malha de dados abrange a tendência geral de gerenciamento de dados para o autoatendimento, os desenvolvedores do Citizen devem vir cada vez mais das fileiras dos proprietários de dados
- Governança de dados— a malha de dados também adotou a tendência de longa data em direção a um modelo de governança federada mais formalizado, defendido por diretores de dados, administradores de dados e fornecedores de catálogo de dados por muitos anos.
- Usabilidade de dados— investigando os princípios da malha de dados, há muito trabalho básico para garantir que os produtos de dados sejam altamente utilizáveis. Os princípios para produtos de dados estarão preocupados com dados valiosos, utilizáveis e viáveis de compartilhar.
7 casos de uso de malha de dados
Uma malha de dados bem-sucedida atende aos casos de uso para domínios de dados operacionais e analíticos. Os sete casos de uso a seguir ilustram a amplitude de recursos que uma malha de dados traz para os dados corporativos.
Ao integrar dados e análises operacionais em tempo real, as empresas podem tomar melhores decisões operacionais e estratégicas.MIT Sloan School of Management
1. Modernização de aplicação
Olhando além das migrações de 'lift and shift' de arquiteturas de dados monolíticas para a nuvem, muitas organizações também procuram aposentar seus aplicativos centralizados do passado e migrar para uma arquitetura de aplicativos de microsserviços mais moderna.


Mas os monólitos de aplicações legadas geralmente dependem de bancos de dados maciços, levantando a questão de como fasear o plano de migração para diminuir interrupções, riscos e custos. Uma malha de dados pode fornecer um importante recurso operacional de TI para clientes que fazem transições em fases de monólitos para arquitetura de malha. Por exemplo:
- Descarregamento de subdomínio de transações de banco de dados, como filtragem de dados por 'contexto limitado'
- Replicação de transações bidirecional para migrações em fases
- Sincronização entre plataformas, como de mainframe para DBaaS
No jargão dos arquitetos de microsserviços, essa abordagem usa uma caixa de saída de transação bidirecional para habilitar o padrão de migração de figueira estranguladora , um contexto limitado por vez.
2. Disponibilidade e continuidade dos dados

As aplicações críticas para os negócios exigem KPIs e SLAs muito altos em relação à resiliência e continuidade. Independentemente de esses aplicativos serem monolíticos, microsserviços ou algo intermediário, eles não podem ser desativados!
Para sistemas de missão crítica, um modelo de dados distribuído de consistência eventual geralmente não é aceitável. No entanto, essas aplicações devem operar em muitos data centers. Isso levanta a questão da continuidade dos negócios, "Como posso executar meus aplicativos em mais de um data center e ainda garantir dados corretos e consistentes"
Independentemente de as arquiteturas monolíticas estarem usando "conjuntos de dados fragmentados" ou os microsserviços estarem sendo configurados para alta disponibilidade entre sites, a malha de dados oferece dados corretos e de alta velocidade a qualquer distância.
Uma malha de dados pode oferecer a base para dados descentralizados, mas ainda assim 100% corretos entre as localidades. Por exemplo:
- Transações lógicas de latência muito baixa (plataforma cruzada)
- Garantias capazes de ACID para dados corretos
- Resolução multi-ativa, bidirecional e de conflito
3. Caixa de saída de eventos e transação


