Améliorez les soins reposant sur la valeur grâce à la surveillance des performances

Améliorer le bien-être du personnel et les soins apportés aux patients
Les systèmes de santé d'aujourd'hui sont confrontés à deux problèmes majeurs et liés : l'épuisement professionnel et les pénuries de personnel. Près de 50 % des médecins et infirmiers interrogés ont signalé des symptômes d'épuisement important en raison de la lourdeur des tâches administratives et bureaucratiques et un nombre d'heures de travail trop élevé. En conséquence, de nombreux travailleurs ont choisi de quitter le secteur à la recherche d'un meilleur équilibre entre vie professionnelle et vie privée, laissant les hôpitaux en proie à de graves pénuries de personnel qu'ils ne peuvent combler. Plus de la moitié des hôpitaux américains déclarent que le taux de vacance des postes d'infirmiers est supérieur à 7,5 % et que les heures supplémentaires et les dépenses d'agence ont augmenté de 169 % depuis 2013. Malheureusement, selon de nombreuses estimations, la pénurie de professionnels de santé ne fera qu'empirer au cours de la prochaine décennie.
Pour faire face à ces deux problèmes, les prestataires doivent continuer à optimiser leurs modèles de dotation en personnel de manière à donner la priorité au bien-être des professionnels de santé tout en garantissant la meilleure expérience et les meilleurs résultats possibles pour les patients. Les plateformes de données joueront un rôle essentiel en donnant aux fournisseurs un accès central aux données provenant de systèmes disparates et d'analyses avancées et de modèles de machine learning qu'ils peuvent utiliser pour prévoir plus précisément les besoins en personnel. Grâce à ces informations, les institutions de santé peuvent mieux équilibrer les charges de travail et veiller à ce que les effectifs soient toujours suffisants pour prévenir l'épuisement professionnel et améliorer les soins aux patients.
Simplifier les emplois du temps du personnel de santé grâce au machine learning
Alors que les données cliniques peuvent donner beaucoup d'information aux médecins sur leurs patients, les systèmes opérationnels, tels que les systèmes de gestion du capital humain (HCM), peuvent quant à eux apporter de nombreux renseignements aux organismes de soins de santé sur leurs salariés, en fournissant des informations telles que les horaires effectués, les heures travaillées et les congés maladie pris par les professionnels de santé et d'autres membres du personnel. Comme l'illustre le schéma suivant, Oracle Data Platform unifie les données médicales et opérationnelles et utilise des analyses avancées et le machine learning pour aider les fournisseurs à comprendre l'impact des modèles de dotation sur les résultats des soins aux patients, la façon dont les décisions en matière de dotation en personnel peuvent avoir un impact sur les soins de la semaine suivante en temps quasi réel, les lacunes de personnels qui peuvent être comblées en cas d'un autre pic important de COVID-19, l'aspect d'un modèle de dotation optimale pour un moment donné, et plus encore.
