
AI Data Platform
Oracle AI Data Platform unifies your enterprise data, applies the business context AI needs to act accurately, and deploys agents that automate workflows, decisions, and processes—across every function, at enterprise scale. It’s one platform, end to end, with a governed data foundation and embedded intelligence.
See AI deliver business outcomes
Join us at Oracle AI World in Las Vegas from October 25 to 28 to see how Oracle’s AI and other technology innovations are helping organizations solve challenges across industries. Hear from Oracle leaders, explore demos and case studies, and connect with experts and peers.
What's new in Oracle AI Data Platform?
-
ISG Buyers Guide™ for AI and Data Platforms 2026
The Buyers Guide highlights leading providers in AI, data management, deployment capabilities, and more. Read it now to see why Oracle was named an Overall Leader.
-
Build AI That Works for Business
AI is only as good as its foundation. Discover how Oracle AI Data Platform provides a trusted, governed environment to help build accurate AI at scale.
-
3 Ways Enterprise AI Helps Pay Off for Financial Services Firms
Discover how Oracle AI Data Platform helps financial services firms unify trusted data, apply industry models, and embed AI into core workflows so teams can act on insights faster.
-
5 Ways Oracle AI Data Platform Can Benefit Your Business
Discover five key ways Oracle AI Data Platform can transform your enterprise data and AI initiatives.
Why Oracle AI Data Platform?
Enterprise AI succeeds when three things come together: data your organization trusts, context that reflects how your business actually operates, and intelligence embedded where decisions happen.
-
Trusted enterprise data
Enterprise AI is only as reliable as the data behind it. Oracle AI Data Platform unifies structured and unstructured data across your business systems, including Oracle Fusion Cloud ERP, SCM, HCM, customer experience (CX), and non-Oracle sources, into a single foundation. Data can stay secure and support your compliance requirements, accessed in place or moved through trusted, lineage-tracked pipelines, so AI operates on complete, accurate information rather than fragmented copies.
-
Deep business semantics
AI models understand language. They don't inherently understand your business. Oracle AI Data Platform encodes the metrics, relationships, domain logic, and process context that define how your organization operates across finance, supply chain, HR, and customer operations. Agents and analytics built on this semantic layer can reason in your business language and can produce outputs that are consistent, explainable, and trusted by the people making decisions.
-
AI in the flow of work
AI creates value only when it acts. Oracle AI Data Platform embeds agents and intelligence directly into business workflows where decisions are made—inside Oracle Applications and across third-party operational systems. Embedded AI surfaces recommendations, optimizes approvals, and drives action at the point where it changes outcomes.
AI Data Platform customer success stories
-
University College Dublin aims to improve chronic care with Oracle AI Data Platform
Using Oracle AI Data Platform, the UCD Clinical Research Centre is transforming respiratory care, turning unstructured clinical data into actionable insights. By combining synthetic and open data sets, they built a research analytics tool to support chronic disease research and data analysis.
-
Clopay drives manufacturing success with Oracle AI Data Platform
Clopay® Garage Doors is using Oracle AI Data Platform to transform how it understands and serves its customers. With millions of unique SKUs across its product line, Clopay replaced manual spreadsheet analysis with AI-powered insights that accurately predict dealer churn and reveal trends before they happen—driving stronger business performance, better decisions, and improved profitability.
Explore Oracle AI Data Platform features and capabilities
Build a complete data lakehouse across structured, semi-structured, and unstructured data. Raw data lands in object storage as the bronze layer, ingested where it lives or landed directly without unnecessary duplication. Autoscaling compute with managed Apache Spark refines it into clean, access-controlled data sets in the silver layer. Oracle Autonomous AI Database delivers the curated, AI-ready gold layer that is optimized for analytics, machine learning, and AI agents. One lakehouse. One environment. This means that every user—from data engineer to business user—works with the same trusted data.
- Any sources, any sinks, any language, anywhere
Catalog and connect to more than 100 sources and sinks, including relational databases, SaaS applications, streaming feeds, and third-party data providers. For example, a data engineer can combine ERP records, customer events, and clickstream data into Apache Spark transformations, land trusted gold tab - Visual data pipeline creation
Design no-code and pro-code ETL and ELT pipelines that orchestrate ingestion, transformation, and enrichment from bronze to gold in a single workflow. - Interoperability with open file formats
Store and query data in open formats, including Apache Iceberg and Delta Lake directly on Oracle Cloud Infrastructure (OCI) Object Storage, with transactional consistency, time-travel queries, and schema evolution. Interoperate with Apache Spark, Apache Flink, and any engine compatible with Iceberg or Delta Lake. No proprietary lock-in, no rewrites when tools change. - Best-in-class engines for data preparation and queries
Data engineers can run large-scale data transformations in Apache Spark. Data scientists can build ML models. Business users can perform ad-hoc exploration using SQL and Oracle AI Database against the same data. Each user can pick the right engine for their workload without copying or remodeling data. - Converged analytics across data and databases
Query structured tables, semi-structured JSON, geospatial data, and AI vector embeddings across object storage and connected databases under one, role-based access control model. For example, a business user can validate a new revenue projection by joining the lakehouse activity streams with the authoritative customer records in Oracle AI Database in a single SQL query. - AI-ready gold layer
Machine learning pipelines, retrieval-augmented generation (RAG) knowledge bases, and AI agents consume curated, business-validated data. AI engineers ground models on the same authoritative facts that drive operational reporting, not raw or intermediate copies. - Autonomous gold layer operations
Gain the benefits of a self-tuning, self-scaling, and self-repairing warehouse with automatic indexing, query optimization, and workload management. Deliver consistent, subsecond performance across billions of rows during peak hours without manual tuning. Scale compute independently from storage to serve hundreds of concurrent users. - First-class, first-party integration
Bring Oracle Fusion Applications data, including ERP, HCM, supply chain, and CX, directly into the lakehouse. Prepare Fusion data in Apache Spark–powered notebooks for AI agent grounding, historical reporting, and predictive analytics on the operational system of record. - Data sharing
Share live lakehouse data with internal teams, partners, and Oracle applications without copying or moving it. Data sharing helps to keep every consumer on the most current, authoritative version.
Oracle AI Data Platform gives data scientists and ML engineers a fully managed environment to help build, train, track, and operationalize machine learning models directly over lakehouse data. The full MLOps lifecycle—distributed Spark training, experiment tracking, model registry, and catalog-published deployment—runs in a customer-managed and customer-governed workspace with no infrastructure to manage.
- ML pipelines and workflows: Orchestrate end-to-end ML pipelines with reusable components—data preparation, feature engineering, training, and evaluation—using AI Data Platform's workflow infrastructure. Build once, run on schedule or on trigger, with role-based access control policies you define and control.
- Experiments and model registry: Track all model training runs with automatic metrics logging, hyperparameter capture, and artifact versioning. Compare experiments, register production models, and manage lifecycle workflows.
- Model publishing and catalog registration: - Publish trained models to the AI data catalog to make them discoverable, versioned, and accessible across agents, applications, and workflows. Lineage tracking and access control policies are applied at registration.
- Apache Spark with GPU: Scale feature engineering and model training across distributed Spark clusters, accelerating workloads with NVIDIA market-leading GPU-powered ETL and ML.
- Data science agents (coming soon): AI agents that autonomously explore data sets, generate hypotheses, write and execute code, and iterate on model training, dramatically reducing time from raw data to production model.
