Streaming FAQ
General Questions
What is Oracle Cloud Infrastructure Streaming?
Oracle Cloud Infrastructure (OCI) Streaming provides a fully managed, scalable, and durable messaging solution for ingesting continuous, high-volume streams of data that you can consume and process in real-time. Streaming is available in all supported Oracle Cloud Infrastructure regions. For a list, visit the Regions and Availability Domains page.
Why should I use Streaming?
Streaming is a serverless service that offloads the infrastructure management ranging from networking to storage and the configuration needed to stream your data. You do not have to worry about the provisioning of infrastructure, ongoing maintenance, or security patching. The Streaming service synchronously replicates data across three Availability Domains, providing high availability and data durability. In regions with a single Availability Domain, the data is replicated across three Fault Domains.
How can I use Streaming?
Streaming makes it easy to collect, store, and process data generated in real -time from hundreds of sources. The number of use cases is nearly unlimited, ranging from messaging to complex data stream processing. Following are some of the many possible uses for Streaming:
- Messaging: Use Streaming to decouple the components of large systems. Producers and consumers can use Streaming as an asynchronous message bus and act independently and at their own pace.
- Metric and log ingestion: Use Streaming as an alternative for traditional file-scraping approaches to help make critical operational data quickly available for indexing, analysis, and visualization.
- Web or mobile activity data ingestion: Use Streaming for capturing activity from websites or mobile apps, such as page views, searches, or other user actions. You can use this information for real-time monitoring and analytics, and in data warehousing systems for offline processing and reporting.
- Infrastructure and apps event processing: Use Streaming as a unified entry point for cloud components to report their lifecycle events for audit, accounting, and related activities.
How do I get started with Streaming?
You can start using Streaming as follows:
- Create a stream by using the Oracle Cloud Infrastructure Console or the CreateStream API operation.
- Configure producers to publish messages to the stream. See Publishing Messages.
- Build consumers to read and process data from the stream. See Consuming Messages.
Alternately, you can also use Kafka APIs to produce and consume from a stream. For more information refer to Using Streaming with Apache Kafka.
What are the service limits of Streaming?
The throughput of Streaming is designed to scale up without limits by adding partitions to a stream. However, there are certain limits to keep in mind while using Streaming:
- The maximum retention period for messages in a stream is seven days.
- The maximum size of a unique message that can be produced to a stream is 1 megabyte (MB).
- Each partition can handle up to 1 MB per second of throughput with any number of requests for writes.
- Each partition can support a maximum total data write rate of 1 MB per second and a read rate of 2 MB per second.
How does Streaming compare to a queue-based service?
Streaming provides stream-based semantics. Stream semantics provide strict ordering guarantees per partition, message replayability, client-side cursors, and massive horizontal scale of throughput. Queues do not offer these features. Queues can be designed to provide ordering guarantees if using FIFO queues, but only at the cost of adding significant overhead in performance.
Key Concepts
What is a stream?
A stream is a partitioned, append-only log of messages, to which producer applications write data to and from which consumer applications read data.
What is a stream pool?
A stream pool is a grouping that you can use to organize and manage streams. Stream pools provide operational ease by providing an ability to share configuration settings across multiple streams. For example, users can share security settings like custom encryption keys on the stream pool to encrypt the data of all the streams inside the pool. A stream pool also enables you to create a private endpoint for streams by restricting internet access to all of the streams within a stream pool. For customers using Streaming's Kafka compatibility feature, the stream pool serves as the root of a virtual Kafka cluster, thereby enabling every action on that virtual cluster to be scoped to that stream pool.
What is a partition?
A partition is a base throughput unit that enables horizontal scale and parallelism of production and consumption from a stream. A partition provides a capacity of 1 MB/sec data input and 2 MB/sec data output. When you create a stream, you specify the number of partitions you need based on the throughput requirements of your application. For example, you can create a stream with 10 partitions, in which case you can achieve a throughput of 10 MB/sec input and 20 MB/sec output from a stream.
What is a message?
A message is a base64-encoded unit of data stored in a stream. The maximum size of a message you can produce to a partition in a stream is 1 MB.
What is a key?
A key is an identifier used to group related messages. Messages with the same key are written to the same partition. Streaming ensures that any consumer of a given partition will always read that partition's messages in exactly the same order as they were written.
