Prévention de la fraude et anti-blanchiment d'argent

Limiter les risques tout en offrant un service client fluide
La fraude financière constitue un problème majeur pour le secteur des services financiers. Non seulement elle se présente sous de nombreuses formes différentes, mais elle est souvent difficile à détecter en raison de la complexité des relations entre les entités et les modèles cachés. Une fois détectées, les institutions financières doivent informer les clients de toute activité frauduleuse en temps réel et prendre des mesures immédiates pour l'arrêter, par exemple en bloquant la carte de crédit du client.
Le secteur des services financiers est également réglementé et doit rendre compte des activités de lutte contre le blanchiment d'argent (AML) et faire preuve de diligence complète envers ses clients à l'aide des processus de connaissance clientèle (ou KYC). Cela nécessite souvent d'analyser les données sur les produits, les marchés et les zones géographiques pour identifier les relations et les modèles pour l'AML.
En théorie, le blanchiment d'argent est simple : les fraudeurs font circuler l'argent sale, le mélangent avec des fonds légitimes, puis le transforment en actifs durs. En réalité, c'est beaucoup plus compliqué. Ils doivent réaliser de nombreux transferts valides et complexes entre des comptes créés à l'aide d'identités synthétiques (souvent volées) et utilisant souvent des informations similaires, telles que des e-mails et des adresses de rue. En résumé, une grande quantité de données doit être analysée. C'est pourquoi une plateforme de données unifiée qui prend en charge les techniques d'analyse avancées, telles que l'analyse de graphes, est essentielle pour les programmes d'AML.
Protéger les clients et les établissements grâce au machine learning
Le secteur des services financiers continue d'être fortement surveillé et réglementé. Rares sont les domaines faire l'objet d'autant de réglementations que la lutte contre le blanchiment de capitaux et le contre-terroriste. La fraude financière et ses vastes réseaux criminels représentent un problème complexe en recrudescence qui exige des solutions qui fournissent des informations à l'échelle de l'entreprise et du monde entier.
L'architecture suivante démontre comment les composants et fonctionnalités Oracle, y compris l'analyse avancée et le machine learning, peuvent être combinés pour créer une plateforme de données qui couvre l'ensemble du cycle de vie des analyses de données et fournit les informations dont les équipes de lutte contre le blanchiment d'argent ont besoin pour identifier les modèles de comportement anormaux pouvant indiquer une activité frauduleuse.