Build AI agents and applications grounded in your enterprise's own data—not generic LLM capabilities. Your agents and apps are access-controlled by your policies and enriched with your business semantics and domain knowledge. AI agents are connected to your AI data catalog, business ontologies, and enterprise systems so they can reason within the context your company actually runs on. Compose multi-agent systems using any foundation model—from no-code visual builders to full pro-code development—and deploy to managed AI compute with built-in observability.
- No-code visual flow builder: Design and compose agents visually with a drag-and-drop canvas. Connect SQL tools, RAG knowledge bases, LLM prompt nodes, and fan out to multiple tools—all without writing a line of code. Switch foundation models from a drop-down without rebuilding the flow.
- Pro-code development: Write agents in Python using the AI Data Platform SDK with full access to LangChain, OCI Generative AI, and any open source library. Every visual flow capability is fully accessible in code; import scikit-learn, LangChain, or any framework alongside the agent SDK.
- Multi-agent systems: Design and orchestrate systems of cooperating AI agents, such as orchestrator agents, specialist sub-agents, and tool-using agents, to help tackle complex, multi-step enterprise workflows autonomously using the A2A protocol.
- Any foundation model: Use any model on OCI, such as Llama, Cohere, Mistral, Grok, and more, or bring your own fine-tuned models. Swap models from the Oracle Cloud Infrastructure (OCI) Compute drop-down menu without rebuilding application logic.
- AIOps and observability: Full observability across the agent lifecycle from development to production. Test agents interactively in the platform’s playground, inspecting tool calls, LLM reasoning, and outputs before deployment. Sessions capture an audit trail with status, duration, inputs/outputs, and per-step event detail across dev, test, and production. Monitor latency, token usage, error rates, and custom business KPIs in real time.
A single, integrated development environment for data engineers, data scientists, and AI developers to collaborate on end-to-end data and AI projects with enterprise-grade role-based access control (RBAC), CI/CD, versioning, and auditability built in. Connect all personas through shared tools, notebooks, and pipelines, all powered by integrated access to the platform's underlying services and catalog.
- Workbench home dashboard: A unified home screen with access to every capability—master catalog, workspaces, workflows, compute, agent flows, and administrative functions, including data sharing, roles, and audit logs. Quick-action tiles drop you directly into AI integration, get data, analyze, or manage access functions.
- Workspaces: Project-scoped environments where teams collaborate on notebooks, pipelines, agents, and experiments. All artifacts are versioned, shared, and access-controlled within the workspace boundary with full role-based access control per project.
- Notebooks, workflows, and agents: All development artifacts are managed in one place, including Jupyter-compatible notebooks, pipeline workflow DAGs, AI agents, and ML experiments. Share, version, and collaborate across the team without context-switching.
- SQL tool and compute management: Run ad-hoc SQL queries directly against catalog tables with compute lifecycle controls built in. Attach, detach, or spin up new AI compute resources from within the IDE—no separate console required.
- CI/CD and Git integration: Native Git integration for versioning notebooks, pipelines, agent definitions, and model configurations. Connect to GitHub, GitLab, or Bitbucket for continuous integration and automated deployment of data-to-AI project artifacts.
- RBAC, auditing, and network isolation: Granular, role-based access control across workspaces, artifacts, and compute. Comprehensive audit logs for every user action. Network isolation with private endpoints helps ensure sensitive workloads never touch the public internet.
Discover, understand, and manage access to all your data and AI assets in a single, unified catalog that spans the full medallion architecture, including bronze ingestion, silver curation, and gold AI-ready data products. Oracle AI Data Platform's AI data catalog connects to Autonomous AI Database, OCI Object Storage, and third-party sources through external catalogs, surfacing rich business meaning through semantic context and ontologies. Every team finds not just what data exists but what it means to the business. Every AI agent automatically inherits that understanding.
- Unified data and AI asset catalog: A single catalog for all data and AI assets, including structured tables, unstructured files, knowledge bases, ML models, feature stores, and agent definitions. The catalog is access-managed with consistent policies across data and AI. It covers the full medallion architecture, enabling fast ingestion, curation, and delivery of data products and AI applications at every layer.
- External catalogs and asset discovery: Connect to external data sources—Autonomous AI Database, OCI Object Storage, and third-party systems—without unnecessarily moving or duplicating data. Automatically discover and catalog structured and unstructured assets with AI-assisted metadata enrichment and lineage tracking from the point of connection.
- Business ontologies and semantic layer: Define domain ontologies and semantic relationships between business concepts. Business glossaries, semantic ontologies, domain taxonomies, and AI-generated synonyms enable users find data by meaning, not table names. AI agents automatically inherit this semantic understanding.
- Zero copy: Query data where it lives. Access and query data without moving or copying it. Connect directly to your existing Oracle Database, Autonomous AI Database, and Exadata and query in place using SQL. Data stays in its authoritative source while the catalog federates access, applies role-based access control, and surfaces it, reducing duplication and lowering cost.
- Zero ETL: Help eliminate ETL pipelines with Oracle GoldenGate for AI-powered, real-time, log-based replication from any source database for high-throughput streaming ingestion directly into the lakehouse. Data is cataloged and AI-ready the moment it lands.
- Volumes: Volumes store unstructured data alongside data assets in the catalog. Attach to knowledge bases to help enable agents and applications to securely retrieve unstructured content, such as documents, PDFs, and images.
- Data lineage: Visualize end-to-end data lineage, including raw ingestion through transformations, ML feature engineering, model training, and AI application serving. Instantly understand the impact of upstream changes across the full data and AI pipeline.
Enterprise AI at scale demands enterprise-grade security, access management, and auditability, applied consistently across every data asset, model, and agent. Oracle AI Data Platform enforces a two-layer security model: Oracle Cloud Infrastructure Identity and Access Management (IAM) for identity and authentication, combined with Oracle AI Data Platform Workbench for fine-grained access control across every catalog asset, workspace, and AI resource, with comprehensive audit logs for full traceability. Manage your entire data and AI estate without bolting security on as an afterthought.
- Two-layer security model: Security operates at two levels: OCI IAM handles identity, authentication, and cloud-level access; AI Data Platform Workbench controls who can discover, read, modify, and use each data and AI asset within the platform. Both policies are defined and managed by the customer. Oracle maintains the framework that enforces them. You gain the advantages of a defense-in-depth architecture without ceding control.
- AI Data Platform Workbench: Granular, role-based access control across workspaces, catalog assets, compute resources, agents, and administrative functions. Roles are applied consistently across data and AI with no gaps between what users can see in the catalog and what they can act on in the platform.
- Audit logging and traceability: Comprehensive audit logs for every user action, data access, agent interaction, and administrative change provide traceability across the platform to support compliance, investigation, and access history reporting.
- Network isolation and private endpoints: Deploy workspaces, compute, and data connections within private VCN subnets with private endpoints. Sensitive workloads never traverse the public internet. Network isolation is enforced at the infrastructure layer.
- OCI Identity and Access Management and security integration: OCI IAM handles identity federation and authentication across the platform. Deep integration with OCI Vault for secrets management, OCI Certificates for TLS, and OCI Security Advisor for posture recommendations provides a unified security control plane across data, AI, and infrastructure.
A centralized registry for discovering and managing AI agents at enterprise scale, including agents built with AI Data Platform and third-party agents as well as MCP servers and tools. The AI registry tracks every agent's identity, capabilities, permissions, versions, and interaction logs, giving platform administrators visibility and control over the growing fleet of AI agents operating across the enterprise.
- Centralized agent registry A unified registry to help you list, version, and manage all your AI agents whether they are built with AI Data Platform or third-party tools. Track each agent's identity, declared capabilities, permission scope, version history, and interaction logs. Discover agents by capability, domain, or team with rich metadata for management, access control, and reuse at enterprise scale.