What is a producer?
A producer is a client application that can write messages to a stream.
What is a consumer and a consumer group?
A consumer is a client application that can read messages from one or more streams. A consumer group is a set of instances which coordinates messages from all of the partitions in a stream. At any given time, the messages from a specific partition can only be consumed by a single consumer in the group.
What is a cursor?
A cursor is a pointer to a location in a stream. This location could be a pointer to a specific offset or time in a partition, or to a group's current location.
What is an offset?
Each message within a partition has an identifier called offset. Consumers can read messages starting from a specific offset and are allowed to read from any offset point they choose. Consumers can also commit the latest processed offset so they can resume their work without replaying or missing a message if they stop and then restart.
Security
How secure is my data when I am using Oracle Cloud Infrastructure Streaming?
Streaming provides data encryption by default, both at rest and in transit. Streaming is fully integrated with Oracle Cloud Infrastructure Identity and Access Management (IAM), which lets you use access policies to selectively grant permissions to users and groups of users. While using REST APIs, you can also securely PUT and GET your data from Streaming through SSL endpoints with HTTPS protocol. Further, Streaming provides complete tenant-level isolation of data without any "noisy neighbor" problems.
Can I use my own set of master keys to encrypt the data in streams?
Streaming data is encrypted both at rest and in transit, along with ensuring message integrity. You can let Oracle manage encryption, or use Oracle Cloud Infrastructure Vault to securely store and manage your own encryption keys if you need to meet specific compliance or security standards.
What security settings of a stream pool can I edit after its creation?
You can edit the stream pool's data encryption settings at any time if you would like to switch between using "Encryption provided by Oracle Keys" and "Encryption managed using Customer Managed Keys". Streaming does not impose any restrictions on how many times this activity can be performed.
How do I manage and control access to my stream?
Streaming is fully integrated with Oracle Cloud Infrastructure IAM. Every stream has a compartment assigned. Users can specify role-based access control policies that may be used to describe fine-grained rules at a tenancy, compartment, or single-stream level.
Access policy is specified in a form of "Allow <subject> to <verb> <resource-type> in <location> where <conditions>".
What authentication mechanism do Kafka users have to use with Streaming?
Authentication with the Kafka protocol uses auth tokens and the SASL/PLAIN mechanism. You can generate tokens on the console user details page. See Working with Auth Tokens for more information. We recommend you create a dedicated group/user and grant that group the permission to manage streams in the appropriate compartment or tenancy. You then can generate an auth token for the user you created and use it in your Kafka client configuration.
Can I privately access Streaming APIs from my Virtual Cloud Network (VCN) without using public IPs?
Private endpoints restrict access to a specified virtual cloud network (VCN) within your tenancy so that its streams cannot be accessed through the internet. Private endpoints associate a private IP address within a VCN to the stream pool, allowing Streaming traffic to avoid traversing the internet. To create a private endpoint for Streaming, you need access to a VCN with a private subnet when you create the stream pool. See About Private Endpoints and VCNs and Subnets for more information.
Integrations
How do I use Oracle Cloud Infrastructure Streaming with Oracle Cloud Infrastructure Object Storage?
You can write the contents of a stream directly to an Object Storage bucket, typically to persist the data in the stream for long term storage. This can be achieved using Kafka Connect for S3 with Streaming. For more information, see the Publishing To Object Storage From Oracle Streaming Service blog post.
How do I use Streaming with Oracle Autonomous AI Database?
You can ingest data from a table in an Oracle Autonomous AI Transaction Processing instance. For more information, see the Using Kafka Connect With Oracle Streaming Service And Autonomous DB blog post.
How do I use Streaming with Micronaut?
You can use the Kafka SDKs to produce and consume messages from Streaming, and you can use Micronaut's built-in support for Kafka. For more information, see the Easy Messaging With Micronaut's Kafka Support And Oracle Streaming Service blog post.
How do I use Streaming to ingest IoT data from MQTT brokers?
For information, see the Ingest IoT Data from MQTT Brokers into OCI-Oracle Streaming Service, OCI- Kafka Connect Harness, and Oracle Kubernetes Engine blog post.
