Siatka danych w przedsiębiorstwie
Rozwiązania, przypadki użycia i analizy przypadków
Czym jest siatka danych?
Siatka danych to gorący temat w dziedzinie oprogramowania korporacyjnego. Stanowi nowe podejście do myślenia o danych w oparciu o rozproszoną architekturę do zarządzania danymi. Polega na uczynieniu danych bardziej dostępnymi dla użytkowników biznesowych poprzez bezpośrednie połączenie właścicieli, producentów i konsumentów danych. Siatka danych ma na celu poprawę wyników biznesowych rozwiązań ukierunkowanych na dane, a także przyspieszenie wdrażania nowoczesnych architektur danych.
Z biznesowego punktu widzenia siatka danych wprowadza nowe pomysły dotyczące „myślenia o produktach danych”. Innymi słowy jest to traktowanie danych jako produktu spełniającego „zadanie do wykonania”, na przykład w celu usprawnienia procesu podejmowania decyzji, pomocy w wykryciu oszustw lub ostrzegania przedsiębiorstwa o zmianach w statusie łańcucha dostaw. Aby tworzyć produkty o wysokiej wartości, firmy powinny skupić się na zmianach w kulturze i sposobie myślenia, angażując się w bardziej wielofunkcyjne podejście do modelowania domen biznesowych.
Od strony technologicznej, podejście Oracle do siatki danych obejmuje trzy ważne nowe obszary tematyczne w zakresie architektury opartej na danych:
- Narzędzia dostarczające produkty danych pod postacią kolekcji danych, zdarzeń danych i analiz danych
- Rozproszone, zdecentralizowane architektury danych, które pomagają organizacjom odchodzącym od monolitycznych architektur w przetwarzaniu w wielu chmurach i chmurach hybrydowych lub organizacjom, które muszą działać w globalnie zdecentralizowany sposób
- Dane w ruchu dla organizacji, które nie mogą polegać wyłącznie na scentralizowanych, statycznych danych wsadowych, i które zamiast tego przechodzą na oparte na zdarzeniach księgi danych i potoki strumieniowe dla zdarzeń danych w czasie rzeczywistym, zapewniające bardziej aktualne analizy
Inne ważne kwestie, takie jak narzędzia samoobsługowe dla użytkowników nietechnicznych i silne modele zarządzania danymi sfederowanymi, są równie ważne dla architektury siatki danych, jak w przypadku innych, bardziej scentralizowanych i klasycznych metod zarządzania danymi.
Nowa koncepcja danych

Strategia oparta na siatce danych to zmiana podejścia na postrzeganie danych jako produktu. Siatka danych wprowadza zmiany organizacyjne i procesowe, których przedsiębiorstwa będą potrzebowały do zarządzania danymi jako swoimi środkami trwałymi. Perspektywa Oracle dotycząca architektury siatki danych wymaga odpowiedniego dostosowania pomiędzy organizacyjnymi i analitycznymi domenami danych.
Siatka danych ma na celu bezpośrednie powiązanie producentów danych z użytkownikami biznesowymi oraz, w jak największym stopniu, usunięcie pośredniczenia działu IT z projektów oraz procesów przyjmujących, przygotowujących i przekształcających zasoby danych.
Zaangażowanie Oracle w technologię siatki danych skupia się na udostępnieniu naszym klientom platformy spełniającej nowoczesne wymagania technologiczne. Obejmuje to narzędzia dla produktów danych, zdecentralizowane architektury sterowane zdarzeniami oraz wzorce strumieni danych w ruchu. W przypadku modelowania domen produktów danych i innych problemów socjotechicznych, Oracle wykorzystuje wyniki prac prowadzonych przez lidera w dziedzinie technologii siatki danych, Zhamaka Dehghaniego.
Zalety siatki danych
Inwestycja w siatkę danych może przynieść imponujące korzyści, takie jak:
- Całkowita przejrzystość wartości danych dzięki zastosowaniu najlepszych praktyk dotyczących produktów danych.
- Dostępność danych operacyjnych na poziomie powyżej 99,999% przy użyciu mikrousługowych potoków danych do konsolidacji i migracji danych.
- 10 razy szybsze cykle innowacji, odchodzące od ręcznego, zorientowanego na zadania procesu ETL na rzecz ciągłej transformacji i ładowania (CTL).
- Zmniejszenie o ponad 70% kosztów inżynierii danych, wzrost w zakresie CI/CD, niewymagające programowania i samoobsługowe narzędzia do przetwarzania danych oraz zwinne programowanie.
Siatka danych stanowi sposób myślenia i nie tylko
Siatka danych to koncept, który jest nadal na wczesnym etapie rozwoju na rynku. Można więc zobaczyć różnorodne treści marketingowe o rozwiązaniach mających być „siatką danych”. Jednak często nie są one zgodne z centralną filozofią lub zasadami siatki danych.
Prawdziwa siatka danych to sposób myślenia, model organizacyjny i podejście do architektury danych przedsiębiorstwa z wykorzystaniem narzędzi pomocniczych. Rozwiązanie oparte na siatce danych powinno uwzględniać myślenie o danych jako produkcie, zdecentralizowaną architekturę danych, własność danych w oparciu o domenę, rozproszony dostęp do danych w ruchu, samoobsługowy dostęp i silne zarządzanie danymi.
Siatka danych nie jest żadnym z poniższych:
- Produktem dostawcy: nie istnieje pojedynczy produkt siatki danych.
- Jeziorem danych lub hurtownią danych: dane uzupełniają się i mogą być częścią większej siatki danych, która obejmuje wiele jezior, stawów i systemów zapisu danych.
- Katalogiem lub wykresem: siatka danych wymaga fizycznej implementacji.