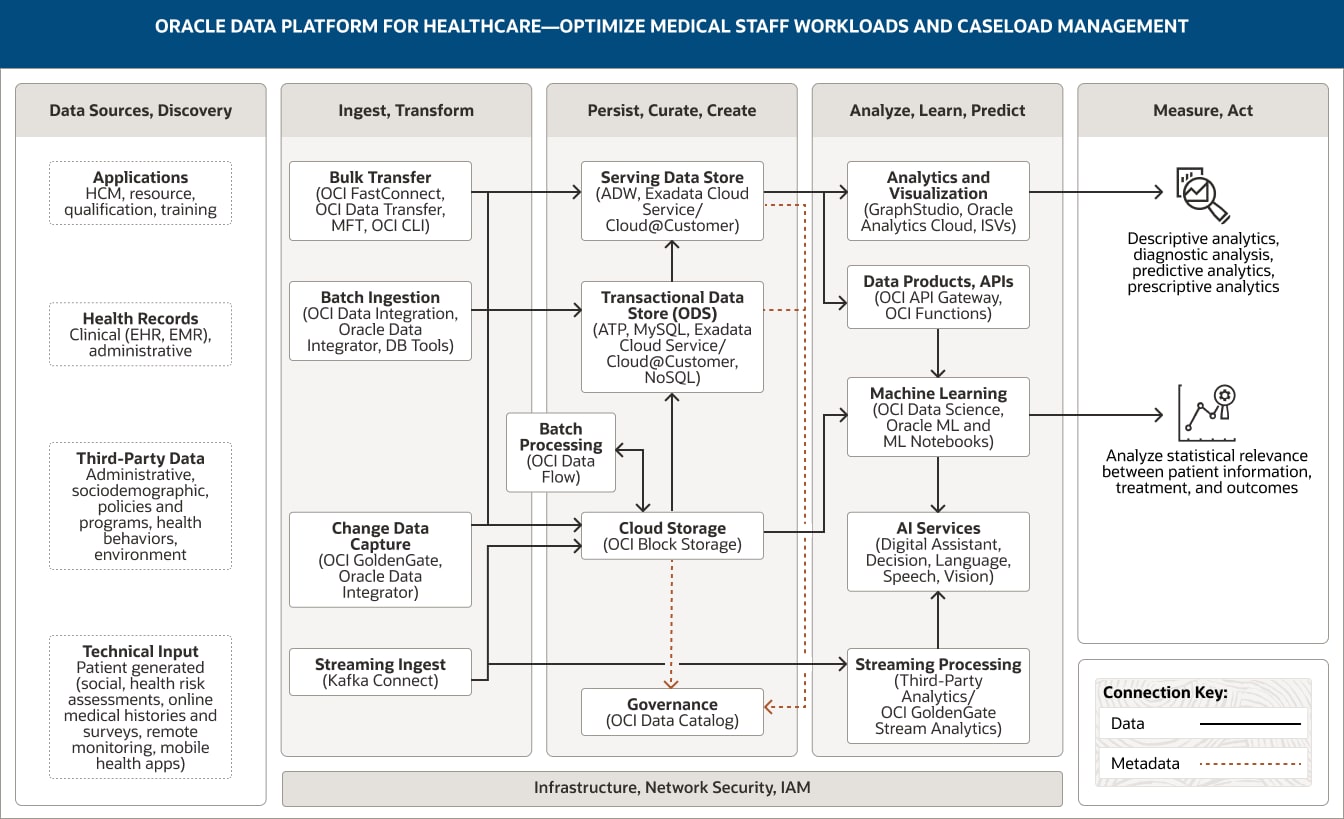
Cette illustration montre comment utiliser Oracle Data Platform pour les soins de santé afin d'optimiser la charge de travail du personnel médical. La plateforme comprend les cinq piliers suivants :
- 1. Sources de données et repérage
- 2. Ingestion et transformation
- 3. Sauvegarde, tri et création
- 4. Analyses, apprentissage et prévision
- 5. Mesures et réactions
Le pilier « Sources de données et repérage » inclut quatre catégories de données.
- 1. Les données d'application comprennent les données HCM, de ressource, de qualification et de formation.
- 2. Les dossiers de santé incluent des données médicales, telles que des données provenant des dossiers de santé partagés, des dossiers médicaux partagés et des systèmes administratifs.
- 3. Les données tierces comprennent des données administratives et sociodémographiques et des données relatives aux politiques et programmes, aux comportements en matière de santé et à l'environnement.
- 4. Les données d'entrée techniques comprennent les données générées par les patients (comme les données sociales, les évaluations des risques pour la santé, les antécédents médicaux en ligne et les réponses aux enquêtes) et les données des applications de suivi à distance et de télésanté.
Le pilier « Ingestion et transformation » comprend quatre fonctionnalités.
- 1. Le transfert en masse utilise OCI FastConnect, OCI Data Transfer, MFT et l'interface de ligne de commande OCI.