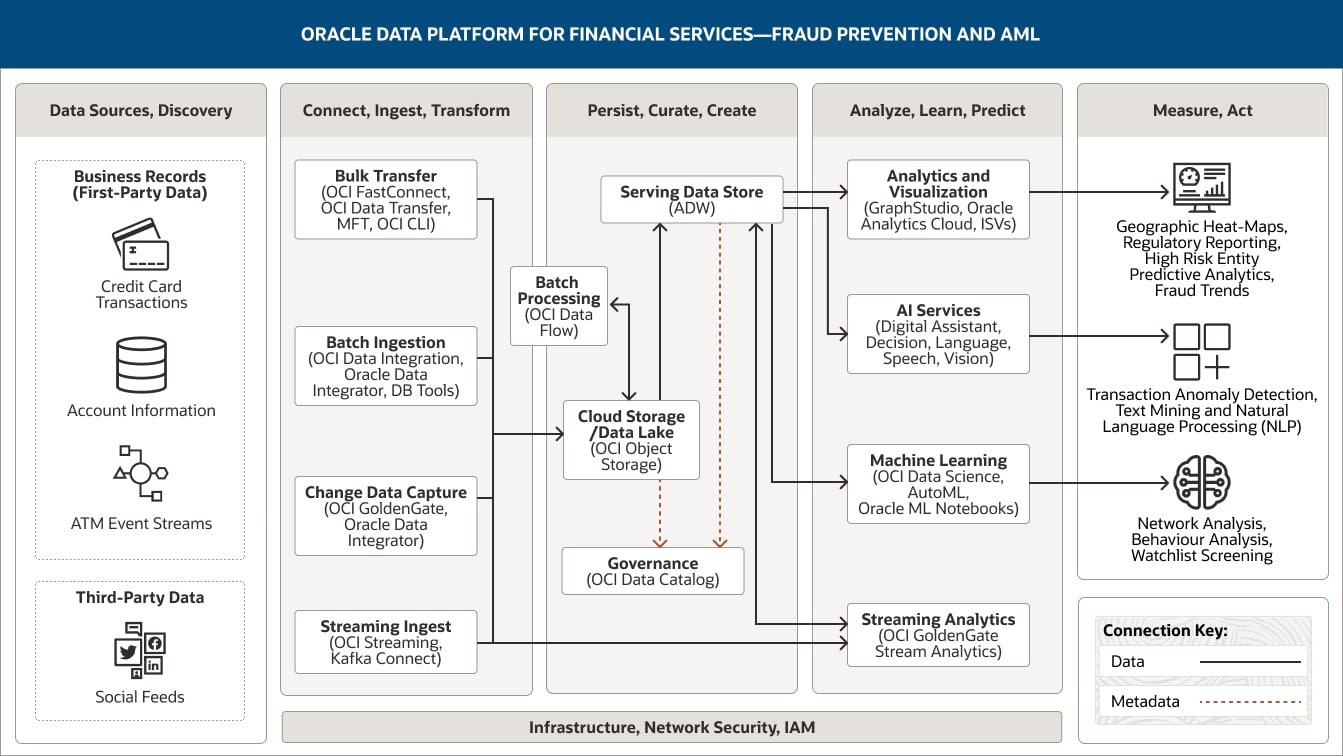
Cette image montre comment la plateforme de données Oracle pour les services financiers peut être utilisée pour prendre en charge la prévention des fraudes et les activités anti-blanchiment. La plateforme comprend les cinq piliers suivants :
- Sources de données et repérage
- Connexion, ingestion et transformation
- Sauvegarde, tri et création
- Analyses, apprentissage et prévision
- Mesurer. Agir
Le pilier « Sources de données et repérage » inclut deux catégories de données.
Les données internes à votre entreprise comprennent les transactions par carte de crédit, les informations de compte et les flux d'événements des distributeurs automatiques de billets.
Les données tierces incluent les flux sociaux.
Le pilier « Connexion, ingestion et transformation » comprend quatre fonctionnalités.
Le transfert en masse utilise OCI FastConnect, OCI Data Transfer, MFT et l'interface de ligne de commande OCI.
L'assimilation par lots utilise OCI Data Integration, Oracle Data Integrator et les outils de base de données.
La capture des données de modification utilise OCI GoldenGate et Oracle Data Integrator.
L'ingestion de flux utilise OCI Streaming et Kafka Connect.
Les quatre fonctionnalités se connectent de manière unidirectionnelle à la capacité de stockage/lac de données cloud dans le pilier « Sauvegarde, tri et création ».
De plus, l'ingestion de flux est connectée au traitement de flux au sein du pilier « Analyses, apprentissage et prévision ».
Le pilier « Sauvegarde, tri et création » comprend quatre fonctionnalités.
Le dépôt de données de service utilise Autonomous Data Warehouse et Exadata Cloud Service.
Le stockage/lacs de données cloud utilise OCI Object Storage.
Le traitement par lots utilise OCI Data Flow.
La gouvernance utilise OCI Data Catalog.
Ces fonctionnalités sont connectées au sein du pilier. Le stockage cloud/lac de données est connecté de manière unidirectionnelle au dépôt de données de service. Il est également connecté de manière bidirectionnelle au traitement par lots.
Une fonctionnalité se connecte au pilier « Analyses, apprentissage et prévision » : le dépôt de données de service se connecte de manière unidirectionnelle aux fonctions d'analyse et de visualisation, d'IA et de machine learning, et de manière bidirectionnelle à la fonction d'analyse en continu.