Uma plataforma moderna de malha de serviço de serviço usa eventos para intercâmbio de dados. Em vez de depender do processamento em lote na camada de dados, as cargas úteis de dados fluem continuamente quando os eventos acontecem na aplicação ou no armazenamento de dados.
Para algumas arquiteturas, os microsserviços precisam trocar cargas úteis de dados entre si. Outros padrões requerem intercâmbio entre aplicativos monolíticos ou armazenadores de dados. Isso levanta a pergunta: “ Como posso trocar de forma confiável a carga útil de dados de microsserviço entre meus aplicativos e dados?”
Uma malha de dados pode fornecer a tecnologia de fundação para o intercâmbio de dados centrados em microsserviços. Por exemplo:
- Microsserviço para microsserviço dentro do contexto
- Microsserviço para microsserviço dentro do contexto
- Monólito para/para o microsserviço
Padrões de microsserviços, como fornecimento de eventos, CQRs e Outbox de transação, são soluções comumente entendidas; Uma malha de dados fornece as ferramentas e estruturas para tornar esses padrões repetíveis e confiáveis em escala.
4. Integração orientada a eventos
Além dos padrões de design de microsserviços, a necessidade de integração corporativa se estende a outros sistemas de TI, como bancos de dados, processos de negócios, aplicações e dispositivos físicos de todos os tipos. Uma malha de dados fornece a base para a integração de dados em movimento.
Os dados em movimento geralmente são orientados por eventos. Uma ação do usuário, um evento de dispositivo, uma etapa do processo ou um comprometimento de armazenamento de dados podem iniciar um evento com uma carga útil de dados. Essas cargas de dados são cruciais para integrar sistemas da Internet das Coisas (IoT), processos de negócios e bancos de dados, data warehouses e lagos de dados.
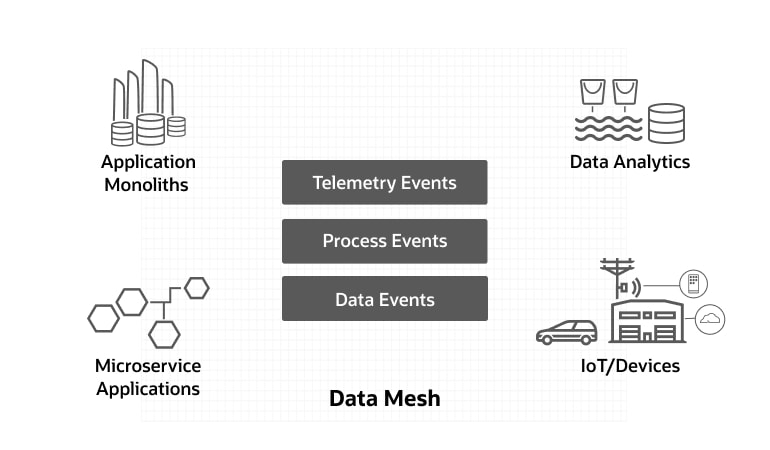
Uma malha de dados fornece a tecnologia de fundação para integração em tempo real em toda a empresa. Por exemplo:
- Conectando eventos de dispositivos do mundo real aos sistemas de TI
- Integração de processos de negócios em sistemas ERP
- Alinhando bancos de dados operacionais com dados analíticos
As grandes empresas naturalmente terão uma mistura de sistemas antigos e novos, monólitos e microsserviços, lojas de dados operacionais e analíticas; Uma malha de dados pode ajudar a unificar esses recursos em diferentes domínios de negócios e dados.
5. Ingestão de streaming (para análises avançadas)

As lojas de dados analíticas podem incluir dados de dados, data warehouses, cubos OLAP, data lakes e tecnologias de dados de dados.
De um modo geral, existem apenas duas maneiras de trazer dados para esses dados analíticos:
- Carregamento em lote/micro-lotes-em um agendador de tempo
- Ingestão de streaming - carregando eventos de dados contínuos
Uma malha de dados fornece a base para uma capacidade de ingestão de dados de streaming. Por exemplo:
- Eventos de dados de bancos de dados ou dados
- Eventos de dispositivo da telemetria física
- Registro de eventos de aplicações ou transações comerciais
A ingestão de eventos por fluxo pode reduzir o impacto nos sistemas de origem, melhorar a fidelidade dos dados (importante para a ciência dos dados) e permitir análises em tempo real.
6. Pipelines de dados de streaming

Uma vez ingerido nos datastores analíticos, geralmente é necessário que os pipelines de dados preparem e transformem os dados em diferentes estágios de dados ou zonas de dados. Esse processo de refinamento de dados geralmente é necessário para os produtos de dados analíticos a jusante.
Uma malha de dados pode fornecer uma camada de pipeline de dados governada independentemente que trabalha com armazenamento analítico de dados, fornecendo os seguintes serviços principais:
- Descoberta de dados de autoatendimento e preparação de dados
- Governança de recursos de dados entre domínios
- Preparação e transformação de dados em formatos de produto de dados necessários
- Verificação de dados por política que garante consistência
Esses pipelines de dados devem ser capazes de trabalhar em diferentes dados físicos (como martes, armazéns ou lagos) ou como um "fluxo de dados de pushdown" nas plataformas de dados analíticas que suportam dados de streaming, como a Apache Spark e outras tecnologias de data lakehouse.
7. Análises avançadas do streaming