- 2. L'ingestion par lots utilise OCI Data Integration, Oracle Data Integrator et les outils de base de données.
- 3. La capture des données de modification utilise OCI GoldenGate et Oracle Data Integrator.
- 4. L'ingestion de flux de données utilise Kafka Connect.
Ces quatre fonctionnalités se connectent de manière unidirectionnelle au dépôt de données de service, au stockage cloud et au dépôt de données transactionnel dans le pilier « Sauvegarde, tri et création ».
De plus, l'ingestion de flux est connectée au traitement de flux au sein du pilier « Analyses, apprentissage et prévision ».
Le pilier « Sauvegarde, tri et création » comprend cinq fonctionnalités.
- 1. Le dépôt de données de service utilise Autonomous Data Warehouse, Exadata Cloud Service et Exadata Cloud@Customer.
- 2. Le dépôt de données transactionnelles utilise Autonomous Transaction Processing, MySQL, Exadata Cloud Service, Exadata Cloud@Customer et NoSQL.
- 3. Le stockage cloud utilise OCI Object Storage.
- 4. Le traitement par lots utilise OCI Data Flow.
- 5. La gouvernance utilise OCI Data Catalog.
Ces fonctionnalités sont connectées au sein du pilier. Le stockage cloud est connecté de manière unidirectionnelle au dépôt de données de service. Il est également connecté de manière bidirectionnelle au traitement par lots.
Le dépôt de données transactionnel est connecté de manière unidirectionnelle au dépôt de données de service.
Deux fonctionnalités se connectent au pilier « Analyses, apprentissage et prévision » : le dépôt de données de service se connecte à la fois à la fonction d'analyse et de visualisation, aux produits de données et à la fonctionnalité API. Le stockage cloud se connecte à la fonctionnalité de machine learning.
Le pilier « Analyses, apprentissage et prévision » comprend cinq fonctionnalités.
- 1. L'analyse et la visualisation utilisent Oracle Analytics Cloud, GraphStudio et des éditeurs de logiciels indépendants.
- 2. Les produits de données et les API utilisent OCI API Gateway et OCI Functions.
- 3. Le machine learning utilise OCI Data Science, Oracle Machine Learning et Oracle ML Notebooks.
- 4. Les services d'IA utilisent Oracle Digital Assistant, OCI Decision, OCI Speech, OCI Language et OCI Vision.
- 5. Le traitement des flux de données utilise OCI GoldenGate Stream Analytics et l'analyse de flux provenant de tiers.
Trois fonctionnalités sont connectées au sein du pilier. Les produits de données, la fonctionnalité API est connectée de manière unidirectionnelle à la fonctionnalité de machine learning, elle-même connectée de manière unidirectionnelle à la fonctionnalité des services d'IA, et le traitement de flux est connecté de manière unidirectionnelle à la fonctionnalité des services d'IA.
Le dépôt de données de service, le dépôt de données transactionnel et les métadonnées d'approvisionnement du stockage d'objets vers OCI Data Catalog.
Le pilier « Mesures et réactions » saisit comment l'analyse des données peut être appliquée pour permettre l'optimisation des charges de travail du personnel médical et la gestion du nombre de dossiers. Ces applications sont divisées en deux groupes.
- 1. Le premier groupe comprend des analyses descriptives, des analyses de diagnostic et des analyses prédictives et prescriptives.
- 2. Le deuxième groupe comprend l'analyse de la pertinence statistique entre l'information du patient, le traitement et les résultats.
- 3. Les trois piliers centraux (« Ingestion et transformation », « Sauvegarde, tri et création » et « Analyses, apprentissage et prévision ») sont pris en charge par l'infrastructure, le réseau, la sécurité et IAM.
Il existe trois principales façons d'injecter des données dans une architecture afin de permettre aux organismes de santé de comprendre comment optimiser la dotation en personnel de chacun de leurs services à un moment donné.
