エンタープライズ・データ・メッシュ
ソリューションとユース・ケースおよびケース・スタディ
データメッシュとは
エンタープライズ・ソフトウェアで話題のデータメッシュは、データ管理のための分散アーキテクチャに基づく、データに関する新しい考え方です。データ所有者、データ作成者、データ消費者を直接つなぐことで、ビジネスユーザーがデータにアクセスおよび利用しやすくなるという考え方です。データメッシュは、データ中心のソリューションのビジネス成果を向上させ、最新のデータ・アーキテクチャの導入を促進することを目的としています。
ビジネスの観点から見ると、データメッシュは「データ製品思考」という新しい考え方を取り入れるものです。つまり、意思決定の改善、不正行為の検出、サプライチェーンの状況の変化に対する警告など、「なすべき仕事」を行うための製品としてデータをとらえるということです。価値の高いデータ製品を生み出すためには、企業は文化と考え方を変え、ビジネスドメインのモデリングに、より機能横断的なアプローチを取る必要があります。
技術面では、データメッシュに関するオラクルの見解として、データドリブンなアーキテクチャのための3つの重要な新領域を挙げています。
- データコレクション、データイベント、データ分析などのデータ製品を提供するツール
- モノリシックなアーキテクチャからマルチクラウドやハイブリッド・クラウドへの移行を選択する組織や、グローバルに分散した運用が必要な組織を支援する分散・非集中型データ・アーキテクチャ
- よりタイムリーな分析を提供するリアルタイムのデータイベントを実現するために、一元化された、静的かつバッチ指向のデータだけに依存するのではなく、イベント駆動型のデータ台帳やストリーミング中心のパイプラインに移行することをを目指す組織のための移動中のデータ
その他、非技術系ユーザー向けのセルフサービスツールや強力なフェデレーテッド・データ・ガバナンスモデルなども、より集中的で古典的なデータ管理手法と同様に、データメッシュ・アーキテクチャにとって重要な課題となっています。
データの新しい概念

データメッシュというアプローチは、データを製品として考えることへのパラダイムシフトです。データメッシュは、企業がデータをビジネスの有形資本資産として管理するために必要な、組織的およびプロセス的な変更をもたらします。オラクルの考えるデータメッシュ・アーキテクチャでは、組織や分析データの領域を横断した連携が求めらます。
データメッシュは、データ作成者とビジネスユーザーを直接結びつけること、また、データリソースの取り込み、準備、変換プロジェクトおよびプロセスから、できるだけITによる介入を排除することを目的としています。
オラクルがデータメッシュに注力してきた理由は、こうした新たなテクノロジー要件に対応できるプラットフォームをお客様に提供することにありました。これには、データ製品のためのツール、分散型やイベント駆動型アーキテクチャ、および移動中のデータのためのストリーミング・パターンが含まれます。データ製品のドメイン・モデリングやその他の社会技術的な懸念について、オラクルは、データメッシュのソートリーダーであるZhamak Dehghaniによる活動との整合を図っています。
データメッシュのメリット
データメッシュに投資することで、以下のような素晴らしいメリットが得られます。
- データ製品思考のベストプラクティスを適用することにより、データの価値を完全に把握できます。
- データ統合とデータ移行にマイクロサービスベースのデータパイプラインを使用することで、99.999%以上の運用データ可用性を実現。
- イノベーションサイクルを10倍高速化し、手動、バッチ指向のETLから継続的な変換とロード(CTL)へと移行します。
- データ・エンジニアリングを70%以上削減し、CI/CD、ノーコード、セルフサービス・データ・パイプライン・ツール、アジャイルな開発を実現できます。
データメッシュという考え方、そしてその先
データメッシュの市場は、まだ成熟の初期段階にあります。そのため、「データメッシュ」を謳うソリューションに関するさまざまなマーケティング・コンテンツを目にすることがありますが、こうしたいわゆるデータメッシュ・ソリューションは、コアとなるアプローチや原則に合っていないことがよくあります。
適切なデータメッシュとは、考え方であり、組織モデルであり、エンタープライズ・データ・アーキテクチャのアプローチとそれを支えるツールのことです。データメッシュ・ソリューションは、データ製品思考、分散型データ・アーキテクチャ、ドメイン指向のデータ所有権、分散型の移動中のデータ、セルフサービス・アクセス、強力なデータガバナンスをある程度兼ね備えている必要があります。
データメッシュは、以下のいずれでもありません。
- ベンダー製品:単一のデータメッシュ・ソフトウェア製品は存在していません。
- データレイクやデータレイク・ハウス:これらは補完的なものであり、複数のデータレイク、データポンド、および業務系システムにまたがる、より大規模なデータメッシュの一部の場合もあります。
- データカタログまたはグラフ:データメッシュは物理的な実装を必要とします。
- 単発のコンサルティング・プロジェクト:データメッシュはジャーニーであり、単発のプロジェクトではありません。