- Agent-to-agent (A2A) protocol: Enable structured, standardized communication between AI Data Platform agents and third-party agents using the open A2A protocol. Compose complex workflows where specialist agents collaborate with orchestrator agents with clear identity, capability declaration, and permission boundaries enforced at every interaction.
- Model Context Protocol (MCP) servers and tools: Register and expose MCP servers and tools. Agents dynamically discover and invoke tools at runtime, including database queries, REST APIs, and custom business functions, without hardcoded bindings. Tool permissions are managed through the registry policies you define consistent with how agent access is controlled.
Give nontechnical users access to the full power of your enterprise data through self-service analytics, curated AI agents, and AI-powered insights. AI capabilities are embedded directly in the business workflows where decisions happen. No technical skills required. It’s enterprise AI democratized.
- Analytics in business workflows: Oracle Analytics Cloud embeds world-class analytics directly into the applications your teams use every day, including Oracle Fusion ERP, HCM, and CX. Ask questions in natural language, surface AI-generated narratives, and share centrally managed dashboards within the workflow.
- A unified conversational interface (coming soon): A single pane of glass to discover, query, and collaborate with your organization's AI agents. Agent Hub interprets business user requests, finds and invokes the right agent, and presents results in context—all through natural language. No technical skills required.
- Curated AI agent library: Browse a curated library of approved agents—internal agents built by your data teams and vetted third-party agents—with descriptions, example prompts, and usage guidance for common business tasks.
- Managed access and security: Users can manage every agent interaction and analytics query by the same RBAC policies as the underlying data. Users only see agents and data they're authorized to access. It’s enterprise security without extra configuration.
See AI Data Platform in Action
Data Engineer
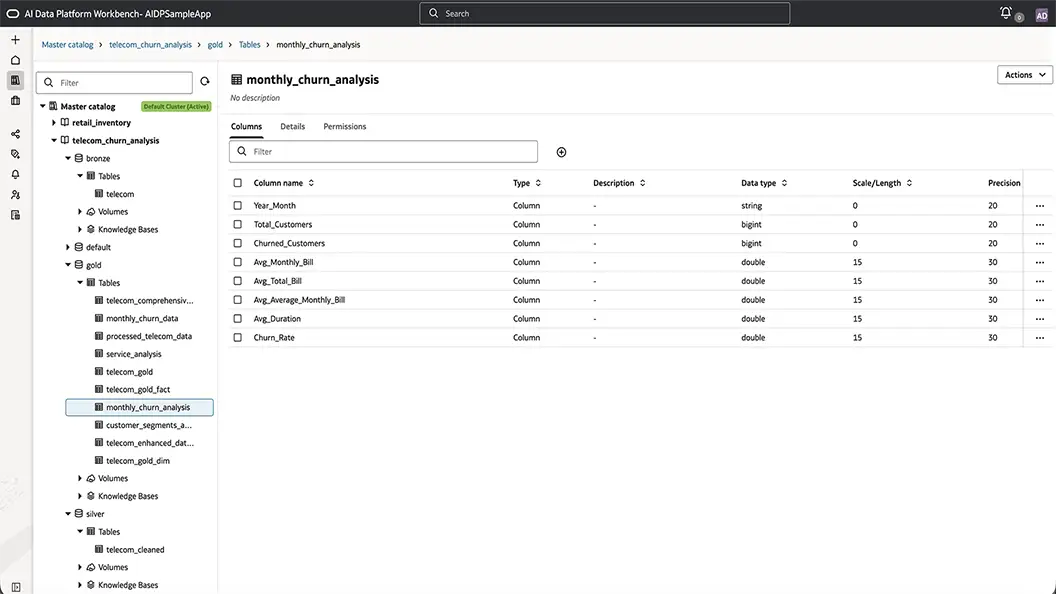
Build a complete lakehouse from raw data to AI-ready gold
Oracle AI Data Platform gives data engineers one path from ingestion to consumption across structured and unstructured data. Raw data lands in object storage, is refined with Spark into trusted silver data sets, and is delivered as curated gold data ready for analytics, AI agents, and downstream applications.
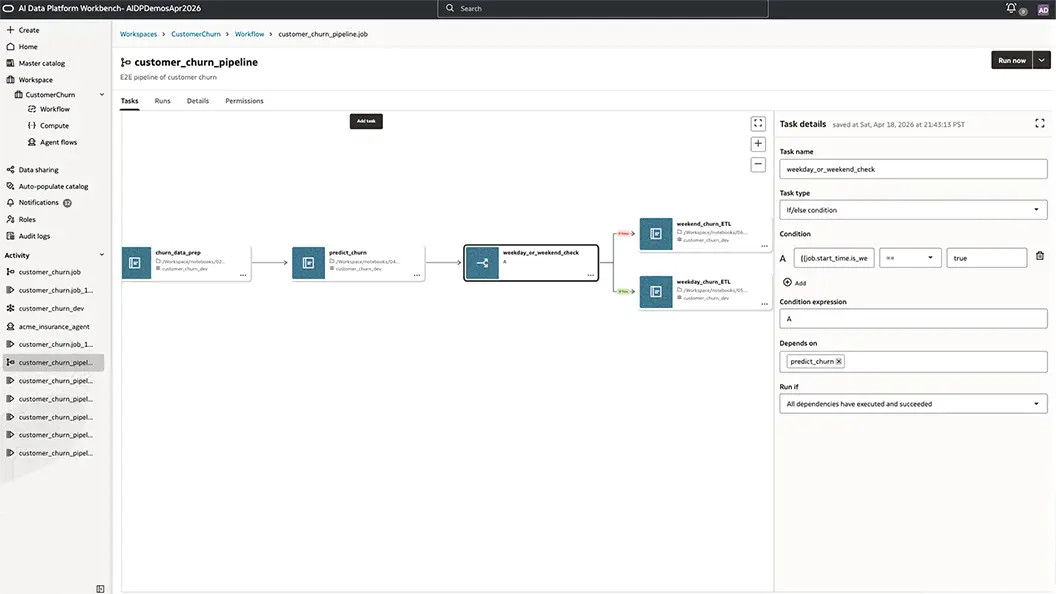
Design pipelines in one managed workspace
Data engineers can build ingestion, transformation, and enrichment pipelines via workflow jobs without switching platforms. This shortens development cycles while keeping every stage access-controlled, reusable, and easier to operate at enterprise scale.
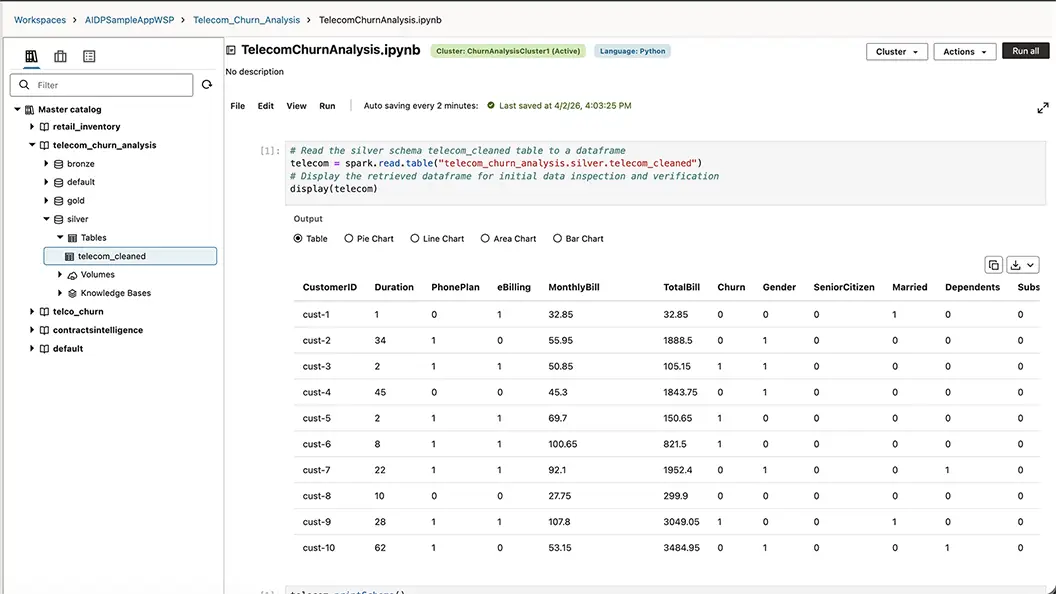
Run Spark and SQL where your data already lives
Teams can use Spark for large-scale processing and SQL for fast exploration and reporting, choosing the best engine for each workload. With in-place access across object storage and connected databases, engineers can analyze and prepare data without unnecessary movement or duplication.