- L'historique des effectifs et les données relatives aux patients sont essentiels pour comprendre et prévoir les besoins futurs en personnel. L'application HCM fournit une grande partie des données nécessaires pour obtenir des informations sur les modèles de dotation en personnel passés et les membres du personnel. L'application d'admission, de sortie et de transfert, quant à elle, fournit des détails de base sur chaque patient. Ces données peuvent être affinées avec des données du patient provenant de sources tierces, telles que des données non structurées provenant des médias sociaux. Des extractions fréquentes en temps réel ou quasiment en temps réel nécessitant une capture des données de modification sont courantes, et des données sont régulièrement ingérées à partir des systèmes opérationnels HCM et ADT à l'aide d'OCI GoldenGate. OCI GoldenGate est également un composant essentiel de l'évolution des architectures de maillage de données, où les « produits de données » sont les objets de données centraux.
- Nous pouvons désormais ajouter des flux de données à partir de dispositifs portables qui seront ingérés en temps réel à l'aide d'un service de diffusion en continu/Kafka. Par exemple, nous pouvons ingérer des données provenant de dispositifs portables avec suivi GPS qui surveillent l'emplacement et le mouvement du personnel tout au long de la journée et l'utiliser pour comprendre comment mieux affecter le personnel aux unités et aux patients. Ces données transmises en continu (événements) sont ingérées et certaines transformations/agrégations de base sont effectuées avant d'être stockées dans le stockage cloud.
- Alors que les besoins en temps réel évoluent, l'extraction la plus courante des systèmes de santé est une sorte d'ingestion par lots à l'aide d'un processus d'extraction, de transformation, et de chargement ou d'extraction, de chargement et de transformation. L'ingestion par lots permet d'importer des données à partir de systèmes qui ne prennent pas en charge l'ingestion en continu (par exemple, d'anciens systèmes mainframe). Pour bien comprendre les besoins des patients, nous devons également ingérer des données à partir d'un système opérationnel tel qu'un dossier médical partagé ou qu'un dossier de santé partagé, probablement via le protocole Fast Healthcare Interoperability Resources. Les données proviennent de différents produits et zones géographiques. Les ingestions par lots peuvent être fréquentes, par exemple toutes les 10 ou 15 minutes, mais elles sont toujours moins fines, car ce sont des transactions qui sont extraits et traités en groupes et non individuellement.
Les options de persistance et de traitement de toutes les données collectées reposent sur quatre composants.
- Les données brutes ingérées sont stockées dans le stockage cloud pour le traitement par lots, qui effectue notamment le nettoyage et l'enrichissement nécessaires pour rendre les données consommables en aval par les utilisateurs, qui pourraient être des personnes, des applications ou des plateformes de machine learning. Bien que certaines données puissent être placées directement dans le dépôt de données de service, elles sont également placées simultanément dans le stockage cloud. Ces données seront traitées à l'aide de Spark. Le traitement peut être effectué directement à l'aide d'OCI Data Flow ou dans le cadre d'un pipeline plus important à l'aide des fonctionnalités d'orchestration d'OCI Data Integration. Ces ensembles de données traités sont renvoyés au stockage cloud pour persistance, conservation et analyse ascendantes, et finalement pour chargement sous forme optimisée dans le dépôt de données de service.
- Le dépôt de données transactionnel est utilisé pour la génération de rapports opérationnels et comme source de données pour un entrepôt de données de domaine ou un entrepôt de données d'entreprise. Il s'agit d'un élément complémentaire à un entrepôt de données dans un environnement d'aide à la décision et sert à l'établissement de rapports opérationnels, aux contrôles et à la prise de décisions, par opposition au mécanisme de décision, qui est utilisé pour l'appui tactique et stratégique à la décision. Un dépôt de données opérationnelle (ODS) est généralement une base de données relationnelle conçue pour intégrer et conserver des données provenant de plusieurs sources à utiliser pour des opérations, des rapports, des contrôles et une prise de décision opérationnelle supplémentaires.
