Building an Adaptive Intelligence Process in Oracle Cloud
by Brendan Tierney
This article explains the main components of an adaptive intelligence solution for machine learning and how the various components of the Oracle Cloud service offerings can be used to build such a solution.
Over the past few years, there has been a large uptake of machine learning and predictive analytics, along with many other data science–type solutions. These technologies are being used to create various types of predictive models and advanced decision-management solutions to gain a deeper understanding of data and then use these new insights to gain a competitive advantage. Every day, new reports are available detailing how organizations around the world are discovering new patterns in their data and using this new information to understand and interact with their customers in many new ways. Chatbots are one of the latest technologies using machine learning in new and innovative ways. (Check out the Intelligent Bots feature of Oracle Mobile Cloud.)
With the increasing use of such technologies—along with the ever-growing range of data from traditional data sources (boring old small data) to sensors and Internet of Things (IoT) technologies—the ability to manage the data science process and lifecycle is becoming ever more important and ever more complex. The ability to manage these processes in an automated or semiautomated manner is now what most organizations are turning their focus towards, because too much time is being taken up with running scripts and performing simple, straightforward evaluations. The time data scientists take doing these tasks can be better spent on new application areas for their organizations.
The automation of the data science process is the focus of many organizations as a way to free up their data scientists from performing mundane and repetitive tasks, so they can concentrate on delivering data science to new areas of the business. This automation of the data science process is commonly referred to as adaptive intelligence. Adaptive intelligence involves building a process, an infrastructure, and applications to support the continual building, evaluating, monitoring, and deployment of machine learning models, as well as the continual monitoring of the effectiveness of these machine learning models in an automated manner.
What Is Adaptive Intelligence?
Adaptive intelligence is the next layer to be developed by the data science team after building and deploying advanced analytics and machine learning throughout an organization. With each deployment of an advanced analytics or machine learning solution, additional data is generated by the models and applications and, hence, an additional level of monitoring is required.
For example, the models might predict a particular subset of customers will "churn." Over time, data will be gathered to reflect if these and other customers have actually churned. Monitoring and evaluating the data is needed to examine what customers actually churned and compare them to the predicted list of customers. Detailed examination of the data and results are needed to determine the main contributing factors for customers churning, and so on.
A lot of data can be generated by the models and additional data might need to be gathered, assessed, and monitored. The data science team will struggle to find the time for gathering and monitoring the data being generated, while at the same time working on new advanced analytics and machine learning solutions. This process becomes iterative and needs to occur on a regular basis to determine if the machine learning models need to be updated to reflect the current and changing nature of the data for each of the application area. This iterative process is highlighted by the outer circular ring of the cross-industry process for data mining (CRISP-DM) lifecycle, as highlighted in red in Figure 1.

Figure 1: CRISP-DM lifecycle highlighting the iterative nature of data science projects
This outer iterative ring of the CRISP-DM process represents the core nature of what is involved with building an adaptive intelligence solution, and it is discussed in most literature that is available on the topic. It is this outer ring that can consume a significant amount of development effort, but it can also provide a significant amount of savings in human effort and monetary savings that can be achieved through the quicker and more efficient deployment of newer and updated machine learning models throughout an organization.
