ストリーミングに関するFAQ
一般的な質問
Oracle Cloud Infrastructure Streamingとは何ですか。
Oracle Cloud Infrastructure(OCI)Streamingは、フルマネージドでスケーラブルな耐久性のあるメッセージソリューションであり、リアルタイムで消費および処理できるデータの継続的で大量のストリームを取り込みます。Streamingは、サポートされているすべてのOracle Cloud Infrastructureリージョンで利用できます。リストについては、リージョンと可用性ドメインに関するページを参照してください。
Streamingを使用する理由は何ですか。
Streamingは、ネットワークからストレージに至るまでのインフラストラクチャ管理と、データのストリーミングに必要な構成をオフロードするサーバーレスサービスです。インフラストラクチャのプロビジョニング、継続的なメンテナンス、セキュリティパッチについて心配する必要はありません。Streamingサービスは、3つの可用性ドメイン間でデータを同期的に複製し、高可用性とデータの耐久性を実現します。単一の可用性ドメインを持つリージョンでは、データは3つのフォールト・ドメインに複製されます。
Streamingの使用方法を教えてください。
Streamingにより、数百ものソースからリアルタイムで生成されたデータを簡単に収集、保存、および処理できます。メッセージから複雑なデータストリーム処理にいたるまで、使用例の数はほぼ無制限です。Streamingの考えられる用途のいくつかを以下に示します。
- メッセージング:Streamingを使用して、大規模システムのコンポーネントを分離します。プロデューサーとコンシューマーは、Streamingを非同期メッセージバスとして使用し、それぞれ独自のペースで行動できます。
- メトリックとログの取り込み:従来のファイルスクレイピングアプローチの代わりにStreamingを使用して、重要な運用データを、インデックス作成、分析、視覚化により迅速に利用できるようにします。
- Web/モバイルアクティビティのデータの取り込み:Streamingを使用して、Webサイトまたはモバイルアプリからのアクティビティ(ページビュー、検索、または他のユーザーアクションなど)をキャプチャします。この情報は、リアルタイムの監視と分析、およびオフラインでの処理とレポート作成のためのデータウェアハウジングシステムに使用できます。
- インフラストラクチャとアプリのイベント処理:クラウド・コンポーネントの統合エントリポイントとしてStreamingを使用し、監査、会計、および関連アクティビティのライフサイクル・イベントのレポート作成をします。
Streamingの使用を開始するにはどうすればよいですか。
Streamingは、次のようにして使用を開始できます。
- Oracle Cloud Infrastructure ConsoleまたはCreateStream API操作を使用してストリームを作成します。
- メッセージをストリームに公開するようにプロデューサーを構成します。メッセージの公開を参照してください。
- ストリームからデータを読み取って処理するコンシューマーを構築します。メッセージの消費を参照してください。
または、Kafka APIを使用して、ストリームから生成および消費することもできます。詳細については、 Apache KafkaでのStreamingの使用を参照してください。
Streamingのサービス制限はどれくらいですか。
Streamingのスループットは、ストリームにパーティションを追加することで無制限にスケールアップするように設計されています。ただし、Streamingを使用する際に留意すべき一定の制限があります。
- ストリームでのメッセージの最大保存期間は7日です。
- ストリームに生成できる一意のメッセージの最大サイズは1メガバイト(MB)です。
- 各パーティションは、最大1 MB/秒のスループットで任意の数の書き込みリクエストを処理できます。
- 各パーティションは、1秒あたり1 MBの最大合計データ書き込み率と1秒あたり2 MBの読み取り率をサポートできます。
Streamingはキューベースのサービスとどのように比較されますか。
Streamingは、ストリームベースのセマンティクスを提供します。ストリームセマンティクスは、パーティションごとの厳密な順序保証、メッセージの再生可能性、クライアント側のカーソル、およびスループットの大規模な水平方向のスケーリングを提供します。キューはこれらの機能を提供しません。キューは、FIFOキューを使用する場合に順序保証を提供するよう設計できますが、パフォーマンスのオーバーヘッドが大幅に増加するという犠牲が伴います。
キーコンセプト
ストリームとは何ですか?
ストリームは、メッセージのパーティション化された追加専用ログであり、プロデューサーアプリケーションによるデータの書き込み先、コンシューマーアプリケーションによるデータの読み取り元となります。
ストリームプールとは何ですか。
ストリームプールは、ストリームを整理および管理するために使用できるグループです。ストリームプールは、複数のストリーム間で構成設定を共有する機能を提供するため、操作が容易になります。たとえば、ユーザーはストリームプールでカスタム暗号化キーなどのセキュリティ設定を共有して、プール内のすべてのストリームのデータを暗号化できます。ストリームプールでは、ストリームプール内のすべてのストリームへのインターネットアクセスを制限することにより、ストリームのプライベートエンドポイントを作成することもできます。StreamingのKafka互換性機能を使用しているお客様の場合、ストリームプールは仮想Kafkaクラスターのルートとして機能するため、その仮想クラスターでのすべてのアクションをそのストリームプールにスコープできます。
パーティションとは何ですか。
パーティションは基本スループット・ユニットであり、ストリームからの生成と消費の水平方向のスケーリングと並列処理を可能にします。パーティションの容量は、1秒あたり1 MBのデータ入力と2秒あたり2 MBのデータ出力になります。ストリームを作成するときは、アプリケーションのスループット要件に基づいて、必要なパーティションの数を指定します。たとえば、10個のパーティションを持つストリームを作成できます。その場合、ストリームから10 MB/秒の入力と20 MB/秒の出力のスループットを実現できます。
メッセージとは何ですか。
メッセージは、ストリームに格納されているbase64でエンコードされたデータの単位です。ストリーム内のパーティションに生成できるメッセージの最大サイズは1 MBです。
キーとは何ですか?