Le pilier « Analyses, apprentissage et prévision » comprend quatre fonctionnalités.
L'analyse et la visualisation utilisent Oracle Analytics Cloud, GraphStudio et des éditeurs de logiciels indépendants.
Les services d'IA utilisent OCI Anomaly Detection, OCI Forecasting, OCI Language
Le machine learning utilise OCI Data Science et Oracle Machine Learning Notebooks.
Les analyses de flux utilisent OCI GoldenGate Stream Analytics.
Le pilier « Mesures et réactions » comprend trois consommateurs : les tableaux de bord et de rapports, les applications et les modèles de machine learning.
Les personnes et les partenaires regroupent les cartes de chaleur géographiques, la création de rapports réglementaire, les analyses prédictives d'entité à risque élevé et les tendances de la fraude.
Les applications concernent la détection d'anomalies de transaction, l'exploration de texte et le traitement du langage naturel.
Les modèles de machine learning comprennent l'analyse du réseau, l'analyse du comportement et le filtrage de la liste de contrôle.
Les trois piliers centraux (« Ingestion et transformation », « Sauvegarde, tri et création », et « Analyses, apprentissage et prévision ») sont pris en charge par l'infrastructure, le réseau, la sécurité et IAM.
Il existe trois principaux moyens d'injecter des données dans une architecture pour permettre aux entreprises de services financiers d'identifier les activités potentiellement frauduleuses.
- Pour commencer, nous avons besoin de données provenant de systèmes transactionnels et d'applications bancaires de base. Ces données peuvent être enrichies avec des données client provenant de sources tierces, telles que des données non structurées provenant des réseaux sociaux. Les extractions fréquentes en temps réel ou quasiment en temps réel nécessitant une capture de données de modification sont courantes, et les données sont régulièrement ingérées à partir de systèmes de gestion des transactions, des risques et des clients à l'aide d'Oracle Cloud Infrastructure (OCI) GoldenGate. OCI GoldenGate est également un composant essentiel de l'évolution des architectures de maillage de données, où les « produits de données » sont gérés via des registres de données d'entreprise et des flux de données polyglottes qui effectuent des processus de transformation et de chargement continus (plutôt que les processus d'inclusion et d'extraction, de transformation et de chargement par lots utilisés dans les architectures monolithiques).
- Nous pouvons désormais utiliser l'ingestion de flux de données pour intégrer des données à partir de capteurs IoT, de pipelines Web, de fichiers journaux, d'appareils de point de vente, de distributeurs automatiques de billets, de réseaux sociaux et d'autres sources de données en temps réel via OCI Streaming/Kafka. Ces données transmises en continu (événements) sont ingérées et certaines transformations/agrégations de base sont effectuées avant d'être stockées dans le stockage cloud. Parallèlement à l'ingestion, nous pouvons filtrer, agréger, corréler et analyser de grands volumes de données provenant de plusieurs sources en temps réel à l'aide des analyses de diffusion en continu. Ces activités aident non seulement les institutions financières à détecter les menaces et les risques commerciaux (par exemple, les transactions suspectes d'un guichet automatique (ATM), comme les transactions répétées multiples), mais fournissent également des informations sur leur efficacité globale en matière de prévention des fraudes. Les événements corrélatifs et les modèles détectés peuvent être renvoyés (manuellement) pour un examen des données brutes par des experts en science des données. En outre, des événements peuvent être générés pour déclencher des actions, telles que la notification aux clients d'éventuelles fraudes par e-mail ou SMS ou le blocage de cartes de débit compromises. Oracle GoldenGate Stream Analytics est une technologie en mémoire qui effectue des calculs analytiques en temps réel sur les flux de données.