Is Oracle GoldenGate for Big Data compatible with Streaming?
Oracle GoldenGate for Big Data is now certified to integrate with Streaming. For more information, see Connecting to Oracle Streaming Service in the Oracle GoldenGate for Big Data documentation.
Is there a way to ingest data directly from Streaming into Oracle Autonomous AI Lakehouse?
You need to use Kafka JDBC Sink Connect to directly transport streaming data into Oracle Autonomous AI Lakehouse.
- The Using Kafka Connect With Oracle Streaming Service And Autonomous DB blog post explains how to use a Kafka Connect source connector, which pushes data from Oracle Autonomous AI Lakehouse into streams. You need the opposite, a sink connector.
- TheOSS data to ADW in almost real-time blog post explains how to use an external table with an object store path to get data in Oracle Autonomous AI Lakehouse.
Pricing
How am I charged for using Oracle Cloud Infrastructure Streaming?
Streaming uses simple pay-as-you-use pricing, which ensures you only pay for the resources you use. The pricing dimensions include
- GET/PUT request price: Gigabytes of data transferred
- Price for storage (based on retention period hours used): Gigabytes of storage per hour
Please refer to the OCI Streaming page for the latest pricing information.
Will I be charged for provisioning even if I don't use the service?
Streaming’s industry-leading pricing model ensures that you pay only when you use the service within the default service limits.
Is there an additional charge for moving data in and out of Streaming?
Streaming does not charge an additional price for moving data in and out of the service. Further, users can leverage the power of Service Connector Hub to move data to and from Streaming in a serverless manner at no additional price.
Is there a free tier for Streaming?
Streaming currently doesn't operate in the free tier.
Managing Oracle Cloud Infrastructure Streams
What IAM permissions do I need to access Streaming?
Identity and Access Management lets you control who has access to your cloud resources. To use Oracle Cloud Infrastructure resources, you must be given the required type of access in a policy written by an administrator, whether you're using the Console or the REST API with an SDK, CLI, or other tools. Access policy is specified in the form of
Allow <subject> to <verb> <resource-type> in <location> where <conditions>
Administrators of a tenancy can use the policy
Allow group StreamAdmins to manage streams in tenancy
which lets a specified group StreamAdmins do everything with streaming ranging from creating, updating, listing, and deleting streams and their related resources. However, you can always specify more granular policies so that only select users in a group are eligible for only a subset of activities they can perform on a given stream. If you're new to policies, see Getting Started with Policies and Common Policies. If you want to dig deeper into writing policies for Streaming, see Details for the Streaming Service in the IAM policy reference.
How can I automate the deployment of streams at scale?
You can provision a stream and all its associated components like IAM policies, partitions, encryption settings, etc., using the Oracle Cloud infrastructure Resource Manager or Terraform provider for Oracle Cloud Infrastructure. For information on the Terraform provider, see Terraform topic for the Streaming service.
How do I decide the number of partitions I need?
When you create a stream, you must specify how many partitions the stream has. The expected throughput of your application can help you determine the number of partitions for your stream. Multiply the average message size by the maximum number of messages written per second to estimate your expected throughput. Since a single partition is limited to a 1 MB per second write rate, a higher throughput requires additional partitions to avoid throttling. To help you manage application spikes, we recommend allocating partitions slightly higher than your maximum throughput.
How do I create and delete partitions in a stream?
You create partitions when you create a stream, either on the Console or programmatically.
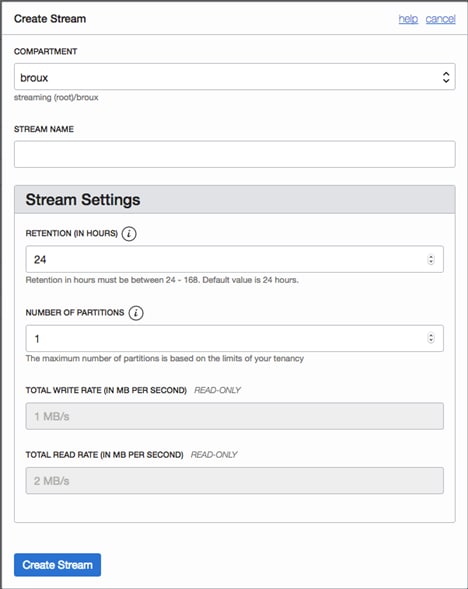
Console UI:
Programmatically:
Create a Stream
CreateStreamDetails streamDetails =
CreateStreamDetails.builder()
.compartmentId(compartmentId)
.name(streamName)
.partitions(partitions)
.build();
A more detailed example is provided with the SDK.