- セルフサービス型の分析製品:従来のセルフサービス型分析、データ準備、データ・ラングリングは、他のデータ・アーキテクチャと同様、データメッシュの一部である可能性もあります。
- データ・ファブリック: 概念的には関連していますが、データ・ファブリックのコンセプトは、さまざまなデータ統合やデータ管理のスタイルをより広く包含しているのに対し、データメッシュは分散化やドメイン駆動型のデザインパターンに関連しています。
なぜデータメッシュなのか
悲しいことに、過去のモノリシックなデータ・アーキテクチャは、煩雑でコストが高く、柔軟性に欠けるというのが実情です。長年にわたり、アプリケーションから分析に至るまで、デジタル・ビジネス・プラットフォームに費やされる時間とコストのほとんどは、統合作業に関するものであることが明らかになっています。その結果、ほとんどのプラットフォーム・イニシアチブが失敗しています。
データメッシュは、一元的なモノリシック・データ・アーキテクチャの特効薬ではありません。しかし、データメッシュ戦略の原則やプラクティス、およびテクノロジーは、データドリブンのビジネス・イニシアチブにおける、最も緊急かつ未対応の、最新化に関する課題のいくつかを解決するために設計されています。
データメッシュがソリューションとして登場するきっかけとなったテクノロジーのトレンドには、次のようなものがあります。
- デジタル・トランスフォーメーションの70-80%が失敗する
- 業務系データの停止に伴うコストが上昇している
- クラウド・ロックインが現実のものとなり、さらにコストがかかる可能性がある
- データレイクが成功することはほとんどなく、分析にのみ焦点が当てられている
- 分散型データの台頭により、より効果的、効率的、かつ経済的なアーキテクチャが求められている
- 組織のサイロ化により、データ共有の問題が深刻化している
- データは競争力を高めるための触媒であり、それを適切に管理することが重要である
なぜ今データメッシュが必要なのか、詳しくはZhamak Dehghaniの2019年の原著論文、「モノリシックなデータレイクから分散型データメッシュに移行する方法」をお読みください。
データメッシュの定義
データメッシュの背後にある分散型戦略は、セルフサービス型のデータ・インフラストラクチャを構築して、データを製品として扱い、ビジネスユーザーがデータにアクセスしやすくすることを目的としています。
重要な結果
データ製品思考- データ消費者の視点へと、考え方をシフトすること
- データドメイン所有者はデータ製品のKPI/SLAに責任を持つこと
- 同じデータ・ドメインとテクノロジー・メッシュのセマンティクスを採用
- 「データの投げっぱなし」を排除する
- データイベントを記録システムから直接リアルタイムで取得し、必要な場所にデータを配信するセルフサービス・パイプラインを実現
- 分散型データとソース・アラインド・データ製品を実現するために不可欠な機能
モノリシックなITアーキテクチャの排除
分散型アーキテクチャ- 分散型データ、サービス、クラウドのために構築されたアーキテクチャ
- あらゆるイベントの種類、形式、複雑性に対応できるように設計
- デフォルトによるストリーム処理、例外によるバッチ処理
- 開発者を支援し、データ利用者とデータ作成者を直接つなげるために構築
- セキュリティ、検証、来歴、透明性などの機能を内蔵
データメッシュを強化するオラクルの機能
理論を実践するためには、ミッションクリティカルなデータに対してエンタープライズ・クラスのソリューションを導入する必要があります。そこでオラクルは、エンタープライズ・データメッシュを強化するための信頼できるさまざまなソリューションを提供します。
データ製品の作成と共有
- Oracle Converged Databaseを使用したマルチモデルのデータコレクションにより、データ利用者が必要とする形式での「シェイプシフトする」データ製品を作成
- Oracle APEX Application DevelopmentとOracle REST Data Servicesを使用した、アプリケーションまたはAPIとしてのセルフサービス型データ製品により、すべてのデータに簡単にアクセスおよび共有可能
- Oracle Cloud SQLおよびBig Data SQLによるSQLクエリやデータ仮想化のための単一のアクセス・ポイント
- オラクルのデータ・サイエンス・プラットフォーム、Oracle Cloud Infrastructure(OCI)データ・カタログ、およびデータレイク・ハウス用のオラクルのクラウド・データ・プラットフォームによる機械学習用のデータ製品
- Oracle Stream Analyticsによる、リアルタイム・イベント、データ・アラート、およびロー・データ・イベント・サービスとしてのソース・アラインド・データ製品
- 包括的なOracle Analytics Cloudソリューションで、コンシューマー・アラインドおよびセルフサービスのデータ製品
分散型データ・アーキテクチャの運用
- Kubernetes、Docker、またはAutonomous Databaseを使用したクラウドネイティブなオラクルのプラガブル・データベースを使用した、データ・コンテナのための、アジャイルな「サービス・メッシュ」スタイルのCI/CD