- Alors que les besoins en temps réel évoluent, l'extraction la plus courante des systèmes bancaires de base, des clients et des systèmes financiers est une assimilation par lots à l'aide d'un processus d'extraction, de transformation et de chargement. L'ingestion par lots permet d'importer des données à partir de systèmes qui ne prennent pas en charge l'assimilation en continu (par exemple, d'anciens systèmes mainframe). Pour les processus de lutte contre le blanchiment d'argent et de connaissance de la clientèle, les données proviennent de différents systèmes opérationnels, tels que les systèmes de traitement des transactions de compte courant et de compte de crédit, et les flux de données tiers fournissant des informations sur le client. Les données proviennent de différents produits et zones géographiques. Les ingestions par lots peuvent être fréquentes, par exemple toutes les 10 ou 15 minutes, mais elles sont toujours moins fines, car ce sont des groupes de transactions qui sont extraits et traités et non des transactions individuelles. OCI propose différents services pour gérer l'assimilation par lots, tels que le service OCI Data Integration natif ou Oracle Data Integrator exécuté sur une instance OCI Compute. Selon les volumes et les types de données, les données peuvent être chargées dans le stockage d'objets ou directement dans une base de données relationnelle structurée pour le stockage persistant.
La persistance et le traitement des données reposent sur trois (voire quatre) composants.
- Les données brutes incluses sont stockées dans un stockage cloud à des fins algorithmiques. Nous utilisons OCI Object Storage en tant que niveau de persistance des données principal. Spark dans OCI Data Flow est le moteur de traitement par lots principal pour les données telles que les données transactionnelles, d'emplacement, d'application et de géo-mappage. Le traitement par lots implique plusieurs activités, notamment le traitement du bruit de base, la gestion des données manquantes et le filtrage en fonction des jeux de données sortants définis. Les résultats sont réécrits dans différentes couches de stockage d'objets ou dans un référentiel relationnel persistant en fonction du traitement nécessaire et des types de données utilisés.
- Ces ensembles de données traitées sont renvoyés vers le stockage cloud pour la persistance, le tri, l'analyse et finalement le chargement sous forme optimisée vers le dépôt de données de service, fourni ici par Oracle Autonomous Database. Les données sont désormais conservées sous forme relationnelle optimisée pour les performances de traitement et de requête. Selon les préférences d'architecture, vous pouvez également procéder de la même manière avec Oracle Big Data Service en tant que cluster Hadoop géré. Dans ce cas d'utilisation, toutes les données nécessaires à l'entraînement des modèles de machine learning sont accessibles sous forme brute à partir du stockage d'objets. Pour entraîner les modèles, les modèles historiques sont combinés à des enregistrements de transaction afin de détecter et d'étiqueter les risques potentiels. L'association de ces ensembles de données à d'autres, comme les données d'appareil et les données géospatiales, nous permet d'appliquer des techniques de science des données pour affiner les modèles existants et en développer de nouveaux pour mieux prévoir les fraudes potentielles. Ce type de persistance peut également être utilisé pour stocker les données des schémas faisant partie des dépôts de données accessibles via des tables externes et des partitions hybrides.
La capacité d'analyse, de prévision et d'action repose sur trois approches technologiques.
- Les services d'analyse et de visualisation, tels qu'Oracle Analytics Cloud, fournissent des analyses reposant sur les données organisées du dépôt de données de service. Il s'agit d'analyses descriptives (décrit les tendances actuelles de détection des fraudes avec des histogrammes et des graphiques), d'analyses prédictives, telles que l'analyse des séries chronologiques (prédit des modèles, détecte les tendances et détermine la probabilité de résultats incertains) et d'analyses prescriptives (propose des actions appropriées menant à une prise de décision optimale). Ces analyses peuvent être utilisées pour répondre à des questions telles que : Comment la fraude détectée sur cette période diverge-t-elle des périodes précédentes ?