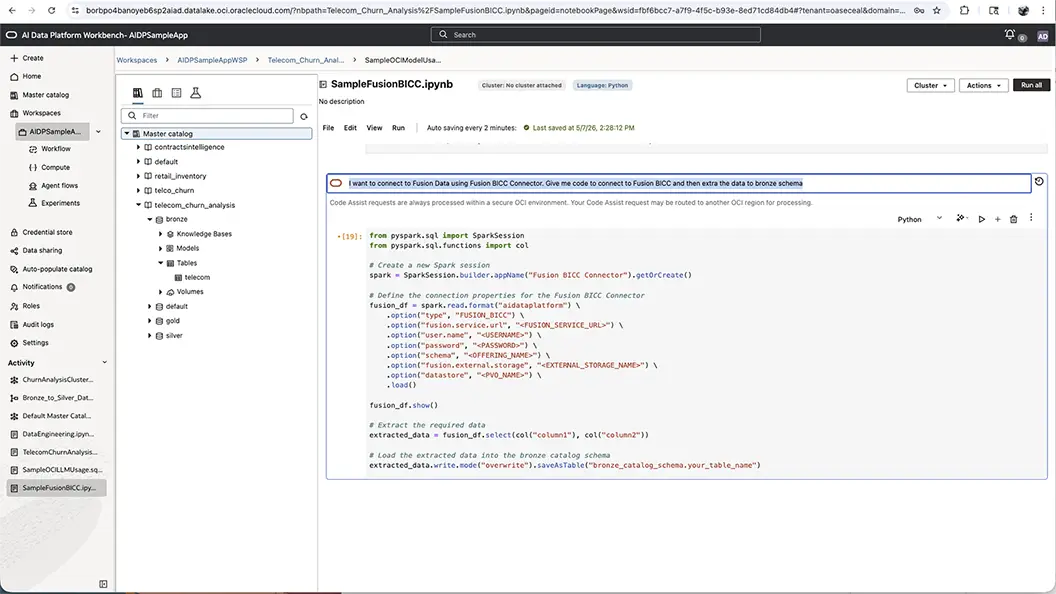
Accelerate pipeline delivery with AI-assisted engineering
AI-assisted development helps engineers move from source connection to production-ready pipeline faster with code generation, smart recommendations, and guided workflow creation. Combined with direct Oracle Fusion data integration, teams can quickly transform ERP, HCM, SCM, and CX data into managed AI-ready assets.
Data Steward
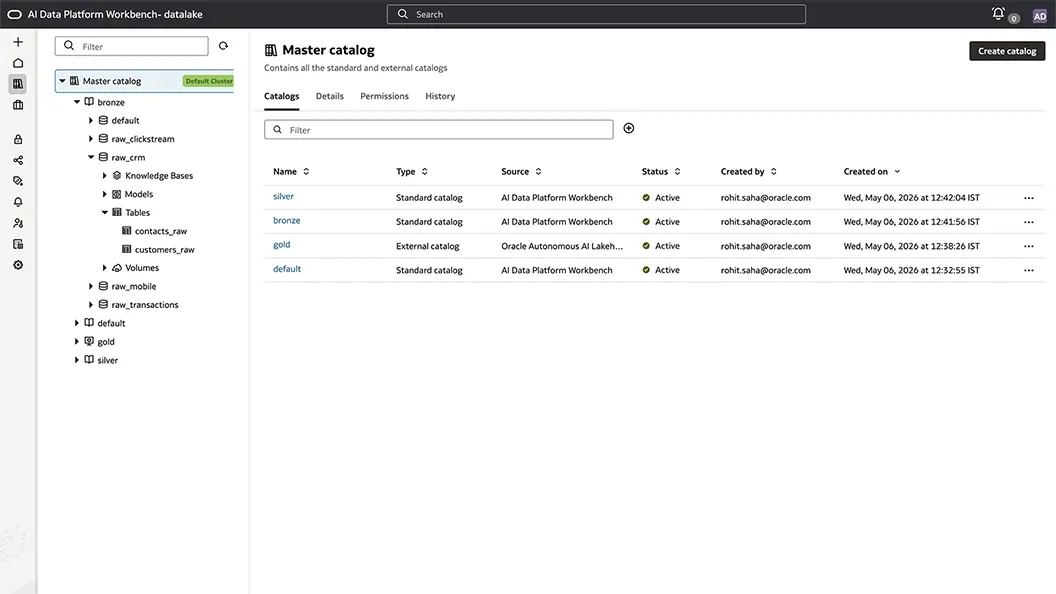
A unified metadata layer across your entire Oracle Cloud data estate
The master catalog serves as the central metadata layer, registering and organizing metadata without moving or copying underlying data. It connects to data where it resides across Autonomous AI Database, Oracle Database, and OCI Object Storage, covering both structured assets, such as tables, views, and schemas, and unstructured data.
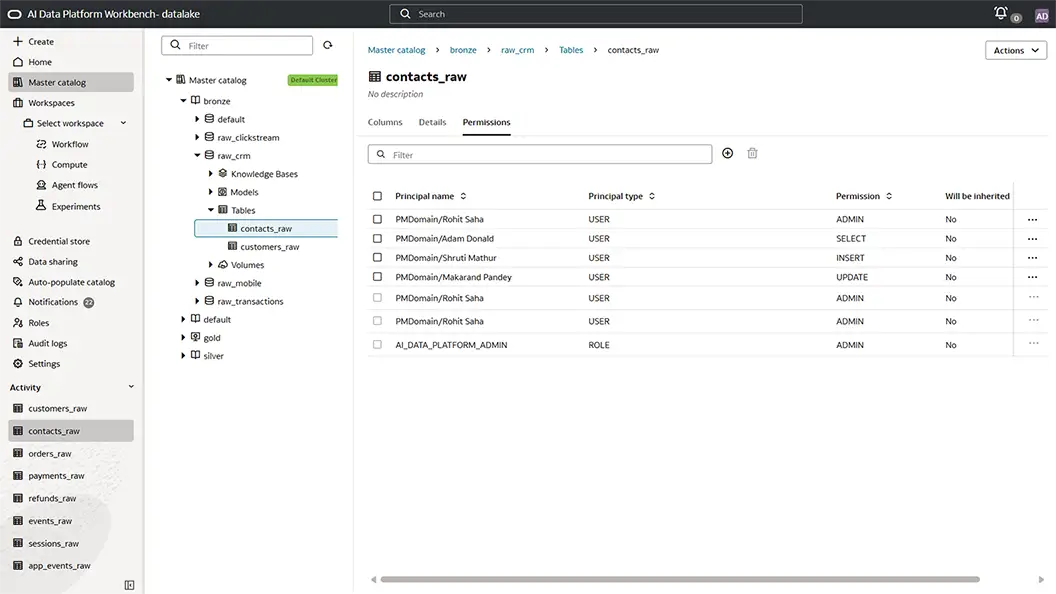
Consistent access control across all AI and data workloads
A centralized role-based access management framework designed to support secure data usage. Oracle AI Data Platform Workbench provides fine-grained access controls and policy management at the data layer, helping organizations manage how users and AI workloads access data while supporting scalable AI initiatives.
