Was ist MongoDB? Ein Expertenratgeber
Jeffrey Erickson | Senior Writer | 30. Oktober 2024

MongoDB wurde 2007 von zwei Entwicklern entwickelt, die eine Möglichkeit suchten, enorme – daher der Name – Mengen kleiner Transaktionen im Werbegeschäft zu verfolgen. Die neue Datenbank, die zunächst den Namen 10gen trug, speicherte Daten in einfachen, dokumentbasierten „Buckets“ aus JSON-ähnlichen Dateien und konnte sehr schnell skaliert werden. Ein aufwendiges Datenmodell oder präzise Transaktionssynchronisierung waren nicht erforderlich, da die Anwendung lediglich Anzeigenaufrufe zählte – das Risiko war also gering.
Dennoch bot MongoDB genau die Einfachheit, nach der viele Entwickler suchten. 2009 wurde MongoDB im Rahmen des Open-Source-Entwicklungsmodells veröffentlicht, 2018 erfolgte der Wechsel zur Server Side Public License (SSPL). Seither hat sich MongoDB zum De-facto-Standard-Datenspeicher vieler Open-Source-Entwicklungsstacks entwickelt. Zu den Kunden zählen unter anderem Expedia, Lyft, eBay und viele mehr. Werfen wir nun einen Blick darauf, was MongoDB so besonders macht.
Was ist MongoDB?
MongoDB ist eine beliebte Open-Source-Dokumentendatenbank, die häufig in modernen Web- und Mobilanwendungen eingesetzt wird. Sie wird als NoSQL-Datenbank kategorisiert, was bedeutet, dass sie einen flexiblen, dokumentenorientierten Ansatz zur Datenspeicherung verfolgt – im Gegensatz zu klassischen, tabellenbasierten relationalen Methoden. Ein wesentlicher Teil der Attraktivität von MongoDB liegt in ihrer Einfachheit und der klaren Ausrichtung auf Entwickler. MongoDB-Operationen folgen dem Akronym CRUD – Create, Read, Update, Delete (Erstellen, Lesen, Aktualisieren, Löschen).
MongoDB speichert Daten in JSON-Dokumenten, wodurch sich gespeicherte Daten – ob strukturiert, unstrukturiert oder halbstrukturiert – relativ einfach für verschiedene Arten von Anwendungen nutzen lassen. Das flexible Datenmodell von MongoDB ermöglicht es Entwicklern, unstrukturierte Daten zu speichern, während Indizierungsfunktionen für schnellen Datenzugriff sowie Replikation für Datensicherheit und Verfügbarkeit sorgen. Das bedeutet, dass Entwickler mit MongoDB anspruchsvolle und leistungsfähige Anwendungen entwerfen und realisieren können.
Während MongoDB ursprünglich entwickelt wurde, um Impressionen über Tausende von Werbeseiten hinweg zu erfassen, gewann es schon bald große Beliebtheit als flexibler Datenspeicher in der Open-Source-Webentwicklung. Seit seiner Einführung im Jahr 2007 wurde MongoDB kontinuierlich weiterentwickelt und verfügt heute über ein umfangreiches Funktionsspektrum – darunter Ad-hoc-Abfragen, Indizierung und Echtzeit-Aggregation. Ein zentraler Vorteil von MongoDB für Entwickler ist seine intuitive Handhabung und die schnelle Einsatzbereitschaft im Vergleich zu den meisten gängigen relationalen Datenbanken. Die in MongoDB gespeicherten JSON-Dokumente entsprechen Datentypen, die Entwicklern aus Programmiersprachen wie JavaScript oder Python (z. B. Dictionaries) vertraut sind. Darüber hinaus bietet MongoDB eine umfangreiche Auswahl an Client-Bibliotheken mit Treibern für zahlreiche Programmiersprachen, darunter PHP, .NET, Java, Python, Node.js und viele andere.
Wie alle Technologien hat auch MongoDB seine Stärken und Schwächen. Es wurde ursprünglich für den Bereich der Online-Werbung entwickelt, wo schnelle parallele Zugriffe erforderlich waren, jedoch keine hohe Transaktionsgenauigkeit oder tiefgehende Echtzeitanalyse. Auch heute folgt MongoDB den BASE-Prinzipien – Availability, Scalability, Eventual Consistency (Verfügbarkeit, Skalierbarkeit und letztendliche Konsistenz). Daher wird MongoDB bevorzugt in Szenarien eingesetzt, in denen hohe Verfügbarkeit und Skalierbarkeit im Vordergrund stehen. Für Anwendungen wie Finanztransaktionen oder geschäftskritische Unternehmenssysteme greifen Entwickler hingegen meist auf relationale Datenbanken zurück. Diese unterstützen ACID-Transaktionen (Atomicity, Consistency, Isolation, Durability) und gewährleisten damit die Zuverlässigkeit und Konsistenz von Datenbankoperationen. In jüngerer Zeit entstehen jedoch Technologien, die Entwicklern das Beste aus beiden Welten bieten – die Entwicklungseinfachheit von JSON kombiniert mit den Vorteilen von SQL.