キーは、関連するメッセージをグループ化するために使用される識別子です。同じキーのメッセージは同じパーティションに書き込まれます。Streamingにより、特定のパーティションのコンシューマーは常に、そのパーティションのメッセージを、書き込みとまったく同じ順序で読み取ることができます。
プロデューサーとは何ですか。
プロデューサーは、ストリームにメッセージを書き込むことができるクライアントアプリケーションです。
コンシューマーおよびコンシューマーグループとは何ですか。
コンシューマーは、1つ以上のストリームからメッセージを読み取ることができるクライアントアプリケーションです。コンシューマーグループは、ストリーム内のすべてのパーティションからのメッセージを調整する一連のインスタンスです。特定のパーティションからのメッセージは、常にグループ内の1つのコンシューマーのみが消費できます。
カーソルとは何ですか。
カーソルは、ストリーム内の場所へのポインターです。この場所は、パーティション内の特定のオフセットや時間へのポインター、またはグループの現在の場所へのポインターである場合があります。
オフセットとは何ですか。
パーティション内の各メッセージには、オフセットと呼ばれる識別子があります。コンシューマーは特定のオフセットから始まるメッセージを読み取ることができ、選択した任意のオフセットポイントから読み取ることができます。コンシューマーは最新の処理済みオフセットをコミットすることもできるため、停止して再起動した場合にメッセージを再生したり、見落としたりすることなく作業を再開できます。
セキュリティ
Oracle Cloud Infrastructure Streamingを使用している場合、データはどの程度安全ですか。
Streamingは、保存時と転送時のどちらでもデフォルトでデータ暗号化を行います。Streamingは、完全なIntegrated with Oracle Cloud Infrastructure Identity and Access Management(IAM)であり、アクセスポリシーを使用して、ユーザーおよびユーザーグループに権限を選択的に付与できます。REST APIを使用しているとき、HTTPSプロトコルを使用してSSLエンドポイントを介したStreamingからデータを安全にPUTおよびGETすることもできます。さらに、Streamingはデータを完全にテナントレベルで分離するため、「ノイズネイバー」の問題は発生しません。
独自のマスターキーセットを使用して、ストリーム内のデータを暗号化できますか。
Streamingデータは、メッセージの整合性を確保するとともに、保存時と転送時のどちらでも暗号化されます。Oracleに暗号化の管理を任せることも、特定のコンプライアンスまたはセキュリティ基準を満たす必要がある場合は、Oracle Cloud Infrastructure Vaultを使用して独自の暗号化キーを安全に保存および管理することもできます。
ストリームプールの作成後に編集できるセキュリティ設定は何ですか。
「Oracleキーによって提供される暗号化」と「顧客管理キーを使用して管理される暗号化」の使用を切り替える場合は、ストリームプールのデータ暗号化設定をいつでも編集できます。Streamingでは、このアクティビティを実行できる回数に制限はありません。
ストリームへのアクセスを管理および制御する方法を教えてください。
Streamingは、完全なIntegrated with Oracle Cloud Infrastructure IAMです。すべてのストリームにコンパートメントが割り当てられています。ユーザーは、テナンシー、コンパートメント、または単一ストリームレベルで詳細なルールを記述するために使用できるロールベースのアクセス制御ポリシーを指定できます。
アクセスポリシーは、「Allow <subject> to <verb> <resource-type> in <location> where <conditions>」という形式で指定します。
KafkaユーザーはStreamingでどの認証メカニズムを使用する必要がありますか。
Kafkaプロトコルによる認証では、認証トークンとSASL/PLAINメカニズムを使用します。コンソールのユーザー詳細ページでトークンを生成できます。詳細については、認証トークンの使用を参照してください。専用のグループ/ユーザーを作成し、適切なコンパートメントまたはテナンシーでストリームを管理する権限をそのグループに付与することをお勧めします。その後、作成したユーザーの認証トークンを生成し、Kafkaクライアント構成で使用できます。
パブリックIPを使用せずに、仮想クラウドネットワーク(VCN)からストリーミングAPIにプライベートにアクセスできますか。
プライベートエンドポイントは、テナンシー内の指定された仮想クラウドネットワーク(VCN)へのアクセスを制限して、そのストリームにインターネット経由でアクセスできないようにします。プライベートエンドポイントは、VCN内のプライベートIPアドレスをストリームプールに関連付け、Streamingトラフィックがインターネットを通過しないようにします。Streaming用のプライベートエンドポイントを作成するには、ストリームプールを作成するときにプライベートサブネットを持つVCNにアクセスする必要があります。詳細については、プライベートエンドポイントについておよびVCNとサブネットを参照してください。
統合
Oracle Cloud Infrastructure Object StorageでOracle Cloud Infrastructure Streamingを使用するにはどうすればよいですか。
ストリームのコンテンツをObject Storageバケットに直接書き込むことができます。これは通常、長期保存を目的としてストリーム内のデータを永続化するためです。これは、StreamingでKafka Connect for S3を使用して実現できます。詳細については、Oracle Streaming ServiceからObject Storageへの公開ブログ投稿を参照してください。
Oracle Autonomous AI DatabaseでStreamingを利用するにはどうすればよいですか?
