Consolidation des données d'usine de fabrication

Optimisez l'efficacité et réduisez les risques grâce à des données consolidées en temps réel
De nos jours, les fabricants doivent pouvoir mesurer l'efficacité de leurs lignes de production sur tous leurs sites ; ils doivent être informés immédiatement des problème, il n'est pas question d'attendre cinq ou dix minutes. Cependant, il s'agit également de l'un de leurs plus grands problèmes, car cette capacité repose sur l'accès en temps réel aux données de plusieurs sites distants qui peuvent avoir une connectivité Internet limitée ou sporadique. Pour résoudre ce problème, nous devons propager le machine learning et l'acquisition de données à la périphérie du réseau.
Simplifiez la prise de décision en périphérie
Nous pouvons configurer Oracle Data Platform pour résoudre ce problème en incluant les appareils Oracle Roving Edge (RED). Chaque appareil RED est conçu pour capturer, stocker, exécuter, gérer et obtenir des informations à partir des données, ce qui permet aux fabricants d'automatiser le processus de prise de décision et la gestion des équipements de fabrication en périphérie. Oracle Data Platform pour la fabrication comprend également des fonctionnalités de détection d'anomalies qui peuvent être utilisées pour résoudre les perturbations des lignes de fabrication et fournir des informations liées à la maintenance afin d'améliorer les mesures correctives.
L'architecture suivante démontre comment Oracle Data Platform prend en charge la consolidation des données d'usine en déployant en périphérie des analyses avancées et du machine learning pour identifier les anomalies, effectuer une collecte intelligente de données et fournir des informations opérationnelles en temps réel.
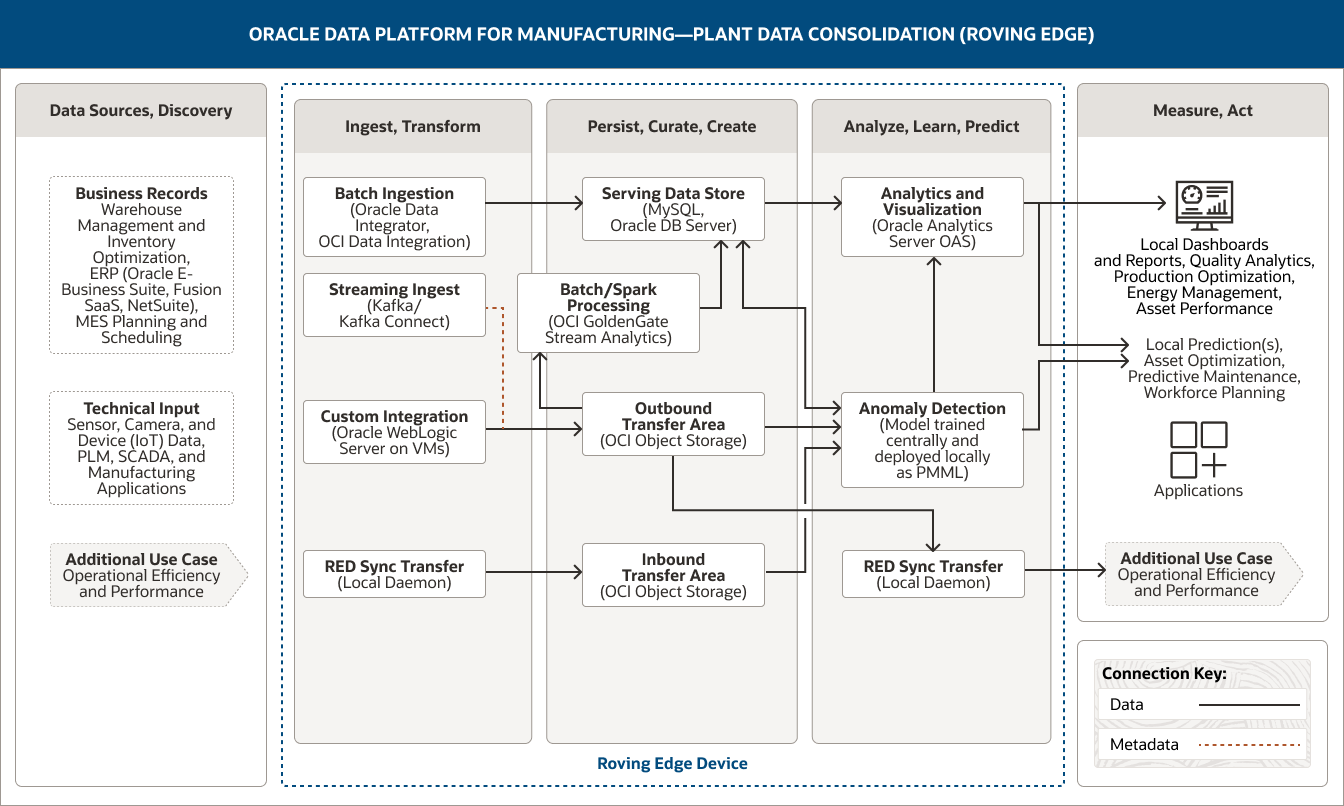
Cette image montre comment utiliser Oracle Data Platform pour la fabrication afin de consolider les données d'usine. La plateforme comprend les cinq piliers suivants :
- 1. Sources de données et repérage
- 2. Ingestion et transformation
- 3. Sauvegarde, tri et création
- 4. Analyses, apprentissage et prévision
- 5. Mesures et réactions
Le pilier « Sources de données et repérage » inclut deux catégories de données.
- 1. Les données des enregistrements métier comprennent les données de gestion des entrepôts et d'optimisation des stocks, les données ERP (Oracle E-Business Suite, Fusion SaaS, NetSuite) et les données de planification MES.