- Oracle GoldenGateマイクロサービスおよびVeridataを使用したクロスリージョン、マルチクラウド、およびハイブリッド・クラウドのデータ同期による、信頼性の高いアクティブ/アクティブなトランザクション・ファブリック
- Oracle Integration CloudとOracle Internet of Things Cloudにより、ほとんどのアプリケーション、ビジネス・プロセス、およびIoT(Internet of Things)データ・イベントを利用可能
- Oracle GoldenGateまたはOracle Transaction Manager for Microservicesイベント・キューを使用して、マイクロサービス・イベントのソーシングやKafkaおよびデータレイクへのリアルタイム収集を行うことができます。
- Oracle Verrazzano、HelidonおよびGraal VMを使用して、分散型ドメイン駆動設計パターンをサービス・メッシュに取り込みます。
データメッシュの3つの重要な特徴
データメッシュは単なる新しい技術的な流行語ではありません。データメッシュは、データへのアクセスを向上させ、発見しやすくするための、新たな原則、プラクティス、および技術的機能のセットです。データメッシュのコンセプトは、過去の巨大なモノリシックなエンタープライズ・データ・アーキテクチャから、最新の分散型、非集中型のデータドリブンなアーキテクチャへの移行を促すことで、前世代のデータ統合アプローチやアーキテクチャとは一線を画しています。データメッシュのコンセプトには、次のような重要な特徴があります。
1. データ製品思考
データメッシュを実現するための最も重要な第一歩は、考え方の転換です。データ・アーキテクチャの最新化を成功させるためには、習熟したイノベーションのプラクティスを積極的に取り入れることが不可欠となります。
これらの習熟したプラクティスには、次のようなものがあります。
- デザイン思考—優れたデータ製品を構築するためのエンタープライズ・データ・ドメインに適用される「困難な問題」を解決するための、実証済の手法
- 「Jobs to be done」理論——エンタープライズ・データ製品が真のビジネス課題を解決していることを確認するために、顧客重視のイノベーションと成果重視のイノベーション・プロセスを適用する

デザイン思考の手法は、部門横断的なイノベーションを阻む組織の縦割り構造を打破するのに役立つ実証済みのテクニックを提供します。「Jobs to be done」理論は、最終消費者の特定の目的、つまり「Jobs to be done」を達成するデータ製品を設計するための重要な基盤であり、製品の目的を定義するものです。
データ製品のアプローチは、当初はデータサイエンスのコミュニティから生まれたものでしたが、現在ではデータ管理のあらゆる側面に適用されています。データメッシュは、モノリシックなテクノロジー・アーキテクチャを構築することでなく、データ利用者とビジネス成果に焦点を当てます。
データ製品思考は他のデータ・アーキテクチャにも適用できますが、データメッシュには不可欠な要素です。データ製品思考をどのように適用するかの実用的な例として、Intuit社のチームが彼らの経験について詳細な分析を記しています。
データ製品
原材料から店頭の商品まで、あらゆる種類の製品は、価値ある資産として生産され、消費されることを意図し、特定の役割を担っています。データ製品は、ビジネスドメインや解決すべき問題によって様々な形態があり、以下のようなものがあります。
- 分析—履歴/リアルタイムのレポートとダッシュボード
- データセット—さまざまなシェイプ/フォーマットのデータコレクション
- モデル—ドメインオブジェクト、データモデル、機械学習(ML)機能
- アルゴリズム—MLモデル、スコアリング、ビジネスルール
- データサービスおよびAPI—ドキュメント、ペイロード、トピック、REST API、その他
データ製品は消費されるために作成され、通常IT部門外で所有されています。また、以下のような追加属性の追跡が必要となります。
- ステークホルダー・マップ—この製品を所有し、利用するのは誰か?
- パッケージングと文書化—どのように消費されるのか?どのようにラベル付けされるのか?
- 目的と価値—その製品の暗黙的・明示的な価値は何か?時間の経過による減価償却はあるか?
- 品質と一貫性—品質と使用のKPIとSLAは何か?検証可能か?
- 来歴、ライフスタイル、ガバナンス—データの信頼性と説明可能性があるか?
2. 分散型データ・アーキテクチャ

分散型ITシステムは今や現実のものとなりました。また、SaaSアプリケーションやパブリック・クラウド・インフラストラクチャ(IaaS)の台頭により、アプリケーションとデータの分散化は今後も続くと考えられます。アプリケーション・ソフトウェアのアーキテクチャは、かつての中央集権的なモノリスから、分散型のマイクロサービス(サービス・メッシュ)へと移行しつつあります。データ・アーキテクチャも同じように分散化の流れに乗り、データはより多様な物理的サイトや多くのネットワークに分散されるようになるでしょう。これを私たちはデータメッシュと呼んでいます。
メッシュとは?