Os eventos estão acontecendo continuamente. A análise dos eventos em um fluxo pode ser crucial para entender o que está acontecendo de momento a momento.
Esse tipo de análise baseada em séries temporais dos fluxos de eventos em tempo real pode ser importante para os dados do dispositivo IoT no mundo real e para entender o que está acontecendo em seus data centers de TI ou em transações financeiras, como o monitoramento de fraudes.
Uma malha de dados completa incluirá os recursos fundamentais para analisar eventos de todos os tipos, em muitos tipos diferentes de janelas de tempo de evento. Por exemplo:
- Análise de fluxo de eventos simples (eventos da web)
- Monitoramento de atividades comerciais (eventos SOAP/REST)
- Processamento de eventos complexos (correlação multistristream)
- Análise de eventos de dados (em transações DB/ACID)
Como os pipelines de dados, as análises de streaming podem ser capazes de executar dentro da infraestrutura estabelecida do Data Lakehouse, ou separadamente, como serviços nativos em nuvem.
Alcançar o valor máximo, operando uma malha comum em toda a propriedade de dados
Aqueles na borda principal da integração de dados estão buscando integração operacional e analítica em tempo real a partir de uma coleção diversificada de dados de datastores resilientes. As inovações têm sido implacáveis e rápidas à medida que a arquitetura de dados evolui para a análise de streaming. A alta disponibilidade operacional levou a análises em tempo real, e a automação de engenharia de dados simplifica a preparação de dados, permitindo que cientistas e analistas de dados com ferramentas de autoatendimento.
Resumo dos casos de uso de malha de dados