Wie gelangen Daten von Anwendungen in die MongoDB-Datenbank?
- Diese sprachspezifischen Bibliotheken ermöglichen die Kommunikation zwischen der Anwendung und MongoDB.
- Der MongoDB-Datenbankserver ist der zentrale Ort, an dem die Daten gespeichert und verwaltet werden. Er kann als einzelne Instanz, als Replikat-Cluster oder als Sharding-Cluster konfiguriert sein.
- Die Datenfiles enthalten die eigentlichen Dokumente innerhalb der MongoDB-Datenbank.
- Das Chunk-Speichersystem teilt Dateien in Abschnitte fester Größe und speichert sie entsprechend.
MongoDB-Umgebungen
MongoDB ist in verschiedenen Konfigurationen und Service-Stufen verfügbar, um den Anforderungen von Entwicklern gerecht zu werden – von kleinen über mittelgroße bis hin zu großen Unternehmensprojekten.
- MongoDB Atlas ist ein Database-as-a-Service-Angebot von MongoDB, das die Bereitstellung und Verwaltung von Datenbanken über verschiedene Cloud-Anbieter hinweg ermöglicht. Atlas automatisiert viele administrative Aufgaben – darunter Skalierung und Datensicherungen.
- MongoDB Community ist eine Open-Source-Version der Datenbank, die auf kleine und mittelgroße Projekte zugeschnitten ist, die eine NoSQL-Lösung suchen. Da sie Open Source ist, eignet sie sich besonders für Anpassungen und Innovationen und bietet Entwicklern eine aktive Community zur Unterstützung. Allerdings verfügt die Community-Version weder über offiziellen Support noch über Service-Level-Agreements (SLAs), bietet weniger Sicherheitsfunktionen und nur eingeschränkte Verwaltungstools.
- MongoDB Enterprise Advanced ist die Premium- und kommerzielle Version von MongoDB Community. Sie bietet erweiterte Sicherheitsoptionen sowie eine In-Memory-Speicher-Engine, um anspruchsvolle Unternehmensanwendungen zu unterstützen.
Wichtige Erkenntnisse
- MongoDB ist eine beliebte NoSQL-Datenbank, die zum Speichern von strukturierten, halbstrukturierten und unstrukturierten Daten verwendet wird.
- Anstelle von Tabellen, wie in klassischen relationalen Datenbanken, speichert MongoDB Daten in JSON-Dokumenten, die in Collections organisiert sind.
- Da MongoDB keine starren Schemas erfordert, ermöglicht es ein flexibles Datenmodell, das sich an Änderungen in der Anwendungsfunktionalität anpassen kann.
- Ursprünglich wurde MongoDB für die schnelle Speicherung und den schnellen Abruf im Werbegeschäft entwickelt – ohne großen Fokus auf Transaktionskonsistenz oder schnelle Datenanalysen. Spätere Entwicklungen, wie etwa Sharding, erweiterten die Leistungsfähigkeit und Einsatzmöglichkeiten von MongoDB erheblich.
- Da MongoDB andere Stärken bietet als eine klassische relationale Datenbank, suchen Entwickler häufig nach Möglichkeiten, das Beste aus beiden Ansätzen zu kombinieren.
MongoDB einfach erklärt
MongoDB ist eine NoSQL-Datenbank, die ein dokumentenorientiertes Datenmodell verwendet. Dabei wird jeder Datensatz als Dokument in einer Collection gespeichert – anstelle der Zeilen und Spalten, wie sie in gängigen relationalen Datenbanken wie MySQL üblich sind.
MongoDB speichert JSON-Dokumente in einem Format namens BSON (Binary JSON). Die nicht-relationale Struktur dieser Dokumente ermöglicht es, sowohl strukturierte als auch halb- und unstrukturierte Anwendungsdaten zu speichern und zu verarbeiten. Im Gegensatz zu relationalen Datenbanken arbeitet MongoDB nicht mit starren Schemas. Stattdessen sind die Dokumente flexibel aufgebaut und können Arrays sowie verschachtelte Dokumente enthalten – ideal für die Speicherung komplexer und hierarchischer Daten.