メッシュとは、非階層的なノードの大きなグループが協調して作業することを可能にするネットワークトポロジです。
一般的な技術の例としては、以下のようなものがあります。
- WiFiMesh—多くのノードが協力してより良いカバレッジを実現
- ZWave/Zigbee—低電力のスマート・ホーム・デバイス・ネットワーク
- 5G mesh—信頼性と回復力の高いセル接続
- Starlink—世界規模での衛星ブロードバンド・メッシュ
- Service mesh—分散したマイクロサービス(アプリケーション・ソフトウェア)を統合的に制御する方法
データメッシュは、これらのメッシュの概念に沿ったもので、仮想/物理ネットワークや広大な距離にわたってデータを分散させる方法を提供します。ETLやデータ連携ツールなどのレガシーデータ統合モノリシック・アーキテクチャ、さらには最近ではAWS Glueなどのパブリック・クラウド・サービスでは、高度に集中化されたインフラストラクチャが必要とされます。
完全なデータメッシュ・ソリューションは、オンプレミス・システムから複数のパブリッククラウド、さらにはエッジネットワークに至るまで、マルチクラウドのフレームワークで動作可能であるべきです。
分散セキュリティ
データが高度に分散化された世界では、情報セキュリティの役割が最も重要です。高度に集中化されたモノリスとは異なり、分散システムでは、さまざまなレベルのアクセスに対してさまざまなユーザーを認証・認可するのに必要な作業を外部に委託しなければなりません。ネットワーク間で、セキュアに権限を与えることは、非常に困難です。
これには、いくつか考慮すべき点があります。
- 保存時の暗号化—ストレージに書き込まれたデータ/イベント
- 分散認証—mTLS、証明書、SSO、シークレットストア、データ保管庫など、サービスやデータストアのため
- 移動中の暗号化—インメモリで流れているデータ/イベント
- アイデンティティ管理—LDAP/IAMタイプのサービス、クロスプラットフォーム
- 分散認証—サービスエンドポイントがデータを冗長化するためのもの
例: Open Policy Agent(OPA)サイドカーで、マイクロサービスのエンドポイントが処理するコンテナ/K8Sクラスタ内に、ポリシー決定ポイント(PDP)を配置する。LDAP/IAMは、JWTに対応した任意のサービス。 - 決定論的マスキング—確実かつ一貫してPIIデータを難読化するためのもの
ITシステムのセキュリティは難しいものですが、分散システムで高いセキュリティを提供することはさらに困難です。しかし、これらは解決できない問題ではありません。
分散型データドメイン
データメッシュの基本的な考え方は、所有権と責任の分散という考え方です。ベストプラクティスは、データ製品およびデータドメインの所有権を、組織内でデータに最も近い立場の人々に分散させることです。実際には、これはソースデータ(例えば、記録/アプリケーションの運用システムなどの生のデータソース)または分析データ(例えば、データ消費者が簡単に消費できるようにフォーマットされた典型的な複合または集約データ)と一致する場合があります。どちらの場合も、データの作成者と消費者は、IT組織ではなくビジネス部門と連携していることが多くあります。
データ領域を組織化する古い方法は、ETLツール、データウェアハウス、データレイクなどのテクノロジー・ソリューションや、企業の構造的組織(人事、マーケティング、その他のビジネスライン)と連携する罠に陥りがちです。しかし、あるビジネス上の問題に対して、データドメインは、解決しようとする問題の範囲、特定のビジネスプロセスの文脈、あるいは特定の問題領域のアプリケーション群に最もよく合致していることが多いのです。大規模な組織では、これらのデータドメインは通常、社内の組織や技術のフットプリントにまたがっています。
データドメインの機能分解は、データメッシュにおいて第一級の優先度を持っています。ドメインモデリングのための様々なデータ分解手法は、データメッシュアーキテクチャに後付けすることが可能です。これには、古典的なデータウェアハウス・モデリング(KimballやInmonなど)やデータ保管庫モデリングが含まれます。しかし、現在データメッシュ・アーキテクチャで試みられている最も一般的な手法は、ドメイン駆動設計(DDD)です。DDDのアプローチは、マイクロサービスの機能分解から生まれ、現在ではデータメッシュの文脈で適用されています。
3. 移動中の動的データ
オラクルがデータメッシュの議論において追加した重要な分野があります。それは、最新のデータメッシュに欠かせない要素として、移動中のデータの重要性を高めることです。移動中のデータは、データメッシュをモノリシックで一元的なバッチ処理という従来の世界から脱却させるために不可欠です。移動中のデータの機能は、次のようなデータメッシュの核となるいくつかの疑問に答えるものです。
- ソース・アラインド・データ製品にリアルタイムでアクセスするにはどうすればよいのか?
- 物理的に分散化されたデータメッシュで、信頼できるデータ・トランザクションを分散させる手段を提供できるツールは何か?
- データイベントをデータ製品のAPIとして利用できるようにする必要がある場合、何を使えばいいのか?
- 常に最新でなければならない分析データ製品について、どのようにデータドメインに準拠させ、信頼性と妥当性を確保するか?
