グラフデータベースとは
2024年11月5日

グラフデータベースは、人、場所、出来事の間の関係性を明らかにします。この特長により、マッピング、製品レコメンデーション、不正検知など、さまざまな用途で重宝されています。最近では、AIシステムがグラフを活用することで、出力結果にさらなる文脈や細やかなニュアンスを加えるようになっています。グラフデータベースがどのような仕組みで機能し、その独自の能力を最大限に引き出すにはどうすればよいか、詳しく見ていきましょう。
グラフデータベースとは
グラフデータベースは、複雑に関連したデータを保存し、検索できるよう設計されたデータベースです。これは、エンティティをノードとして格納および表し、関係をエッジとして表すことによって機能します。このグラフ状の構造により、データ同士の複雑なつながりを簡単に見つけたり分析したりできる点が特徴です。
現在、市場にはさまざまなグラフデータベースが存在します。Neo4jのようにグラフデータ専用の製品もあれば、Oracle AI Databaseのようにグラフ含む複数のデータモデルに対応したマルチモーダルなエンタープライズ・データベースもあります。従来のリレーショナル・データベースでは、データは表の形で保存し、関係性を確認するには複雑な結合処理が必要でした。しかしグラフデータベースでは、最初から「関係」もデータベースの基本要素として組み込まれるため、Cypher、Gremlin、PGQL、SQLなどの言語を使用して直接問いかけることができます。
グラフデータベースは、データ同士の関係性が複雑だったり、よく変わる場面で特に威力を発揮します。たとえば、最適なルートを割り出すために多くの要因が絡み合うルーティングや物流システム、あるいは、レコメンデーションのためにユーザー、グループ、関心事の間の複雑なつながりを把握する必要があるソーシャルメディア・ネットワークなどのユースケースで人気があります。さらに最近ではGraph RAGアーキテクチャの利用も増えており、よりタイムリーで関連性が高く、微妙なニュアンスまで反映した出力を実現するために、AIシステムでもグラフデータベースを活用しています。
主なポイント
- グラフデータベースは、データ同士の関係や依存関係を効率的に調べる手段を提供します。
- データをノードおよびエッジとして格納することで、グラフ・データベースにより、接続されたエンティティ間の迅速なナビゲーションおよび関連データの高速取得が可能になります。
- グラフデータベースは、セマンティックWebアプリケーション、詐欺検出、SNS、小売やエンタメ分野のレコメンドシステムなど、さまざまな用途で利用されています。
- グラフデータベースは、Graph RAGアーキテクチャを使用してより細やかなニュアンスを含んだ正確な出力を導き出すAIシステムでも活用されています。
グラフデータベースの解説
グラフデータベースは、データの関係性を表現するためにグラフモデルを使用します。これにより、ユーザーは、基本的に既存の接続に沿ってデータ・セットを横断してデータ・ポイント間の(間接的な)関係を見つける「トラバーサル問合せ」と呼ばれるものを実行できます。その後、データベースはグラフアルゴリズムを適用し、パターン、パス(経路)、コミュニティ、インフルエンサー、単一障害点、その他の関係性を特定します。グラフの強みは、非常に大規模で多様なデータセットであっても、異質なデータソース同士を結びつけて新しい洞察を見つけ出せる能力にあります。