Streaming manages the partitions internally so that you don't need to manage them. A user cannot directly delete a partition. When you delete a stream, all the partitions associated with that stream are deleted.
What is the minimum throughput I can request for a stream?
The throughput of an Oracle Cloud Infrastructure stream is defined by a partition. A partition provides 1 MB per second data input and 2 MB per second data output.
What is the maximum throughput I can request for a stream?
The throughput of an Oracle Cloud Infrastructure stream can be scaled up by adding more partitions to it. There are no theoretical upper bounds on the number of partitions a stream can hold. However, each Oracle Cloud Infrastructure tenancy comes with a default partition limit of 5 for Universal Credits type accounts. If you need more partitions, you can always request to have your service limits increased.
How can I increase service limits for my tenancy using the Oracle Cloud Infrastructure Console?
You can request for an increase in service limit by following these steps:
- In the upper-right corner of the Console, open the User menu and click Tenancy:<tenancy_name>.
![]()
- Click Service Limits, and then click Request a service limit increase.
![]()
- Fill out the form, selecting Others for Service Category and Other Limits for Resource. In Reason for Request, request to increase the number of partitions for the Streaming service in your tenancy.
What are some of the best practices for managing streams?
Here are a few best practices to keep in mind while creating a stream:
- Stream names should be unique within a stream pool. This means you can create two streams with the same name in the same compartment only if they are on different stream pools.
- After a stream is created, you can't change the number of partitions in it. We recommend allocating partitions slightly higher than your maximum throughput. This can help you manage application spikes.
- The retention period of a stream cannot be changed after it is created. By default, the data is stored in a stream for 24 hours. However, it can be configured to retain the data anywhere between 24 and 168 hours. The amount of data stored in a stream has no impact on the performance of the stream.
Producing Messages to an Oracle Cloud Infrastructure Stream
How do I produce messages to a stream?
Once a stream is created and is in the "Active" state, you can begin to produce messages. You can produce to a stream either using the console or via API.
For console: Go to the Streaming service section on the console, located under the Solutions and Platform > Analytics tab. If you already have streams created, select a stream in a compartment and navigate to the "Stream Details" page. Click on the "Produce test Message" button on the console. This will randomly assign a partition key to the message and will write to a partition in the stream. You can view this message in the Recent Messages section by clicking on Load Messages button.
For APIs: You can use either Oracle Cloud Infrastructure Streaming APIs or Kafka APIs to produce to a stream. The message will be published to a partition in the stream. If there is more than one partition, you specify a key to choose which partition to send the message to, and if you don't specify a key, Streaming assigns one for you by generating a UUID and sends the message to a random partition. This ensures the messages without a key are evenly distributed across all partitions. However, we recommend that you always specify a message key so that you can explicitly control the partitioning strategy for your data.
Examples of how to produce messages to a stream using Streaming SDKs are located in the documentation.
How do I know which partition a producer will use?
While using the Oracle Cloud Infrastructure APIs to produce a message, the partitioning logic is controlled by Streaming. This is called server-side partitioning. As a user, you choose which partition to send to based on the key. The key is hashed and the resulting value is used to determine the partition number to send the message to. Messages with the same key go to the same partition. Messages with different keys might go to different partitions or to the same partition.
However, if you are using Kafka APIs to produce to a stream, the partitioning is controlled by the Kafka client and the partitioner in the Kafka client is responsible for partitioning logic. This is called client-side partitioning.
How do I generate an effective partition key?
To ensure uniform distribution of messages, you need an effective value for your message keys. To create one, consider the selectivity and cardinality of your streaming data.
- Cardinality: Consider the total number of unique keys that could potentially be generated based on the specific use case. Higher key cardinality generally means better distribution.
- Selectivity: Consider the number of messages with each key. Higher selectivity means more messages per key, which can lead to hotspots.