これらの疑問は、単なる「実装の詳細」の問題ではなく、データ・アーキテクチャそのものにとって極めて重要なものです。静的なデータに対するドメイン駆動設計は、同じ設計の動的な移動中のデータの処理とは異なるテクノロジーやツールを使用することになります。例えば、動的データ・アーキテクチャでは、データ台帳がデータイベントの中心的な唯一の情報源となります。
イベント駆動型データ台帳

元帳は、分散データ・アーキテクチャを機能させるための基本的な要素です。会計台帳と同じように、データ台帳は取引が発生するとその内容を記録します。
台帳を分散させると、データイベントはどの場所でも「再生可能」なものになります。台帳の中には、高可用性やディザスタ・リカバリのために使われる飛行機のフライトレコーダーのようなものもあります。
集中型やモノリシック型のデータストアとは異なり、分散型台帳は他の(外部の)システムで起こるアトミックイベントやトランザクションを追跡することを目的として作られています。
データメッシュは一種類の台帳ではありません。ユースケースや要件に応じて、データメッシュは以下のようなさまざまなタイプのイベント駆動型のデータ台帳を利用することができます。
- 汎用的なイベント台帳—KafkaやPulsarなど
- データイベント台帳—分散型CDC/レプリケーションツール
- メッセージングミドルウェア—ESB、MQ、JMS、AQなど
- ブロックチェーン台帳—セキュアで不変な複数の関係者間の取引向け
これらの台帳は、企業全体の耐久性のあるイベントログのようなものです。これにより、記録システムおよび分析システムで発生したデータイベントの実行リストが提供されます。
ポリグロット・データストリーム

ポリグロット・データストリームは、かつてないほど普及しています。これらのストリームは、イベントタイプ、ペイロード、トランザクションのセマンティクスによって異なります。データメッシュは、さまざまな企業データのワークロードに必要なストリームタイプをサポートする必要があります。
単純なイベント :
- Base64 / JSON—ロー、スキーマレス・イベント
- ローテレメトリ—スパース・イベント
基本的なアプリのロギング /IoT(Internet of Things)イベント:
- JSON/Protobuf— スキーマがある場合もあり
- MQTT—IoTに特化したプロトコル
アプリケーションのビジネス・プロセス・イベント:
- SOAP/REST イベント—XML/XSD、JSON
- B2B—交換プロトコルと基準
データイベント/トランザクション:
- 論理変更レコード—LCR、SCN、URID
- 一貫した境界線—コミット対オペレーション
ストリームデータ処理
ストリーム処理とは、イベントストリーム内でデータを操作する方法です。「ラムダ関数」とは異なり、ストリームプロセッサは、特定のタイムウィンドウ内のデータフローのステートフル特性を維持し、データに対してより高度な分析クエリを適用することができます。
- しきい値、アラート、テレメトリー監視
- RegEx関数、数学/ロジック、連結
- レコード単位、置換、マスキング
基本的なデータ・フィルタリング:
簡単なETL:
CEPと複雑なETL:
- 複雑なイベント処理(CEP)
- DML(ACID)処理、タプルのグループ化
- 集計、ルックアップ、複合結合
ストリーム分析:
- 時系列解析とカスタム時間ウィンドウ
- 地理空間、機械学習、組み込みAI
その他の重要な属性と原則
もちろん、データメッシュの属性は3つだけではありません。ここでは、オラクルが最新のデータメッシュ・アプローチの新しい独自の側面であると考える属性に注目し、上記の3つに焦点を当てました。
その他の重要なデータメッシュの属性は以下のとおりです。
- セルフサービス・ツール — データメッシュは、セルフサービスを目指すデータ管理全体のトレンドを取り入れています。データ所有者の一員がシチズン・デベロッパーとなるケースが多くなるでしょう。
- データガバナンス— データメッシュは、最高データ責任者、データスチュワード、データカタログベンダーが長年提唱してきた、より正式な統合型ガバナンスモデルを目指すというトレンドも取り入れています。
- データのユーザビリティ — データメッシュの原則を掘り下げると、データ製品のユーザビリティを確保するための基礎作業がかなり多くあります。データ製品は、価値があり、利用可能で、共有可能なデータであることが原則となります。
データメッシュの7つのユースケース
データメッシュが成功すれば、運用データだけでなく、分析データの分野でもユースケースを満たすことができます。以下の7つのユースケースから、データメッシュが企業データにもたらす機能の幅の広さをご覧いただけます。
リアルタイムの運用データと分析を統合することで、企業は業務上および戦略上のより良い意思決定を行うことができます。MIT Sloan School of Management
1. アプリケーションの最新化
