Fraud prevention and anti–money laundering

Minimize risk while delivering seamless customer service
Financial fraud poses a major challenge for the financial services industry. Not only does it come in many different forms, but it’s often difficult to detect due to the complexity of the relationships between entities and hidden patterns. And, once detected, financial institutions must notify customers of fraudulent activity in real time and take immediate action to stop it—for example, by blocking the customer’s credit card.
The financial services industry is also regulated and must report anti–money laundering (AML) activities and complete due diligence on their customers using Know Your Customer (or KYC) processes. This often requires analyzing data across products, markets, and geographies to identify relationships and patterns for AML.
Conceptually, money laundering is simple: Dirty money is passed around, blended with legitimate funds, and then turned into hard assets. In reality, it’s far more complicated, relying on a long, complex series of valid transfers between accounts created using synthetic (often stolen) identities and often using similar information, such as email and street addresses. In short, it involves a vast amount of data, which is why a unified data platform that supports advanced analytic techniques, such as graph analysis, is essential for AML programs.
Protect both customers and institutions with machine learning
The financial services industry continues to be highly monitored and regulated, and few areas have seen a greater increase in regulatory focus than anti–money laundering and counter-terrorist financing activities. Driven by vast criminal networks, financial fraud is a sophisticated and growing challenge requiring anti–money laundering solutions that provide insight across the enterprise and the entire globe.
The following architecture demonstrates how Oracle components and capabilities, including advanced analytics and machine learning, can be combined to create a data platform that covers the entire data analytics lifecycle and delivers the insights AML teams need to identify the anomalous patterns in behavior that can be indicative of fraudulent activity.
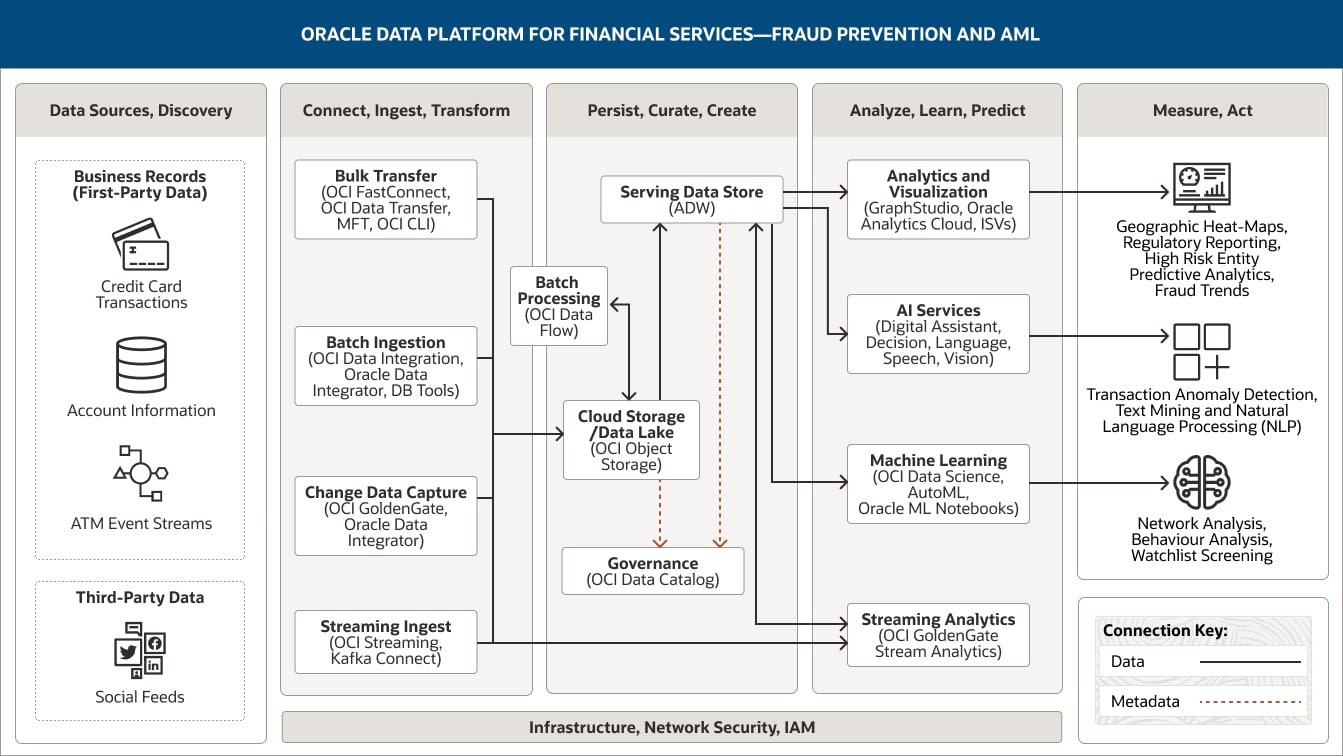
This image shows how Oracle Data Platform for financial services can be used to support fraud prevention and AML activities. The platform includes the following five pillars:
- Data Sources, Discovery
- Connect, Ingest, Transform
- Persist, Curate, Create
- Analyze, Learn, Predict
- Measure. Act
The Data Sources, Discovery pillar includes two categories of data.