- 2. Les données d'entrée techniques incluent les données des capteurs, des caméras et des appareils (IoT) et les données provenant de PLM, SCADA et des applications de fabrication.
Le pilier « Ingestion et transformation » comprend quatre fonctionnalités.
- 1. L'ingestion par lots utilise Oracle Data Integrator et OCI Data Integration.
- 2. L'ingestion de flux de données utilise Kafka Connect.
- 3. L'intégration personnalisée utilise Oracle WebLogic Server sur les machines virtuelles.
- 4. Le transfert de synchronisation RED utilise un démon local.
L'ingestion par lots se connecte de manière unidirectionnelle au dépôt de données de service
L'inclusion et l'intégration personnalisées de Streaming se connectent de manière unidirectionnelle à la zone de transfert sortant.
En outre, le transfert de synchronisation RED se connecte de manière unidirectionnelle à la zone de transfert entrant.
Le pilier « Sauvegarde, tri et création » comprend quatre fonctionnalités.
- 1. Le dépôt de données de service utilise MySQL et le serveur Oracle DB.
- 2. Le traitement par lots/traitement Spark utilise OCI GoldenGate Stream Analytics.
- 3. La zone de transfert sortant utilise OCI Object Storage.
- 4. La zone de transfert entrant utilise OCI Object Storage.
Ces fonctionnalités sont connectées au sein du pilier. Le traitement par lots/Spark est connecté de manière unidirectionnelle au dépôt de données de service.
La zone de transfert sortant est connectée de manière unidirectionnelle au traitement par lots/Spark.
Trois fonctionnalités sont liées au pilier « Analyses, apprentissage et prévision » :
Le dépôt de données de service se connecte de manière unidirectionnelle à la fonction d'analyse et de visualisation et de manière bidirectionnelle à la fonction de détection d'anomalies. La zone de transfert sortant se connecte de manière unidirectionnelle aux fonctions de détection d'anomalies et de transfert de synchronisation RED.
La zone de transfert entrante se connecte de manière unidirectionnelle à la capacité de détection d'anomalies.
Le pilier « Analyses, apprentissage et prévision » comprend trois fonctionnalités.
- 1. L'analyse et la visualisation utilisent Oracle Analytics Server.
- 2. La détection d'anomalies utilise un modèle entraîné de manière centralisée et déployé localement en tant que PMML.
- 3. Le transfert de synchronisation RED utilise un démon local.
La fonction de détection d'anomalies est connectée de manière unidirectionnelle à la fonction d'analyse et de visualisation dans le pilier.