Bei sehr großen Datenmengen skalieren dokumentenorientierte Datenbanken wie MongoDB horizontal, indem sie Daten über mehrere Knoten oder Cluster verteilen – eine Technik, die als Sharding bezeichnet wird. Dieses Modell ermöglicht eine schnelle Speicherung und einen ebenso schnellen Abruf von Daten. Diese Architektur war naheliegend, da MongoDB ursprünglich für den Einsatz im Werbegeschäft entwickelt wurde, wo Millionen von Anzeigen gleichzeitig über Tausende von Websites ausgeliefert werden können. Eine direkte Analyse zwischen einzelnen Anzeigen war dabei nicht erforderlich, was eine physische Verteilung der Daten erlaubte.
Hierarchische Dokumentendatenbanken bieten sehr schnelle Lesezugriffe, während Datenanalysen langsamer sein können, da alle verschachtelten Ebenen der Daten geprüft werden müssen. Relationale Datenbanken hingegen speichern Informationen in separaten Tabellen, wobei ein einzelnes „Objekt“ in mehreren Tabellen referenziert werden kann – was groß angelegte analytische Abfragen effizienter macht. Angesichts dieser unterschiedlichen Stärken wählen Entwicklungsteams in der Regel das Datenbanksystem, das am besten zu den aktuellen Anforderungen ihrer Anwendung passt. Alternativ kann auch eine multimodale Datenbank eingesetzt werden, die vollständigen SQL-Zugriff auf sowohl relationale als auch JSON-Dokumentdaten und viele weitere Datentypen bietet.
ACID im Vergleich zu BASE
Welche Lösung Sie wählen, hängt von den Anforderungen Ihrer Anwendung ab.
| ACID (Atomarität, Konsistenz, Isolation, Dauerhaftigkeit) | BASE (Grundsätzlich verfügbar, weicher Zustand, letztendlich konsistent) |
|---|---|
|
Atomarität: Stellt sicher, dass eine gesamte Transaktion als eine einzige Einheit behandelt wird. Entweder werden alle Änderungen erfolgreich ausgeführt – oder keine. Dadurch werden Teilaktualisierungen vermieden, die Ihre Daten in einen inkonsistenten Zustand versetzen könnten. Konsistenz: Garantiert, dass die Datenbank nach einer Transaktion von einem gültigen Zustand in einen anderen übergeht. Dadurch werden Geschäftsregeln und Datenintegrität sichergestellt. Isolation: Stellt sicher, dass gleichzeitige Transaktionen sich nicht gegenseitig beeinflussen. Jede Transaktion wird so ausgeführt, als liefe sie isoliert ab – selbst wenn mehrere Transaktionen gleichzeitig stattfinden. Dauerhaftigkeit: Sobald eine Transaktion bestätigt wurde, werden die Änderungen dauerhaft im Speicher gesichert und bleiben auch bei Systemausfällen, wie etwa Abstürzen, erhalten. |
Grundsätzlich verfügbar: Konzentriert sich auf die Maximierung der Datenverfügbarkeit. Das System bleibt auch bei teilweisen Ausfällen funktionsfähig, sodass die meisten Lese- und Schreibvorgänge fortgesetzt werden können. Weicher Zustand: Die Datenkonsistenz ist unmittelbar nach einer Schreiboperation nicht garantiert. Es kann eine kurze Verzögerung auftreten, bis Änderungen in allen Replikaten sichtbar sind, was vorübergehende Inkonsistenzen verursachen kann. Letztendlich konsistent: Im Laufe der Zeit wird die Konsistenz durch Hintergrundprozesse wiederhergestellt, die Änderungen zwischen den Replikaten abgleichen. |
|
Vorteile: Hohe Datenintegrität und starke Konsistenz machen ACID ideal für Anwendungen, bei denen Genauigkeit entscheidend ist – wie z. B. bei Finanztransaktionen. |
Vorteile: Hohe Verfügbarkeit und Skalierbarkeit machen BASE ideal für Anwendungen, die eine hohe Betriebszeit und Reaktionsfähigkeit erfordern – insbesondere in verteilten Systemen. Die weniger strengen Konsistenzanforderungen ermöglichen schnellere Schreibvorgänge und eine bessere Skalierbarkeit. |
|
Nachteile: Der Leistungsaufwand bedeutet, dass die Einhaltung der ACID-Garantien zu langsameren Schreibgeschwindigkeiten führen kann. Strenge Konsistenzanforderungen sind in hochskalierbaren Umgebungen oft schwierig umzusetzen. |
Nachteile: Vorübergehende Inkonsistenzen können während der Datensynchronisierung auftreten, was BASE weniger für Anwendungen eignet, bei denen strikte Datenintegrität und sofortige Konsistenz entscheidend sind. |
Funktionsweise von MongoDB
MongoDB speichert Daten in Collections, die den Tabellen in relationalen Datenbanken entsprechen. Jede Collection enthält mehrere Dokumente, deren Struktur variieren kann. Es ist nicht erforderlich, die Struktur der Dokumente im System vorab zu definieren, da sie selbstbeschreibend sind – jedes Dokument enthält also Metadaten, die die Felder innerhalb des Dokuments beschreiben.