モノリシック・データ・アーキテクチャの、クラウドへの「リフト&シフト」移行にとどまらず、多くの企業が過去の集中型アプリケーションを廃棄し、より最新のマイクロサービス・アプリケーション・アーキテクチャへの移行を模索しています。


しかし、レガシー・アプリケーションのモノリスは、通常、巨大なデータベースに依存しているため、移行計画をどのように段階的に進めれば、混乱やリスク、コストを減らせるかという疑問が出てきます。データメッシュは、モノリスからメッシュ・アーキテクチャへの段階的な移行を行うお客様に、重要な運用IT能力を提供することができます。たとえば、次の場合です。
- データベース・トランザクションのサブドメイン・オフロード(「コンテキスト境界」によるデータのフィルタリングなど)
- 段階的移行のための、双方向トランザクション・レプリケーション
- メインフレームからDBaaSへの移行など、クロスプラットフォームの同期化
マイクロサービスアーキテクトの専門用語で言うと、このアプローチは、双方向トランザクション送信ボックスを使用して、ストラングラー・フィグの移行パターン(一度に1つのコンテキスト境界)を可能にすることです。
2. データの可用性と継続性

業務上不可欠なアプリケーションは、回復力と継続性に関して非常に高いKPIとSLAが要求されます。これらのアプリケーションがモノリシックであろうと、マイクロサービスであろうと、あるいはその半々であろうと、ダウンは許されません。
ミッションクリティカルなシステムでは、通常、分散型の最終的整合性データモデルを受け入れることはできません。しかし、このようなアプリケーションは、多くのデータセンターで運用されなければなりません。このため、「正しい一貫性のあるデータを保証しながら、複数のデータセンターでアプリケーションを実行するにはどうすればよいか」という事業継続のための疑問が生まれます。
モノリシック・アーキテクチャが「シャーディングされたデータセット」を使用しているか、マイクロサービスがクロスサイト高可用性のために設定されているかにかかわらず、データメッシュはどんな距離にあっても正確で高速なデータを提供します。
データメッシュは、分散型でありながら、サイト間で100%正しいデータを提供するための基盤を提供することができます。たとえば、次の場合です。
- 非常に低レイテンシな論理トランザクション(クロスプラットフォーム)
- ACID対応による正しいデータの保証
- マルチアクティブ、双方向性、競合解決
3. イベントソーシングとトランザクション送信ボックス


最新のサービスメッシュ型プラットフォームでは、データ交換にイベントを使用します。データ層でのバッチ処理に依存するのではなく、アプリケーションやデータストアでイベントが発生すると、データ・ペイロードが連続的に流れます。
ある種のアーキテクチャでは、マイクロサービス間でデータ・ペイロードを交換する必要があります。また、モノリシックなアプリケーションやデータストア間で交換する必要があるパターンもあります。このことから、「マイクロサービスのデータ・ペイロードをアプリやデータストア間で確実に交換するにはどうしたらよいか?」という疑問が生まれます。
データメッシュは、マイクロサービス中心のデータ交換のための基盤となるテクノロジーを提供することができます。たとえば、次の場合です。
- マイクロサービスからマイクロサービスへ(コンテキスト内)
- マイクロサービスからマイクロサービスへ(コンテキスト間)
- モノリスからマイクロサービスへ/マイクロサービスからモノリスへ
イベントソーシング、CQRS、トランザクション送信ボックスなどのマイクロサービス・パターンは、一般的に理解されているソリューションです。データメッシュは、これらのパターンを大規模に再現可能かつ信頼できるものにするためのツールとフレームワークを提供します。
4. イベント駆動型の統合
マイクロサービスのデザインパターンを超えて、エンタープライズ統合の必要性は、データベース、ビジネス・プロセス、アプリケーション、あらゆる種類の物理デバイスなど、他のITシステムにも及びます。データメッシュは、移動中のデータを統合するための基盤を提供します。
移動中のデータは、通常、イベント駆動型です。ユーザーアクション、デバイスイベント、プロセス・ステップ、データストア・コミットはすべて、データ・ペイロードを持つイベントを開始することができます。これらのデータ・ペイロードは、Internet of Things(IoT)システム、ビジネス・プロセス、データベース、データウェアハウス、データレイクを統合する上で非常に重要です。
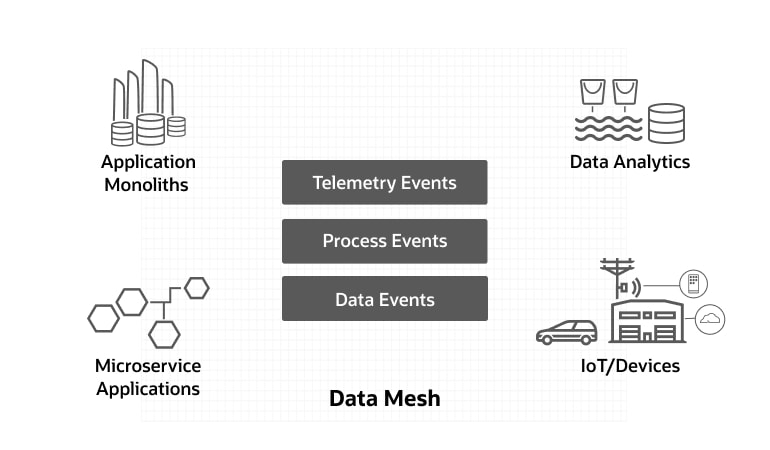
データメッシュは、企業全体のリアルタイム統合のための基盤となるテクノロジーを提供します。たとえば、次の場合です。
- 実際の設備イベントをITシステムに接続する
- ERPシステム間のビジネス・プロセスの統合
- 業務データベースと分析用データストアの連携