Business record (first-party) data comprises credit card transactions, account information, and ATM event streams.
Third-party data includes social feeds.
The Connect, Ingest, Transform pillar comprises four capabilities.
Bulk transfer uses OCI FastConnect, OCI Data Transfer, MFT, and OCI CLI.
Batch ingestion uses OCI Data Integration, Oracle Data Integrator, and DB tools.
Change data capture uses OCI GoldenGate and Oracle Data Integrator.
Streaming ingest uses OCI Streaming and Kafka Connect.
All four capabilities connect unidirectionally into the cloud storage/data lake capability within the Persist, Curate, Create pillar.
Additionally, streaming ingest is connected to stream processing within the Analyze, Learn, Predict pillar.
The Persist, Curate, Create pillar comprises four capabilities.
The serving data store uses Autonomous Data Warehouse and Exadata Cloud Service.
Cloud storage/data lake uses OCI Object Storage.
Batch processing uses OCI Data Flow.
Governance uses OCI Data Catalog.
These capabilities are connected within the pillar. Cloud storage/data lake is unidirectionally connected to the serving data store; it is also bidirectionally connected to batch processing.
One capability connects into the Analyze, Learn, Predict pillar: The serving data store connects unidirectionally to the analytics and visualization, AI services, and machine learning capabilities and bidirectionally to the streaming analytics capability.
The Analyze, Learn, Predict pillar comprises four capabilities.
Analytics and visualization uses Oracle Analytics Cloud, GraphStudio, and ISVs.
AI services uses OCI Anomaly Detection, OCI Forecasting, OCI Language
Machine learning uses OCI Data Science and Oracle Machine Learning Notebooks.
Streaming analytics uses OCI GoldenGate Stream Analytics.
The Measure, Act pillar comprises three consumers: dashboards and reports, applications, and machine learning models.
People and partners comprise Geographic Heat-Maps, Regulatory Reporting, High Risk Entity Predictive Analytics, Fraud Trends.
Applications comprises Transaction Anomaly Detection, Text Mining and Natural Language Processing (NLP).
Machine learning models comprises Network Analysis, Behavior Analysis, Watchlist Screening.
The three central pillars—Ingest, Transform; Persist, Curate, Create; and Analyze, Learn, Predict—are supported by infrastructure, network, security, and IAM.
There are three main ways to inject data into an architecture to enable financial services organizations to identify potentially fraudulent activity.
- To start, we need data from transactional systems and core banking applications. This data can be enriched with customer data from third-party sources, which could include unstructured data from social media, for example. Frequent real-time or near real-time extracts requiring change data capture are common, and data is regularly ingested from transactional, risk, and customer management systems using Oracle Cloud Infrastructure (OCI) GoldenGate. OCI GoldenGate is also a critical component of evolving data mesh architectures where “data products” are managed via enterprise data ledgers and polyglot data streams that perform continuous transform and load processes (rather than the batch ingest and extract, transform, and load processes used in monolithic architectures).
- We can now use streaming ingest to ingest data from IoT sensors, web pipelines, log files, point-of-sale devices, ATMs, social media, and other data sources in real time via OCI Streaming/Kafka. This streamed data (events) is ingested and some basic transformations/aggregations are performed before the data is stored in cloud storage. In parallel with ingestion, we can filter, aggregate, correlate, and analyze high volumes of data from multiple sources in real time using streaming analytics. This not only helps financial institutions detect business threats and risks—for example, suspicious transactions from an ATM, such as multiple repeat transactions— but it also provides insights into their overall fraud prevention efficiency. Correlating events and identified patterns can be fed back (manually) for a data science examination of the raw data. Additionally, events can be generated to trigger actions, such as notifying customers about potential fraud via email or SMS or blocking compromised debit cards. Oracle GoldenGate Stream Analytics is an in-memory technology that performs real-time analytical computations on streaming data.