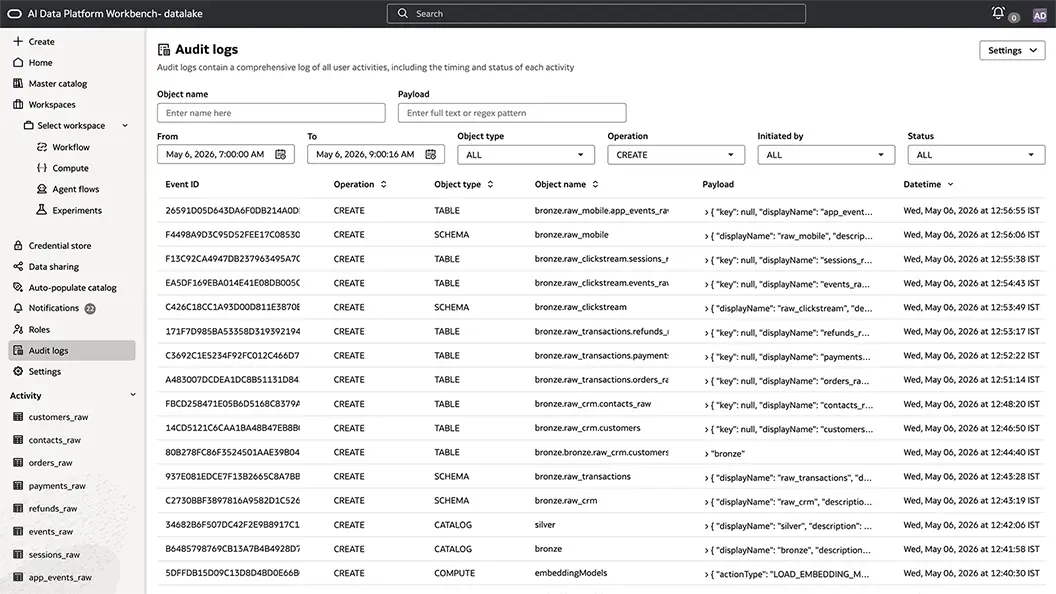
Complete visibility into data access across all AI and data workloads
Provide transparency and security with audit logs that track who accessed what data, when, and how. Gain end-to-end visibility across Oracle AI Data Platform Workbench for auditing and operational oversight.
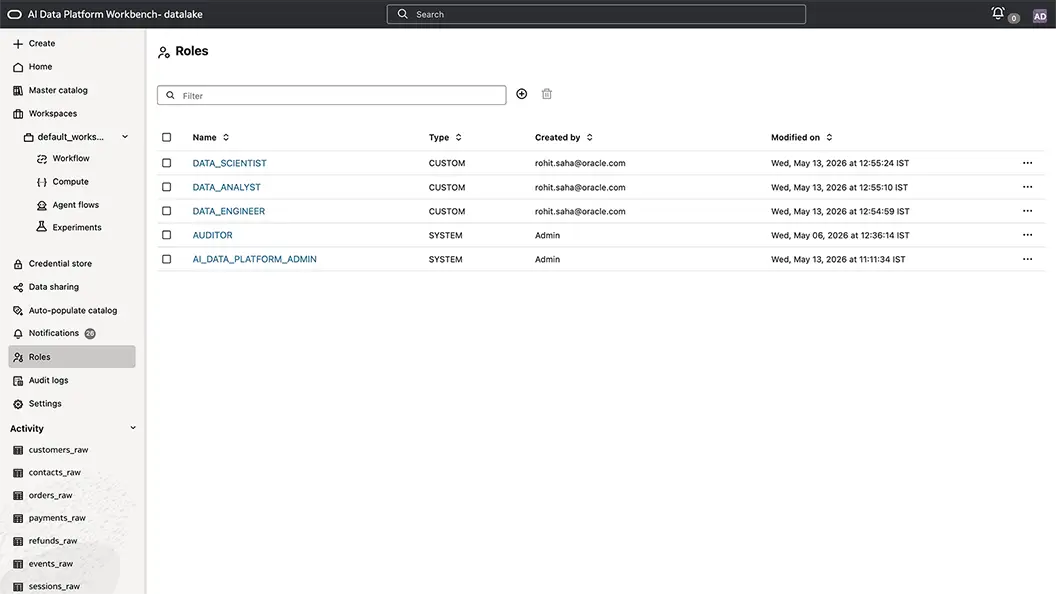
Role-based access management across AI and data workloads
Define and manage roles across Oracle AI Data Platform Workbench to ensure users and AI workloads have appropriate access to data, tools, and platform resources. Granular role-based controls simplify administration, strengthen security, and make it easier to apply access policies.
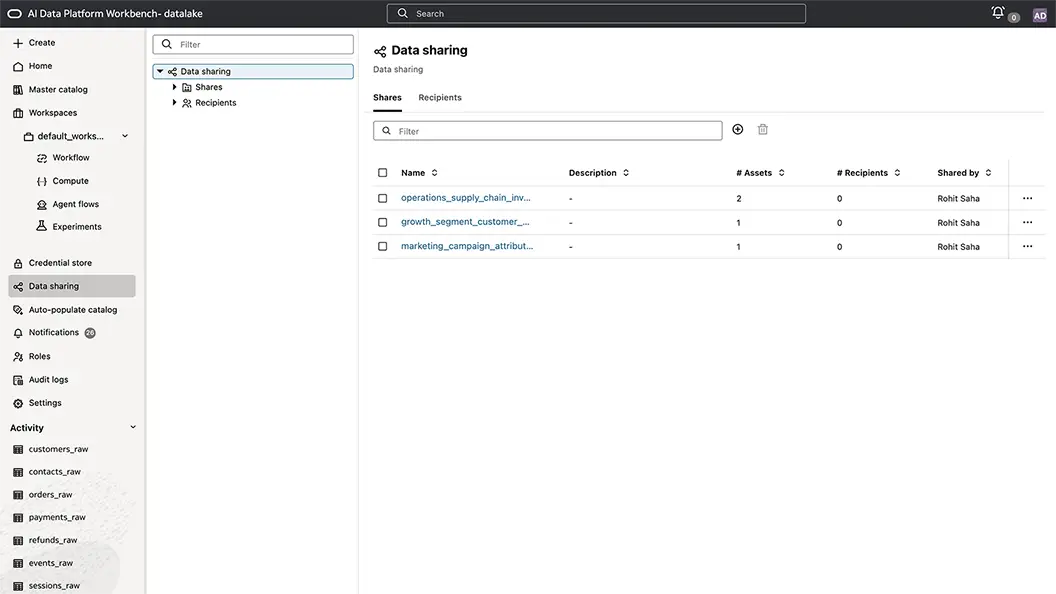
Seamless data sharing
Securely share data across teams and projects without unnecessary duplication or data movement. Oracle AI Data Platform Workbench enables controlled, policy-driven data sharing that improves collaboration, accelerates access to trusted data, and simplifies enterprise-scale data operations.