グラフアルゴリズムは、グラフ内のデータ間の関係性や動作を分析するために特別に設計されており、通常の手法では見つけにくい関係性も明らかにできます。たとえば、グラフアルゴリズムを使用すれば、ソーシャルネットワークやビジネスプロセスにおいて、どの個人やアイテムが他の要素と最も強くつながっているかを特定できます。また、「コミュニティ」、「異常」、「共通のパターン」、さらには特定の個人や一連の取引を結びつける「経路(パス)」などを抽出することも可能です。
これらの洞察を得るために、アルゴリズムは「頂点」間のパスや距離、そしてその重要性やクラスタリングを探索します。「頂点」とは、データセット内のエンティティを表すデータポイントのことです。その重要性を判断するために、アルゴリズムは多くの場合、入力される「エッジ」や隣接する「頂点」の重要性、その他の指標を確認します。グラフデータベースは、これらの関係性をノードと共にデータとして直接保存するため、関連する情報を素早く検索・取得できます。また、グラフデータベースはスキーマの柔軟性が高い傾向にあり、関係性の変化に合わせてデータモデルを柔軟に進化させることができます。
グラフデータベースの仕組み
グラフデータベースは、ノード(たとえば口座や取引などのエンティティ)と、それらをつなぐエッジ(関係)からなるネットワークとして情報を保存します。データベースに対しクエリを実行する際は、事前に定義されたエッジをたどって、ノードからノードへと移動しながら、特定のパターンや経路を見つけ出します。
以下の画像は、グラフデータベースの仕組みを表すシンプルな例です。これは「ケビン・ベーコンの6次隔たり(Six Degrees of Kevin Bacon)」という有名なパーティーゲームを視覚化したものです。このゲームは、俳優のベーコンと他の俳優の間に、共演した映画を通じてつながりを作るというものです。グラフ分析が「関係性」に注目していることを説明するには、まさにうってつけの例といえます。
ケビン・ベーコンが出演したすべての映画と、それらの映画に出演した全俳優という、2つのカテゴリのノードを含むデータセットを想像してみてください。そして、グラフ技術を使用して「マペットの人気キャラクターであるミス・ピギーと、ベーコンをどのようにつなぐか」といったクエリを実行すると、結果は次のようになります。
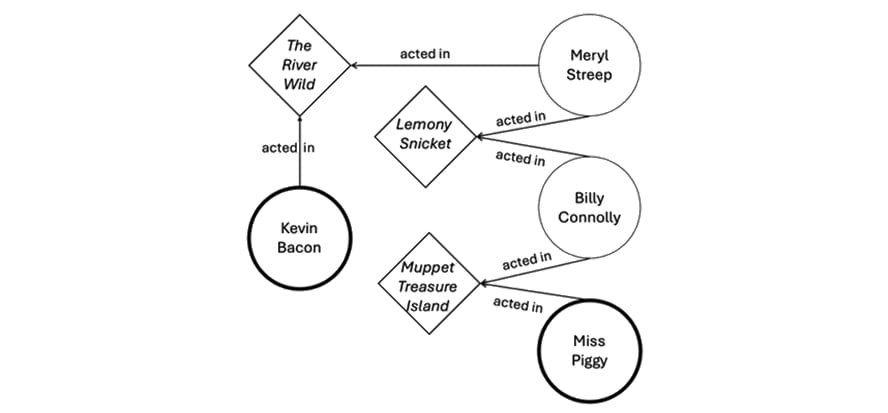
この例では、利用可能なノード(頂点)は俳優と映画の両方であり、関係性(エッジ)は「出演した」というステータスです。ここから、クエリは次の結果を返します。
- ベーコンは、メリル・ストリープと『The River Wild』で共演した。
- ストリープは、ビリー・コノリーと『A Series of Unfortunate Events』で共演した。
- コノリーは、ミス・ピギーと『Muppet Treasure Island』で共演した。
グラフデータベースを使用すれば、次のようなさまざまな関係性を調べるクエリも実行できます。
- 「ケビン・ベーコンとミス・ピギーを結ぶ最短の経路は?」
答え: 最短経路分析(例:上記の6次の隔たりゲーム)を使います。 - 「最も多くの俳優と共演したのは誰か?」
答え: 次数中心性という手法で、最も共演数が多い俳優を特定できます。 - 「ケビン・ベーコンと他のすべての俳優との平均的な距離はどのくらいか?」