With adaptive intelligence, data science teams are looking at automating the outer ring of Figure 1. To do this, they need to define what their process is and how each component of the process can be automated. Additionally, any exception handling also needs to be defined to alert the data science team with any anomalies or any significant changes that the machine learning algorithms discover. The adaptive intelligence solution automates the process of monitoring the deployed advanced analytics and machine learning models and monitoring the data produced, to accomplish the following:
- Self-learning when models should be rebuilt
- Self-determining the tuning and parameter settings for the new models
- Evaluating the new models to assess if they should be deployed
- Deploying the new models to the relevant part of the technical infrastructure
- Determining the differences in data and model behaviors
- Altering the data science team to any significant changes in the data behavior
- Updating dashboards with changes in the data and models
The list of processes within an adaptive intelligence solution is long and complex. Most organizations start with building such a solution within their own data centers. But as the number of advanced analytics and machine learning models increases, so does the complexity of being able to manage the processes. This is why most organizations are now building their adaptive intelligence solutions using the cloud, because it allows automatic scaling and elastic computation when needed and, in my case, using the various Oracle Cloud solutions. This allows an organization to easily scale out their adaptive intelligence solution from having only an on-premises environment to having a hybrid solution that combines on-premises and cloud environments, to having a fully deployed solution on Oracle Cloud. For example, most of the Oracle Cloud applications have adaptive intelligence built into them. See the "Oracle Cloud Applications with Adaptive Intelligence" section for details about these Oracle Cloud applications.
Organizations that have embarked on building an automated adaptive intelligence solution are seeing large savings. The first area of savings is with the data science team. The automated adaptive intelligence solutions free the data scientists from the mundane tasks of rerunning the various tasks for rebuilding the models and verifying any changes to the machine learning models. The data scientists can now focus on new business problems and how the various data science methods can be used in other areas of the organization, with the aim of driving business value.
A second area is with an automated process that significantly reduces the time it takes to identify and deploy new or improved machine learning models. The quicker these models can be deployed, the sooner fraud can be detected, the sooner money can be saved, and the sooner additional income can be generated ("time is money").
Components of an Adaptive Intelligence Solution
As data science projects evolve, a number of different processes will be developed to aid data scientists perform their common and regular tasks. Over time, most of these tasks can start to consume most of their working days. At this point, either the productivity of the data science team is greatly reduced or they turn their attention to building adaptive intelligence solutions.
It can take some time to build a fully automated solution; many teams start by building it on their existing infrastructure. However, they realize quickly that they need more storage for their data and more technical components. This is when a hybrid solution is created with some components on premises and some using cloud services. Over time, most organizations move most of the adaptive intelligence solution so it is fully hosted on the cloud, while the deployment of the advanced analytics and machine learning solutions remain in the on-premises production environments.Figure 2 shows the typical components of an adaptive intelligence solution. Constant communication is need between the cloud platform and the on-premises components. This allows for continuous monitoring and evaluation of the data, and it also allows for the deployment of the updated machine learning models as soon as they are available. The following paragraphs outline the main components of an adaptive Intelligence solution, as shown in Figure 2.
The first part of the adaptive intelligence solution that needs defining is the Business Area Data Definition Repository. This allows the data scientists to define the various source applications and the data elements that can be used. The data to be monitored and extracted for the machine learning processes is defined along with various data processing tasks that need to be performed. The data scientists will need to define this information as they migrate each machine learning process and model out of the lab environment and into the adaptive intelligence processes.
The data sources and the data defined will need to be constantly monitored to look for any significant changes in data distributions, newer categories of data, and how the volume of data changes over time. The Data Monitoring process will perform this task and can update the Business Area Data Definition Repository with these changes. This allows the Data Monitoring process to determine when it might be best to initiate the Model Build Workspace process, which can then examine the data to see if any changes to the machine learning models are necessary.
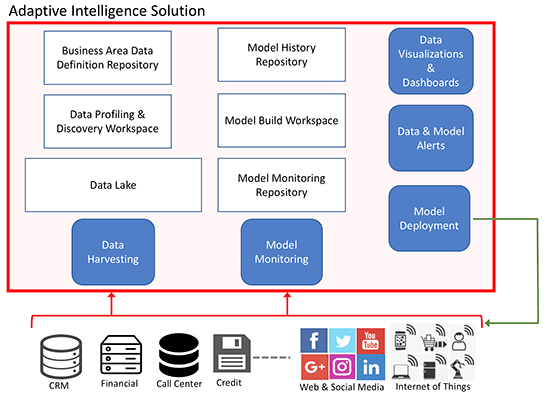
Figure 2: Components of an adaptive intelligence solution
When a model has been identified that needs to be updated, the Data Harvesting process is initiated. This process extracts data from the relevant data sources and loads the data into the Data Lake for the adaptive intelligence solution. This lake acts as the main data repository, and the same data can be used for many different machine learning models. Additionally, depending on the time involved with harvesting the data, a real-time harvesting process can be used to continuously populate the data lake with up-to-date data.