オラクルAutonomous AI Transaction Processingインスタンス内のテーブルからデータを取り込むことができます。詳細については、Oracle Streaming ServiceおよびAutonomous DBでのKafka Connectの使用ブログ投稿を参照してください。
MicronautでStreamingを使用するにはどうすればよいですか。
Kafka SDKを使用して、Streamingからのメッセージを生成および消費できます。また、MicronautによるKafkaの組み込みサポートを使用できます。詳細については、MicronautによるKafkaサポートとOracle Streaming Serviceによる簡単なメッセージングブログ投稿を参照してください。
Streamingを使用してMQTTブローカーからIoTデータを取り込むにはどうすればよいですか。
詳細については、 MQTTブローカーからOCI-Oracle Streaming Service、OCI- Kafka Connect Harness、およびOracle Kubernetes EngineへのIoTデータの取り込みブログ投稿を参照してください。
Oracle GoldenGate for Big DataはStreamingと互換性がありますか。
Oracle GoldenGate for Big Dataは、Streamingとの統合が認定されました。詳細については、Oracle GoldenGate for Big Dataドキュメントの Oracle Streaming Serviceへの接続を参照してください。
StreamingからOracle Autonomous AI Lakehouseへ直接データを取り込む方法はありますか?
Streamingデータを直接Oracle Autonomous AI Lakehouseに転送するには、Kafka JDBC Sink Connectを使用する必要があります。
- 「Using Kafka Connect With Oracle Streaming Service And Autonomous DB」というブログ記事では、Kafka Connectのソースコネクタの使い方を解説しています。これは、Oracle Autonomous AI Lakehouseからストリームへデータを送る方法です。ただし、反対のものであるシンクコネクタが必要です。
- 「OSS data to ADW in almost real-time」というブログ記事では、オブジェクトストアのパスを持つ外部テーブルを利用し、Oracle Autonomous AI Lakehouseにデータを取り込む方法について説明しています。
価格設定
Oracle Cloud Infrastructure Streamingの使用料金はどのように課金されますか。
Streamingではシンプルな従量制の料金設定が採用されており、使用したリソースについてのみ料金が発生します。料金は次の要素に基づいて決まります。
- GET/PUTリクエストの価格: データ転送のギガバイト
- ストレージの価格(使用された保存期間時間数に基づく): ストレージの1時間あたりのギガバイト数
最新の価格については、OCIストリーミング・ページご覧ください。
サービスを使用しなくても、プロビジョニング料金は課金されますか。
Streamingの業界をリードする価格設定モデルでは、デフォルトのサービス制限内でサービスを使用した場合にのみ、料金が発生します。
Streamingにデータを出し入れするための追加料金はかかりますか。
Streamingでは、データをサービスに出し入れするための追加料金はかかりません。さらに、ユーザーはService Connector Hubの機能を利用し、サーバーレス方式でStreamingにデータを出し入れできます。追加料金はかかりません。
Streamingの無料枠はありますか。
現在のところ、Streamingは無料枠では動作しません。
Oracle Cloud Infrastructureストリームの管理
StreamingにアクセスするにはどのようなIAM権限が必要ですか。
Identity and Access Managementを使用すると、クラウド・リソースにアクセスできるユーザーを制御できます。Oracle Cloud Infrastructureリソースを使用するには、コンソールを使用しているか、SDK、CLI、またはその他のツールでREST APIを使用しているかに関係なく、管理者が作成したポリシーで必要とされるタイプのアクセス権を付与する必要があります。アクセスポリシーは、
Allow <subject> to <verb> <resource-type> in <location> where <conditions>
テナンシーの管理者はポリシーを使用できる
Allow group StreamAdmins to manage streams in tenancy
この場合、指定されたグループStreamAdminsは、ストリームとその関連リソースの作成、更新、一覧表示、削除など、ストリーミングに関するあらゆる操作を行うことができます。ただし、いつでもより詳細なポリシーを指定し、グループ内の特定のユーザーのみが、特定のストリームで実行できるアクティビティのサブセットのみ実行できる資格を持つようにすることができます。ポリシーを初めて使用する場合は、ポリシーを使ってみるおよび一般的なポリシーを参照してください。Streamingのポリシーの作成についてさらに詳しく調べる場合は、IAMポリシーリファレンスのStreamingサービスの詳細を参照してください。
大規模なストリームのデプロイを自動化するにはどうすればよいですか。
ストリームとそれに関連するすべてのコンポーネント(IAMポリシー、パーティション、暗号化設定など)は、Oracle Cloud Infrastructure Resource ManagerまたはOracle Cloud Infrastructure用のTerraformプロバイダを使用してプロビジョニングできます。Terraformプロバイダの詳細については、StreamingサービスのTerraformに関するトピックを参照してください。
必要なパーティションの数はどう決定すればよいですか?