- While real-time needs are evolving, the most common extract from core banking, customer, and financial systems is a batch ingestion using an extract, transform, and load process. Batch ingestion is used to import data from systems that can’t support streaming ingestion (for example, older mainframe systems). For anti–money laundering and Know Your Customer processes, data is sourced from different operational systems, such as current and credit account transaction processing systems, and third-party data feeds providing customer intelligence. The data is sourced across products and geographies. Batch ingestions can be frequent, as often as every 10 or 15 minutes, but they are still bulk in nature as groups of transactions are extracted and processed rather than individual transactions. OCI offers different services to handle batch ingestion, such as the native OCI Data Integration service or Oracle Data Integrator running on an OCI Compute instance. Depending on the volumes and data types, data can be loaded into object storage or loaded directly into a structured relational database for persistent storage.
Data persistence and processing is built on three (optionally four) components.
- Ingested raw data is stored in cloud storage for algorithmic purposes; we use OCI Object Storage as the primary data persistence tier. Spark in OCI Data Flow is the primary batch processing engine for data such as transactional, location, application, and geo-mapping data. Batch processing involves several activities, including basic noise treatment, missing data management, and filtering based on defined outbound datasets. Results are written back to various layers of object storage or to a persistent relational repository based on the processing needed and the data types used.
- These processed datasets are returned to cloud storage for onward persistence, curation, and analysis and ultimately for loading in optimized form to the serving data store, provided here by Oracle Autonomous Database. Data is now persisted in optimized relational form for curation and query performance. Alternatively, depending on architectural preference, this can be accomplished with Oracle Big Data Service as a managed Hadoop cluster. In this use case, all the data needed to train the machine learning models is accessed in raw form from object storage. To train the models, historical patterns are combined with transaction-level records to identify and label potential risks. Combining these datasets with others, such as device data and geospatial data, lets us apply data science techniques to refine existing models and develop new ones to better predict potential frauds. This type of persistence can also be used to store data for schemas that are part of the data stores accessed via external tables and hybrid partitions.
The ability to analyze, predict, and act is built on three technology approaches.
- Analytics and visualization services, such as Oracle Analytics Cloud, deliver analytics based on the curated data from the serving data store. This includes descriptive analytics (describes current fraud identification trends and flagged activity with histograms and charts), predictive analytics, such as time series analysis (predicts future patterns, identifies trends, and determines the probability of uncertain outcomes), and prescriptive analytics (proposes suitable actions leading to optimal decision-making). These analytics can be used to answer questions such as: How does actual flagged fraud this period compare to previous periods?
- Alongside advanced analytics, machine learning models are developed, trained, and deployed. These trained models can be run on both current and historical transactional data to detect money laundering by matching patterns of transactions and behaviors, and the results can be persisted back to the serving layer and reported using analytics tools such as Oracle Analytics Cloud. To optimize model training, the model and data can also be fed into machine learning systems, such as OCI Data Science, to further train the models for more effective anti–money laundering pattern detection before promoting them. These models can be accessed via APIs, deployed within the serving data store, or embedded as part of the OCI GoldenGate streaming analytics pipeline.
- Additionally, we can use the advanced capabilities of cloud native artificial intelligence services.
- OCI Anomaly Detection is an artificial intelligence service that makes it easy to build business-specific anomaly detection models that flag critical incidents, speeding up detection and resolution. In this use case, we would deploy these models to detect fraud during the lifecycle of a transaction; during audits; in specific contexts, for example, based on the vendor, merchant, or type of transaction; and in many other scenarios. OCI Anomaly Detection can identify all these types of fraud by using historical data and building an appropriate anomaly detection model. For example, if the dataset includes the type of transaction with the amount, location (latitude and longitude), vendor name, and other details, OCI Anomaly Detection can identify if the fraud is related to the transaction amount, the transaction account, the location where the transaction occurred, or the vendor who filed the transaction.