答え: 近接中心性を使うことで、映画業界の俳優同士のつながりの強さが分かります。
もちろん、これはグラフ分析としてはユニークで面白い例ですが、このアプローチ自体はほとんどすべてのデータに適用できます。つまり、大量のレコードが自然な「つながり」を持つ状況であれば、同じ考え方で分析できます。グラフ分析の代表的な用途としては、SNSやコミュニケーションネットワークの分析、Webサイトのトラフィックや利用状況の分析、金融取引や口座の分析などがあります。
グラフを使用したグラフデータベース
グラフを作成するには、まずノードとエッジを特定してデータモデルを定義します。その後、SQLやオラクルのPGQLなどのクエリ言語、あるいはCypherやGremlinといったオープンソースツールを使用して、グラフデータベースにデータを挿入します。
グラフデータベースとグラフ分析
データベースは、グラフデータをたどってパターンや関係性を見つけるアルゴリズムをサポートすることで、グラフ分析を可能にします。代表的な例として、幅優先探索(BFS)や深さ優先探索(DFS)があります。さらに、グラフデータベースには、中心性の指標やコミュニティ検出など、グラフ分析のための機能があらかじめ組み込まれていることも多くあります。一部のデータベースでは、頂点やエッジの削除、グループ化、拡大、フォーカス(絞り込み)といった操作を素早く実行できるため、ビジュアライゼーション(可視化)を調整しながら、複雑なグラフデータ内の関係性を探索することが可能です。
グラフデータベースの利点
グラフデータベースは、データポイント間の関係性を重視しているため、複雑な相関関係を効率的に分析でき、より少ない労力で、より深く本質的な洞察を導き出すことができます。具体的なメリットは以下の通りです。
- ネットワーク分析の向上: グラフは、最も多くのアクティビティや影響を生み出しているノードを即座に特定したり、ネットワーク内の最も脆弱な箇所を見つけ出したりできるため、ネットワークやコミュニティの状態分析に役立ちます。
- 1秒未満の高速分析: グラフデータベースは関係性を明示的に保存しているため、クエリやアルゴリズムは頂点間のこの接続性を利用し、1秒に満たない短時間で処理を実行できます。これに対し、従来のデータベースで同じ結果を得ようとすると、膨大な数の「結合」を実行する必要があり、数時間から数日かかる場合もあります。
- 幅広いユースケース: グラフを使用することで、ソーシャルネットワーク、IoTセンサーの出力、データレイク、データウェアハウスなどにおけるつながりやパターンを検索・発見できます。また、銀行業務での不正検知、製造工程における依存関係の特定、小売システムでのレコメンデーションなど、複数のビジネスユースケースにおいて、複雑な取引データを迅速に分析することが可能です。
グラフデータベースの効果的な活用
人、場所、出来事、資金、その他あらゆるデータポイント間の関係性やつながりを素早く理解できることは、幅広いビジネスや行政の活動において極めて重要です。その理由を、いくつかの例で見てみましょう。
グラフデータベースのユースケース
グラフデータベースは、データポイント間の「関係性」の重要性を共通項として、幅広い業界で使用されています。ユースケースには以下のようなものがあります。
-
