Automating Tasks Securely with RAG and a Choice of LLMs

Introduction
In the effort to streamline repetitive tasks or automate them entirely, why not enlist the help of AI? Using a foundation model to automate repetitive tasks may sound appealing, but it may put confidential data at risk. Retrieval-augmented generation (RAG) is an alternative to fine-tuning, keeping inference data isolated from a model’s corpus.
We want to keep our inference data and model separated—but we also want a choice in which large language model (LLM) we use and a powerful GPU for efficiency. Imagine if you could do all of this with just one GPU!
In this demo, we’ll show how to deploy a RAG solution using a single NVIDIA A10 GPU; an open source framework such as LangChain, LlamaIndex, Qdrant, or vLLM; and a light 7-billion-parameter LLM from Mistral AI. It’s an excellent balance of price and performance and keeps inference data separated while updating the data as needed.
Demo
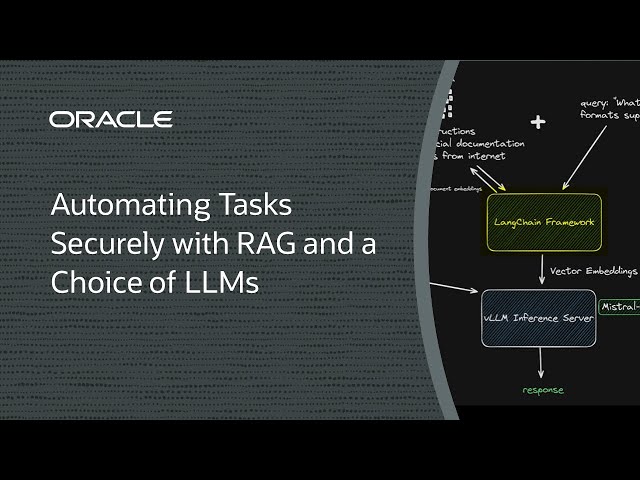
Prerequisites and setup
- Oracle Cloud account—sign-up page
- Oracle GPU compute instance—documentation
- LlamaIndex—documentation
- LangChain—documentation
- vLLM—documentation
- Qdrant—documentation