Trois fonctionnalités sont liées au pilier « Mesures et réactions ». La fonction d'analyse et de visualisation est connectée de manière unidirectionnelle aux tableaux de bord et rapports locaux, ainsi qu'aux prédictions locales. La fonction de détection d'anomalies est connectée de manière unidirectionnelle aux prédictions locales et la fonction de transfert de synchronisation RED est connectée de manière unidirectionnelle à un autre cas d'utilisation.
Le pilier « Mesure et réactions » saisit la façon dont les données d'usine consolidées peuvent être utilisées. Ces utilisations potentielles sont divisées en quatre groupes.
- Le premier groupe comprend des tableaux de bord et des rapports locaux.
- Le second groupe comprend des prédictions locales.
- Le troisième groupe comprend les applications.
- Le quatrième groupe contient un cas d'utilisation supplémentaire, à savoir l'efficacité opérationnelle et les performances.
Les trois piliers centraux : « Ingestion et transformation», « Sauvegarde, tri et création » et « Analyses, apprentissage et prévision » sont pris en charge par les appareils Oracle Roving Edge.
Il existe quatre principales façons d'injecter des données dans une architecture pour permettre aux fabricants de comprendre facilement l'efficacité opérationnelle et les performances.
- Une intégration personnalisée d'Oracle Integration Repository nous permet d'intégrer des données, structurées et non structurées, à partir de différentes sources, pour des interactions avec les appareils, des API personnalisées, etc. Les données peuvent être ingérées à partir de n'importe quel type de développement d'applications (par exemple, code Java ou Python autonome, applications reposant sur Oracle WebLogic Server ou applications reposant sur Kubernetes). Les données seront stockées dans le stockage d'objets pour plus d'affinement, pour un transfert sortant ou pour alimenter les modèles d'IA.
- La synchronisation de données RED est un moyen simple et efficace de transférer des modèles de ML d'un emplacement central (par exemple, votre référentiel de stockage d'objets pour les modèles entraînés dans Oracle Cloud Infrastructure (OCI)) vers la périphérie. Dans ce cas d'utilisation, la définition de bord aurait le RED colocalisé avec d'autres machines au sein de l'usine elle-même. Les nouvelles versions des modèles sont stockées au format PMML (Predictive Model Markup Language) autonome. Le démon local effectue une mise à jour lorsqu'un nouveau modèle est détecté et le propage automatiquement vers l'appareil RED. La synchronisation de données RED est également un excellent moyen de transférer toutes les données collectées par différents services RED tout au long de la journée (par exemple, les anomalies pertinentes, les signaux, etc.) vers votre emplacement central, le plus susceptible de stocker des objets sur OCI. Ces données seront ensuite utilisées pour la création de rapports opérationnelle et l'entraînement des modèles de machine learning. Le volume de données impliquées dans ces processus de synchronisation de données RED déterminera vos besoins en matière de télécommunications de centre de données ou de bande passante satellite.
- L'ingestion par lots utilise Oracle Data Integrator, une solution complète d'intégration de données qui répond à tous les besoins d'intégration de données, des chargements par lots à haut volume et hautes performances aux processus d'intégration de flux d'activités reposant sur des événements et aux services de données compatibles SOA. Alors que les besoins en temps réel évoluent, l'extraction la plus courante des systèmes ERP, de planification, de gestion des entrepôts et de gestion des transports est une ingestion par lots à l'aide d'un processus d'extraction, de transformation et de chargement ou d'extraction, de chargement et de transformation. Ces extraits peuvent être fréquents, aussi souvent que toutes les 10 à 15 minutes, mais ils sont toujours de nature globale lorsque les transactions sont extraites et traitées par groupes plutôt qu'individuellement. OCI propose différents services pour gérer l'ingestion par lots, tels que le service OCI Data Integration natif ou Oracle Data Integrator exécuté sur une instance OCI Compute. Selon les volumes et les types de données, les données peuvent être chargées dans le stockage d'objets ou directement dans une base de données relationnelle structurée pour le stockage persistant.