ストリームを作成するときは、ストリームに含まれるパーティションの数を指定する必要があります。アプリケーションの予想スループットは、ストリームのパーティション数を決定するのに役立ちます。平均メッセージサイズに1秒あたりに書き込まれるメッセージの最大数を乗算して、予想スループットを見積もります。単一のパーティションは1秒あたり1 MBの書き込み速度に制限されるため、スループットが高くなると、スロットリングを回避するために追加のパーティションが必要になります。アプリケーションのスパイクを管理しやすくするため、最大スループットよりわずかに高いパーティションを割り当てることをお勧めします。
ストリーム内でパーティションを作成・削除するにはどうすればよいですか?
ストリームを作成するときに、コンソールまたはプログラムでパーティションを作成します。
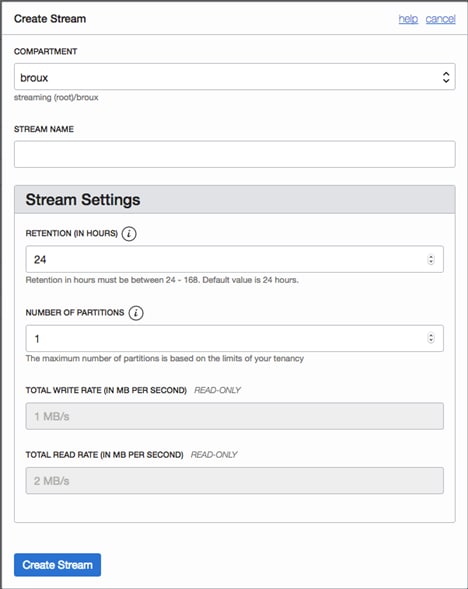
コンソールUI:
プログラム:
ストリームの作成
CreateStreamDetails streamDetails =
CreateStreamDetails.builder()
.compartmentId(compartmentId)
.name(streamName)
.partitions(partitions)
.build();
より詳細な例は、SDKにあります。
Streamingの内部でパーティションが管理されるため、パーティションを管理する必要はありません。ユーザーはパーティションを直接削除することはできません。ストリームを削除すると、そのストリームに関連付けられているすべてのパーティションが削除されます。
ストリームにリクエストできる最小スループットはいくつですか?
Oracle Cloud Infrastructureストリームのスループットは、パーティションによって定義されます。パーティションは、1秒あたり1 MBのデータ入力と1秒あたり2 MBのデータ出力を提供します。
ストリームにリクエストできる最大スループットはいくつですか。
Oracle Cloud Infrastructureストリームのスループットは、パーティションを追加することでスケールアップできます。ストリームが保持できるパーティションの数に理論上の上限はありません。ただし、各Oracle Cloud Infrastructureテナンシーには、ユニバーサル・クレジット・タイプ・アカウントのデフォルトのパーティション制限として5が設定されています。より多くのパーティションが必要な場合、いつでもサービス制限の引き上げをリクエストできます。
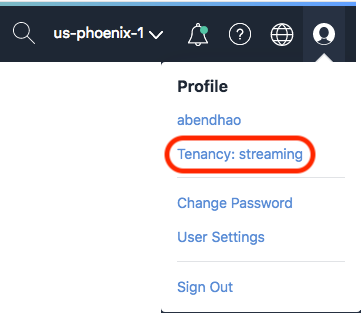
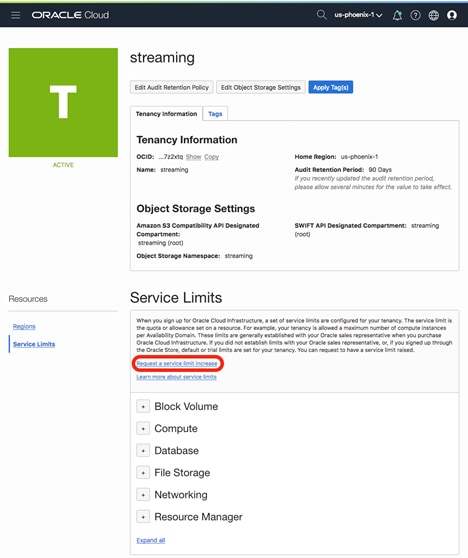
Oracle Cloud Infrastructure Consoleを使用して、テナンシーのサービス制限を引き上げるにはどうすればよいですか。
次の手順に従って、サービス制限の引き上げをリクエストできます。
- コンソール右上の「ユーザー」メニューを開き、「テナンシ:<tenancy_name> をクリックします。
![]()
- 「サービス制限」をクリックし、「サービス制限の引き上げをリクエストする」をクリックします。
![]()
- フォームに記入し、「サービスカテゴリ」で「その他」、「リソース」で「その他の制限」を選択します。「リクエストの理由」で、テナンシーにおけるStreamingサービスのパーティション数の引き上げをリクエストします。
ストリームを管理するためのベストプラクティスにはどのようなものがありますか。
ストリームを作成する際に留意すべきいくつかのベストプラクティスを次に示します。
- ストリーム名は、ストリームプール内で一意にする必要があります。つまり、異なるストリームプールにある場合にのみ、同じコンパートメントに同じ名前の2つのストリームを作成できます。
- ストリームが作成されると、その中のパーティションの数を変更することはできません。最大スループットより少し高いパーティションを割り当てることを推奨しています。これは、アプリケーションのスパイクを管理するのに役立ちます。
- ストリームの保持期間は、作成後に変更することはできません。デフォルトでは、データは24時間ストリームに保存されます。ただし、データの保持期間は24時間~168時間の任意の時間に構成できます。ストリームに保存されるデータの量は、ストリームのパフォーマンスに影響を与えません。
Oracle Cloud Infrastructureストリームへのメッセージの生成