When all the data is available in the Data Lake, the Data Profiling and Discovery process is initiated to profile the data to determine if there have been any variations in the profile of the various data elements and if any correlations can be determined. All variations and any early discoveries from this process are flagged via the Data and Model Alerts process and are visually presented in the adaptive intelligence dashboards.
After all the necessary the data has been harvested for a particular model, the Model Build Workspace process can commence. This process examines the Model History Repository to discover what machine learning algorithms have been previously used. These algorithms will then be used on the newer data, evaluating the model output and performing self-tuning on the algorithms to determine the optimal setting and outcomes. The results generated by the new development models will be measured against the previously generated models to determine if the existing production-deployed model should remain or if it should be updated with one of the newly created models. This process can use a combination of machine learning algorithms including in-database algorithms, R algorithms, algorithms from Oracle R Enterprise (a feature of Oracle Advanced Analytics), Spark algorithms, and so on.
When it comes to the deployment of a new model, the machine learning language used to generate the best model in the adaptive intelligence solution should, in most cases, match the language used in the deployed production environment. In such cases, the new model can be copied to the production environment easily to replace the existing model. In some instances, there might be a difference between the two environments. In those cases, the machine learning model details can be exported using Predictive Model Markup Language (PMML) and then imported into the production environment.
Building an adaptive intelligence solution can be a large and complex process, but the benefits it can give an organization in both human effort and monetary savings can be significant, resulting is a very quick return on investment. Building such a solution can be costly and very time-consuming, because the technical infrastructure might not exist and the procurement process can take a long time. Using the available cloud solutions allows you to avoid most of these difficulties.
Building an Adaptive Intelligence Solution in Oracle Cloud
Most organizations start building such a solution using their on-premises infrastructure. In most cases, this is possible for one or a small number of machine learning models that are based on a small number of data sources.
As the number of machine learning models increases as well as the number and complexity of the data sources, organizations use a number of cloud-based solutions that work together to get the scalability they need. It is this cloud scalability that makes adaptive intelligence solutions one of the next technology waves in the area of data science.
Oracle has a large suite of platform-as-a-service (PaaS) offerings. The current list is shown in Figure 3, and this list is due to grow over the coming months.

Figure 3: Oracle Cloud PaaS offerings
Oracle Big Data Cloud Service is the ideal solution for the data lake part of an adaptive intelligence solution. It allows the necessary data gathered from across the enterprise to be stored. It also allows the storage of the historical data as well as the transient data that are necessary to monitor and update the machine learning models.
Oracle Big Data Cloud Service can also be used for the repository components of the overall solution. It comes with Spark, Oracle R Advanced Analytics for Hadoop, and Oracle Big Data Spatial and Graph, thereby providing a range of advanced analytical and machine learning algorithms.
To manage the process of moving and monitoring the data in various source applications to Oracle Big Data Cloud Service, there are a couple of options. For data replication and movement defined for certain time periods or snapshots, Oracle Data Integrator Cloud Service can be used to manage the movement of data. Alternatively, if near real-time capability is needed, Oracle GoldenGate Cloud Service can be used or, if you prefer to use the power of Kafka, the Oracle Event Hub Cloud Service can be used. Using these latter two cloud services allows for more near real-time monitoring of the data, which will in turn sooner identify when the models need to be updated. Then the newer models can be deployed back into the production environment sooner.
