O que é um data lakehouse?
Mike Chen | Estrategista de Conteúdo | 1 de março de 2022

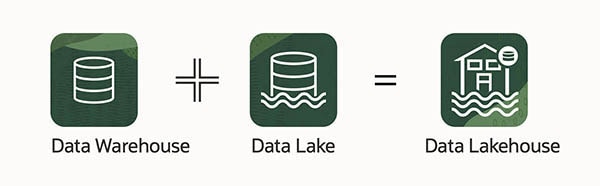
Um data lakehouse pode ser definido como uma plataforma de dados moderna construída a partir de uma combinação de um data lake e um data warehouse. Mais especificamente, um data lakehouse pega o armazenamento flexível de dados não estruturados de um data lake e os recursos e ferramentas de gerenciamento dos data warehouses e os implementa estrategicamente juntos como um sistema maior. Essa integração entre duas ferramentas únicas oferece uma solução com o melhor dos dois mundos. Para detalhar ainda mais um data lakehouse, é importante primeiro entender totalmente a definição dos dois termos originais.
Data Lakehouse vs. Data Lake vs. Data Warehouse
Quando falamos sobre data lakehouse, estamos nos referindo ao uso combinado das atuais plataformas de repositório de dados.
- Data lake (o “lake” em lakehouse): Um data lake é um repositório de armazenamento de baixo custo usado principalmente por cientistas de dados, mas também por analistas de negócios, gerentes de produto e outros tipos de usuários finais. É um conceito de big data. Dados brutos não estruturados de várias fontes organizacionais vão para o "lake", geralmente para preparação antes de serem carregados em um data warehouse e criarem conjuntos de dados.
- Data warehouse (a “house” em lakehouse): Um data warehouse é um tipo diferente de repositório de armazenamento de um data lake em que um data warehouse armazena dados processados e estruturados, com curadoria para uma finalidade específica, e armazenado em um formato determinado. Esses dados geralmente são consultados por usuários corporativos, que usam os dados preparados em ferramentas analíticas para gerar relatórios e projeções. Um data warehouse geralmente inclui recursos de gerenciamento de dados, como limpeza de dados e extração/carregamento/transformação (ETL).
Sendo assim, como um data lakehouse combina essas duas ideias? De forma geral, um data lakehouse remove os silos entre um data lake e um data warehouse. Isso significa que os dados podem ser facilmente movidos entre o armazenamento flexível e de baixo custo de um data lake para um data warehouse e vice-versa, fornecendo acesso fácil às ferramentas de gerenciamento de um data warehouse para implementação de esquema e governança, geralmente alimentados por machine learning e inteligência artificial para limpeza de dados. O resultado cria um repositório de dados que integra a coleção acessível e não estruturada de data lakes e a preparação robusta de um data warehouse. Ao fornecer o espaço para coletar de fontes de dados selecionadas enquanto usa ferramentas e recursos que preparam os dados para uso comercial, um data lakehouse acelera os processos. De certa forma, data lakehouses são data warehouses – que se originaram conceitualmente no início dos anos 1980 – reformulados para nosso mundo moderno orientado por dados.
Recursos de um Data Lakehouse
Depois de entedender o conceito geral de um data lakehouse, vamos nos aprofundar um pouco mais sobre alguns elementos mais específico. Um data lakehouse oferece muitas peças familiares dos conceitos históricos de data lake e data warehouse, mas de uma forma que os funde em algo novo e mais eficaz para o mundo digital de hoje.
Recursos de gerenciamento de dados
Um data warehouse geralmente oferece recursos para gerenciamento de dados, como limpeza de dados, ETL e aplicação de esquemas. Eles são trazidos para um data lakehouse como um meio de preparar dados rapidamente, permitindo que dados de fontes selecionadas trabalhem juntos naturalmente e sejam preparados para análises adicionais e ferramentas de inteligência de negócios (BI).
Formatos de armazenamento abertos
O uso de formatos de armazenamento abertos e padronizados significa que os dados de fontes de dados selecionadas têm uma vantagem significativa na capacidade de trabalhar em conjunto e estar prontos para análises ou relatórios.
Armazenamento Flexível
A capacidade de separar os recursos de computação dos recursos de armazenamento simplifica o redimensionamento do armazenamento sempre que necessário.
Suporte para streaming
Muitas fontes de dados usam streaming em tempo real diretamente de dispositivos. Um data lakehouse é desenvolvido para para melhorar o apoio em tempo real da ingestão, quando comparado a um data warehouse padrão. À medida que o mundo se torna mais integrado aos dispositivos da Internet das Coisas, o suporte em tempo real está ficando mais importante.
Cargas de trabalho diversificadas
Como um data lakehouse integra os recursos de um data warehouse e de um data lake, ele é uma solução ideal para várias cargas de trabalho diferentes. De relatórios de negócios a equipes de ciência de dados e ferramentas de análise, as qualidades inerentes de um data lakehouse podem suportar diferentes cargas de trabalho dentro de uma organização.
Vantagens de um data lakehouse: Uma plataforma moderna de dados
Ao construir um data lakehouse, as organizações podem agilizar seu processo geral de gerenciamento de dados com uma plataforma de dados unificada. Um data lakehouse pode substituir soluções individuais, superando os silos criados por repositórios diferentes. Essa integração cria um processo de ponta a ponta muito mais eficiente sobre fontes de dados curadas. Isso gera vários benefícios.
- Menos administração: Ao usar um data lakehouse, qualquer fonte conectada a ele pode ter seus dados acessíveis e consolidados para uso, em vez de extraí-los de dados brutos e prepará-los para trabalhar em um data warehouse.
- Melhor governança de dados: Os data lakehouses simplificam e melhoram a governança ao consolidar recursos e fontes de dados e são construídos com um esquema aberto padronizado, que permite maior controle sobre segurança, métricas, acesso baseado em função e outros elementos de gestão cruciais.
- Padrões simplificados: Os data warehouses surgiram na década de 1980, quando a conectividade era extremamente limitada, o que significa que os padrões de esquema localizados eram frequentemente criados dentro das organizações, até mesmo em departamentos. Hoje, existem padrões de esquema abertos para muitos tipos de dados, e os data lakehouses aproveitam isso ingerindo várias fontes de dados com um esquema padronizado sobreposto para simplificar os processos.
- Maior rentabilidade: Os data lakehouses são construídos com infraestrutura que separa computação e armazenamento, o que permite fácil adição de armazenamento sem a necessidade de aumentar o poder de computação. Isso cria um escalonamento econômico com o uso simples de armazenamento de dados de baixo custo.
Embora algumas organizações construam um data lakehouse, outras adquirirão um serviço de nuvem de data lakehouse.
Casos de sucesso dos clientes: Data Lakehouse

