簡介
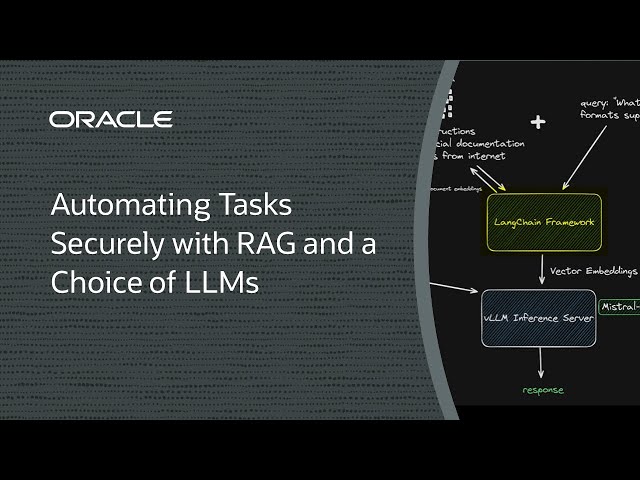
為了簡化重複性任務或完全自動化,為什麼不加入 AI 的協助?使用基礎模型將重複性工作自動化可能會相當具有吸引力,但可能會讓機密資料面臨風險。檢索增強生成 (RAG) 是微調的替代方案,可將推論資料與模型的語料庫隔離。
我們希望將推論資料和模型分開,但我們也希望選擇我們使用的大型語言模型 (LLM) 和強大的 GPU 來提高效率。想像一下,如果只要一個 GPU 就能做到這一切!
在此示範中,我們將展示如何使用單一 NVIDIA A10 GPU 部署 RAG 解決方案;這是 LangChain、LlamaIndex、Qdrant 或 vLLM 等開放原始碼架構;以及來自 Mistral AI 的輕量 7-billion-parameter LLM。在更新資料時,價格與效能之間取得極佳平衡,並視需要保留推論資料。
展示