- Jednorazowym projektem konsultingowym: siatka danych to trwały proces, a nie pojedynczy projekt.
- Produktem umożliwiającym samodzielną analizę: klasyczne, samoobsługowe analizy, przygotowywanie danych i porządkowanie danych mogą być częścią siatki danych, a także innych architektur danych.
- Strukturą danych: mimo że są one powiązane koncepcyjnie, koncepcja struktury danych obejmuje szerszy zakres różnych stylów integracji i zarządzania danymi. Siatka danych jest bardziej powiązana z decentralizacją i projektowaniem opartym na domenach.
Dlaczego warto zastosować siatkę danych?
Smutna prawda polega na tym, że dotychczasowe monolityczne architektury danych są kłopotliwe, drogie i nieelastyczne. Na przestrzeni lat stało się jasne, że większość czasu i kosztów związanych z cyfrową platformą biznesową, począwszy od aplikacji po analitykę, pochłaniają wysiłki związane z integracją. W rezultacie większość inicjatyw opartych na platformach kończy się porażką.
Chociaż siatka danych nie jest magicznym panaceum dla scentralizowanych, monolitycznych architektur danych, to jej zasady, praktyki i technologie są zaprojektowane w celu rozwiązania najbardziej palących problemów i wyzwań związanych z modernizacją inicjatyw biznesowych opartych na danych.
Oto niektóre trendy technologiczne, które doprowadziły do powstania rozwiązania w postaci siatki danych:
- 70-80% transformacji cyfrowych kończy się porażką.
- Koszty operacyjnych awarii związanych z danymi rosną.
- Blokada w platformach chmurowych jest faktem i może stać się bardziej kosztowna.
- Jeziora danych rzadko odnoszą sukces i skupiają się tylko na analizie.
- Wzrost popularności danych rozproszonych wymusza stosowanie bardziej efektywnej, wydajnej i ekonomicznej architektury.
- Silosy w organizacjach pogarszają problemy z udostępnianiem danych.
- Dane są głównym narzędziem w zdobywaniu przewagi nad konkurencją. Zarządzanie nimi ma kluczowe znaczenie.
Więcej informacji na temat znaczenia siatki danych znajdziesz w oryginalnym dokumencie Zhamaka Dehghaniego z 2019 roku: Jak przenieść się poza monolityczne jezioro danych do rozproszonej siatki danych.
Definiowanie siatki danych
Zdecentralizowana strategia siatki danych ma na celu traktowanie danych jako produktu poprzez tworzenie samoobsługowej infrastruktury danych w celu zwiększenia ich dostępności dla użytkowników biznesowych.
Skupienie się na wynikach
Myślenie o produktach danych- Diametralna zmiana punktu widzenia konsumenta danych
- Właściciele domen danych są odpowiedzialni za wskaźniki KPI i umowy SLA produktów danych
- Ta sama domena danych i semantyka technologii siatki dla wszystkich
- Koniec z „przerzucaniem danych ponad murem”
- Przechwytywanie zdarzeń związanych z danymi w czasie rzeczywistym bezpośrednio z systemów danych i umożliwienie samoobsługowego dostarczania danych tam, gdzie jest to potrzebne
- Podstawowa możliwość tworzenia produktów zdecentralizowanych danych i danych dopasowanych do źródła
Odrzucenie monolitycznej architektury IT
Zdecentralizowana architektura- Architektura stworzona z myślą o zdecentralizowanych danych, usługach i chmurze
- Stworzone do obsługi wszystkich typów zdarzeń, formatów i złożoności
- Domyślne przetwarzanie strumieni, przetwarzanie partii wg wyjątku
- Stworzona z myślą o wspomaganiu programistów i bezpośredniego łączenia konsumentów danych z ich producentami
- Wbudowane zabezpieczenia, weryfikacja, identyfikowalność i przejrzystość
Funkcje Oracle obsługujące siatkę danych
Do zastosowania teorii w praktyce konieczne jest wdrożenie rozwiązań klasy korporacyjnej dla danych o krytycznym znaczeniu. Oracle oferuje szereg zaufanych rozwiązań, które wzmocnią korporacyjną siatkę danych.