ストリームにメッセージを生成するにはどうすればよいですか。
ストリームが作成されて「アクティブ」状態になると、メッセージの生成を開始できます。コンソールまたはAPIを使用してストリームに生成できます。
コンソールの場合:コンソールで、「ソリューションとプラットフォーム」>「分析」タブにある「Streamingサービス」セクションに移動します。すでにストリームを作成している場合、コンパートメントでストリームを選択し、「ストリームの詳細」ページに移動します。コンソールの「テストメッセージの作成」ボタンをクリックします。これにより、メッセージにパーティションキーがランダムに割り当てられ、ストリーム内のパーティションに書き込まれます。このメッセージは、「メッセージの読み込み」ボタンをクリックすることにより、「最近のメッセージ」セクションで表示できます。
APIの場合:Oracle Cloud Infrastructure Streaming APIまたはKafka APIのいずれかを使用して、ストリームを生成できます。メッセージはストリーム内のパーティションに公開されます。複数のパーティションがある場合、メッセージの送信先のパーティションを選択するためのキーを指定します。キーを指定しない場合、StreamingはUUIDを生成してキーを割り当て、メッセージをランダムなパーティションに送信します。これにより、キーのないメッセージがすべてのパーティションに均等に分散されます。ただし、データのパーティショニング戦略を明示的に制御できるように、必ずメッセージキーを指定することをお勧めします。
Streaming SDKを使用してストリームにメッセージを生成する方法の例は、ドキュメントを参照してください。
プロデューサーが使用するパーティションを知るにはどうすればよいですか。
Oracle Cloud Infrastructure APIを使用してメッセージを生成している間、パーティショニングロジックはStreamingによって制御されます。これはサーバー側のパーティショニングと呼ばれます。ユーザーは、キーに基づいて送信先のパーティションを選択します。キーはハッシュされ、結果の値は、メッセージの送信先のパーティション番号を決定するために使用されます。同じキーのメッセージは同じパーティションに行きます。キーが異なるメッセージは、異なるパーティションまたは同じパーティションに送信される場合があります。
ただし、Kafka APIを使用してストリームに生成する場合、パーティショニングはKafkaクライアントによって制御され、Kafkaクライアントのパーティショナーがパーティショニングロジックを担当します。これは、クライアント側のパーティショニングと呼ばれます。
効果的なパーティションキーを生成する方法を教えてください。
メッセージを均等に分散するには、メッセージキーに有効な値が必要です。作成するには、ストリーミングデータの選択性とカーディナリティを検討してください。
- カーディナリティ:特定の用途ケースに基づいて生成される可能性のある一意のキーの総数を検討してください。キーカーディナリティが高いほど、分散がよくなります。
- 選択性:各キーを持つメッセージ数を検討してください。選択性が高いほど、キーあたりのメッセージ数が多くなり、ホットスポットの発生につながります。
必ず、高いカーディナリティと低い選択性を目指します。
生成と同じ順序でメッセージがコンシューマーに配信されるようにするにはどうすればよいですか。
Streamingは、パーティション内で線形化可能な読み取りと書き込みを保証します。同じ値のメッセージが同じパーティションに送られるようにするには、それらのメッセージに同じキーを使用する必要があります。
メッセージサイズはストリームのスループットにどのように影響しますか。
パーティションのデータ入力レートは1 MB/秒であり、1秒あたり最大1000件のPUTメッセージがサポートされます。したがって、レコードサイズが1 KB未満の場合、パーティションの実際のデータ入力レートは1 MB/秒未満になり、1秒あたりのPUTメッセージの最大数によって制限されます。次の理由により、メッセージはバッチで作成することをお勧めします。
- サービスに送信されるPUTクエストの数を減らすることで、スロットルが回避される。
- スループットが向上する。
メッセージのバッチサイズは1MBを超えてはなりません。この制限を超えると、スロットリングメカニズムがトリガーされます。
1MBを超えるメッセージの処理はどうすればよいですか?