Always aim for high cardinality and low selectivity.
How do I ensure that the messages are delivered to the consumers in the same order that they are produced?
Streaming guarantees linearizable reads and writes within a partition. If you want to make sure that messages with the same value go to the same partition, you should use the same key for those messages.
How can message size affect the throughput of my stream?
A partition provides 1MB/sec data input rate and supports up to 1000 PUT messages per sec. Therefore, if the record size is less than 1KB, the actual data input rate of a partition will be less than 1MB/sec, limited by the maximum number of PUT messages per second. We recommend that you produce messages in batches for the following reasons:
- It reduces the number of put requests sent to the service, which avoids throttling.
- It enables better throughput.
The size of a batch of messages shouldn't exceed 1 MB. If this limit is exceeded, the throttling mechanism is triggered.
How do I handle messages that are bigger than 1 MB?
You can either use chunking or send the message by using Oracle Cloud Infrastructure Object Storage.
- Chunking: You can split large payloads into multiple, smaller chunks that Streaming can accept. The chunks are stored in the service in the same way that ordinary, non-chunked messages are stored. The only difference is that the consumer must keep the chunks and combine them into the message when all the chunks have been collected. The chunks in the partition can be interwoven with ordinary messages.
- Object Storage: A large payload is placed in Object Storage and only the pointer to that data is transferred. The receiver recognizes this type of pointer payload, transparently reads the data from Object Storage, and provides it to the end-user.
What happens if I produce at a rate greater than what is allowed by a partition?
When a producer produces at a rate greater than 1MB per second, the request gets throttled and a 429, Too Many Requests error is sent back to the client indicating that too many requests per second per partition are being received.
Consuming Messages from an Oracle Cloud Infrastructure Stream
How do I read data from a stream?
A consumer is an entity that reads messages from one or more streams. This entity can exist alone or be part of a consumer group. To consume messages, you must create a cursor and then use that cursor to read messages. A cursor points to a location in a stream. This location could be a specific offset or time in a partition or a group's current location. Depending on the location you would like to read from, there are various cursor types available: TRIM_HORIZON, AT_OFFSET, AFTER_OFFSET, AT_TIME,
and LATEST.
For more information, refer to the documentation onConsuming Messages.
What is the maximum number of messages I can consume from a stream at any given point in time?
The getLimit( ) method of the GetMessagesRequest class returns the maximum number of messages. You can specify any value up to 10,000. By default, the service returns as many messages as possible. Consider your average message size to avoid exceeding throughput on the stream. Streaming GetMessages batch sizes are based on the average message size produced to the particular stream.
How do I avoid duplicate messages to my consumers?
Streaming provides "at-least-once" delivery semantics to consumers. We recommend that consumer applications take care of duplicates. For example, when a previously inactive instance of the consumer group rejoins the group and starts consuming messages that have not been committed by the previously assigned instance, there is a chance of processing duplicates.
How do I know if a consumer is falling behind?
A consumer is said to be falling behind if you are producing faster than you can consume. To determine if your consumer is falling behind you can use the timestamp of the message. If the consumer is falling behind, consider spawning a new consumer to take over some of the partitions from the first consumer. If you're falling behind on a single partition, there's no way to recover.
Consider the following options:
- Increase the number of partitions in the stream.
- If the issue is caused by a hotspot, change the message key strategy.
- Reduce message processing time, or handle requests in parallel.
If you want to know how many messages are left to consume in a given partition, use a cursor of type LATEST, get the offset of the next published message, and make the delta with the offset that you are currently consuming. Since we don't have a dense-offset, you can get only a rough estimate. However, if your producer stopped producing, you can't get that information because you'll never get the offset of the next published message.
How do consumer groups work?
Consumers can be configured to consume messages as part of a group. Stream partitions are distributed among members of a group so that messages from any single partition are sent only to a single consumer. Partition assignments are rebalanced as consumers join or leave the group. For more information, refer to the documentation on Consumer Groups.
Why should I use consumer groups?