Data Scientist
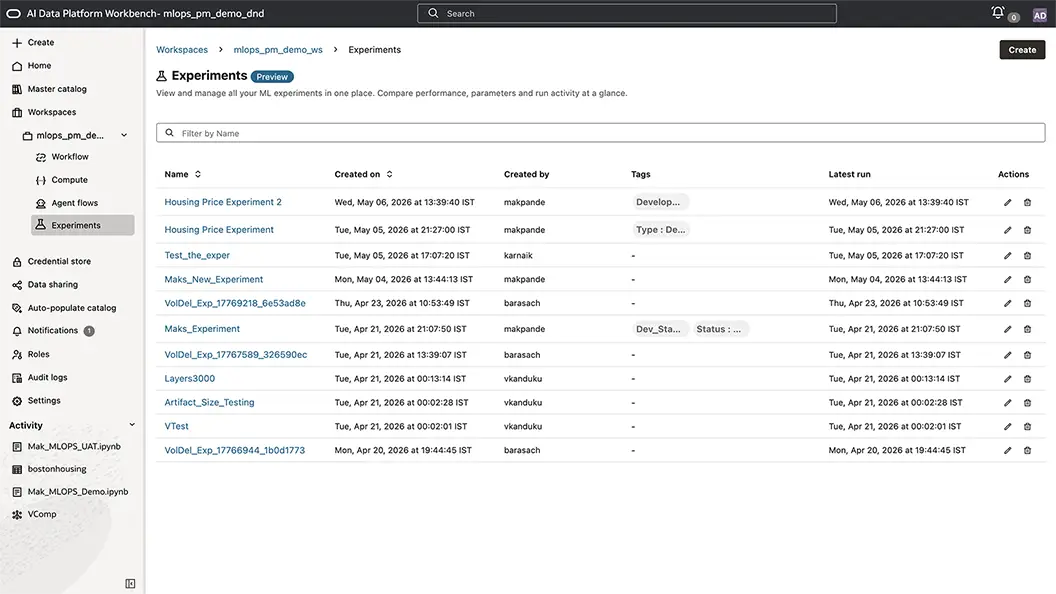
Experiment tracking for every team workspace
Experiments in Oracle AI Data Platform Workbench keep teams separated by workspace while autologging captures parameters, metrics, and artifacts, creating a reproducible history that reduces rework and makes it easy to rerun past experiments with controlled changes. AI Data Platform Workbench handles the administrative tasks so data scientists can focus on the science.
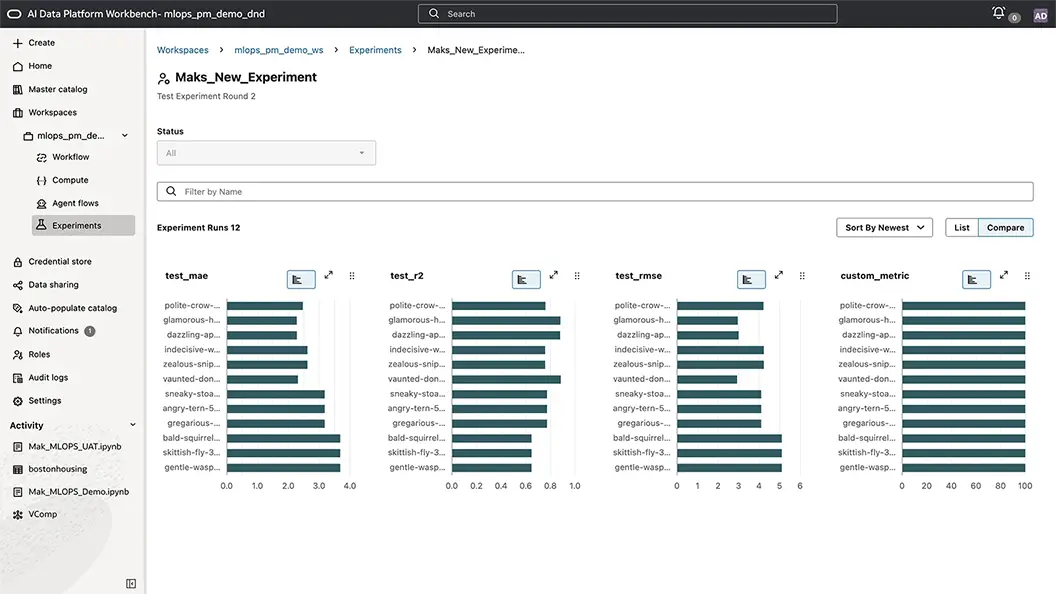
Promote the winning models to the registry with a one-click run comparison
Data scientists can filter and compare runs to identify the top performer, then register it from the experiment run into the master catalog–backed model registry with versions, tags, and custom fields, turning “best run” into a shared, discoverable champion asset. AI Data Platform automatically manages versions when improvements are made.
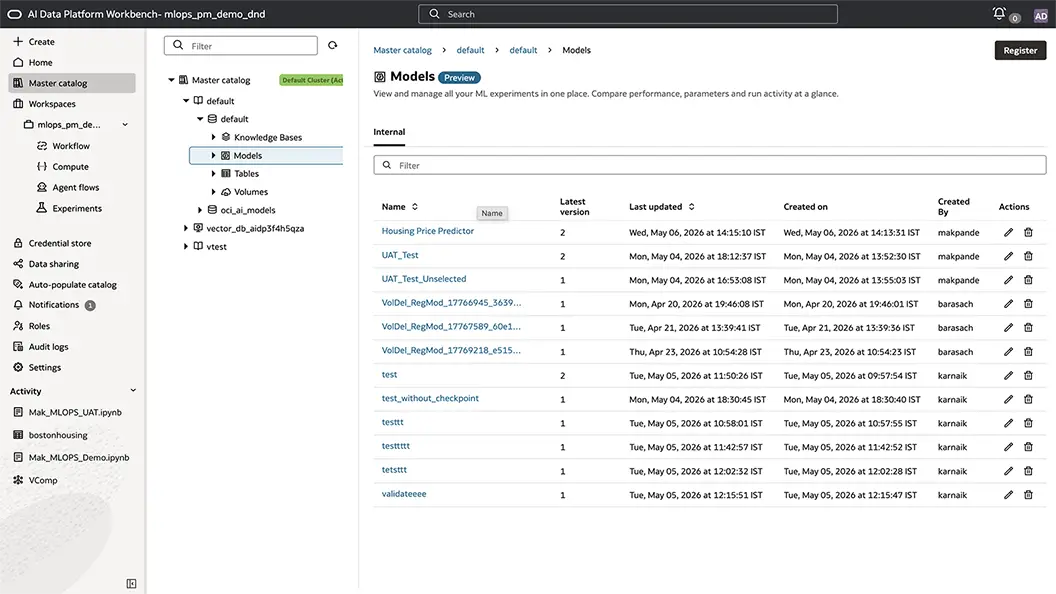
From best model to inference, no packaging overhead
Promote the best model into the registry with automatic versioning, tags, and custom metadata, making it easy to discover and reuse the right model without relying on institutional knowledge or side channels. Load the latest or a specific version directly into notebooks and run batch inference. AI Data Platform keeps everything from experimentation to inferencing simple, consistent, and repeatable.