Zur Leistungssteigerung unterstützt MongoDB Indizierung für beliebige Felder in einem Dokument. Indizes ermöglichen eine effiziente Ausführung von Abfragen und können Primär- und Sekundärindizes umfassen. Die Abfragesprache von MongoDB unterstützt CRUD-Operationen (Create, Read, Update, Delete) und bietet zusätzlich Möglichkeiten für komplexe Aggregationen, Textsuche und georäumliche Abfragen. Um Antwortzeiten zu verbessern, stellt MongoDB ein Aggregationsframework bereit, mit dem Entwickler komplexe Datenverarbeitungen serverseitig einrichten können. Das bedeutet, dass Analysen direkt im Cluster durchgeführt werden können, in dem sich die Daten befinden – ohne sie auf eine andere Plattform übertragen zu müssen, wie etwa bei Apache Spark oder Hadoop. Dies kann die Menge der Daten reduzieren, die zwischen Client und Server übertragen werden.
MongoDB sorgt für hohe Verfügbarkeit und bessere Leistung, indem es Replikatsätze unterstützt. Replikate können zur Lastverteilung genutzt werden, indem Lese- und Schreiboperationen auf mehrere Instanzen verteilt werden. Diese Replikatsätze bieten außerdem Redundanz und erhöhen die Datenverfügbarkeit, da mehrere Kopien der Daten auf unterschiedlichen Datenbankservern gespeichert werden. Im Falle eines Hardwareausfalls oder von Wartungsarbeiten ermöglichen Replikatsätze ein automatisches Failover sowie eine sichere Datenwiederherstellung.
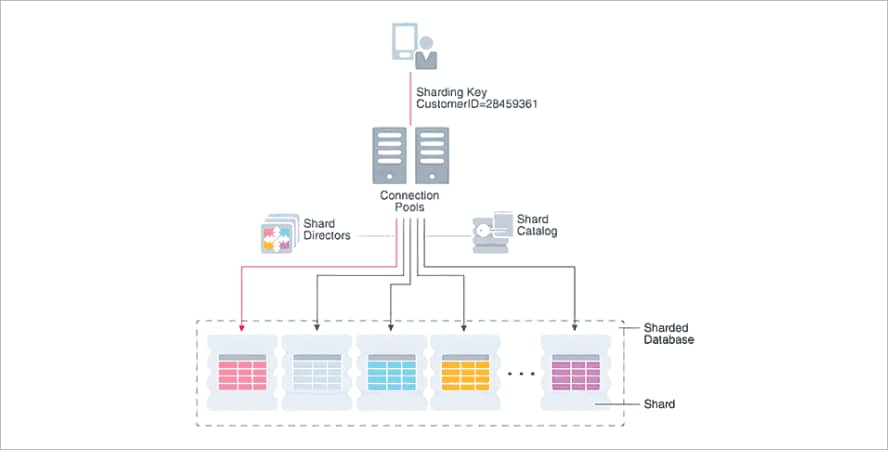
Zur Skalierung unterstützt MongoDB horizontales Skalieren über Sharding – eine Methode, bei der Daten auf mehrere Datenbanken und Maschinen verteilt werden. Ein Sharded Cluster kann aus mehreren Replikatsätzen bestehen. Das Sharding wird über einen Shard Key konfiguriert, der festlegt, wie die Daten über die einzelnen Shards verteilt werden. Diese Technik hilft, große Datenmengen und umfangreiche Transaktionen effizient zu verarbeiten, indem sie die Daten und die Last auf mehrere Server aufteilt.
Funktionsweise von Sharding
Jeder Shard ist eine eigenständige Datenbankinstanz, die Teilmengen der Daten einer geshardeten Datenbank speichert.
MongoDB im Vergleich zu RDBMS
Jede Art von Datenbank – ob relational, wie MySQL, Postgres oder Oracle Database, oder dokumentenorientiert, wie CouchDB, DynamoDB und MongoDB – hat ihre eigenen Stärken und Schwächen. Die Wahl zwischen beiden Ansätzen hängt in der Regel von den spezifischen Anforderungen und Rahmenbedingungen der jeweiligen Anwendung ab.