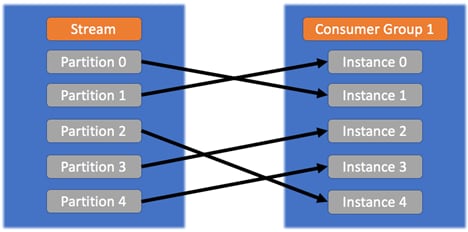
Consumer groups provide the following advantages:
- Each instance in a consumer group receives messages from one or more partitions that are “automatically” assigned to it, and the same messages aren’t received by the other instances (which are assigned to different partitions). In this way, we can scale the number of instances up to the number of the partitions by having one instance reading only one partition. In this case, a new instance of joining the group is in an idle state without being assigned to any partition.
- Having instances as part of different consumer groups means providing a publish-subscribe pattern in which the messages from partitions are sent to all the instances across the different groups.
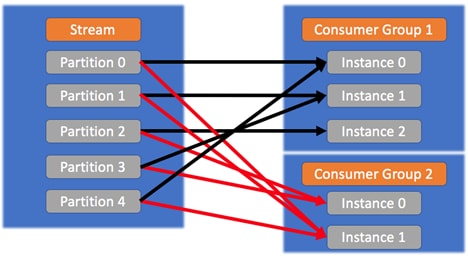
Inside the same consumer group, the rules are as shown in the following image:![]()
Across different groups, the instances receive the same messages, as shown in the following image:
![]()
This is useful when the messages inside a partition are of interest for different applications that will process them in different ways. We want all the interested applications to receive all the same messages from the partition. - When an instance joins a group, if enough partitions are available (that is, the limit of one instance per partition hasn't been reached), a rebalancing starts. The partitions are reassigned to the current instances, plus the new one. In the same way, if an instance leaves a group, the partitions are reassigned to the remaining instances.
- Offset commits are managed automatically.
Is there a limit on how many consumer groups I can have per stream?
There is a limit of 50 consumer groups per stream. Consumer groups are ephemeral. They disappear when they're not used for the retention period of the stream.
What timeouts do I need to be aware of while using consumers and consumer groups?
The following components of the Streaming have timeouts:
- Cursor: As long as you keep consuming messages, there is no need to create a cursor. If the consumption of messages stops for more than 5 minutes, the cursor must be re-created.
- Instance: If an instance stops consuming messages for more than 30 seconds, it's removed from the consumer group and its partition is reassigned to another instance. This is referred to as rebalancing.
What is rebalancing within a consumer group?
Rebalancing is the process in which a group of instances that belong to the same consumer group coordinates to own a mutually exclusive set of partitions that belong to a specific stream. At the end of a successful rebalance operation for a consumer group, every partition within the stream is owned by one or more consumer instances within the group.
What triggers a rebalance activity within a consumer group?
When an instance of a consumer group becomes inactive either because it fails to send a heartbeat for more than 30 seconds or the process is terminated, a rebalance activity is triggered within the consumer group. This is done to handle the partitions previously consumed by the inactive instance and reassign it to an active instance. Similarly, when an instance of a consumer group that was previously inactive joins the group, a rebalance is triggered to assign a partition to start consuming from. The Streaming service provides no guarantee in reassigning the instance to the same partition when it rejoins the group.
How do I recover from a consumer failure?
To recover from a failure, you must store the offset of the last message that you processed for each partition so that you can start consuming from that message if you need to restart your consumer.
Note: Do not store the cursor; they expire after 5 minutes.
We don't provide any guidance for storing the offset of the last message that you processed, so you can use any method you want. For example, you can store the cursor on another stream, or a file on a VM, or an Object Storage bucket. When your consumer restarts, read the offset of the last message that you processed and then create a cursor of type AFTER_OFFSET and specify the offset that you just got.
Kafka Compatability for Oracle Cloud Infrastructure Streaming
How do I integrate my existing Kafka application with Streaming?
The Streaming service provides a Kafka endpoint that can be used by your existing Apache Kafka based applications. A configuration change is all that is required to have a fully managed Kafka experience. Streaming's Kafka compatibility provides an alternative to running your own Kafka cluster. Streaming supports Apache Kafka 1.0 and newer client versions and works with your existing Kafka applications, tools, and frameworks.
What configuration changes need to be done for my existing Kafka application to interact with Streaming?