チャンキングを使用するか、Oracle Cloud Infrastructure Object Storageを使用してメッセージを送信できます。
- チャンキング:大きなペイロードは、Streamingサービスが受け入れることができる複数の小さなチャンクに分割できます。チャンクは、通常の(チャンクされていない)メッセージ格納と同じ方法でサービスに格納されます。唯一の違いは、コンシューマーはチャンクを保持し、すべてのチャンクが収集されたときにそれらをメッセージと結合する必要があることです。パーティション内のチャンクは、通常のメッセージと織り交ぜることができます。
- Object Storage:大きなペイロードがObject Storageに配置され、そのデータへのポインターのみが転送されます。レシーバーはこのタイプのポインターペイロードを認識し、Object Storageからデータを透過的に読み取り、エンドユーザーに提供します。
パーティションで許可されている速度よりも速い速度で生成するとどうなりますか。
プロデューサーが1秒あたり1 MBを超える速度で生成すると、リクエストはスロットルされ、パーティションごとの1秒あたりのリクエストが多すぎることを示す「 429:リクエストが多すぎます」エラーがクライアントに返送されます。
Oracle Cloud Infrastructureストリームからのメッセージの消費
ストリームからデータを読み取る方法を教えてください。
コンシューマは、1つ以上のストリームからメッセージを読み取るエンティティです。このエンティティは、単独で存在またはコンシューマー・グループの一部として存在することもできます。メッセージを消費するには、カーソルを作成し、そのカーソルを使用してメッセージを読み取る必要があります。カーソルは、ストリーム内の場所をポイントします。この場所は、パーティション内の特定のオフセットや時間、またはグループの現在の場所である場合があります。読み取り元の場所に応じて、TRIM_HORIZON、AT_OFFSET、AFTER_OFFSET、AT_TIME、LATESTなどのさまざまなカーソルタイプを使用できます。
詳細については、メッセージの消費に関するドキュメントを参照してください。
特定の時点でストリームから消費できるメッセージの最大数はいくつですか。
GetMessagesRequestクラスのgetLimit( )メソッドは、メッセージの最大数を返します。10,000まで任意の値を指定できます。デフォルトでは、サービスは可能な限り多くのメッセージを返します。ストリームのスループットを超えないように、平均メッセージサイズを検討してください。ストリーミングサービスのGetMessagesバッチサイズは、特定のストリームに生成された平均メッセージサイズに基づいています。
コンシューマへのメッセージ重複を回避するにはどうすればよいですか?
Streamingは、「少なくとも1回」の配信セマンティクスをコンシューマーに提供します。コンシューマアプリケーションで重複を処理することを推奨しています。たとえば、コンシューマーグループの以前非アクティブであったインスタンスがグループに再参加し、以前割り当てられたインスタンスによってコミットされていないメッセージの消費を開始すると、重複の処理が必要になる可能性があります。
コンシューマーが遅延しているかどうかはどうすればわかりますか。
消費の速度が生成に追い付いていない場合、コンシューマーは遅延していると言うことができます。コンシューマーが遅延しているかどうかを判断するには、メッセージのタイムスタンプを使用できます。コンシューマーが遅延している場合は、新しいコンシューマーを生成して、最初のコンシューマーからいくつかのパーティションを引き継ぐことを検討してください。単一のパーティションで遅れている場合、回復する方法はありません。
次のオプションを検討してください。
- ストリームのパーティション数を増やします。
- 問題の原因がホットスポットである場合は、メッセージキーの戦略を変更してください。
- メッセージの処理時間を短縮するか、リクエストを並行して処理します。
特定のパーティションで消費するメッセージがいくつ残っているかを知りたい場合は、タイプLATESTのカーソルを使用して、次の公開メッセージのオフセットを取得し、現在使用しているオフセットでデルタを作成します。密度オフセットがないため、大まかな見積もりしか得られません。ただし、プロデューサーが生成を停止した場合、次の公開メッセージのオフセットを取得することはできないため、その情報を取得することはできません。
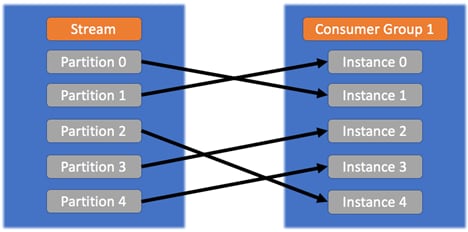
コンシューマ・グループはどのように機能しますか?
コンシューマは、グループの一部としてメッセージを消費するよう構成できます。ストリームパーティションはグループのメンバー間で分散されるため、単一のパーティションからのメッセージは単一のコンシューマーにのみ送信されます。パーティションの割り当ては、コンシューマーがグループに参加またはグループから脱退するときに再調整されます。詳細については、コンシューマーグループに関するドキュメントを参照してください。
コンシューマ・グループを使用するメリットはありますか?
