Big Data 平台
无缝扩展和运行 Apache Spark、Hive、Trino、Flink 等工具。利用熟悉的开源工具,通过 Data Science 记事本轻松进行开发和可视化,以极高的性价比获得强大功能。
了解 OCI Big Data 平台的功能




数据是机器学习的原始材料。了解如何在云端充分利用您的现有数据开展机器学习。
大数据集群可以轻松迁移到 OCI。请了解迁移准则。
利用数据湖整合所有数据
-
完备的集成式解决方案
部署一个完备的集成式解决方案,包括数据管理、数据集成和数据科学,帮助分析团队实现企业数据的最大价值。客户可通过批处理、流处理和实时处理方式提取数据,并根据需要将其存储在数据仓库或数据湖中。然后,团队对数据进行编目和应用治理,以便将其用于分析、可视化和机器学习模型。IT 团队在数据仓库和数据湖中采用一致的安全性策略。
-
易于管理和操作
利用可通过 API 访问的全托管式无服务器 Apache Spark 集群提高开发人员的工作效率。自动供应、保护和关闭每个集群,以减少开发人员的工作量。客户可以部署任意规模或款型的全托管式 Hadoop 集群,然后一键添加安全性和高可用性。
-
可部署在 Oracle Cloud 数据中心或客户数据中心
根据需要部署 Oracle 大数据服务,满足客户数据驻留和延迟要求。对于大数据服务以及所有其他 Oracle Cloud Infrastructure 服务,客户都可以在 Oracle Public Cloud 中使用,或者将其作为 Oracle Dedicated Region Cloud@Customer 环境的一部分部署在客户数据中心。
将大数据工作负载迁移到 OCI — 实现成本节省。
使用 OCI Big Data 服务顺利迁移到云端。无论您正在使用现有的数据湖、Spark、Hadoop、Flink、Hive 还是其它 Hadoop 组件,Oracle 全面、经过验证的方法都能够轻松迁移。您无需进行大量配置或集成即可迁移到 OCI,且对当前环境的影响极小。Oracle 工程师和合作伙伴将提供详细的分步资源和专家指导,确保您无缝迁移到云端。
使用 Apache Hadoop 将您的环境迁移到 OCI Big Data
- 完全托管:我们负责支持和管理 Apache Hadoop 和 Spark 生态系统,您只需在云中运行和扩展自己的大数据工作负载。
- 轻松迁移:将您的工作负载迁移到 OCI,并确保您以极高的性价比继续使用您熟悉的开源工具。
- 无缝集成:在 OCI 中统一所有数据应用的体验,并利用 Oracle Modern Data Platform。
Oracle 数据平台充分释放数据潜能
- 整合事务和分析数据 — 消除数据孤岛。
- 利用 Oracle IaaS 和 Oracle SaaS(或介于这两者之间的解决方案),选择所需的控制力。
- 将任何类型的数据导入平台 — 我们打破了结构化和非结构化数据之间的障碍。
- 了解 OCI 的强大功能以及它对其他云技术服务提供商的开放性 — 我们随时准备好为您服务。
- 使用 Oracle Analytics Cloud 报告或任何第三方分析应用 — OCI 具备开放性。