ソーシャルメディアの分析: SNSは、多くのノード(ユーザーアカウント)との多次元的なつながり(多方向へのエンゲージメント)を伴うため、理想的なユースケースとなります。SNSのグラフ分析では、「ユーザーはどれくらいアクティブか(ノード数)」、「どのユーザーが最も大きな影響力を持つか(つながりの密度)」、「相互のやり取りが最も多いのは誰か(つながりの方向と密度)」といった要素を特定できます。しかし、ボットによってこれらの情報が不自然に歪められている場合、分析結果は役に立ちません。
ソーシャルメディア・ネットワークは、ユーザー・エクスペリエンス全体に悪影響を及ぼすボットアカウントの排除に全力を挙げています。幸いなことに、グラフ分析はボットを識別して除外する優れた手段となります。実際のユースケースとして、オラクルのチームはOracle Marketing Cloudを使用して、ソーシャルメディア広告とその反響を評価し、特にボットの特定に取り組みました。これらのボットによる最も一般的な動作は、ターゲット・アカウントからのコンテンツの再投稿することであり、その結果、それらの高いを人為的に膨らませました。シンプルなパターン分析により、リポスト数と周囲とのつながりの密度が明らかになりました。自然に人気のあるアカウントは、ボットによって作られたアカウントと比較して、周囲との関係性に明確な違いが見られました。
この画像は、自然に人気のあるアカウントを示しています。
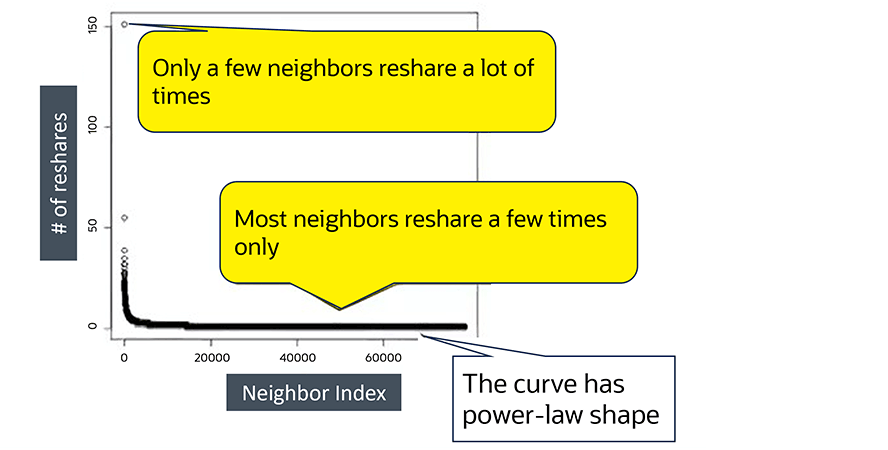 実在するSNSアカウントをシンプルな曲線グラフで見ると、ほとんどのフォロワー(隣接ノード)はコンテンツを数回だけリポストするという、べき乗則分布に従った形状を示します。
実在するSNSアカウントをシンプルな曲線グラフで見ると、ほとんどのフォロワー(隣接ノード)はコンテンツを数回だけリポストするという、べき乗則分布に従った形状を示します。この画像は、ボットによるアカウントの動作を示しています。
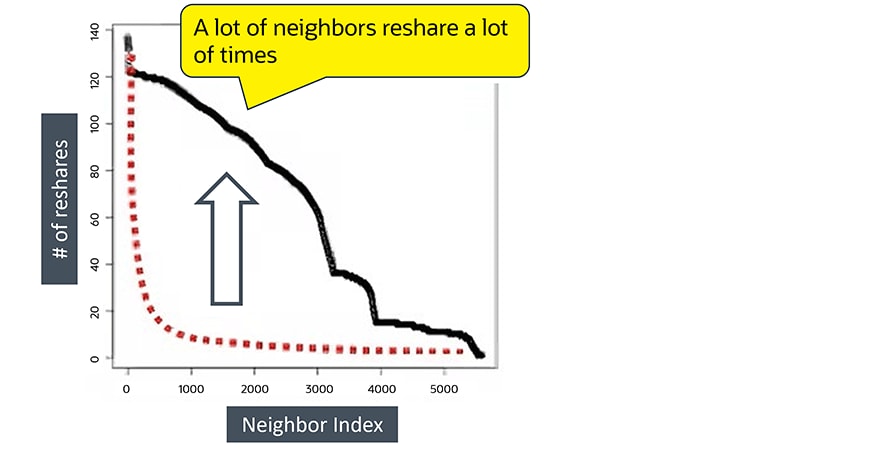 ボットアカウントの活動をシンプルな曲線グラフで見ると、何度もリポストを繰り返すフォロワー(隣接ノード)の数が極端に多いため、ボットアカウントを容易に特定できます。
ボットアカウントの活動をシンプルな曲線グラフで見ると、何度もリポストを繰り返すフォロワー(隣接ノード)の数が極端に多いため、ボットアカウントを容易に特定できます。グラフ分析によって「自然なパターン」と「ボットのパターン」を判別できたら、あとはそれらのアカウントをフィルタリングして除外するだけです。さらに踏み込んで、ボットとリポスト対象アカウントの間にどのような関係があるかを詳しく調べることも可能です。このボット検出プロセスが正確であることを確認するため、フラグが立てられたアカウントを1か月後にチェックしたところ、結果は次のとおりでした。
- 停止:89%
- 削除:2.2%
- 今もアクティブ:8.8%
ペナルティの対象となったアカウントの割合が91.2%という極めて高い数値であったことは、パターン識別の正確さを証明しています。こうした複雑なパターンの特定は、一般的な表形式のデータベースでは大幅に長い時間がかかりますが、グラフ分析なら短時間で実行できます。
クレジットカード不正の追跡: グラフデータベースは、金融業界において不正を検知するための強力なツールとなっています。カードへのICチップの埋め込みといった技術の進歩にもかかわらず、不正の手口は依然として多様です。例えば、スキミング装置を使って磁気ストライプから情報を盗み出す手法は、チップリーダーがまだ導入されていない場所で今も一般的に使われています。盗み出された情報は、偽造カードに書き込まれ、商品の購入や現金の引き出しに悪用されます。