コンシューマ・グループには次のメリットがあります。
- コンシューマーグループ内の各インスタンスは、自動的に」割り当てられている1つ以上のパーティションからメッセージを受信し、同じメッセージは(異なるパーティションに割り当てられている)他のインスタンスでは受信されません。このようにして、1つのインスタンスが1つのパーティションのみを読み取るようにすることにより、インスタンスの数をパーティションの数まで増やすことができます。この場合、グループに参加する新しいインスタンスは、どのパーティションにも割り当てられずにアイドル状態になります。
- インスタンスを さまざまなコンシューマー・グループ の一部として持つと、パーティションからのメッセージが各種グループにまたがるすべてのインスタンスに送信される 公開-登録パターンが生成されます。
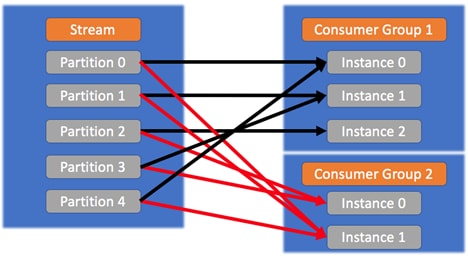
同じコンシューマーグループ内のルールは、次の画像に示すとおりです。![]()
また、異なるグループ間では、インスタンスは同じメッセージを受信します(下図参照)。
![]()
これは、パーティション内のメッセージが、さまざまな方法でメッセージ処理する異なるアプリケーションにとって重要な場合に役立ちます。興味のあるすべてのアプリケーションが、パーティションから同じメッセージをすべて受信するようにします。 - インスタンスがグループに参加するときに、十分なパーティションがある場合(つまり、パーティションごとに1つのインスタンスの制限に達していない場合)、リバランスが開始されます。パーティションは現在のインスタンスと新しいインスタンスに再割り当てされます。同様に、インスタンスがグループを離れると、パーティションは残りのインスタンスに再割り当てされます。
- オフセットのコミットは自動で管理されます。
ストリームごとに持つことができるコンシューマーグループの数に制限はありますか。
ストリームあたりのコンシューマーグループの制限は50です。コンシューマーグループは一時的なものです。ストリームの保持期間に使用されない場合は消滅します。
コンシューマーおよびコンシューマーグループを使用する際に注意する必要があるタイムアウトは何ですか。
Streamingの次のコンポーネントにはタイムアウトがあります。
- カーソル:メッセージを消費し続ける限り、カーソルを作成する必要はありません。メッセージの消費が5分を超えて停止した場合は、カーソルを再作成する必要があります。
- インスタンス:インスタンスがメッセージの消費を30秒以上停止すると、そのインスタンスはコンシューマー・グループから削除され、そのパーティションが別のインスタンスに再割り当てされます。これはリバランスと呼ばれます。
コンシューマ・グループ内のリバランスとは何ですか?
リバランスとは、同じコンシューマーグループに属するインスタンスのグループが、特定のストリームに属するパーティションの専用セットを相互に所有するように分散するプロセスです。コンシューマーグループのリバランス操作が正常に終了すると、ストリーム内のすべてのパーティションは、グループ内の1つ以上のコンシューマーインスタンスによって所有されます。
コンシューマーグループ内でリバランスアクティビティをトリガーするものは何ですか。
コンシューマーグループのインスタンスが30秒を超えてハートビートの送信に失敗したか、プロセスが終了したために非アクティブになると、コンシューマーグループ内でリバランスアクティビティがトリガーされます。これは、非アクティブなインスタンスによって以前に消費されたパーティションを処理し、それをアクティブなインスタンスに再割り当てするために行われます。同様に、以前は非アクティブであったコンシューマーグループのインスタンスがグループに参加すると、リバランスがトリガーされ、消費を開始するパーティションが割り当てられます。Streamingサービスは、グループに再参加するときにインスタンスを同じパーティションに再割り当てすることを保証しません。
コンシューマの障害からどのように回復すればよいですか?
障害から回復するには、パーティションごとに処理した最後のメッセージのオフセットを保存して、コンシューマーを再起動する必要がある場合にそのメッセージからの消費を開始できるようにする必要があります。
注:5分で期限切れになりますので、カーソルを保存しないでください。
最後に処理したメッセージのオフセットを保存するためのガイダンスは提供されていないため、任意の方法を使用できます。たとえば、カーソルを別のストリームに保存したり、VM上のファイルに保存したり、Object Storageバケットに保存したりできます。コンシューマーが再起動したら、最後に処理したメッセージのオフセットを読み取り、タイプAFTER_OFFSETのカーソルを作成して、取得したオフセットを指定します。
KafkaとOracle Cloud Infrastructure Streamingの互換性
既存のKafkaアプリケーションをStreamingと統合するにはどうすればよいですか。
Streamingサービスは、既存のApache Kafkaベースのアプリケーションで使用できるKafkaエンドポイントを提供します。完全に管理されたKafkaエクスペリエンスを実現するために必要なのは、構成の変更だけです。StreamingとKafkaの互換性により、独自のKafkaクラスターを実行する代わりの方法が実現します。Streamingは、Apache Kafka 1.0以降のクライアントバージョンをサポートし、既存のKafkaアプリケーション、ツール、およびフレームワークで動作します。
既存のKafkaアプリケーションがStreamingとやり取りするには、どのような構成変更を行う必要がありますか。
既存のKafkaアプリケーションをお持ちのお客様は、Kafka構成ファイルの次のパラメータを変更するだけでStreamingに移行できます。
security.protocol: SASL_SSL
sasl.mechanism: PLAIN
sasl.jaas.config: org.apache.kafka.common.security.plain.PlainLoginModule required username="{username}" password="{pwd}"; bootstrap.servers: kafka.streaming.{region}.com:9092 # Application settings