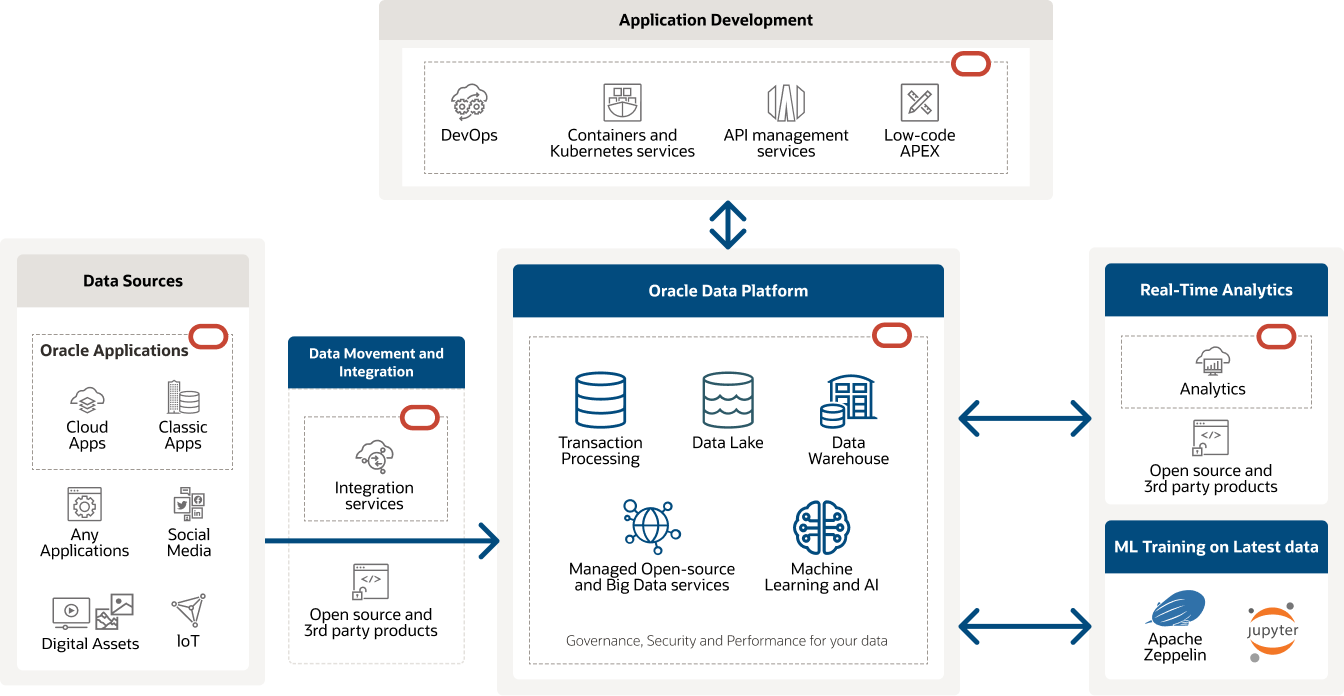 该图是 Oracle 数据平台概览图,分为数据源、数据迁移服务(如集成服务)、Oracle 现代数据平台(核心)以及结果(非必要)和应用开发服务几部分。
该图是 Oracle 数据平台概览图,分为数据源、数据迁移服务(如集成服务)、Oracle 现代数据平台(核心)以及结果(非必要)和应用开发服务几部分。 了解我们的客户如何使用 Big Data



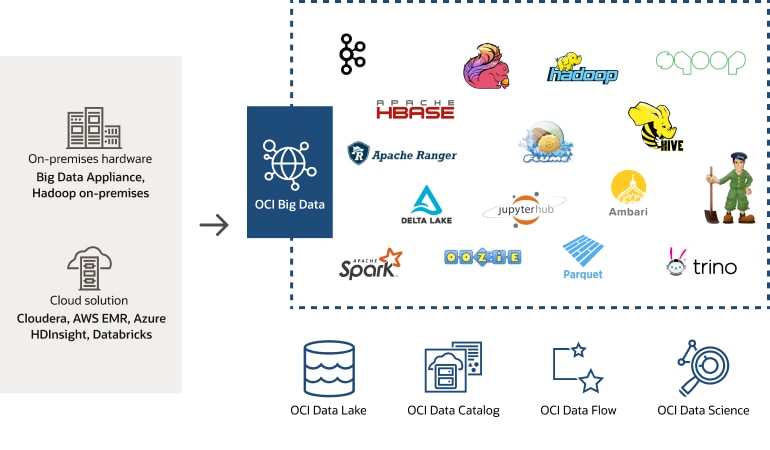
Oracle 提供的大数据服务
-
数据移动和集成
-
使用实时、一致的事务数据、高效的批量加载和流数据来连接和扩展分析应用。
- OCI Data Integration
使用无代码数据流设计器,简化复杂的数据提取、转换和加载流程 (ETL/E-LT),轻松地将数据“注入”数据湖和数据仓库,以供数据科学和分析使用。 - Oracle Data Integrator
Oracle Data Integrator 为提取、转换和加载提供高级数据迁移。Oracle Data Integrator 专门针对 Oracle 云数据库和本地部署数据库进行了优化。 - Oracle GoldenGate
Oracle GoldenGate 具有高可用性,支持实时数据集成、变更数据捕获、数据复制、转换,以及运营系统和分析系统间数据验证。 - OCI Streaming
OCI Streaming 为数百种跨类别的第三方产品提供开箱即用的集成功能,这些产品包括 DevOps、数据库、大数据和 SaaS 应用。
-
大数据和数据湖
-
通过开源平台满足大数据需求
- OCI Big Data
OCI Big Data 是一个基于 Hadoop 的数据湖服务,可用于存储和分析大量原始客户数据。作为一项托管服务,OCI Big Data 随带一个全面集成的体系,其中的开源工具和 Oracle 增值工具可有效简化 IT 运营。 - OCI Data Flow
OCI Data Flow 是一个全托管式 Apache Spark 服务,可高效处理超大型数据集,无需您部署或管理基础设施。这意味着开发人员不必管理基础设施,可以专注地开发进而快速交付应用。 - OCI Data Catalog
OCI Data Catalog 有助于企业的数据专业人员使用整个企业的数据资产清单来搜索、探究和治理数据。 - OCI Object Storage
OCI Object Storage 支持您以原生格式存储任意类型的数据,非常适合用于构建灵活、可扩展的现代应用。
-
人工智能和机器学习
-
利用预构建 AI 模型或者自行创建模型,从数据中获取洞察。
- OCI AI Services
OCI AI Services 是一组采用预构建机器学习模型的服务,可帮助开发人员更轻松地将 AI 应用到应用和业务运营中。您可以对这些模型进行自定义训练,以获得更准确的业务结果。 - OCI Data Science
利用专为团队构建的数据科学服务来快速构建、训练、部署和管理机器学习模型。 - Machine Learning in Oracle Database