- Nous avons créé des ensembles de données traités prêts à être rendus persistants sous forme relationnelle optimisée pour le traitement et les performances des requêtes dans le dépôt de données de service. Cela permet aux fournisseurs d'examiner toutes les données et variables nécessaires pour élaborer des plans de dotation en personnel optimaux.
La capacité à analyser, prévoir et agir repose sur deux technologies.
- Les services d'analyse et de visualisation fournissent des analyses descriptives (descriptions des tendances actuelles avec des histogrammes et des graphiques), des analyses prédictives (prédiction des événements, identification des tendances et détermination des probabilités de résultats incertains) et des analyses prescriptives (propositions d'actions appropriées conduisant à une prise de décision optimale). Ensemble, ils peuvent être utilisés pour prédire les besoins de dotation en personnel et offrir des recommandations appropriées. Par exemple, l'analyse peut être utilisée pour prédire si un groupe de patients vivant dans une zone spécifique, qui sont soumis à des impacts environnementaux variables (tels que la température) et qui montrent certains symptômes peuvent indiquer une épidémie imminente qui obligerait un prestataire à modifier son modèle de dotation en personnel pour gérer l'augmentation du nombre de dossiers prévue.
- Outre l'utilisation d'analyses avancées, les modèles de machine learning sont développés, entraînés et déployés. Ces modèles entraînés peuvent être exécutés à la fois sur les données opérationnelles actuelles et historiques pour détecter les événements et les tendances, comme une insatisfaction croissante de la part du personnel, pouvant entraîner des taux de rotation plus élevés. Ces événements et d'autres résultats peuvent être rendus persistants dans la couche de service et signalés à l'aide d'outils d'analyse tels qu'Oracle Analytics Cloud. Le modèle et les données peuvent également être intégrés dans des systèmes de machine learning, tels qu'OCI Data Science, afin de former davantage les modèles pour recommander des modèles de dotation en personnel plus efficaces avant de les promouvoir. Ces modèles sont accessibles via des API, déployés dans le dépôt de données de service ou intégrés dans le pipeline d'analyses de diffusion en continu OCI GoldenGate.
- Nos règles et politiques de gouvernance peuvent être appliqués à nos données et modèles conservés, testés et de haute qualité, et peuvent être exposés en tant que produit de données (API) au sein d'une architecture de maillage de données à des fins de distribution dans l'ensemble de l'organisme de santé.
Au-delà de la dotation en personnel : utiliser les données pour résoudre d'autres problèmes clés du secteur de la santé
Au-delà de la possibilité offerte à votre service de santé de développer des modèles de dotation en personnel plus précis et améliorés, Oracle Data Platform peut également vous aider à optimiser vos opérations dans d'autres domaines afin d'améliorer les soins aux patients, de réduire vos coûts et d'améliorer l'expérience de vos salariés. Voici quelques exemples.
- Soins globaux et coordonnés pour les groupes de patients cibles.
- Détection à l'avance du risque de défaillance du système en cas de pandémie et intervention de manière proactive pour assurer la réussite du système.
- Surveillance des tendances de la cohorte de patients pour évaluer l'efficacité de leurs programmes de soins.
- Identification des domaines d'utilisation excessive du traitement.
- Suivi de la qualité et du coût de la prestation de soins.
- Création de modèles de stratification des risques pour les patients.
- Prévision du risque de réadmission des patients.
- Recommandation de soins préventifs pour favoriser la prise en charge autonome des patients.
Ressources associées
-
Cas d’utilisation
Optimisation de la chaîne d'approvisionnement des soins de santé
Découvrez comment améliorer la résilience de votre chaîne d'approvisionnement grâce à Oracle Data Platform pour le secteur de la santé.
-
Cas d’utilisation
Gestion des soins de santé au sein de la population
Découvrez comment optimiser la gestion des soins de santé afin de mieux répondre aux besoins de vos patients, d'améliorer vos résultats et de réduire vos coûts grâce à Oracle Data Platform pour la santé.