topicName: [streamOcid]
StreamingでKafka Connectを使用するにはどうすればよいですか。
KafkaコネクタをStreamingで使用するには、コンソールまたはコマンドライン・インターフェイス(CLI)を使用してKafka Connect構成を作成します。Streaming APIは、これらの構成ハーネスを呼び出します。特定のコンパートメントで作成されたKafka Connect構成は、同じコンパートメント内のストリームに対してのみ機能します。同じKafka Connect構成で複数のKafkaコネクタを使用できます。別個のコンパートメントでストリームを生成または消費する必要がある場合、またはKafka Connect構成のスロットル制限に達するのを避けるためにより多くの容量が必要な場合(たとえば、コネクタが多すぎる、コネクターのワーカーが多すぎるなど)、Kafkaコネクタ構成をさらに作成できます。
Streamingでは、ファーストパーティ製品およびサードパーティ製品とのどのような統合が提供されますか。
StreamingとKafka Connectの互換性は、既存の多くのファーストパーティコネクタおよびサードパーティコネクタを利用して、データをソースからターゲットに移動できることを意味します。Oracle製品用のKafkaコネクタには次のものがあります。
- Oracle Cloud Infrastructure Object Storage(Kafka Connect for S3を使用)
- Kafka Connect Amazon S3ソースコネクタ(プロデューサー向け)
- Kafka Connect Amazon S3シンクコネクタ(コンシューマー向け)
- Oracle Integration Cloud
- Oracle AI Database (Kafka Connect JDBCを使用)
- Oracle GoldenGate
サードパーティのKafkaソースおよびシンクコネクタの完全なリストについては、Confluent Kafkaの公式ハブを参照してください。
Oracle Cloud Infrastructureストリームの監視
ストリームはどこで監視できますか?
Streamingは、Oracle Cloud Infrastructure Monitoringと完全に統合されています。コンソールで、監視するストリームを選択します。「ストリームの詳細」ページで「リソース」セクションに移動し、「監視チャートの生成」をクリックしてプロデューサーのリクエストを監視するか、「監視チャートの消費」をクリックしてコンシューマー側のメトリックを監視します。メトリックは、パーティションレベルではなくストリームレベルで使用できます。サポートされているStreamingメトリックの説明については、ドキュメントを参照してください。
Streamingを監視するとき、どのような統計を利用できますか。
コンソールで使用可能な各メトリックは、次の統計を提供します。
- レート、合計、平均値
- 最小、最大、カウント
- P50、P90、P95、P99、P99.9
これらの統計は、次の時間間隔で生成されます
- 自動
- 1分
- 5分
- 1時間
通常はどのメトリックにアラームを設定すればよいですか。
プロデューサーの場合、次のメトリックにアラームを設定することを検討してください。
- PUTメッセージのレイテンシ:レイテンシの増加は、メッセージの公開に時間がかかっていることを意味します。これは、ネットワークの問題を示している可能性があります。
- PUTメッセージの合計スループット:
- 合計スループットの重要な増加は、パーティションあたり1 MB/秒の制限に達し、その事象がスロットルメカニズムをトリガーすることを示す場合があります。
- 重要な減少は、クライアントプロデューサーに問題があるか、停止しようとしていることを意味します。
- PUTメッセージのスロットルレコード:メッセージがスロットルされたときに通知を受け取ることは重要です。
- PUTメッセージの失敗:運用チームが理由の調査を開始できるように、PUTメッセージが失敗し始めた場合に通知を受け取ることは重要です。
コンシューマの場合、次のメトリックに基づいて同じアラームを設定することを検討してください。
- メッセージのレイテンシを取得
- GETメッセージの合計スループット
- スロットルされたメッセージの取得
- メッセージ失敗の取得
ストリームが正常であるかの確認方法を教えてください。
ストリームは、アクティブ状態のときに正常です。ストリームを生成でき、応答が成功すれば、ストリームは正常です。データがストリームで生成された後、構成された保持期間の間、コンシューマーはデータにアクセスできます。GetMessages APIの呼び出しが高いレベルの内部サーバーエラーを返してくる場合、サービスは正常ではありません。
ストリームが正常だと、メトリックも正常です。
- メッセージのレイテンシの出力レベルが低いです。
- PUTメッセージの合計スループットが、パーティションあたり1 MB/秒に近づいています。
- メッセージのスロットルレコードの出力は、0に近いです。
- メッセージ失敗の出力は、0に近いです。
- メッセージのレイテンシの出力レベルが低いです。
- GETメッセージの合計スループットが、パーティションあたり2 MB/秒に近づいています。
- メッセージのスロットルリクエストの出力は、0に近いです。
- メッセージ失敗の出力は、0に近いです。
メッセージはいつストリームでスロットルされますか。
スロットリングは、ストリームが新しい読み取りまたは書き込みを処理できないことを示します。次のしきい値を超えると、スロットルメカニズムがアクティブになります。
- GetMessages:1秒あたり5回の呼び出し、またはパーティションあたり2 MB/秒
- PutMessages:パーティションあたり1 MB/秒
- 管理およびコントロールプレーン操作(CreateCursor、ListStreamなど):ストリームあたり1秒に5回の呼び出し
APIエラーのリストはどこにありますか?
APIエラーの詳細は、ドキュメントにあります。