Crie uma malha operacional e analítica em toda a propriedade de dados
Colocar todos esses recursos de gerenciamento de dados para trabalhar em uma arquitetura unificada afetará todos os consumidores de dados. Uma malha de dados ajudará a melhorar seus sistemas globais de registro e sistemas de engajamento para operar de maneira confiável em tempo real, alinhando os dados em tempo real a gerentes de linha de negócios, cientistas de dados e seus clientes. Ele também simplifica o gerenciamento de dados para seus aplicativos de microsserviço de próxima geração. Usando métodos e ferramentas analíticos modernos, seus usuários finais, analistas e cientistas de dados serão ainda mais responsivos à demanda dos clientes e às ameaças competitivas. Para ler sobre um exemplo bem documentado, veja os objetivos e os resultados da Intuit.
beneficia -se de uma malha de dados em projetos de pontos
Ao adotar sua nova mentalidade de produto e modelo operacional, é importante desenvolver experiência em cada uma dessas tecnologias de habilitação. Em sua jornada de malha de dados, você pode obter benefícios incrementais evoluindo sua arquitetura de dados rápida para a análise de transmissão, aproveitando seus investimentos operacionais de alta disponibilidade para análises em tempo real e fornecendo análises de autoatendimento em tempo real para seus cientistas e analistas de dados em tempo real para seus cientistas e analistas de dados.
Compare e contraste
| Malha de dados | Integração App-Dev | Armazenamento de dados analíticos | |||||
|---|---|---|---|---|---|---|---|
| Malha de dados | Integração de dados | Metacatálogo | Microsserviços | Mensagens | Data lakehouse | DW Distribuído | |
| Pessoas, processo e métodos: | |||||||
| Foco em produtos de dados | disponível |
disponível |
disponível |
Oferta 1/4 |
Oferta 1/4 |
Oferta 3/4 |
Oferta 3/4 |
| Atributos da arquitetura técnica: | |||||||
| Arquitetura distribuída | disponível |
Oferta 1/4 |
Oferta 3/4 |
disponível |
disponível |
Oferta 1/4 |
Oferta 3/4 |
| Razões-gerais orientados a eventos | disponível |
não disponível |
Oferta 1/4 |
disponível |
disponível |
Oferta 1/4 |
Oferta 1/4 |
| Suporte a ACID | disponível |
disponível |
não disponível |
não disponível |
Oferta 3/4 |
Oferta 3/4 |
disponível |
| Orientado a fluxo | disponível |
Oferta 1/4 |
não disponível |
não disponível |
Oferta 1/4 |
Oferta 3/4 |
Oferta 1/4 |
| Foco em dados analíticos | disponível |
disponível |
disponível |
não disponível |
não disponível |
disponível |
disponível |
| Foco em dados operacionais | disponível |
Oferta 1/4 |
disponível |
disponível |
disponível |
não disponível |
não disponível |
| Malha física & lógica | disponível |
disponível |
não disponível |
Oferta 1/4 |
Oferta 3/4 |
Oferta 3/4 |
Oferta 1/4 |
Resultados comerciais
Benefícios gerais
mais rápido, ciclos de inovação orientados a dados
Custos reduzidos para operações de dados-críticos
Resultados operacionais
Liquidez de dados multicloud
- Desbloqueie o capital de dados para fluir livremente
Compartilhamento de dados em tempo real
- Ops-to-Ops e Ops-to-analytics
Borda, serviços de dados baseados em localização
- Correlacione eventos de dispositivo/dados na vida real
Confie MicrosServices Data Interchange
- Adjunto de eventos com dados corretos
- DataOps e IC /CD para dados
continuidade ininterrupta
- 99.999% SLAs de tempo de subida
- Migrações em nuvem
Resultados analíticos
Automatização e simplificação de produtos de dados
- Conjuntos de dados de vários modelos
Análise de dados de séries temporais
- Deltas /Alterado registros
- Fidelidade Event -By -Event
Elimine cópias completas de dados para dados operacionais
- Ledgers e pipelines baseados em log
Data lakes e warehouses distribuídos
- Híbrido/multicloud/global
- Integração de streaming/ETL
Análise preditiva
- monetização de dados, novos serviços de dados para venda
Reunindo tudo
A transformação digital é muito, muito difícil e, infelizmente, a maioria das empresas falhará nisso. Ao longo dos anos, a tecnologia, o design de software e a arquitetura de dados estão se tornando cada vez mais distribuídos, à medida que as técnicas modernas se afastam de estilos altamente centralizados e monolíticos.
A malha de dados é um novo conceito para dados-uma mudança deliberada em direção a eventos de dados altamente distribuídos e em tempo real, em oposição ao processamento de dados monolítico, centralizado e no estilo em lote. Na sua essência, a malha de dados é uma mudança de mentalidade cultural para colocar as necessidades dos consumidores de dados em primeiro lugar. É também uma mudança real de tecnologia, elevando as plataformas e serviços que capacitam uma arquitetura de dados descentralizada.
Os casos de uso para a malha de dados abrangem dados operacionais e dados analíticos, que é uma diferença essencial dos lagos/casas de dados convencionais de dados e armazéns de dados. Esse alinhamento dos domínios de dados operacionais e analíticos é um facilitador crítico para a necessidade de direcionar mais autoatendimento para o consumidor de dados. A tecnologia moderna da plataforma de dados pode ajudar a remover o intermediário na conexão de produtores de dados diretamente aos consumidores de dados.
A Oracle tem sido líder da indústria em soluções de dados críticos de missão e colocou algumas das capacidades mais modernas para capacitar uma malha de dados confiável:
- A Oracle Generation 2 Cloud Infrastructure conta com mais de 33 regiões ativas
- Banco de dados multimodelo para produtos de dados "deslocadores de formas"
- Razão-geral de eventos de dados baseado em microsserviços para todos os armazenamentos de dados
- Processamento de fluxo multicloud para dados confiáveis em tempo real
- Plataforma de API, Modern AppDev e ferramentas de autoatendimento
- Análise, visualização de dados e ciência de dados nativos em nuvem