- OCI Forecasting can be used to forecast transaction metrics, such as the number of transactions, transaction amounts, and so on, for the next day, week, or months as a function of current metrics and influencing market conditions. These forecasts can be used for planning and to set a baseline expectation to use in safeguarding against money laundering and other fraud.
- OCI Language and OCI Vision can ingest documents and text that can help enrich the data for fraud detection and AML activities.
- Data governance is another critical component. This is delivered by OCI Data Catalog, a free service providing data governance and metadata management (for both technical and business metadata) for all the data sources in the data lakehouse ecosystem. OCI Data Catalog is also a critical component for queries from Oracle Autonomous Data Warehouse to OCI Object Storage as it provides a way to quickly locate data regardless of its storage method. This allows end users, developers, and data scientists to use a common access language (SQL) across all the persisted data stores in the architecture.
- Finally, our now curated, tested, high-quality, and governed data and models can be exposed as a data product (API) within a data mesh architecture for distribution across the financial services organization.
Improve fraud prevention and AML activities with the right data platform
Oracle Data Platform can help your organization detect money laundering more effectively, boost the accuracy and efficiency of financial crime investigations, and streamline reporting processes to keep compliance costs down.
Related resources
-
Use case
Fraud prevention and anti–money laundering
Learn how Oracle Data Platform for financial services can help you reduce risk and improve fraud detection and compliance in this use case.
-
Use case
Risk calculations and regulatory reporting
Learn how Oracle Data Platform for financial services can help you reduce risk and improve regulatory compliance in this use case.
-
Use case
Improve financial services operations and performance
Learn how to manage financial services operations more efficiently using a data platform that helps improve performance with machine learning.
Get started
Try 20+ Always Free cloud services, with a 30-day trial for even more
Oracle offers a Free Tier with no time limits on more than 20 services such as Autonomous AI Database, Arm Compute, and Storage, as well as US$300 in free credits to try additional cloud services. Get the details and sign up for your free account today.
-
What’s included with Oracle Cloud Free Tier?
- Two Autonomous AI Database instances, 20 GB each
- AMD and Arm Compute VMs
- 200 GB total block storage
- 10 GB object storage
- 10 TB outbound data transfer per month
- 10+ more Always Free services
- US$300 in free credits for 30 days for even more
Learn with step-by-step guidance
Experience a wide range of OCI services through tutorials and hands-on labs. Whether you're a developer, admin, or analyst, we can help you see how OCI works. Many labs run on the Oracle Cloud Free Tier or an Oracle-provided free lab environment.
-
Get started with OCI core services
The labs in this workshop cover an introduction to Oracle Cloud Infrastructure (OCI) core services including virtual cloud networks (VCN) and compute and storage services.
Start OCI core services lab now -
Autonomous AI Database quick start
In this workshop, you’ll go through the steps to get started using Oracle Autonomous AI Database.
Start Autonomous AI Database quick start lab now -
Build an app from a spreadsheet
This lab walks you through uploading a spreadsheet into an Oracle Database table, and then creating an application based on this new table.
Start this lab now
Explore over 150 best practice designs
See how our architects and other customers deploy a wide range of workloads, from enterprise apps to HPC, from microservices to data lakes. Understand the best practices, hear from other customer architects in our Built & Deployed series, and even deploy many workloads with our "click to deploy" capability or do it yourself from our GitHub repo.
Popular architectures
- Apache Tomcat with MySQL Database Service
- Oracle Weblogic on Kubernetes with Jenkins
- Machine-learning (ML) and AI environments
- Tomcat on Arm with Oracle Autonomous AI Database
- Log analysis with ELK Stack
- HPC with OpenFOAM
See how much you can save on OCI
Oracle Cloud pricing is simple, with consistent low pricing worldwide, supporting a wide range of use cases. To estimate your low rate, check out the cost estimator and configure the services to suit your needs.
Experience the difference:
- 1/4 the outbound bandwidth costs
- 3X the compute price-performance
- Same low price in every region
- Low pricing without long-term commitments
Contact sales
Interested in learning more about Oracle Cloud Infrastructure? Let one of our experts help.
-
They can answer questions like:
- What workloads run best on OCI?
- How do I get the most out of my overall Oracle investments?
- How does OCI compare to other cloud computing providers?
- How can OCI support your IaaS and PaaS goals?