Ein relationales Datenbankmanagementsystem (RDBMS) verwendet SQL (Structured Query Language), während MongoDB mit einem dokumentenorientierten Format arbeitet und Document Store APIs nutzt. Dennoch verwendet die MongoDB Query Language (MQL) eine JavaScript-ähnliche Syntax mit Befehlen zum Erstellen, Lesen, Aktualisieren und Löschen von Dokumenten.
MongoDB kennt keine Tabellen oder Zeilen und arbeitet ohne feste Schemas – dadurch entfällt die Notwendigkeit, eine komplexe Struktur zu definieren, bevor die Datenbank genutzt werden kann. Allerdings bedeutet das Fehlen eines zentralen Schemas, dass jede Anwendung, die auf die Collections zugreift, die Struktur der Dokumente kennen muss. Das „Schema“ liegt somit im Anwendungscode und ist nicht in der Datenbank selbst festgelegt. Wenn eine Anwendung das Schema ändert, können dadurch andere Anwendungen beeinträchtigt werden. Im Vergleich dazu dient bei relationalen Datenbanken das Schema als Bauplan für das RDBMS: Es definiert die Organisation der Daten sowie deren Beziehungen zueinander explizit. MongoDB hingegen verfügt nicht über ein eingebautes Konzept zur Darstellung solcher Datenbeziehungen.
Die Flexibilität von Datenspeichern ist bei MongoDB besonders bemerkenswert, da verschiedene Formate wie Key-Value-Stores, Graphen und Dokumente unterstützt werden und sich Datenstrukturen im Laufe der Zeit verändern können. Dies unterscheidet sich deutlich von einem RDBMS, das mit strengen Definitionen, Hierarchien und darauf basierenden Validierungsverfahren arbeitet, um die Datenintegrität sicherzustellen.
Während die Einrichtung einer einfachen MongoDB-Instanz relativ unkompliziert ist, kann die Konfiguration und Verwaltung eines groß angelegten, verteilten MongoDB-Clusters mit Sharding und Replikaten komplex sein. Sie erfordert ein fundiertes Verständnis der Architektur und der verfügbaren Konfigurationsoptionen.
Wichtige Unterschiede
| Relationales | MongoDB | |
|---|---|---|
| Datenmodell | Verwendet Tabellen mit festen Zeilen und Spalten, und die Daten sind in einem vordefinierten Schema strukturiert. | Verwendet Collections aus Dokumenten – JSON-ähnliche Strukturen mit dynamischen Schemas. |
| Schemaflexibilität | Erfordert ein vordefiniertes Schema, das eingerichtet werden muss, bevor Daten hinzugefügt werden können. | Verfügt über ein dynamisches Schema. Neue Felder können zu einem Dokument hinzugefügt werden, ohne dass andere Dokumente in der Collection betroffen sind. |
| Abfragesprache | Verwendet SQL, das sich besonders für komplexe Abfragen sowie zur Definition und Manipulation von Daten eignet. | Verwendet eine dokumentenbasierte Abfragesprache, die als intuitiver gilt, jedoch weniger umfassend und vielseitig ist als SQL. |
| Skalierung | Wird traditionell vertikal skaliert, indem die Leistung der bestehenden Maschine erhöht wird. Fortgeschrittene Funktionen wie Sharding und Oracle Real Application Clusters ermöglichen jedoch auch horizontale Skalierung. | Entwickelt für horizontale Skalierung über mehrere Maschinen hinweg mithilfe von Sharding, das die Daten auf einen Cluster von Servern verteilt. |
| Transaktionen | Unterstützt Mehrzeilen-Transaktionen und ist ACID-konform, wodurch es sich für Anwendungen eignet, bei denen keine Daten verloren gehen oder beschädigt werden dürfen. | Unterstützt Multidokument-Transaktionen, gilt jedoch als weniger robust als die meisten traditionellen relationalen Datenbanken – insbesondere bei verteilten Daten. |
| Performance | Entwickelt, um präzise Transaktionen sicherzustellen, kann jedoch bei großen Datenmengen eine geringere Leistung aufweisen. Die Analyseleistung ist dagegen in der Regel besser. | Ausgelegt auf hohe Leseleistung bei großen Datenvolumen. |
Warum MongoDB verwenden?
MongoDB eignet sich für ein breites Spektrum an Anwendungen – von einfachen CRUD-Anwendungen wie Blog- oder Notiz-Apps bis hin zu komplexen Plattformen wie Amazon Prime. Häufig wird MongoDB in Content-Management-Systemen (CMS), Gaming-Apps mit schnellen Datensynchronisationsanforderungen oder für biometrische Gesundheitsdaten eingesetzt – um nur einige Beispiele zu nennen. Seine Vielseitigkeit hat MongoDB zu einem zentralen Bestandteil populärer Open-Source-Entwicklungsstacks wie MEAN und MERN gemacht.