A Experian melhorou o desempenho em 40% e reduziu os custos em 60% quando transferiu cargas de trabalho de dados críticos de outras nuvens para um data lakehouse na OCI, acelerando o processamento de dados e a inovação de produtos enquanto expandia as oportunidades de crédito no mundo todo.
Generali Group é uma empresa italiana de seguros com uma das maiores bases de clientes do mundo. A Generali tinha diversas fontes de dados, tanto do Oracle Cloud HCM, quanto de outras fontes locais e regionais. O processo de decisão de RH e o envolvimento dos funcionários estavam enfrentando obstáculos, e a empresa buscou uma solução para melhorar a eficiência. A integração do Oracle Autonomous Data Warehouse com as fontes de dados da Generali removeu os silos e criou um único recurso para todas as análises de RH. Isso melhorou a eficiência e aumentou a produtividade entre a equipe de RH, permitindo que eles se concentrassem em atividades de valor agregado, em vez da rotatividade da geração de relatórios.

Uma das principais operadoras de transporte por aplicativo do mundo, a Lyft estava lidando com 30 sistemas financeiros isolados diferentes. Essa separação prejudicava o crescimento da empresa, além de desacelerar os processos. Ao integrar o Oracle Cloud ERP e o Oracle Cloud EPM com o Oracle Autonomous Data Warehouse, a Lyft conseguiu consolidar finanças, operações e análises em um único sistema. Isso reduziu o tempo de fechamento dos livros em 50%, com a possibilidade de simplificar ainda mais os processos. Além de reduzir os custos com o moderamento do tempo ocioso.

A Agroscout é uma desenvolvedora de software que ajuda fazendeiros a maximizarem a saúde e a segurança das colheitas. Para aumentar a produção alimentícia, a Agroscout usou uma rede de drones para procurar insetos e doenças pela lavoura. A empresa precisava de uma maneira eficiente de consolidar os dados e processá-los para identificar sinais de perigo nas culturas. Com a ajuda do Oracle Object Storage Data Lake, os drones conseguiram carregar as imagens da lavoura corretamente. Modelos de machine learning foram desenvolvidos com o OCI Data Science para conseguir processar as imagens. O resultado foi um processo melhorado, que possibilitou respostas rápidas para aumentar a produção.
Descubra Por que o OCI foi o Melhor Lugar para Desenvolver um Lakehouse
A cada dia que passa, mais e mais fontes de dados enviam volumes gigantes de dados em todo mundo. Para qualquer empresa, essa combinação de dados estruturados e desestruturados é um desafio. Os data lakehouses unem, correlacionam e analisam essas saídas em um único sistema gerenciável.