大規模な組織では、新旧のシステム、モノリスとマイクロサービス、業務用と分析用のデータストアが混在しています。データメッシュは、異なるビジネスとデータドメインにあるこれらのリソースを統一するのに役立ちます。
5. ストリーミング取り込み(分析用)

分析用データストアには、データマート、データウェアハウス、OLAPキューブ、データレイク、データレイクハウスなどのテクノロジーがあります。
一般的に、これらの分析用データストアにデータを取り込む方法は2つしかありません。
- バッチ/マイクロ・バッチ・ロード(タイム・スケジューラによる取り込み)
- ストリーミング取り込み(データイベントを継続的にロードする方法)
データメッシュは、ストリーミングデータ取り込み機能の基盤を提供します。たとえば、次の場合です。
- データベースやデータストアからのデータイベント
- 物理デバイスのテレメトリからのデバイスイベント
- アプリケーション・イベント・ロギングやビジネス・トランザクション
ストリームによるイベントの取り込みは、ソースシステムへの影響を軽減し、データの忠実性を高め(データサイエンスにとって重要)、リアルタイムな分析を可能にします。
6. ストリーミング・データ・パイプライン

分析用データストアに取り込まれた後、通常、さまざまなデータステージやデータゾーンでデータを準備し変換するためのデータパイプラインが必要になります。このデータ精製プロセスは、多くの場合、下流の分析データ製品に必要とされます。
データメッシュは、分析データストアと連携する独立したデータ・パイプライン・レイヤーを提供し、次のようなコアサービスを提供することができます。
- セルフサービスによるデータ発見とデータ準備
- ドメインにまたがるデータリソースのガバナンス
- データの準備と必要なデータ製品形式への変換
- 一貫性を確保するためのポリシーに基づくデータ検証
これらのデータパイプラインは、異なる物理データストア(マート、ウェアハウス、レイクなど)間で動作可能である必要があります。また、Apache Sparkやその他のデータレイクハウス技術など、ストリーミングデータをサポートする分析データプラットフォーム内の「プッシュダウン・データ・ストリーム」としても動作可能である必要があります。
7. ストリーミング分析

イベントは継続的に発生します。ストリーム中のイベントを分析することは、刻々と起こっていることを理解する上で非常に重要な意味を持つことがあります。
このようなリアルタイムのイベントストリームを時系列で分析することは、現実のIoTデバイスデータ、ITデータセンターで起きていること、あるいは不正監視などの金融取引全体で起きていることを理解するために重要かもしれません。
フル機能のデータメッシュには、さまざまな種類のイベント時間ウィンドウで、あらゆる種類のイベントを分析するための基礎的な機能が含まれています。たとえば、次の場合です。
- 簡単なイベントストリーム解析(Webイベント)
- ビジネス・アクティビティの監視(SOAP/RESTイベント)
- 複雑なイベント処理(マルチストリーム相関)
- データイベント分析(DB/ACIDトランザクション)
データパイプラインと同様に、ストリーミング分析は、確立されたデータレイクハウス・インフラストラクチャ内で実行することも、クラウドネイティブ・サービスとして個別に実行することも可能です。
データエステート全体で共通のメッシュを運用し、最大の価値を実現する
データ統合の最先端にいる人々は、弾力性のある多様なデータストアのコレクションから、リアルタイムの運用データと分析データを統合することを求めています。データ・アーキテクチャがストリーミング分析に進化するにつれ、テクノロジーの革新は絶え間なく、かつ急速に進んでいます。運用の高可用性は、リアルタイム分析につながります。また、データエンジニアリングの自動化により、データ準備が簡素化され、データサイエンティストやアナリストがセルフサービスツールを利用できるようになりました。
データメッシュのユースケースのまとめ

データエステート全体にわたる運用と分析のメッシュを構築する
これらのデータ管理機能をすべて統合アーキテクチャに組み込むことで、すべてのデータ消費者に影響を与えることができます。データメッシュは、グローバルな記録システムとエンゲージメント・システムをリアルタイムで確実に運用できるように改善し、そのリアルタイムデータを事業部門のマネージャー、データサイエンティスト、顧客に提供するのに役立ちます。また、次世代のマイクロサービス・アプリケーションのデータ管理も簡素化されます。最新の分析手法とツールを使用することで、エンドユーザーやアナリスト、データサイエンティストは、顧客の要求や競合他社の脅威にさらに迅速に対応できるようになります。文書化された例については、Intuitのゴールと結果をご覧ください。
ポイントプロジェクトでのデータメッシュの活用
新しいデータ製品の考え方と運用モデルを採用する際には、これらの実現技術の一つ一つについて経験を積むことが重要です。データメッシュを導入する際には、高速データ・アーキテクチャをストリーミング分析に進化させ、運用上の高可用性への投資をリアルタイム分析に活用し、データサイエンティストとアナリストにリアルタイムのセルフサービス分析を提供することで、段階的な利益を得ることができます。