Wählen Sie MongoDB, wenn Sie Folgendes benötigen:
- Flexibilität. Das JSON-Dokumentformat von MongoDB bietet eine einfache und intuitive Möglichkeit, hierarchische Datenstrukturen darzustellen, die in SQL-Datenbanken nur über komplexe Joins abgebildet werden könnten.
- Verfügbarkeit. Die verteilte Datenbankarchitektur von MongoDB bietet hohe Verfügbarkeit – selbst bei großen und sich häufig ändernden Datensätzen.
- Skalierbar. MongoDB wurde entwickelt, um große, sich schnell ändernde und vielfältige Datensätze zu erfassen, zu verarbeiten und zu analysieren.
- Leistung. Leistungsoptimierungen durch Methoden wie Replikation, Sharding und andere machen MongoDB zu einer leistungsfähigen Lösung für umfangreiche Anwendungen, wie z. B. in den Bereichen Medien und Unterhaltung.
- Kompatibilität. Die JSON-basierten Dokumente von MongoDB bieten eine einfache Kompatibilität mit gängigen Datentypen vieler Programmiersprachen. Darüber hinaus stellen die MongoDB-Clientbibliotheken Treiber für die meisten Programmiersprachen bereit, darunter PHP, .NET, JavaScript und viele mehr.
- Community-Unterstützung. MongoDB ist in vielen Open-Source-Entwicklungsumgebungen der Standard-Datenspeicher, der von einer aktiven Community unterstützt wird.
Features von MongoDB
MongoDB erfreut sich bei Entwicklern großer Beliebtheit – unter anderem dank seiner intuitiven API, des flexiblen Datenmodells und zahlreicher Features, darunter:
- Ad-hoc-Abfragen MongoDB unterstützt Feld-, Bereichs- und reguläre Ausdrucksabfragen, die ganze Dokumente, bestimmte Felder von Dokumenten oder zufällige Stichproben von Ergebnissen zurückgeben können.
- Indizierung. MongoDB unterstützt verschiedene Indextypen, darunter Einzelfeld-, zusammengesetzte (mehrere Felder), Multikey- (Array-), Geodaten-, Text- und Hash-Indizes.
- Replikation. MongoDB bietet hohe Verfügbarkeit durch Replikatsätze mit zwei oder mehr Datenkopien. Schreibvorgänge werden vom primären Replikat ausgeführt, während Leseanforderungen von jedem Replikat bedient werden können. Wenn das primäre Replikat ausfällt, wird ein sekundäres Replikat automatisch zum neuen primären Replikat hochgestuft.
- Skalierbar. Das Skalieren von MongoDB-Datenbanken wird durch Sharding verbessert, da Cluster jeweils nur einen Teil der Daten einer Sammlung speichern. Sharding-Schlüssel bestimmen dabei, wie die Daten verteilt werden.
- Load Balancing. MongoDB kann sowohl vertikal als auch horizontal skaliert werden. Durch Sharding-Cluster wird die Lastverteilung bereits in der grundlegenden Datenbankstruktur ermöglicht. Replikation kann zudem genutzt werden, um die Belastung der primären Server zu verringern.
- Dateispeicherung. Daten werden in Dokumenten gespeichert, die sich direkt auf Objekte in den meisten Programmiersprachen abbilden lassen und so einen einfachen Zugriff innerhalb von Anwendungen ermöglichen.
- Batch-Verarbeitung. Die Datenverarbeitung kann auf verschiedene Weise erfolgen. Manchmal geschieht sie direkt in den Dokumenten, in anderen Fällen über eine Sammelschreibmethode, die die Anzahl der Netzwerkoperationen reduziert.
Vorteile von MongoDB
Die Beliebtheit von MongoDB in der Open-Source-Community beruht auf den zahlreichen Möglichkeiten, die Entwicklung und Wartung von Anwendungen intuitiver und skalierbarer zu gestalten. Zu diesen Vorteilen gehören:
- Benutzerfreundlichkeit für Entwickler. Entwickler entscheiden sich häufig für MongoDB, da es sich leicht herunterladen oder in der Cloud nutzen lässt. Dadurch können sie schnell starten – unter anderem, weil das Arbeiten mit Dokumenten einfacher ist als das Erstellen eines Datenmodells und das Arbeiten mit Tabellen.
- Effizienz. JSON bietet zahlreiche Vorteile durch kompakte Dokumentdateien und menschenlesbaren Inhalt. MongoDB codiert Dokumente im Binärformat (BSON), das kompakter ist und sich schneller verarbeiten lässt als reiner Text.