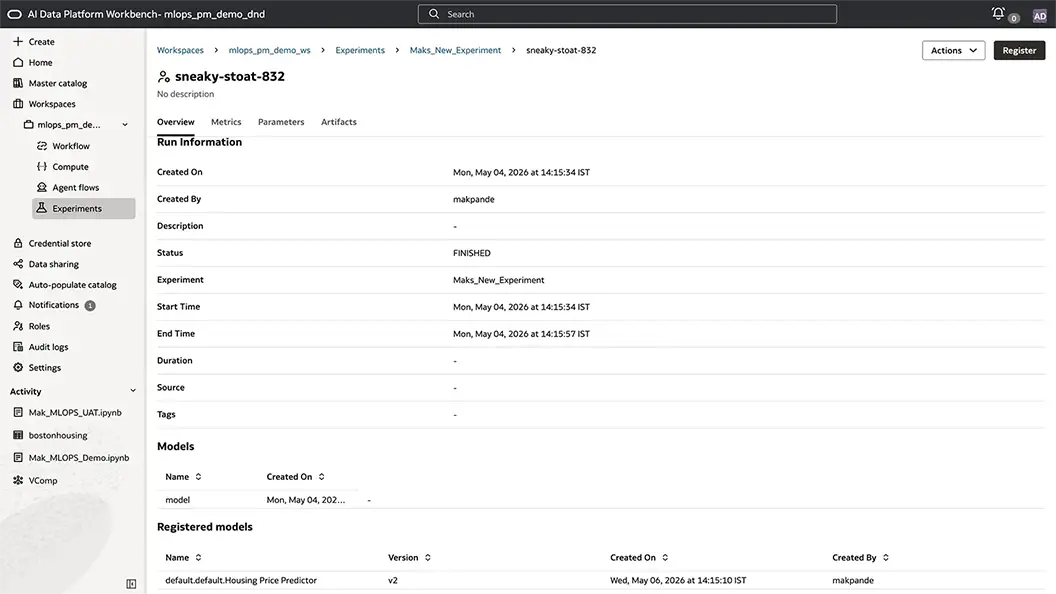
End-to-end lineage helps to make models generated explainable and auditable
Registered models in AI Data Platform trace back to the exact experiment run that produced them, surfacing lineage and run conditions, such as hyperparameters, environment variables, metrics, and artifacts. Teams can understand what was built, how it was built, and why it performs the way it does.
AI Developer
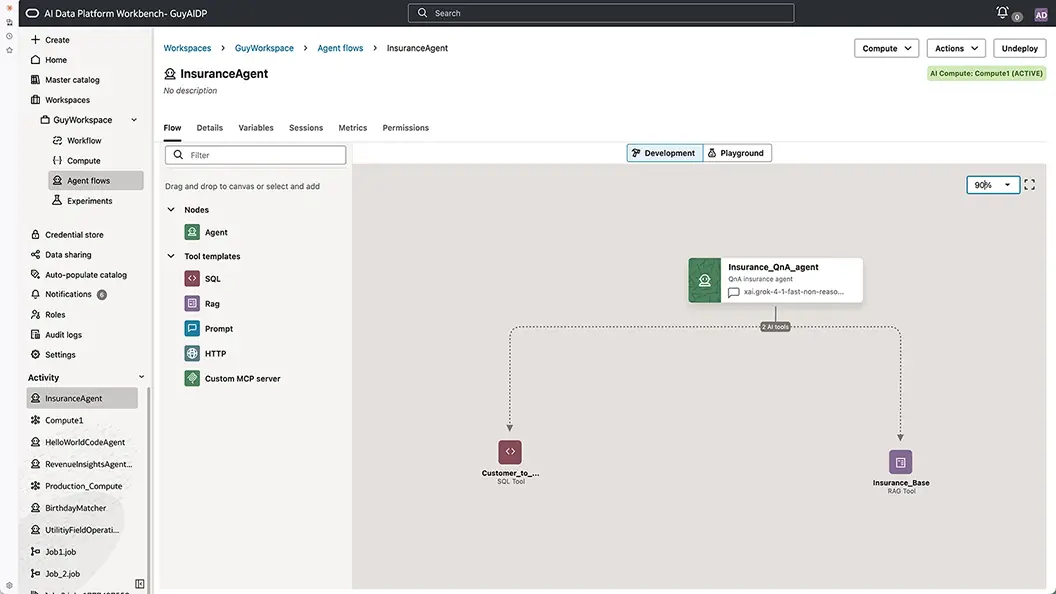
A unified platform for building, managing, and deploying enterprise AI (Coming soon)
Oracle AI Data Platform brings together the tools, integrations, access management and audit capabilities teams need to take AI from development to production. Build agents and applications using visual low-code tools or code-first notebooks, grounded in enterprise knowledge through native vector store integration linked to the master catalog. Best-in-class LLMs are available via OCI Generative AI and Oracle AI Database 26ai, with full lifecycle management ensuring every AI asset is registered, versioned, and tested. Fusion AI Agent Studio integration lets custom agents embed directly into Oracle SaaS applications—closing the loop between AI development and real-world business workflows.
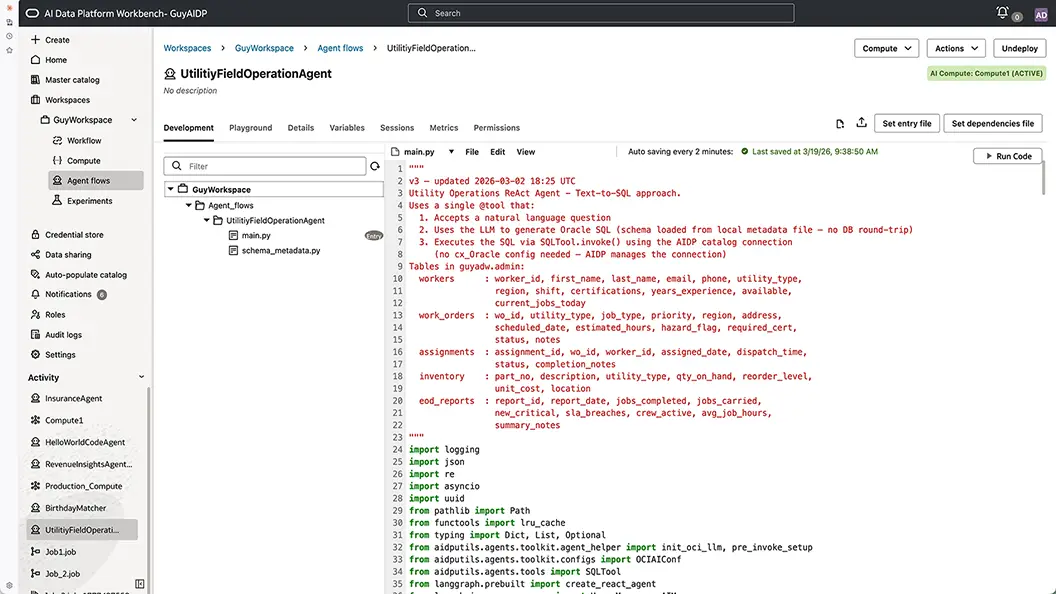
High-code agent development with full platform power
Define agent flows in code using LangGraph, open source frameworks, and third-party Python libraries within AI Data Platform Workbench. The built-in utilities library gives agents seamless access to model configuration, guardrails, and system tools, such as RAG, MCP, SQL, and prompt management. Code-built or canvas-built, all flows test through the same unified playground.