- L'analyse des données en temps réel à partir de plusieurs sources peut aider les fabricants avec des informations précieuses sur leur efficacité opérationnelle et leurs performances globales. Oracle Data Platform utilise l'ingestion de flux pour assimiler des flux de données provenant de plusieurs systèmes de niveau 2 ISA-95, tels que les systèmes SCADA (contrôle de supervision et acquisition de données), les contrôles de logique programmables et les systèmes d'automatisation par lots. La transmission de données en continu (événements) sont ingérées et certaines transformations/agrégations de base sont effectuées avant d'être stockées dans le stockage d'objets. Des analyses de diffusion peuvent être utilisées pour détecter les corrélations dans les événements et des modèles identifiés peuvent être renvoyés (manuellement) pour un examen des données brutes réalisé grâce à la science des données. Alors que les outils d'analyse traditionnels extraient des informations à partir de données au repos, l'analyse en continu évalue la valeur des données en mouvement, c'est-à-dire en temps réel.
La persistance et le traitement des données reposent sur trois composants.
- Dans le dépôt de données de service, les données sont gérées par Oracle Database Server ou par MySQL pour le traitement des données. Le dépôt de données de service fournit un niveau relationnel persistant souvent utilisé pour fournir des données directement aux utilisateurs finaux via des outils SQL. Il sert également de couche de service pour les analyses spécialisées.
- Toutes les données extraites des sources de données sous sa forme brute (en tant qu'extraction ou fichier natif) sont saisies et chargées dans le stockage d'objets afin d'être utilisées dans l'entraînement du modèle de machine learning actuel ou futur. Le stockage d'objets cloud est la couche de persistance des données la plus courante pour notre plateforme de données. Il sert à la fois de zone de transfert entrant et de zone de transfert sortant. Il peut être utilisé pour des données structurées et non structurées.
- Avec le stockage d'objets en tant que niveau de persistance des données principal, OCI GoldenGate Stream Analytics est le moteur de traitement principal. Le traitement par lots implique plusieurs activités, notamment le traitement du bruit de base, la gestion des données manquantes et le filtrage des jeux de données sortants définis. Les résultats sont réécrits dans différentes couches de stockage d'objets ou dans un référentiel relationnel persistant en fonction du traitement nécessaire et des types de données utilisés.
La capacité d'analyser, d'apprendre et de prévoir repose sur deux technologies.
- Les services d'analyse et de visualisation fournissent des analyses descriptives (descriptions des tendances actuelles avec des histogrammes et des graphiques), des analyses prédictives (prédiction des événements, identification des tendances et détermination des probabilités de résultats incertains) et des analyses prescriptives (propositions d'actions appropriées conduisant à une prise de décision optimale). Oracle Analytics Server fournit les fonctionnalités nécessaires pour fournir des analyses descriptives liées aux rapports opérationnels et aux analyses prescriptives. En outre, les modèles de machine learning peuvent être intégrés directement dans le flux de données d'Oracle Analytics Server. Oracle Analytics Server est conçu pour être exécuté sur site et fournit des tableaux de bord, des rapports, des alertes, une préparation de données en libre-service et des algorithmes de machine learning orientés utilisateur final. Oracle Data Platform pour la fabrication est entièrement ouvert et flexible. Par conséquent, si vous le souhaitez, vous pouvez utiliser des outils tiers à la place.
- Outre l'utilisation d'analyses avancées, des modèles de machine learning sont développés, entraînés et déployés pour prendre en charge la détection des anomalies. OCI Anomaly Detection est un service d'IA à destination des développeurs pour faciliter la création de modèles de détection d'anomalies spécifiques à l'entreprise qui signalent les incidents critiques, accélérant ainsi la détection et la résolution. Ces modèles sont entraînés à l'emplacement central et déployés au format PMML pour être exécutés localement en tant que code Java ou Python.
Automatisez la prise de décision pour augmenter la rentabilité
Oracle Data Platform permet aux fabricants de tirer le meilleur parti de toutes leurs données disponibles tout en simplifiant et en rationalisant l'accès aux données et le stockage. La possibilité de propager la collecte de données et l'évaluation du machine learning vers la périphérie via les appareils Oracle Roving Edge aide les fabricants à prendre de meilleures décisions commerciales éclairées par des données précises toujours disponibles quand ils en ont besoin, leur permettant d'augmenter l'efficacité et la production tout en réduisant les coûts.