不正検知において、パターン識別は多くの場合、最初の防御線となります。普段の購入パターンは、場所、頻度、店舗の種類、その他ユーザープロファイルに合う要素をもとに判断します。そこに異常が見られた場合、たとえば、普段はほとんどサンフランシスコ・ベイエリア内で活動している人が、突然フロリダで深夜に買い物をしたようなケースでは、システムが潜在的な不正としてフラグを立てます。こうした判定に必要な計算は、ノード間の関係からパターンを見つけるのが得意なグラフ分析を使うことで、大幅にシンプルになります。このケースでは、ノードの種類を口座(カード保有者)、購入場所、購入カテゴリ、取引、端末として定義します。これにより、自然な行動パターンを簡単に特定できます。たとえば、ある1か月の行動としては次のようなものが挙げられます。
- 複数のペットショップ(決済端末)でペットフード(購入カテゴリ)を購入する
- 特定の地域(購入場所)で、週末にレストランの支払い(取引メタデータ)をする
- 地元のホームセンター(アカウント所在地、購入場所)で修理用資材(購入カテゴリ)を購入する
不正検知は通常、機械学習で対応しますが、グラフ分析を組み合わせることで、より正確で効率的なプロセスに補強できます。関係性に焦点を当てることで、不正なレコードを特定し、フラグを立てるための効果的な予測指標を得ることができます。
マネーロンダリングの追跡: グラフデータベースは、より高度な不正対策にも役立ちます。たとえば、マネーロンダリングは概念的にはシンプルです。不正に得た現金を、正当な資金に紛れ込ませるように何度も動かし、最終的に実物資産に換える、という流れです。より具体的には、「循環送金」と呼ばれる手口があります。これは犯罪者が不正に得た多額の資金を最終的に自分自身に送るものですが、その過程を隠すために、合成IDで作られた「通常のアカウント」間で、長くて複雑な一連の正当な送金を繰り返します。これらのアカウントは、多くの場合、似通った情報を共有しています。そのため、不正な資金の出どころを明らかにするのにグラフ分析が非常に役に立ちます。不正検知を効率化するために、金融機関は口座間の取引をもとにグラフを作成できます。グラフが作成されれば、シンプルなクエリを実行するだけで、互いに送金し合っていて、かつメールアドレス、住所、電話番号などの情報が酷似している口座を持つすべての顧客を即座に見つけ出すことができます。
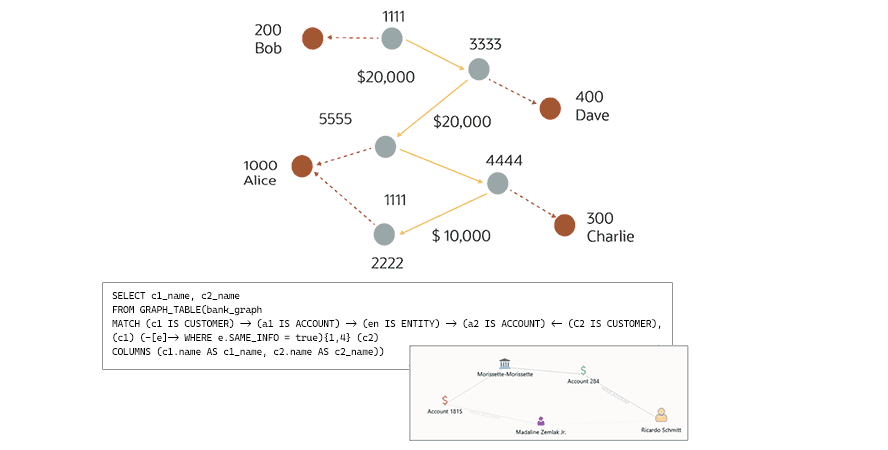 マネーロンダリング検知のためのグラフデータベース・クエリを説明する図。資金移動によって結びついた顧客と口座の視覚的なマップと、それに対応するSQLコード(PGQL)が示されています。
マネーロンダリング検知のためのグラフデータベース・クエリを説明する図。資金移動によって結びついた顧客と口座の視覚的なマップと、それに対応するSQLコード(PGQL)が示されています。この例は、グラフデータベースでシンプルなクエリを実行するだけで、互いに送金し合っていて、なおかつ似た顧客情報を持つ口座を持つ顧客を洗い出し、マネーロンダリングの疑いを発見できることを示しています。
グラフデータベースの未来