Tworzenie i udostępnianie produktów danych
- Wielomodelowe gromadzenie danych przy użyciu konwergentnej bazy danych Oracle, zapewnianie możliwości zmiany wariantu produktów danych w formatach wymaganych przez konsumentów danych
- Samoobsługowe produkty danych w postaci aplikacji lub interfejsów API, wykorzystujące usługi Oracle APEX Application Development i Oracle REST Data Services do uzyskiwania łatwego dostępu i udostępniania wszystkich danych
- Pojedynczy punkt dostępu dla zapytań SQL lub wirtualizacji danych za pomocą Oracle Cloud SQL i Big Data SQL
- Produkty danych przeznaczone do uczenia maszynowego z wykorzystaniem platformy Oracle do analizy danych, usługi Oracle Cloud Infrastructure (OCI) Data Catalog oraz chmurowej platformy danych Oracle do obsługi repozytoriów danych
- Produkty danych dopasowane do źródła jako zdarzenia w czasie rzeczywistym, alarmy o danych i usługi zdarzeń opartych o dane wstępne dzięki usłudze Oracle Stream Analytics
- Dostosowane do klientów, samoobsługowe produkty danych w wszechstronnym rozwiązaniu Oracle Analytics Cloud
Korzystanie z zdecentralizowanej architektury danych
- Elastyczne CI/CD w stylu „siatki usług” dla kontenerów danych korzystających z wtyczkowych baz danych Oracle za pomocą rozwiązań Kubernetes, Docker lub natywnie w chmurze z usługą Autonomous Database
- Synchronizacja danych w wielu regionach, wielu chmurach i chmurach hybrydowych z mikrousługami Oracle GoldenGate i Veridata, co zapewnia zaufaną strukturę transakcji typu aktywny-aktywny
- Wgląd w większość zdarzeń związanych z aplikacjami, procesami biznesowymi i technologią Internet of Things (IoT) za pomocą usług Oracle Integration Cloud i Oracle Internet of Things Cloud
- Wykorzystanie kolekcji zdarzeń z Oracle GoldenGate lub Oracle Transaction Manager for Microservices do uzupełniania zdarzeń z mikrousług lub ich przesyłania w czasie rzeczywistym do systemu Kafka i jezior danych
- Wprowadzenie zdecentralizowanych wzorców projektowych opartych o domeny do własnej siatki usług za pomocą usług Oracle Verrazzano, Helidon i VM Graal
3 kluczowe atrybuty siatki danych
Siatka danych jest czymś więcej niż tylko nowym terminem technicznym. To nowy zbiór zasad, praktyk i możliwości technologicznych, który sprawia, że dane są bardziej dostępne i łatwiejsze do odkrycia. Koncepcja siatki danych odróżnia się od poprzednich podejść do integracji i architektur danych. Zachęca do odejścia od dotychczasowych gigantycznych, monolitycznych architektur danych korporacyjnych na rzecz nowoczesnej, rozproszonej i zdecentralizowanej architektury opartej na danych. Koncepcja siatki danych opiera się na następujących kluczowych atrybutach:
1. Myślenie o produktach danych
Zmiana sposobu myślenia to najważniejszy i pierwszy krok ku siatce danych. Gotowość na przyjęcie wyuczonych praktyk innowacyjnych jest podstawą skutecznej modernizacji architektury danych.
Te praktyki obejmują:
- Myślenie projektowe — sprawdzona metodologia rozwiązywania „niewyobrażalnych problemów”, stosowana w domenach danych przedsiębiorstwa na potrzeby tworzenia wspaniałych produktów danych.
- Teoria zadań do wykonania — stosowanie procesu innowacji skoncentrowanej na kliencie oraz opartej na wynikach w celu zapewnienia, że produkty danych przedsiębiorstwa rozwiązują rzeczywiste problemy biznesowe.

Metodologie myślenia projektowego oferują sprawdzone techniki, które pomagają w rozbiciu silosów organizacyjnych często blokujących międzyfunkcyjne innowacje. Teoria zadań do wykonania jest niezbędnym fundamentem projektowania produktów danych, które spełniają określone cele klienta końcowego lub zadania do wykonania. Definiuje ona cel produktu.
Mimo że podejście oparte na danych pierwotnie zrodziło się w społeczności danologii, aktualnie stosowane jest dla wszystkich aspektów zarządzania danymi. Zamiast tworzyć monolityczne architektury technologiczne, siatka danych koncentruje się na konsumentach danych i wynikach biznesowych.
Myślenie o produktach danych może być stosowane w innych architekturach danych, stanowi jednak kluczową część siatki danych. Pragmatyczne przykłady stosowania myślenia o danych można znaleźć w szczegółowej analizie doświadczeń zespołu firmy Intuit.
Produkty danych
Produkty dowolnego rodzaju, począwszy od surowców po produkty w lokalnym sklepie, są tworzone jako aktywa oferujące wartość, przeznaczone do spożycia i z określonym zadaniem do wykonania. Produkty danych mogą przybierać różne formy, w zależności od domeny biznesowej lub problemu do rozwiązania i mogą obejmować:
- Analizy — raporty i pulpity informacyjne oparte na danych historycznych lub w czasie rzeczywistym.
- Zestawy danych — kolekcje danych w różnych wariantach i formatach.
- Modele — obiekty domen, modele danych, funkcje uczenia maszynowego (ML).
- Algorytmy — modele uczenia maszynowego, oceny, reguły biznesowe.
- Usługi danych i interfejsy API — dokumenty, dane właściwe, tematy, interfejsy API REST itd.
Produkt danych jest tworzony do użytku, zwykle nie należy do działu IT i wymaga śledzenia dodatkowych atrybutów, takich jak:
- Mapa interesariuszy — do kogo należy ten produkt, kto go tworzy i kto z niego korzysta?
- Opakowanie i dokumentacja — jak jest wykorzystywany? W jaki sposób jest oznakowany?
- Cel i wartość — jaka jest ukryta i jawna wartość produktu? Czy produkt ulega amortyzacji w czasie?
- Jakość i spójność — jakie są wskaźniki KPI i umowy SLA dotyczące użytkowania? Czy produkt można zweryfikować?
- Identyfikowalność, cykl życia i zarządzanie — czy istnieje zaufanie do danych i możliwość ich objaśnienia?
2. Zdecentralizowana architektura danych

Zdecentralizowane systemy IT istnieją tu i teraz, a wraz z popularyzacją aplikacji SaaS i infrastruktury chmury publicznej (IaaS) decentralizacja aplikacji i danych stanie się codziennością. Architektury oprogramowania aplikacji odchodzą od przestarzałych, scentralizowanych monolitów do rozproszonych mikrousług (siatki usług). Architektura danych będzie podążać za tym samym trendem w kierunku decentralizacji, a dane będą coraz bardziej rozproszone między różnymi lokalizacjami fizycznymi i wieloma sieciami. Nazywamy to siatką danych.
Czym jest siatka?
Siatka to topologia sieci, która umożliwia płynną współpracę dużej grupy niehierarchicznych węzłów.
Jej powszechne przykłady to:
- WiFiMesh — wiele węzłów współpracujących w celu zapewnienia większego zasięgu.
- ZWave/Zigbee — energooszczędne sieci inteligentnych urządzeń domowych.
- Sieć 5G — bardziej niezawodne i wydajne połączenia komórkowe.