- Flexible Schemas. Das dokumentenbasierte Datenmodell von MongoDB ermöglicht flexible und selbsterklärende Schemas, bei denen sich Felder von Dokument zu Dokument unterscheiden können.
- Einfache Abfragesprache. Die MongoDB Query Language (MQL) wurde entwickelt, um Entwicklern eine einfache Nutzung zu ermöglichen. Sie unterstützt komplexe Abfragen und Indizes, um häufig verwendete Abfragen zu beschleunigen.
- Native Cloud-Services. MongoDB Atlas ist eine cloudnative Datenbank, die regelmäßig aktualisiert wird und sich schnell an neue Technologien anpasst. Ihre Nutzung erleichtert zudem die Migration von Anwendungen in die Cloud.
Nachteile von MongoDB
Obwohl MongoDB viele Vorteile bietet – insbesondere für Anwendungen, die Flexibilität und hohe Leistung bei großen Datenmengen erfordern – bringt es auch einige potenzielle Nachteile mit sich.
- Transaktionsunterstützung. Die Transaktionsunterstützung von MongoDB ist nicht so ausgereift oder robust wie bei traditionellen relationalen Datenbanken. Komplexe Transaktionen, insbesondere solche über mehrere Operationen hinweg, können weniger effizient sein und sich schwieriger umsetzen lassen.
- Datenkonsistenz. Da MongoDB bei Replikatsätzen auf „eventual consistency“ setzt, kann es vorkommen, dass nicht alle Benutzer gleichzeitig dieselben Daten sehen. Für Anwendungen, die eine starke Konsistenz erfordern, kann dies ein erheblicher Nachteil sein.
- Join-Operationen. MongoDB unterstützt Joins nicht in der gleichen Weise wie SQL-Datenbanken. Zwar gibt es Funktionen mit ähnlicher Wirkung, diese sind jedoch meist weniger effizient und können zu komplexeren Abfragen sowie einer geringeren Leistung führen – insbesondere bei komplexen Beziehungen zwischen Dokumenten.
- Speichernutzung. MongoDB hält die am häufigsten verwendeten Daten und Indizes im Arbeitsspeicher (RAM). Daher hängt die Leistung stark von der verfügbaren RAM-Menge ab. Infolgedessen kann eine MongoDB-Datenbank mehr Speicherressourcen und potenziell auch leistungsfähigere Hardware benötigen als andere Datenbanken.
- Speicheraufwand. Das von MongoDB verwendete selbstständige Dokumentenmodell kann zu einem höheren Speicherbedarf führen als die stark normalisierten Tabellen relationaler Datenbanken. Darüber hinaus kann das dynamische Schema von MongoDB zu Datenredundanz und Fragmentierung führen, was den Speicherverbrauch – und damit auch die Kosten – erhöht.
- Indexierungsbeschränkungen. MongoDB bietet zwar zahlreiche Indexierungsoptionen, doch das Verwalten vieler Indizes kann die Schreibgeschwindigkeit beeinträchtigen. Da bei jeder Schreiboperation möglicherweise mehrere Indizes aktualisiert werden müssen, steht die Abfrageleistung häufig in Konkurrenz zur Schreibperformance.
- Kosten. In Szenarien, die High Availability und horizontale Skalierbarkeit erfordern, können die Kosten für den Betrieb und die Wartung eines MongoDB-Clusters – insbesondere in Cloud-Umgebungen – erheblich sein. Der hohe Bedarf an RAM und Speicher kann die Kosten zusätzlich in die Höhe treiben. Dies gilt insbesondere in Situationen mit hoher Verfügbarkeit, in denen Replikatdatenbanken eine gleiche Anzahl von Ressourcen benötigen.
MongoDB-Kompatibilität
MongoDB ist eine NoSQL-Datenbank, die sich gut in dieses Ökosystem einfügt, aber auch für die Zusammenarbeit mit anderen Datenbankverwaltungssystemen entwickelt wurde – mithilfe verschiedener Datenintegrationstools und Connectors. Dieses Toolset umfasst eine ETL-Infrastruktur (Extract, Transform, Load), mit der Daten aus MongoDB extrahiert und migriert oder umgekehrt importiert werden können. Dies ist besonders nützlich, um Daten an relationale Datenbanken für Reporting- oder komplexe Analysezwecke zu übertragen. MongoDB-Anwendungen können zudem über verschiedene Datenbankplattformen hinweg mithilfe von REST-APIs kommunizieren.