-
Cas d’utilisation
Améliorez les soins reposant sur la valeur grâce à la surveillance des performances
Découvrez comment simplifier l'évaluation de votre stratégie de soins reposant sur la valeur avec Oracle Data Platform pour le secteur de la santé.
Lancez-vous
Testez plus de 20 services cloud Always Free grâce à une période d'essai de 30 jours pour encore plus de services
Oracle propose une offre gratuite sans limite de temps sur plus de 20 services tels que Oracle Autonomous AI Database, Arm Compute et Storage, ainsi que 300 dollars américains de crédits gratuits pour essayer d'autres services cloud. Obtenez les détails et créez votre compte gratuit dès aujourd’hui.
-
Que comprend Oracle Cloud Free Tier ?
- Deux instances d'Autonomous AI Database de 20 Go chacune
- AMD et Arm Compute VM
- 200 Go de stockage total par blocs
- 10 Go de stockage d'objets
- 10 To de transfert de données sortantes par mois
- Plus de 10 services Always Free
- 300 USD de crédits gratuits pendant 30 heures pour plus de possibilités
Suivez le guide
Découvrez un large éventail de services OCI via des tutoriels et des ateliers pratiques. Que vous soyez développeur, administrateur ou analyste, nous pouvons vous aider à comprendre comment fonctionne OCI. De nombreux ateliers sont disponibles pour Oracle Cloud Free Tier ou dans un environnement d'ateliers gratuits fournis par Oracle.
-
Introduction aux services fondamentaux d'OCI
Les ateliers de cette session présentent les services principaux d'Oracle Cloud Infrastructure (OCI), y compris les réseaux cloud virtuels (VCN) ainsi que les services de calcul et de stockage.
Commencer l'atelier sur les services principaux d'OCI -
Guide de démarrage rapide de Autonomous AI Database
Au cours de cet atelier, vous découvrirez les étapes à suivre pour commencer à utiliser Oracle Autonomous AI Database.
Commencez dès maintenant le laboratoire de démarrage rapide de Autonomous AI Database. -
Créez une application à partir d'une feuille de calcul
Cet atelier vous explique pas à pas comment télécharger une feuille de calcul dans un tableau d'Oracle Database et comment créer ensuite une application à partir de ce nouveau tableau.
Commencer cet atelier
Découvrez plus de 150 modèles de bonnes pratiques
Découvrez comment nos architectes et d’autres clients déploient une large gamme de workloads, des applications d’entreprise au HPC, des microservices aux lacs de données. Comprenez les bonnes pratiques, écoutez d’autres architectes clients de notre série « Développer et Déployer » et déployez même de nombreux workloads avec notre fonctionnalité de déploiement en un clic ou faites-le vous-même à partir de notre dépôt GitHub.
Architectures populaires
- Apache Tomcat avec MySQL Database Service
- Oracle Weblogic sur Kubernetes avec Jenkins
- Environnements de machine learning (ML) et d'IA
- Tomcat sur Arm avec Oracle Autonomous AI Database
- Analyse des journaux avec la pile ELK
- HPC avec OpenFOAM
Découvrez combien vous pouvez économiser sur OCI
La tarification d'Oracle Cloud est simple, avec des tarifs faibles homogènes dans le monde entier et prenant en charge un large éventail de cas spécifiques. Pour estimer votre tarif réduit, consultez l’estimateur de coûts et configurez les services en fonction de vos besoins.
Ressentez la différence :
- 1/4 des coûts de bande passante sortante
- Rapport prix/performances de calcul 3 fois plus élevé
- Tarifs faibles et identiques dans chaque région
- Tarifs faibles sans engagements à long terme
Contactez l’équipe commerciale
Vous souhaitez en savoir plus sur Oracle Cloud Infrastructure ? Laissez l’un de nos experts vous aider.
-
Il peut répondre à des questions telles que :