Ressources associées
-
Cas d’utilisation
Utilisez les données pour améliorer la santé et la sécurité au travail
Découvrez comment rendre les opérations de production plus sûres à l'aide d'une plateforme de données qui vous aide à améliorer la santé et la sécurité grâce à des analyses avancées.
-
Cas d’utilisation
Utilisez les données pour améliorer l'efficacité opérationnelle et les performances de production
Découvrez comment gérer plus efficacement les opérations de production à l'aide d'une plateforme de données qui améliore les performances grâce au machine learning.
-
Cas d’utilisation
Utilisez vos données pour passer de la maintenance réactive à la maintenance prédictive
Découvrez comment optimiser vos ressources grâce à la maintenance prédictive avec une plateforme de données et du machine learning.
Lancez-vous
Testez plus de 20 services cloud Always Free grâce à une période d'essai de 30 jours pour encore plus de services
Oracle propose une offre gratuite sans limite de temps sur plus de 20 services tels que Oracle Autonomous AI Database, Arm Compute et Storage, ainsi que 300 dollars américains de crédits gratuits pour essayer d'autres services cloud. Obtenez les détails et créez votre compte gratuit dès aujourd’hui.
-
Que comprend Oracle Cloud Free Tier ?
- Deux instances d'Autonomous AI Database de 20 Go chacune
- AMD et Arm Compute VM
- 200 Go de stockage total par blocs
- 10 Go de stockage d'objets
- 10 To de transfert de données sortantes par mois
- Plus de 10 services Always Free
- 300 USD de crédits gratuits pendant 30 heures pour plus de possibilités
Suivez le guide
Découvrez un large éventail de services OCI via des tutoriels et des ateliers pratiques. Que vous soyez développeur, administrateur ou analyste, nous pouvons vous aider à comprendre comment fonctionne OCI. De nombreux ateliers sont disponibles pour Oracle Cloud Free Tier ou dans un environnement d'ateliers gratuits fournis par Oracle.
-
Introduction aux services fondamentaux d'OCI
Les ateliers de cette session présentent les services principaux d'Oracle Cloud Infrastructure (OCI), y compris les réseaux cloud virtuels (VCN) ainsi que les services de calcul et de stockage.
Commencer l'atelier sur les services principaux d'OCI -
Guide de démarrage rapide de Autonomous AI Database
Au cours de cet atelier, vous découvrirez les étapes à suivre pour commencer à utiliser Oracle Autonomous AI Database.
Commencez dès maintenant le laboratoire de démarrage rapide de Autonomous AI Database. -
Créez une application à partir d'une feuille de calcul
Cet atelier vous explique pas à pas comment télécharger une feuille de calcul dans un tableau d'Oracle Database et comment créer ensuite une application à partir de ce nouveau tableau.
Commencer cet atelier
Découvrez plus de 150 modèles de bonnes pratiques
Découvrez comment nos architectes et d’autres clients déploient une large gamme de workloads, des applications d’entreprise au HPC, des microservices aux lacs de données. Comprenez les bonnes pratiques, écoutez d’autres architectes clients de notre série « Développer et Déployer » et déployez même de nombreux workloads avec notre fonctionnalité de déploiement en un clic ou faites-le vous-même à partir de notre dépôt GitHub.
Architectures populaires
- Apache Tomcat avec MySQL Database Service
- Oracle Weblogic sur Kubernetes avec Jenkins
- Environnements de machine learning (ML) et d'IA
- Tomcat sur Arm avec Oracle Autonomous AI Database
- Analyse des journaux avec la pile ELK
- HPC avec OpenFOAM
Découvrez combien vous pouvez économiser sur OCI
La tarification d'Oracle Cloud est simple, avec des tarifs faibles homogènes dans le monde entier et prenant en charge un large éventail de cas spécifiques. Pour estimer votre tarif réduit, consultez l’estimateur de coûts et configurez les services en fonction de vos besoins.
Ressentez la différence :
- 1/4 des coûts de bande passante sortante
- Rapport prix/performances de calcul 3 fois plus élevé
- Tarifs faibles et identiques dans chaque région
- Tarifs faibles sans engagements à long terme
Contactez l’équipe commerciale
Vous souhaitez en savoir plus sur Oracle Cloud Infrastructure ? Laissez l’un de nos experts vous aider.
-
Il peut répondre à des questions telles que :