この10年間、コンピューティング・パワーの向上とデータ量の増大に伴い、グラフデータベースとグラフ技術は大きく進化を遂げてきました。その結果、複雑に絡み合うデータの関係性を分析するうえで、今後ますます重要なツールになることが明らかになっています。企業や組織がデータ活用と分析力をさらに高めていく中で、より複雑な形でインサイトを引き出せるグラフデータベースは、いま必要とされる基盤であり、将来の成功にも欠かせない存在になっていくでしょう。
適切なグラフデータベースの選び方
グラフデータベースには、「プロパティグラフ」と「RDFグラフ(一般にナレッジグラフとも呼ばれます)」という2つの主要なモデルがあります。ニーズに合わせて適切なものを選択する場合、プロパティ・グラフは分析と問合せに重点を置き、RDFグラフはデータ統合とセマンティック検索に重点を置いていることを覚えておくと役立ちます。どちらのタイプも、点の集合(頂点)とそれらの点をつなぐもの(エッジ)で構成されています。グラフデータ内で特定された関係性の意味や文脈を表現するナレッジグラフは、人工知能(AI)の分野でますます重要性が高まっています。
プロパティグラフ: プロパティグラフは、データ間の関係性をモデル化するために使用され、それらの関係性に基づいたクエリやデータ分析を可能にします。プロパティグラフには、主体に関する詳細情報を含む頂点と、頂点間の関係を示すエッジがあります。頂点とエッジには「プロパティ」と呼ばれる属性を持たせ、関連付けることができます。
この例では、同僚のグループとその関係性をプロパティグラフとして表現しています。ここでは、同僚同士がどのように協力し合っているか、あるいは対立しているかを示しています。さらに、同僚の役割、居住都市、リモートワーカーかどうか、部門情報といったプロパティも付けることができます。

プロパティグラフはその汎用性の高さから、金融、製造、公共安全、小売など、さまざまな業界や部門で使用されています。
RDFグラフ: Resource Description Framework(RDF)グラフは、一連のW3C(World Wide Web Consortium)標準規格に準拠しており、「文(ステートメント)」を表現するように設計されています。複雑なメタデータやマスターデータの表現に最適で、リンクトデータ、データ統合、そして近年ではナレッジグラフによく使用されています。ある分野の複雑な概念を表現したり、データに豊かなセマンティクスを付与し、推論を可能にします。
RDFモデルでは、1つの文を3つの要素で表します。主語、述語、目的語に相当する形で、2つの頂点がエッジで結ばれ、これをRDFトリプルと呼びます。各頂点とエッジはURI(Uniform Resource Identifier)で識別されます。RDFモデルは、明確に定義されたセマンティクスを持つ標準形式でデータを公開する方法を提供し、情報交換を可能にします。RDFグラフは、政府の統計機関、製薬会社、医療機関などで広く採用されています。
さらに、インテリジェントなアプリケーションを支える基盤として、RDFグラフの人気が高まっています。多くの大規模言語モデル(LLM)は、DBpediaのような公開データセットのRDFグラフ表現を学習に活用しています。
グラフデータベースとグラフ分析を始めるには