Ausführen von MongoDB-Workloads in Oracle Autonomous Database
Ein gutes Beispiel für die Kompatibilität mit MongoDB ist die Oracle Database API for MongoDB. Sie ermöglicht es Entwicklern, die Open-Source-Tools und Treiber von MongoDB in Verbindung mit einer Oracle Autonomous JSON Database zu verwenden. Dadurch erhalten sie Zugriff auf die multimodalen Funktionen von Oracle und müssen Daten nicht in eine separate Datenbank für Analysen, Machine Learning (ML) oder räumliche Analysen verschieben. Die Autonomous JSON Database kann als multimodale Alternative zu MongoDB Atlas betrachtet werden. Bestehende Anwendungen erfordern dabei oft nur wenige oder gar keine Anpassungen.
Migration von MongoDB-Workloads zur Oracle Autonomous JSON Database
Anstatt auf MongoDB-Funktionen über APIs zuzugreifen, können Entwickler ihre JSON-zentrierten Workloads einfach in eine Oracle Autonomous JSON Database auf Oracle Cloud Infrastructure (OCI) migrieren. Diese bietet einen Cloud-Dokumentdatenbankservice für JSON-basierte Anwendungen mit NoSQL-ähnlichen Dokument-APIs (Simple Oracle Document Access – SODA – und Oracle Database API for MongoDB), serverlosem Skalieren, leistungsstarken ACID-Transaktionen, umfassender Sicherheit und einem günstigen nutzungsabhängigen Preismodell. Während der Migration von MongoDB zur Oracle Autonomous JSON Database kommt es zu keiner Ausfallzeit, da der Prozess mithilfe von Oracle Cloud Infrastructure (OCI) GoldenGate durchgeführt wird.
Erste Schritte mit Autonomous Database
MongoDB-Nutzer verfügen nun über eine noch vielseitigere Möglichkeit, JSON-zentrierte Anwendungen zu entwickeln. Oracle Autonomous Database bietet Entwicklern die Flexibilität, auf geschäftliche Anforderungen zu reagieren – mit einer einzigen Datenplattform, die alle Bedürfnisse abdeckt. So können Entwickler SQL, JSON-Dokumente, Graphen, Geodaten, Text und Vektoren in einer einzigen Datenbank nutzen, um schnell neue Features zu erstellen.
Ein bahnbrechendes neues Feature der Oracle Database, JSON Relational Duality, vereint die Vorteile relationaler Tabellen und JSON-Dokumente – ohne die Kompromisse beider Modelle.
Darüber hinaus bietet die Autonomous Database integrierte KI-Services und In-Database-Machine-Learning (ML), um Anwendungen mit Text- und Bildanalyse, Spracherkennung oder personalisierten Empfehlungen zu erweitern. Mit Autonomous Database Select AI wird natürliche Sprache automatisch in Datenbankabfragen übersetzt, sodass sich kontextbezogene Gespräche mit der Datenbank führen lassen – ganz ohne manuelles Codieren oder komplexe Benutzeroberflächen. Da die Datenbank vollständig autonom arbeitet, können Entwicklungsteams sich ganz auf die Anwendungsentwicklung konzentrieren, während die Datenbank Verfügbarkeit sicherstellt und Daten durch automatisierte Sicherheitsmaßnahmen und kontinuierliche Überwachung schützt.
Sie können noch heute kostenlos starten und in einem Workshop lernen, wie Sie SQL, JSON und Oracle Graph in derselben Anwendung verwenden.
Mit Anwendungsbereichen wie E-Commerce-Plattformen, IoT-Anwendungen und vielem mehr hat MongoDB seine Vielseitigkeit in verschiedensten Branchen unter Beweis gestellt. Seine Fähigkeit, unterschiedliche Datentypen zu verarbeiten und komplexe Abfragen zu unterstützen, macht MongoDB zu einem leistungsstarken Bestandteil moderner Technologiestacks. Da Unternehmen bestrebt sind, den maximalen Nutzen aus ihren Daten zu ziehen, wird MongoDB eine entscheidende Rolle für ihren Erfolg spielen.

Sowohl Entwickler als auch ihre Geschäftspartner profitieren von cloudnativen Anwendungen, die gezielt darauf ausgelegt sind, Agilität, Skalierbarkeit und Effizienz zu maximieren. Erfahren Sie mehr und entdecken Sie 10 weitere Möglichkeiten, wie sich die Cloud verbessert.
Häufig gestellte Fragen zu MongoDB
Was ist der Unterschied zwischen SQL und MongoDB?
MongoDB speichert unstrukturierte Daten, die sich nicht für eine Structured Query Language (SQL) eignen.
Ist MongoDB eine Backend-Sprache?
Nein, aber es kann als Teil einer Backend-Webanwendung verwendet werden.
Ist MongoDB eine Sprache oder ein Framework?
MongoDB ist ein Datenbank-Verwaltungssystem, das unstrukturierte Daten in Dokumenten statt in Tabellen speichert.