For some organizations, Oracle Big Data Cloud Service might not be suitable, because they do not have the scale of data necessary to justify its use. An alternative is to use the database as a service (DaaS) and, particularly, the extreme or high-performance versions of this service. These two versions come with the in-database machine learning option (Oracle Advanced Analytics) and also include Oracle R Enterprise. This will allow you to use the advanced analytics and machine learning capabilities of the R language along with Oracle Database. Using the DaaS versions allows for all the necessary enterprise data and repositories for an adaptive intelligence solution to be located in one cloud service.
Oracle Cloud services allow you to quickly build and adjust your solution while using the elastic scalability of the cloud.
Oracle Cloud Applications with Adaptive Intelligence
For some organizations, building an adaptive intelligence solution might seem to be in the distant future, but examples of such solutions are very common today. Just as advanced analytics and machine learning have been around for many decades, so has the implementation of adaptive intelligence solutions. For example, many Oracle applications have been using machine learning for several years now, and Oracle has built in the ability to update and maintain the various machine learning models automatically. The following Oracle applications, as well as others, have adaptive intelligence built into them, and they are available in Oracle Cloud:
- Oracle Customer Experience Cloud (Oracle CX Cloud)
- Oracle Human Capital Management Cloud (Oracle HCM Cloud)
- Oracle Supply Chain Management Cloud (Oracle SCM Cloud)
- Oracle Enterprise Resource Planning Cloud (Oracle ERP Cloud)
- Oracle Internet of Things Cloud Service
- Oracle Student Cloud
- Oracle Revenue Management Cloud
- Oracle Financial Consolidation and Close Cloud Service
- Oracle Enterprise Performance Management Cloud (Oracle EPM Cloud)
- Oracle Engagement Cloud, which is part of Oracle Customer Experience Cloud
Many of these Oracle Cloud applications use data from the Oracle Data Cloud to supplement the data collected and generated within the applications. This is a distinct advantage these cloud applications have over similar solutions that are custom-developed or are available from various alternative suppliers.
Many companies are now using the principles of adaptive intelligence to build applications that bridge the gap between the data scientist and the end user, and these Oracle applications are examples of this.
Conclusion
Adaptive intelligence is part of the next wave of solutions in data science. The primary aim of building an adaptive intelligence solution is to automate the process of building, evaluating, and deploying advanced analytics and machine learning models in an organization. Automating these processes for defined data science solutions allows data scientists to concentrate on newer application areas rather than spending their time running routine and repetitive processes.
Moving to the cloud allows organizations to build out the automation of their adaptive intelligence solutions in an incremental manner. Using Oracle Cloud services provides the elastic scalability required for the growing amount and ever-changing nature of data that most organizations have.
The range of cloud services available from Oracle allows organizations to build the components of their adaptive intelligence solution using the tools and cloud services that best suit their size and needs. As things change over time, other cloud services can be included to constantly evolve and efficiently update machine learning models. The less time it takes to use these models, the quicker an organization can reduce costs and generate additional cost savings.
About the Author
Oracle ACE Director Brendan Tierney is an independent consultant (Oralytics) and lectures on data science, databases, and big data at the Dublin Institute of Technology/Dublin Technological University. He has 24+ years of experience working in the areas of data mining, data science, big data, and data warehousing. As a recognized data science and big data expert, Tierney has worked on projects in Ireland, the UK, Belgium, Holland, Norway, Spain, Canada, and the US. He is active in the UK Oracle User Group (UKOUG) community and one of the user group leaders in Ireland. Tierney has also been editor of the UKOUG Oracle Scene magazine, is a regular speaker at conferences around the world, and writes for several publications. In addition, he has published four books, three with Oracle Press/McGraw-Hill (Predictive Analytics Using Oracle Data Miner, Oracle R Enterprise: Harnessing the Power of R in Oracle Database, and Real World SQL and PL/SQL: Advice from the Experts) and one with MIT Press (Essentials of Data Science).