- Starlink — szerokopasmowa sieć satelitarna na globalną skalę.
- Siatka usług — sposób na zapewnienie jednolitej kontroli nad zdecentralizowanymi mikrousługami (oprogramowaniem aplikacji).
Siatka danych jest podobna do tych koncepcji siatki i zapewnia zdecentralizowany sposób dystrybucji danych w wirtualnych lub fizycznych sieciach na duże odległości. Starsze monolityczne architektury integrujące dane, takie jak ETL, narzędzia do federacji danymi, a ostatnio usługi chmury publicznej, takie jak AWS Glue wymagają wysoce scentralizowanej infrastruktury.
Pełne rozwiązanie siatki danych powinno działać w środowisku wielochmurowym, potencjalnie obejmującym systemy lokalne, wiele chmur publicznych, a nawet sieci brzegowe.
Rozproszone bezpieczeństwo
W świecie bardzo rozproszonych i zdecentralizowanych danych bezpieczeństwo informacji ma kluczowe znaczenie. W przeciwieństwie do wysoce scentralizowanych monolitów, systemy rozproszone muszą delegować działania niezbędne do uwierzytelniania i autoryzacji różnych użytkowników do różnych poziomów dostępu. Bezpieczne delegowanie zaufania między sieciami nie jest łatwe.
Niektóre związane z tym kwestie to:
- Szyfrowanie danych w spoczynku — jako dane/zdarzenia zapisywane w magazynie
- Uwierzytelnianie rozproszone — dla usług i magazynów danych, takich jak mTLS, certyfikaty, SSO, tajne magazyny i sejfy danych.
- Szyfrowanie podczas trwania procesu — dane/zdarzenia, które znajdują się aktualnie w pamięci.
- Zarządzanie tożsamością — usługi LDAP/IAM, usługi wieloplatformowe.
- Rozproszone autoryzacje — w ramach punktów końcowych usługi w celu redagowania danych
Na przykład: Open Policy Agent (OPA) do umieszczenia punktu decyzyjnego założenia systemowego (PDP) w klastrze kontenera/K8S, w którym przetwarzany jest punkt końcowy mikrousługi. LDAP/IAM może być dowolną usługą JWT. - Maskowanie deterministyczne — w celu niezawodnego i spójnego maskowania danych osobowych.
Zapewnienie bezpieczeństwa w każdym systemie IT jest trudne, a zapewnienie wysokiego bezpieczeństwa w systemach rozproszonych jest jeszcze trudniejsze. Nie są to jednak problemy niemożliwe do rozwiązania.
Zdecentralizowane domeny danych
Podstawowym założeniem siatki danych jest pojęcie podziału własności i odpowiedzialności. Najlepszą praktyką jest sfederowanie własności produktów i domen danych do osób w organizacji, które znajdują się najbliżej danych. W praktyce może to być zgodne z danymi źródłowymi (na przykład z nieprzetworzonymi danymi źródłowymi, takimi jak operacyjne systemy rekordów/aplikacji) lub z danymi analitycznymi (na przykład zazwyczaj złożone dane lub zagregowane i sformatowane dane w celu ułatwienia ich wykorzystania przez konsumentów). W obu przypadkach producenci i konsumenci danych są często przypisani do jednostek biznesowych, a nie do organizacji IT.
Stare sposoby organizowania domen danych często wpadają w pułapkę konieczności dostosowania się do rozwiązań technologicznych, takich jak narzędzia ETL, hurtownie danych, jeziora danych lub strukturalna organizacja firmy ( zasoby ludzkie, marketing i inne obszary działalności). Jednak w przypadku danego problemu biznesowego domeny danych są często najlepiej dostosowane do zakresu rozwiązywanego problemu, kontekstu określonego procesu biznesowego lub rodziny aplikacji w konkretnym obszarze problemu. W dużych organizacjach te domeny danych są zazwyczaj wykorzystywane w sposób przekraczający wewnętrzne struktury i hierarchie, również technologiczne.
W siatce danych funkcjonalny rozkład domen danych ma podstawowy priorytet. Różne metody rozkładu danych na potrzeby modelowania domen można dostosować do architektury siatki danych. Dotyczy to klasycznego modelowanie hurtowni danych (np. Kimball i Inmon) lub modelowania repozytorium danych. Najczęściej stosowaną obecnie metodologią w architekturze siatki danych jest projektowanie oparte na domenach (DDD). Metoda DDD wyłoniła się z rozkładu funkcjonalnego mikrousług i jest obecnie stosowana w kontekście siatki danych.
3. Dynamiczne dane w ruchu
Ważnym elementem dyskusji na temat siatki danych, w ramach którego Oracle zabrało głos, jest zwiększenie znaczenia danych w ruchu jako kluczowego składnika nowoczesnej siatki danych. Dane w ruchu są niezbędne do wyniesienia siatki danych poza przestarzały świat monolitycznego i scentralizowanego przetwarzania wsadowego. Dane w ruchu stanowią odpowiedź na kilka podstawowych pytań dotyczących siatki danych:
- Jak możemy uzyskać dostęp do produktów danych dopasowanych do źródła w czasie rzeczywistym?
- Jakie narzędzia mogą zapewnić przeprowadzanie rozproszonych, zaufanych transakcji danych w fizycznie zdecentralizowanej siatce danych?
- Czego można użyć, jeśli konieczne jest udostępnienie zdarzeń danych jako interfejsy API produktów danych?
- Jak dostosować się do domen danych i zapewnić zaufanie i poprawność w przypadku danych analitycznych, które muszą być stale aktualizowane?