- Outre les analyses avancées, des modèles de machine learning sont développés, entraînés et déployés. Ces modèles entraînés peuvent être exécutés avec des données transactionnelles actuelles et historiques pour détecter le blanchiment d'argent en mettant en correspondance des modèles de transaction et des comportements. Les résultats peuvent être sauvegardés dans la couche de service et être rapportés à l'aide d'outils d'analyse tels qu'Oracle Analytics Cloud. Pour optimiser l'entraînement des modèles, le modèle et les données peuvent également être intégrés aux systèmes de machine learning, tels qu'OCI Data Science, afin d'entraîner davantage les modèles pour une détection plus efficace des modèles de lutte contre le blanchiment d'argent. Ces modèles sont accessibles via des API, déployés dans le dépôt de données de service ou intégrés dans le pipeline d'analyses de diffusion en continu OCI GoldenGate.
- De plus, nous pouvons utiliser les fonctionnalités avancées des services d'intelligence artificielle natifs du cloud.
- OCI Anomaly Detection est un service d'intelligence artificielle qui facilite la création de modèles de détection d'anomalies spécifiques à l'entreprise qui signalent les incidents critiques, accélérant ainsi la détection et la résolution. Dans ce cas d'utilisation, nous déployons ces modèles pour détecter la fraude au cours du cycle de vie d'une transaction, pendant les audits, dans des contextes spécifiques, par exemple, en fonction du fournisseur, du commerçant ou du type de transaction, et dans de nombreux autres scénarios. OCI Anomaly Detection peut identifier tous ces types de fraude en utilisant des données historiques et en créant un modèle de détection d'anomalies approprié. Par exemple, si le jeu de données inclut le type de transaction avec le montant, le lieu (latitude et longitude), le nom du fournisseur et d'autres détails, OCI Anomaly Detection peut déterminer si la fraude est liée au montant de la transaction, au compte de transaction, au lieu de la transaction ou au fournisseur qui a déposé la transaction.
- OCI Forecasting peut être utilisé pour prévoir des indicateurs de transaction, tels que le nombre de transactions, les montants de transaction, etc., pour le jour, la semaine ou les mois suivants, en fonction des indicateurs actuels influençant les conditions du marché. Ces prévisions peuvent être utilisées pour la planification et pour fixer une prévision de référence à utiliser pour la protection contre le blanchiment d'argent et d'autres fraudes.
- OCI Language et OCI Vision peuvent ingérer des documents et du texte qui peuvent aider à enrichir les données pour la détection des fraudes et les activités AML.
- La gouvernance des données est un autre composant essentiel. Il est proposé par OCI Data Catalog, un service gratuit qui fournit la gouvernance des données et la gestion des métadonnées (pour les métadonnées techniques et commerciales) pour toutes les sources de données de l'écosystème de data lakehouse. OCI Data Catalog est également un composant essentiel pour les requêtes à partir d'Oracle Autonomous Data Warehouse vers OCI Object Storage, car il permet de localiser rapidement des données quelle que soit sa méthode de stockage. Les utilisateurs finaux, développeurs et experts en science des données peuvent ainsi utiliser un langage d'accès commun (SQL) dans tous les dépôts de données persistants de l'architecture.
- Enfin, nos modèles et données actuellement sélectionnés, testés, de haute qualité et régis peuvent être exposés en tant que produit de données (API) au sein d'une architecture de maillage de données à des fins de distribution dans toute l'organisation de services financiers.
Améliorer la prévention de la fraude et les activités de lutte contre le blanchiment d'argent avec la bonne plateforme de données
Oracle Data Platform peut aider votre entreprise à détecter plus efficacement le blanchiment d'argent, à coopérer sur les enquêtes sur la criminalité financière et à simplifier les processus de création de rapports afin de réduire les coûts de la conformité.
Ressources associées
-
Cas d’utilisation
Prévention de la fraude et anti-blanchiment d'argent
Découvrez comment Oracle Data Platform aide les entreprises des services financiers à réduire les risques et à améliorer la détection et la conformité des fraudes dans ce cas d'utilisation.