Customers with existing Kafka applications will be able to migrate to Streaming by simply changing the following parameters of their Kafka configuration file.
security.protocol: SASL_SSL
sasl.mechanism: PLAIN
sasl.jaas.config: org.apache.kafka.common.security.plain.PlainLoginModule required username="{username}" password="{pwd}"; bootstrap.servers: kafka.streaming.{region}.com:9092 # Application settings
topicName: [streamOcid]
How do I use Kafka Connect with Streaming?
To use your Kafka connectors with Streaming, create a Kafka Connect configuration using the Console or the command-line interface (CLI). The Streaming API calls these configurations harnesses. Kafka Connect configurations created in a given compartment work only for streams in the same compartment. You can use multiple Kafka connectors with the same Kafka Connect configuration. In cases that require producing or consuming streams in separate compartments, or where more capacity is required to avoid hitting throttle limits on the Kafka Connect configuration (for example too many connectors, or connectors with too many workers), you can create more Kafka Connector configurations.
What integrations with first party and third party products does streaming provide?
Streaming's Kafka Connect compatibility means that you can take advantage of the many existing first- and third-party connectors to move data from your sources to your targets. Kafka connectors for Oracle products include:
- Oracle Cloud Infrastructure Object Storage (Using Kafka Connect for S3)
- Kafka Connect Amazon S3 source connector, for producers
- Kafka Connect Amazon S3 sink connector, for consumers
- Oracle Integration Cloud
- Oracle AI Database (Using Kafka Connect JDBC)
- Oracle GoldenGate
For a complete list of third-party Kafka source and sink connectors, refer to the official Confluent Kafka hub.
Monitoring Oracle Cloud Infrastructure Streams
Where can I monitor my stream?
Streaming is fully integrated with Oracle Cloud Infrastructure Monitoring. In the Console, select the stream that you want to monitor. Under the Stream Details page, navigate to the Resources section, and click on Produce Monitoring Charts to monitor producer requests. or click on Consume Monitoring Charts to monitor the consumer side metrics. The metrics are available at a stream level and not at a partition level. For a description of the Streaming metrics that are supported, see the documentation.
What statistics are available when monitoring Streaming?
Each metric available in the Console provides the following statistics:
- Rate, Sum, and Mean
- Min, Max, and Count
- P50, P90, P95, P99, and P99.9
These statistics are offered for the following time intervals:
- Auto
- 1 minute
- 5 minutes
- 1 hour
What metrics should I typically set alarms for?
For producers, consider setting alarms on the following metrics:
- Put Messages Latency: An increase in latency means that the messages are taking longer to publish, which could indicate network issues.
- Put Messages Total Throughput:
- An important increase in total throughput could indicate that the 1 MB per second per partition limit will be reached, and that event will trigger the throttling mechanism.
- An important decrease could mean that the client producer is having an issue or is about to stop.
- Put Messages Throttled Records: It's important to get notified when messages are throttled.
- Put Messages Failure: It's important to get notified if put messages start failing so that the Ops team can start investigating the reasons.
For consumers, consider setting the same alarms based on the following metrics:
- Get Messages Latency
- Get Messages Total Throughput
- Get Messages Throttled Requests
- Get Messages Failure
How do I know that my stream is healthy?
A stream is healthy when it is in an Active state. If you can produce to your stream, and if you get a successful response, then the stream is healthy. After data is produced in the stream, it is accessible to consumers for the configured retention period. If GetMessages API calls return elevated levels of internal server errors, the service isn't healthy.
A healthy stream also has healthy metrics:
- Put Messages Latency is low.
- Put Messages Total Throughput is close to 1 MB per second per partition.
- Put Messages Throttled Records is close to 0.
- Put Messages Failure is close to 0.
- Get Messages Latency is low.
- Get Messages Total Throughput is close to 2 MB per second per partition.
- Get Messages Throttled Requests is close to 0.
- Get Messages Failure is close to 0.
When do messages get throttled in a stream?
Throttling indicates that the stream is incapable of handling any new reads or writes. The throttling mechanism is activated when the following thresholds are exceeded:
- GetMessages: Five calls per second or 2 MB per second per partition
- PutMessages: 1 MB per second per partition
- Management and control-plane operations, such as CreateCursor, ListStream, etc.: Five calls per second per stream
Where can I find the list of the API errors?
Details about the API errors are located in the documentation.