Te pytania nie dotyczą jedynie „szczegółów wdrożenia” — mają centralne znaczenie dla samej architektury danych. Oparty na domenie projekt danych statycznych będzie oparty na innych technikach i narzędziach niż dynamiczne dane w ruchu przetwarzane w ramach tego samego projektu. Na przykład w dynamicznych strukturach danych, zbiór danych jest centralnym źródłem prawdy dla zdarzeń związanych z danymi.
Zbiory danych oparte na zdarzeniach

Zbiory stanowią podstawowy element tworzenia funkcji architektury rozproszonych danych. Zbiór danych, tak jak księga rachunkowa, rejestruje mające miejsce transakcje.
Podczas dystrybucji księgi zdarzenia danych stają się „odtwarzalne” w dowolnym miejscu. Niektóre księgi są podobne do lotniczych „czarnych skrzynek”, używanych do zapewnienia wysokiej dostępności danych i odzyskiwania po awarii.
W przeciwieństwie do scentralizowanych i monolitycznych magazynów danych, rozproszone księgi są przeznaczone do śledzenia niepodzielnych zdarzeń i/lub transakcji zachodzących w innych (zewnętrznych) systemach.
Siatka danych nie stanowi tylko jednego rodzaju zbioru. W zależności od przypadków użycia i wymagań, siatka danych może korzystać z różnych typów zbiorów danych opartych o zdarzenia, w tym:
- Księga zdarzeń ogólnego przeznaczenia — np. Kafka lub Pulsar
- Księga zdarzeń danych — rozproszone narzędzia CDC/replikacji
- Oprogramowanie pośredniczące do obsługi wiadomości — w tym ESB, MQ, JMS i AQ
- Rejestr Blockchain — w celu zapewnienia bezpiecznych, niezmiennych, wielokanałowych transakcji
Księgi mogą działać łącznie jako trwały dziennik zdarzeń dla całego przedsiębiorstwa, oferując pełną listę zdarzeń danych odbywających się w systemach zapisu i analiz.
Strumienie danych w różnych językach

Strumienie danych w wielu językach występują częściej niż kiedykolwiek. Różnią się one pod kątem typów zdarzeń, ładunków oraz semantyki transakcji. Siatka danych powinna obsługiwać niezbędne typy strumieni dla różnych zadań przetwarzania danych korporacyjnych.
Proste zdarzenia:
— Base64 / surowe, nieschematyczne zdarzenia JSON
— Nieprzetworzone zdarzenia o niskiej telemetrii
Podstawowe zdarzenia logowania aplikacji / Internet of Things (IoT):
— JSON/Protobuf — mogą posiadać schemat
— MQTT — protokoły IoT
Zdarzenia procesów aplikacji biznesowych:
— Zdarzenia SOAP/REST — XML/XSD, JSON
— B2B — programy i standardy wymiany
Zdarzenia/transakcje związane z danymi:
— Logiczne rekordy zmian — LCR, SCN, URID
— Spójność granic — zatwierdzenia a operacje
Przetwarzanie danych strumieniowych
Przetwarzanie strumieniowe to sposób modyfikowania danych w strumieniu zdarzeń. W przeciwieństwie do funkcji typu „lambda”, procesor strumieniowy utrzymuje przepływy danych w określonym oknie czasowym i może stosować wobec danych znacznie bardziej zaawansowane zapytania analityczne.
- Wartości progowe, alarmy i monitorowanie telemetrii
- Funkcje wyrażeń regularnych, matematyka/logika i konkatenacja
- Rejestrowanie, zastępowanie i maskowanie
Podstawowe filtrowanie danych:
Prosty proces ETL:
CEP i złożony proces ETL:
- Złożone przetwarzanie zdarzeń (CEP)
- Przetwarzanie DML (ACID) i grupy krotek
- Agregacje, wartości wyszukiwania, złączenia złożone
Analiza strumieniowa:
- Analizy ciągów czasowych i niestandardowe okna czasowe
- Analizy geoprzestrzenne, uczenie maszynowe i osadzona SI
Inne ważne atrybuty i zasady
Siatka danych ma oczywiście więcej niż trzy atrybuty. Skupiliśmy się na trzech powyższych, aby zwrócić uwagę na atrybuty, które zdaniem Oracle są świeżymi i bardziej unikatowymi aspektami nowoczesnego podejścia do siatki danych.
Inne ważne atrybuty siatki danych obejmują:
- Narzędzia samoobsługowe — siatka danych uwzględnia ogólny trend samoobsługowego zarządzania danymi. Coraz więcej twórców aplikacji będzie wywodzić się szeregów właścicieli danych.
- Zarządzanie danymi — siatka danych uwzględnia również popularny od dawna trend bardziej sformalizowanego, sfederowanego modelu zarządzania, wspierany przez wiele lat przez dyrektorów ds. danych, zarządców danych i dostawców katalogów danych.
- Użyteczność danych — fundamentalne zasady siatki danych zawierają sporo podstaw mających na celu zapewnienie wysoką użyteczność produktów danych. Zasady dotyczące produktów danych będą dotyczyć cennych, użytecznych i możliwych do udostępnienia danych.
7 przypadków użycia siatki danych
Poprawnie wdrożona siatka danych spełnia przypadki użycia dla operacyjnych i analitycznych domen danych. Poniższe siedem przypadków użycia ilustruje szeroki zakres możliwości, które siatka danych oferuje w kontekście danych firmowych.
Firmy mogą podejmować lepsze decyzje operacyjne i strategiczne dzięki integracji danych operacyjnych i analityki w czasie rzeczywistym.Szkoła zarządzania MIT Sloan School of Management
1. Modernizacja aplikacj
Poza migracjami monolitycznych architektur danych do chmury typu „lift and shift”, wiele organizacji stara się również wycofać swoje scentralizowane aplikacje i przejść do bardziej nowoczesnej architektury aplikacji mikrousług.