Machine Learning in Oracle Database 支持规模化数据探索、准备和机器学习建模。 - MySQL HeatWave AutoML
MySQL HeatWave AutoML 免费为用户提供在 MySQL HeatWave 中构建、训练、部署和解释机器学习模型所需的一切资源。
OCI 上的大数据架构
Oracle 利用新的开源数据管理解决方案扩展云技术服务
产品管理高级总监 Carter Shanklin
Oracle Cloud Infrastructure (OCI) 很高兴地宣布推出三个新的托管开源数据管理云技术服务,以及现有服务的三个重要增强。这些服务提供丰富的功能,可帮助各种规模的组织增强数据运营。
赶快行动
享用 Always Free 云技术服务,并试用 30 天的收费服务
Oracle 提供的免费套餐包含了 Autonomous Data Warehouse、OCI Compute 和 Oracle Storage 等服务,另外还有 300 美元的免费储值,让您可以试用更多云技术服务。立即获取详细信息并注册您的免费账户。
-
Oracle Cloud 免费套餐包含哪些内容?
- 永久免费
- 2 个 Autonomous AI Database 实例,各 20 GB
- 计算虚拟机
- 100 GB 块存储卷
- 10 GB 对象存储
-
使用 Oracle Autonomous AI Database 和 OCI Data Catalog 访问数据湖
本研讨会中的动手实践将指导您使用 Oracle Autonomous AI Database 和 OCI Data Catalog 访问通过 Oracle Object Storage 桶创建的数据湖。
开始数据湖访问动手实践 -
Oracle Big Data Service 快速入门
了解如何使用 Oracle Big Data Service 和 OCI 来创建和监视高可用性 Hadoop 集群。您还将向集群中添加 Oracle Cloud SQL 并访问实用程序和主节点,了解如何使用 Cloudera Manager 和 Hue 直接在 Web 浏览器中访问集群。
开始数据湖动手实践 -
了解甲骨文红牛车队如何使用分析和机器学习
甲骨文红牛车队使用分析和机器学习技术分析 70 年来的比赛数据,发现了赛车与其他更加可预测的比赛相比,让人充满兴奋感的背后原因。
开始数据分析动手实践 -
Oracle Cloud Infrastructure Anomaly Detection 快速入门
了解如何使用 OCI Anomaly Detection 创建自定义机器学习模型。您将获取用户上传的数据,使用专用算法来训练模型,并将模型部署到云环境中来检测异常。
开始异常检测动手实践
-
专家能为您解答以下问题:
- 如何开始使用 Oracle 数据湖?
- 数据湖能够提供哪些数据仓库无法提供的功能?
- 企业能够使用数据湖获得哪些收益?
注:为免疑义,本网页所用以下术语专指以下含义:
- 除Oracle隐私政策外,本网站中提及的“Oracle”专指Oracle境外公司而非甲骨文中国。
- 相关Cloud或云术语均指代Oracle境外公司提供的云技术或其解决方案。