-
Cas d’utilisation
Calcul des risques et création de rapport réglementaire
Découvrez comment Oracle Data Platform pour les services financiers peut vous aider à réduire les risques et à améliorer la conformité réglementaire dans ce cas d'utilisation.
-
Cas d’utilisation
Améliorer les opérations et les performances des services financiers
Découvrez comment gérer plus efficacement les opérations des services financiers à l'aide d'une plateforme de données qui améliore les performances grâce au machine learning.
Lancez-vous
Testez plus de 20 services cloud Always Free grâce à une période d'essai de 30 jours pour encore plus de services
Oracle propose une offre gratuite sans limite de temps sur plus de 20 services tels que Oracle Autonomous AI Database, Arm Compute et Storage, ainsi que 300 dollars américains de crédits gratuits pour essayer d'autres services cloud. Obtenez les détails et créez votre compte gratuit dès aujourd’hui.
-
Que comprend Oracle Cloud Free Tier ?
- Deux instances d'Autonomous AI Database de 20 Go chacune
- AMD et Arm Compute VM
- 200 Go de stockage total par blocs
- 10 Go de stockage d'objets
- 10 To de transfert de données sortantes par mois
- Plus de 10 services Always Free
- 300 USD de crédits gratuits pendant 30 heures pour plus de possibilités
Suivez le guide
Découvrez un large éventail de services OCI via des tutoriels et des ateliers pratiques. Que vous soyez développeur, administrateur ou analyste, nous pouvons vous aider à comprendre comment fonctionne OCI. De nombreux ateliers sont disponibles pour Oracle Cloud Free Tier ou dans un environnement d'ateliers gratuits fournis par Oracle.
-
Introduction aux services fondamentaux d'OCI
Les ateliers de cette session présentent les services principaux d'Oracle Cloud Infrastructure (OCI), y compris les réseaux cloud virtuels (VCN) ainsi que les services de calcul et de stockage.
Commencer l'atelier sur les services principaux d'OCI -
Guide de démarrage rapide de Autonomous AI Database
Au cours de cet atelier, vous découvrirez les étapes à suivre pour commencer à utiliser Oracle Autonomous AI Database.
Commencez dès maintenant le laboratoire de démarrage rapide de Autonomous AI Database. -
Créez une application à partir d'une feuille de calcul
Cet atelier vous explique pas à pas comment télécharger une feuille de calcul dans un tableau d'Oracle Database et comment créer ensuite une application à partir de ce nouveau tableau.
Commencer cet atelier
Découvrez plus de 150 modèles de bonnes pratiques
Découvrez comment nos architectes et d’autres clients déploient une large gamme de workloads, des applications d’entreprise au HPC, des microservices aux lacs de données. Comprenez les bonnes pratiques, écoutez d’autres architectes clients de notre série « Développer et Déployer » et déployez même de nombreux workloads avec notre fonctionnalité de déploiement en un clic ou faites-le vous-même à partir de notre dépôt GitHub.
Architectures populaires
- Apache Tomcat avec MySQL Database Service
- Oracle Weblogic sur Kubernetes avec Jenkins
- Environnements de machine learning (ML) et d'IA
- Tomcat sur Arm avec Oracle Autonomous AI Database
- Analyse des journaux avec la pile ELK
- HPC avec OpenFOAM
Découvrez combien vous pouvez économiser sur OCI
La tarification d'Oracle Cloud est simple, avec des tarifs faibles homogènes dans le monde entier et prenant en charge un large éventail de cas spécifiques. Pour estimer votre tarif réduit, consultez l’estimateur de coûts et configurez les services en fonction de vos besoins.
Ressentez la différence :
- 1/4 des coûts de bande passante sortante
- Rapport prix/performances de calcul 3 fois plus élevé
- Tarifs faibles et identiques dans chaque région
- Tarifs faibles sans engagements à long terme
Contactez l’équipe commerciale
Vous souhaitez en savoir plus sur Oracle Cloud Infrastructure ? Laissez l’un de nos experts vous aider.
-
Il peut répondre à des questions telles que :