Przestarzałe monolityczne aplikacje zazwyczaj korzystają z olbrzymich baz danych, co stawia przed planem migracji wyzwania związane z ograniczeniem zaburzeń dostępu, ryzyka i kosztów. Siatka danych może zapewnić ważne operacyjne możliwości informatyczne dla klientów wykonujących stopniowe przejścia z monolitów do architektury siatki. takich jak np.:
- Odciążanie domeny podrzędnej transakcji bazy danych, takich jak filtrowanie danych przez „kontekst powiązany”
- Dwukierunkowa replikacja transakcji na potrzeby migracji fazowych
- Synchronizacja międzyplatformowa, na przykład pomiędzy jednostką główną i DBaaS
W języku architektów mikrousług w tym podejściu używana jest dwukierunkowa skrzynka nadawcza dla transakcji w celu umożliwienia wzorca migracji drzewa figowego w jednym kontekście powiązanym jednocześnie.
2. Dostępność i ciągłość danych

Aplikacje o krytycznym znaczeniu wymagają bardzo wysokich wskaźników KPI i umów SLA w zakresie odporności i ciągłości. Bez względu na to, czy są to aplikacje monolityczne, mikrousługowe czy też mieszane, nie mogą przestać działać!
W przypadku systemów o krytycznym znaczeniu rozproszony model danych zapewniający końcową spójność danych jest zazwyczaj niedopuszczalny. Takie aplikacje muszą jednak działać w wielu centrach danych jednocześnie. Pojawia się więc pytanie o ciągłość biznesową: „jak uruchomić swoje aplikacje w więcej niż jednym centrum danych, a jednocześnie zagwarantować poprawność i spójność danych?”
Bez względu na to, czy w architekturach monolitycznych są używane „odłamkowe zbiory danych”, czy konfigurowane mikrousługi zapewniające wysoką dostępność między lokalizacjami, siatka danych oferuje poprawne, szybkie dane na dowolną odległość.
Siatka danych może stanowić podstawę zdecentralizowanych, ale poprawnych w 100% danych w różnych lokalizacjach. takich jak np.:
- Transakcje logiczne o minimalnych opóźnieniach (między platformami)
- Gwarancje poprawności danych zgodne z ACID
- Wieloaktywne, dwukierunkowe i rozstrzygające konflikty
3. Pozyskiwanie zdarzeń i skrzynka nadawcza dla transakcji


Nowoczesna platforma w stylu siatki usług wykorzystuje zdarzenia do wymiany danych. Zamiast polegania na przetwarzaniu wsadowym w warstwie danych, ładunki danych przepływają w sposób ciągły, gdy zdarzenia mają miejsce w aplikacji lub magazynie danych.
W przypadku niektórych architektur mikrousługi muszą wzajemnie wymieniać się ładunkami danych. Inne wzorce wymagają wymiany między monolitycznymi aplikacjami lub magazynami danych. Nasuwa się pytanie: „w jaki sposób można niezawodnie wymieniać ładunki danych z mikrousług między aplikacjami i magazynami danych?”
Siatka danych może stanowić fundament technologiczny do rozwiązania wymiany danych stworzonego z myślą o mikrousługach. takich jak np.:
- Mikrousługa do mikrousługi w kontekście
- Mikrousługa do mikrousługi w różnych kontekstach
- Monolit do/z mikrousługi
Wzorce mikrousług, takie jak pozyskiwanie zdarzeń, CQRS i skrzynka nadawcza dla transakcji, są powszechnie pojmowanymi rozwiązaniami. Siatka danych oferuje narzędzia i struktury sprawiające, że te wzorce są powtarzalne i niezawodne na dowolną skalę.
4. Integracja oparta na zdarzeniach
Poza wzorcami projektowania mikrousług potrzeba integracji przedsiębiorstwa rozciąga się na inne systemy IT: bazy danych, procesy biznesowe, aplikacje i urządzenia fizyczne każdego rodzaju. Siatka danych oferuje podstawę do integracji danych w ruchu.
Dane w ruchu są zazwyczaj oparte na zdarzeniach. Zdarzenie z ładunkiem danych może zostać zainicjowane przez czynność użytkownika, zdarzenie urządzenia, etap procesu lub zatwierdzenie magazynu danych. Te dane mają kluczowe znaczenie dla integracji systemów Internet of Things (IoT), procesów biznesowych i baz danych, hurtowni danych i jezior danych.
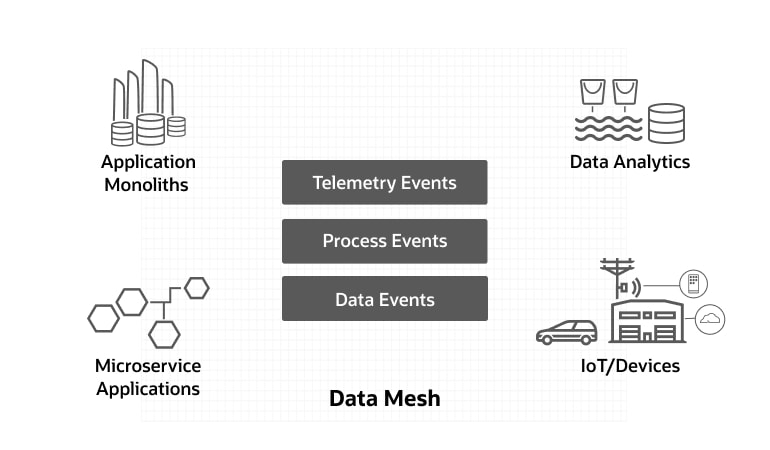
Siatka danych udostępnia podstawową technologię, umożliwiającą integrację w czasie rzeczywistym w całym przedsiębiorstwie. takich jak np.:
- Łączenie rzeczywistych zdarzeń urządzeń z systemami IT
- Integracja procesów biznesowych pomiędzy systemami ERP
- Dopasowywanie operacyjnych baz danych do analitycznych magazynów danych
Duże organizacje będą korzystały z kombinacji starych i nowych systemów, monolitów i mikrousług, operacyjnych i analitycznych magazynów danych. Siatka danych może pomóc zunifikować te zasoby w różnych domenach biznesowych i domenach danych.