比較対照表
| データ・ファブリック | アプリ開発の統合 | 分析用データストア | |||||
|---|---|---|---|---|---|---|---|
| データメッシュ | データ統合 | メタカタログ | マイクロサービス | メッセージ | データレイクハウス | 分散型DW | |
| 人、プロセス、メソッド: | |||||||
| データ製品重視 | 利用可 |
利用可 |
利用可 |
1/4 提供内容 |
1/4 提供内容 |
3/4 提供内容 |
3/4 提供内容 |
| 技術的なアーキテクチャの属性 : | |||||||
| 分散アーキテクチャ | 利用可 |
1/4 提供内容 |
3/4 提供内容 |
利用可 |
利用可 |
1/4 提供内容 |
3/4 提供内容 |
| イベント駆動型台帳 | 利用可 |
利用不可 |
1/4 提供内容 |
利用可 |
利用可 |
1/4 提供内容 |
1/4 提供内容 |
| ACIDサポート | 利用可 |
利用可 |
利用不可 |
利用不可 |
3/4 提供内容 |
3/4 提供内容 |
利用可 |
| ストリーム指向 | 利用可 |
1/4 提供内容 |
利用不可 |
利用不可 |
1/4 提供内容 |
3/4 提供内容 |
1/4 提供内容 |
| 分析データ重視 | 利用可 |
利用可 |
利用可 |
利用不可 |
利用不可 |
利用可 |
利用可 |
| 運用データ重視 | 利用可 |
1/4 提供内容 |
利用可 |
利用可 |
利用可 |
利用不可 |
利用不可 |
| 物理・論理メッシュ | 利用可 |
利用可 |
利用不可 |
1/4 提供内容 |
3/4 提供内容 |
3/4 提供内容 |
1/4 提供内容 |
ビジネスの成果
全体的なメリット
データドリブンのイノベーション・サイクルの高速化
ミッションクリティカルなデータ運用のコスト削減
運用の成果
マルチクラウド・データの流動性
- データ資本の自由な流れを可能にする
リアルタイムのデータ共有
- オペレーションからオペレーションへ、オペレーションから分析へ
エッジ、ロケーションベースのデータサービス
- IRLデバイス/データイベントの関連付け
信頼性の高いマイクロサービスによるデータ交換
- 正しいデータによるイベントソーシング
- データのためのDataOpsとCI/CD
中断のない継続性
- >99.999%以上のアップタイムSLA
- クラウドへの移行
分析成果
データ製品の自動化と簡素化
- マルチモデル・データセット
時系列データ分析
- デルタ/変更レコード
- イベントごとの忠実性
運用データストアのフルデータコピーの排除
- ログベースの台帳とパイプライン
分散型データレイクとウェアハウス
- ハイブリッド/マルチクラウド/グローバル
- ストリーミング統合/ETL
予測分析
- データの収益化、新しいデータサービスの販売
すべてを統合する
デジタル・トランスフォーメーションは非常に難しいため、残念ながらほとんどの企業では失敗に終わっています。長年にわたり、テクノロジー、ソフトウェア設計、データ・アーキテクチャはますます分散化され、現代のテクノロジーは高度に集中化されたモノリシックなスタイルから脱却しつつあります。
データメッシュは、データの新しいコンセプトであり、モノリシック、集中型、バッチスタイルのデータ処理とは対照的に、高度に分散したリアルタイムのデータイベントへと意図的にシフトしています。データメッシュの中核は、データ利用者のニーズを第一に考えるという、文化的な発想の転換です。また、分散型データ・アーキテクチャを強化するプラットフォームやサービスを向上させる、真の技術革新でもあります。
データメッシュのユースケースには、業務データと分析データの両方が含まれます。これは、従来のデータレイク/レイクハウスやデータウェアハウスとの大きな違いの1つです。このように運用データと分析データの領域を一致させることは、データ消費者のセルフサービスを促進するために重要なことです。最新のデータ・プラットフォーム技術は、データ生産者とデータ消費者を直接つなぐことで、中間業者を排除するのに役立ちます。
オラクルは、長年にわたりミッションクリティカルなデータソリューションの業界リーダーとして、信頼性の高いデータメッシュを実現するための最新機能を提供してきました。
- 33以上のアクティブ・リージョンを持つ、オラクルのGeneration 2 Cloudインフラストラクチャ
- 「シェイプシフトする」データ製品のためのマルチモデル・データベース
- すべてのデータストアを対象としたマイクロサービス・ベースのデータイベント台帳
- リアルタイムで信頼できるデータのためのマルチクラウド・ストリーミング処理
- APIプラットフォーム、最新のアプリ開発、セルフサービスツール
- 分析、データ可視化、クラウドネイティブ・データサイエンス