オラクルは、グラフ技術を導入しやすい形で提供しています。Oracle AI DatabaseとOracle Autonomous AI Databaseには、統合されたグラフデータベースとグラフ分析エンジンが備わっており、グラフ・アルゴリズム、パターンマッチング・クエリ、ビジュアライゼーションを使ってデータからより多くのインサイトを引き出せます。グラフは、オラクルのコンバージド・データベースの一部であり、単一のデータベース・エンジンでマルチモーダル、マルチワークロード、マルチテナントのすべての要件に対応します。Oracle Graphは、単一のデータベース内でプロパティ・グラフとRDFグラフの両方のモデルをサポートし、SQLを使用したグラフ分析をサポートします。
多くのグラフデータベースが高性能を謳う中で、オラクルのグラフ製品は、クエリとアルゴリズムの両面で優れた性能を発揮し、Oracle AI Databaseとも緊密に統合されています。これにより、開発者は既存アプリケーションにグラフ分析を無理なく追加でき、データベースが標準で備えるスケーラビリティ、一貫性、リカバリ、アクセス制御、セキュリティもそのまま活用できます。Oracle AI Databaseは、まさに「エンタープライズのためのグラフデータベース」です。
データ内の人、場所、出来事、モノの関係性を理解したい場合、グラフデータベースに勝るツールはありません。この価値は、最新のAIシステムでの採用が進んでいることからも明らかです。データをノードとエッジとして捉えるグラフデータベースによって、AIシステムは関係性をより効果的にたどって分析できるようになります。その結果、より深い洞察と、より正確な意思決定が可能になります。今後数年で、企業や政府機関でAIやAIエージェントの活用がさらに進むにつれ、グラフデータベースの重要性は一段と高まっていくでしょう。

リソースを大量に消費するクエリを、どこで実行するのが最適か。その答えは、複雑に絡み合うデータを最大限に活用するために必要な、卓越したパフォーマンスとAI能力を備えた「ハイパースケール・クラウド」にあります。
グラフデータベースに関するよくある質問
グラフデータベースは何に役立ちますか?
グラフデータベースは、データポイントを「ノード」と「エッジ」として表現し、保存やクエリができるように設計されています。これにより、データ内のパターンや関係性に関する洞察を明らかにすることができます。そのため、SNS、リコメンデーションシステム、不正検知といった、データ同士が密接に関連し合うアプリケーションで特に力を発揮します。
グラフデータベースはAIに使用されますか?
グラフデータベースは、AIアプリケーションでも広く使われています。複雑に関連し合うデータ内の関係性を効率的にクエリできるという利点を活かし、AIによるレコメンデーションシステムの強化や、ナレッジグラフの生成に役立てられています。これにより、AIモデルはテキストやその他のコンテンツをより深く理解するためのセマンティクスを得ることができます。
グラフデータベースはリレーショナルデータベースと同じですか?
グラフデータベースとリレーショナルデータベースは、データの関係性を保存・管理するアプローチが異なります。リレーショナルデータベースは、表と外部キーでデータ同士を関連付けるため、深く相互接続されたデータを扱う場合、結合が複雑になりがちです。一方、グラフデータベースはデータをノードとエッジとして扱うため、関係性をたどる処理や検索を効率よく行えます。そのため、SNS、小売のレコメンデーションエンジン、不正検知システムなど、複雑でつながりの多いデータを扱う用途に適しています。