5. Odbieranie strumienia (na potrzeby analityki)

Analitycznymi magazynami danych mogą być składnice danych, hurtownie danych, kostki OLAP, jeziora danych i technologie repozytorium danych.
Zazwyczaj są dostępne tylko dwa sposoby wprowadzania danych do tych analitycznych magazynów danych:
- Ładowanie wsadowe/mikropartii z harmonogramem czasowym
- Odbieranie strumienia z ciągłym ładowaniem zdarzeń danych
Siatka danych stanowi podstawę przyjmowania funkcjonalności ocbierania strumienia danych. takich jak np.:
- Zdarzenia danych z baz danych lub magazynów danych
- Zdarzenia urządzeń z fizycznej telemetrii urządzenia
- Rejestrowanie zdarzeń aplikacji lub transakcji biznesowych
Odbieranie zdarzeń ze strumienia może zmniejszyć obciążenie systemów źródłowych, poprawić rzetelność danych (co jest ważne dla analityki danych) i umożliwić analizy w czasie rzeczywistym.
6. Potoki danych strumieniowych

Po przyjęciu danych do analitycznych magazynów danych zazwyczaj istnieje potrzeba przygotowania i transformacji danych przez potoki danych na różnych etapach lub w różnych strefach. Taki proces udoskonalania danych jest często niezbędny dla produktów danych analitycznych na późniejszych etapach.
Siatka danych może zapewnić niezależnie zarządzaną warstwę potoku danych, która współpracuje z analitycznymi magazynami danych, zapewniając następujące usługi podstawowe:
- Samoobsługowe wykrywanie i przygotowywanie danych
- Zarządzanie zasobami danych w różnych domenach
- Przygotowywanie i przekształcanie danych w wymagane formaty produktów danych
- Weryfikacja danych według zasad zapewniających ich spójność
Te potoki powinny być zdolne do pracy z różnymi fizycznymi magazynami danych (takimi jak składnice, hurtownie czy jeziora) lub jako „strumień danych pushdown” w analitycznych platformach danych obsługujących przesyłanie strumieniowe danych, takich jak Apache Spark lub inne technologie repozytorium danych.
7. Analizy strumieniowe

Zdarzenia mają miejsce cały czas. Analiza zdarzeń w strumieniu może mieć kluczowe znaczenie dla zrozumienia tego, co się dzieje w danym momencie.
Tego rodzaju analizy strumieni zdarzeń w czasie rzeczywistym oparte na szeregach czasowych mogą być ważne dla danych fizycznych urządzeń IoT i dla zrozumienia, co dzieje się w centrach danych IT lub w transakcjach finansowych, na przykład w ramach wykrywania oszustw.
W pełni funkcjonalna siatka danych będzie zawierać możliwości analizy zdarzeń wszystkich rodzajów, w wielu różnych typach okien czasowych zdarzeń. takich jak np.:
- Prosta analiza strumienia zdarzeń (zdarzenia internetowe)
- Monitorowanie zadania biznesowego (zdarzenia SOAP/REST)
- Przetwarzanie zdarzeń złożonych (korelacja wielostrumieniowa)
- Analiza zdarzeń danych (w transakcjach DB/ACID)
Podobnie jak w przypadku potoków danych, analizy strumieniowe mogą działać w ustanowionej infrastrukturze repozytorium danych, lub osobno, jako usługi natywne w chmurze.
Maksymalna wartość dzięki jednej siatce pokrywającej wszystkie zasoby danych
Liderzy integracji danych pragną operacyjnej i analitycznej integracji danych w czasie rzeczywistym z różnorodnych i odpornych zbiorów danych. Innowacyjna architektura danych bezustannie i szybko ewoluuje w stronę analityki strumieniowej. Wysoka dostępność operacyjna doprowadziła do analiz w czasie rzeczywistym, a automatyzacja inżynierii danych upraszcza przygotowywanie danych, umożliwiając badaczom danych i analitykom korzystanie z narzędzi samoobsługowych.
Podsumowanie przypadków użycia siatki danych

Utwórz siatkę operacyjną i analityczną pokrywającą wszystkie zasoby danych
Umieszczenie wszystkich funkcji zarządzania danymi w ujednoliconej architekturze będzie miało wpływ na każdego konsumenta danych. Siatka danych pomoże ulepszyć globalne systemy zapisu i zaangażowania, w celu ich niezawodnego działania w czasie rzeczywistym, dostosowując dane czasu rzeczywistego do potrzeb menedżerów biznesowych, badaczy danych i klientów. Upraszcza także zarządzanie danymi dla aplikacji mikrousług nowej generacji. Użytkownicy końcowi, analitycy i badacze danych, korzystając z nowoczesnych metod i narzędzi, będą jeszcze szybciej reagować na żądania klientów i zagrożenia ze strony konkurencji. Dobrze udokumentowany przykład można znaleźć celach i wynikach firmy Intuit.
Korzyści z siatki danych w najważniejszych projektach
W miarę wdrażania nowego sposobu myślenia o danych i modelu operacyjnego ważne jest rozwijanie doświadczenia w każdej z tych wspomagających technologii. Podczas migracji do siatki danych można osiągnąć wymierne korzyści, przystosowując architekturę szybkich danych do analizy strumieniowej, wykorzystując inwestycje w wysoką dostępność do analiz w czasie rzeczywistym i zapewniając samoobsługowe analizy w czasie rzeczywistym dla badaczy i analityków danych.