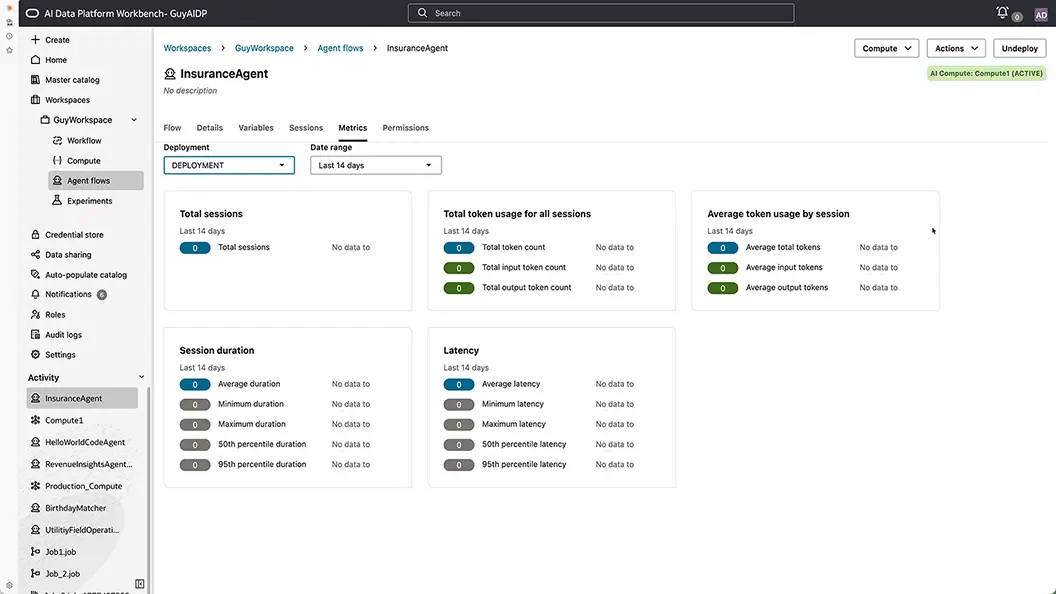
End-to-end observability built into the platform (coming soon)
Oracle AI Data Platform provides built-in observability tools that give teams full visibility into how their AI agents are performing in production. From tracing individual runs to monitoring outputs and surfacing issues in real time, teams can detect, diagnose, and resolve problems without leaving the platform.
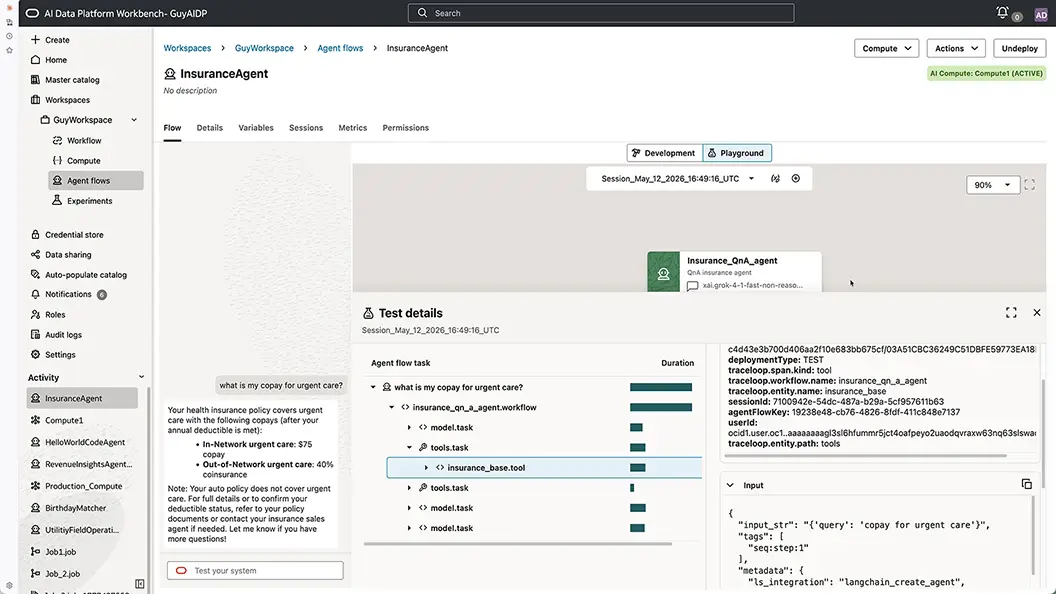
Flexible agent building, testing, and debugging with traceability and an integrated playground (coming soon)
Oracle AI Data Platform supports both no-code, canvas-style agent flow definition and code-based development through LangGraph, giving teams the freedom to build the way they work best. Dedicated build and test panels let developers iterate quickly, with changes made in the build phase immediately available in a comprehensive testing playground so teams can move from idea to working agent flow without unnecessary friction.
Business User
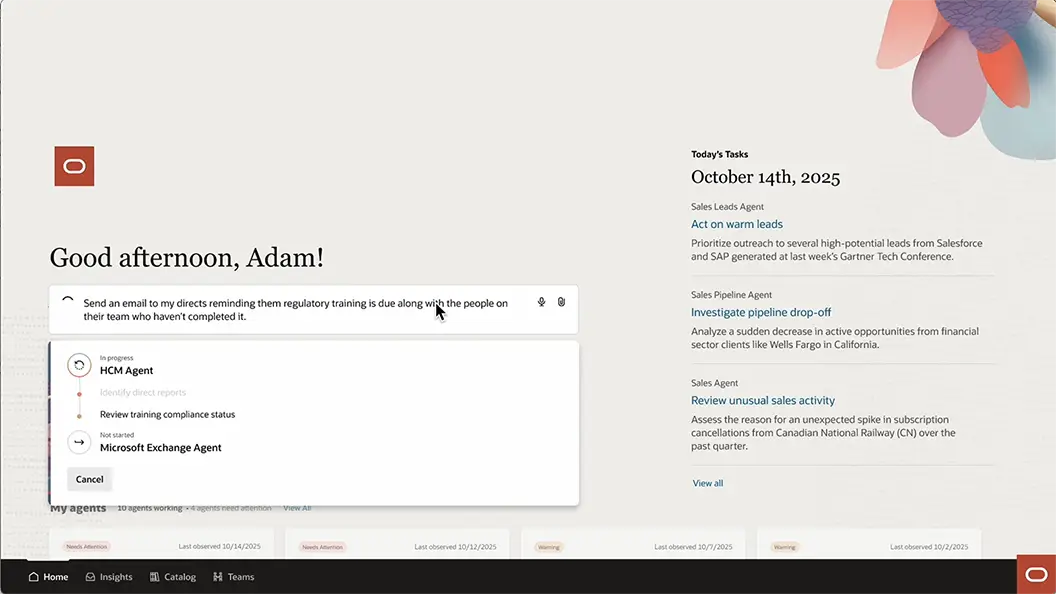
All your agents in one place (coming soon)
Every AI agent your organization uses, whether built in-house, embedded in Oracle Fusion, or connected from third-party systems, will be accessible from a single conversational interface. Ask a question, get automatically routed to the right agent, and pick up exactly where you left off with full session history preserved across every interaction.
Featured AI Data Platform blogs
Agents vs. Workflows: Where Does the ROI Actually Live?
Most enterprises aren’t failing with AI agents because of the technology—they’re failing because they’re using agents where simple workflows would do the job better. This blog explains the key differences between workflows and autonomous agents, and how choosing the right approach impacts ROI, scalability, governance, and cost. It also provides a practical framework for deciding when agentic AI is truly worth the investment.

-
May 12, 2026
You Didn’t Sign Up to Be an Infrastructure Engineer
-
February 13, 2026
The 3 Building Blocks of Enterprise AI
-
December 8, 2025
Getting Started on your Oracle AI Data Platform Journey