Porównanie i wyodrębnienie różnic
| Struktura danych | Integracja programistyczna | Magazyn danych analitycznych | |||||
|---|---|---|---|---|---|---|---|
| Siatka danych | Integracja danych | Metakatalog | Mikrousługi | Wiadomości | Repozytorium danych | Rozproszona hurtownia danych | |
| Ludzie, procesy i metody: | |||||||
| Ukierunkowanie na produkt danych | dostęp. |
dostęp. |
dostęp. |
1/4 dostęp. |
1/4 dostęp. |
3/4 dostęp. |
3/4 dostęp. |
| Atrybuty technicznej architektury: | |||||||
| Architektura rozproszona | dostęp. |
1/4 dostęp. |
3/4 dostęp. |
dostęp. |
dostęp. |
1/4 dostęp. |
3/4 dostęp. |
| Księgi oparte na zdarzeniach | dostęp. |
niedostęp. |
1/4 dostęp. |
dostęp. |
dostęp. |
1/4 dostęp. |
1/4 dostęp. |
| Obsługa ACID | dostęp. |
dostęp. |
niedostęp. |
niedostęp. |
3/4 dostęp. |
3/4 dostęp. |
dostęp. |
| Ukierunkowanie na strumień | dostęp. |
1/4 dostęp. |
niedostęp. |
niedostęp. |
1/4 dostęp. |
3/4 dostęp. |
1/4 dostęp. |
| Ukierunkowanie na dane analityczne | dostęp. |
dostęp. |
dostęp. |
niedostęp. |
niedostęp. |
dostęp. |
dostęp. |
| Ukierunkowanie na dane operacyjne | dostęp. |
1/4 dostęp. |
dostęp. |
dostęp. |
dostęp. |
niedostęp. |
niedostęp. |
| Siatka fizyczna i logiczna | dostęp. |
dostęp. |
niedostęp. |
1/4 dostęp. |
3/4 dostęp. |
3/4 dostęp. |
1/4 dostęp. |
Wyniki biznesowe
Ogólne korzyści
Szybsze cykle innowacji oparte na danych
Niższe koszty operacyjne w zakresie danych krytycznych
Wyniki operacyjne
Wielochmurowa płynność danych
— odblokuj swobodny przepływ kapitału danych
Udostępnianie danych w czasie rzeczywistym
— od operacji do operacji i od operacji do analiz
Brzegowe usługi danych oparte na lokalizacji
— korelacja pomiędzy zdarzeniami fizycznych urządzeń/zdarzeniami danych
Zaufana wymiana danych poprzez mikrousługi
— pozyskiwanie zdarzeń z prawidłowymi danymi
— DataOps i CI/CD dla danych
Nieprzerwana ciągłość
— umowy SLA na poziomie 99,999%
— migracje do chmury
Wyniki analizy
Automatyzacja i upraszczanie produktów danych
— wielomodelowe zbiory danych
Analiza danych dla ciągów czasowych
— Delty/zmienione rekordy
— dokładność poszczególnych zdarzeń
Eliminacja pełnych kopii danych w operacyjnym magazynie danych
— księgi i potoki oparte na dziennikach
Dystrybuowane jeziora i hurtownie danych
— Hybrydowe/wielochmurowe/globalne
— Integracja strumieniowa / ETL
Analityka predykcyjna
— monetyzacja danych, nowe usługi danych na sprzedaż
Połączenie wszystkich możliwości
Transformacja cyfrowa jest wybitnie trudna i niestety większość firm odniesie w tej kwestii porażkę. Wraz z upływem czasu projektowanie oprogramowania i architektura danych stają się coraz bardziej rozproszone, ponieważ nowoczesne techniki wycofują się z wysoce scentralizowanych i monolitycznych stylów.
Siatka danych to nowe podejście do danych — zaplanowane przejście do wysoce rozproszonych i działających w czasie rzeczywistym zdarzeń związanych z danymi, w przeciwieństwie do monolitycznego, scentralizowanego i wsadowego przetwarzania danych. Siatka danych to przede wszystkim kulturowa zmiana myślenia, która stawia potrzeby konsumentów danych na pierwszym miejscu. Jest to także prawdziwa rewolucja technologiczna, wynosząca na piedestał platformy i usług umożliwiające zdecentralizowaną architekturę danych.
Przypadki użycia siatki danych obejmują dane operacyjne i dane analityczne. T jedna z kluczowych różnic w porównaniu z konwencjonalnymi jeziorami/repozytoriami danych i hurtowniami danych. Takie dopasowanie operacyjnych i analitycznych domen danych ma kluczowe znaczenie dla zwiększenia potencjału samoobsługi klienta danych. Nowoczesna technologia platform danych może pomóc usunąć pośredników w łączeniu producentów danych bezpośrednio z ich odbiorcami.
Oracle od dawna jest liderem w zakresie kluczowych rozwiązań w zakresie danych, udostępniając najnowocześniejsze funkcje umożliwiające zaufaną siatkę danych:
- Infrastruktura Oracle Generation 2 Cloud z ponad 33 aktywnymi regionami
- Wielomodelowa baza danych dla produktów danych o „zmiennym wariancie”
- Księga zdarzeń danych oparta na mikrousługach na potrzeby wszelkich magazynów danych
- Przetwarzanie strumieniowe w wielu chmurach na potrzeby zaufanych danych w czasie rzeczywistym
- Platforma interfejsu API platform, nowoczesne tworzenie aplikacji i narzędzia samoobsługowe
- Analizy, wizualizacja danych i natywna analityka danych w chmurze