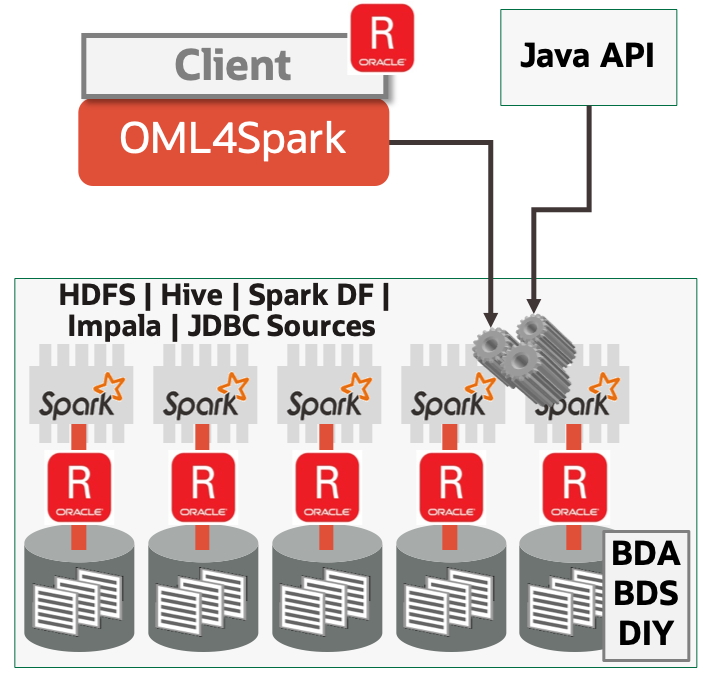
Oracle Machine Learning for Spark
Oracle Machine Learning for Sparkは、Oracle R Advanced Analytics for Hadoopによってサポートされます。SparkおよびHadoop環境に対応したR APIを通じて、データ・サイエンティストやアプリケーション開発者が機械学習モデルを構築してデプロイするための、きわめて拡張性の高い機械学習アルゴリズムを提供します。
Oracle Machine Learning for Spark
OML4Spark R APIは、ローカルのファイルシステム、HDFS、HIVE、Spark DataFrames、Impala、Oracle Database、およびJDBCソースに格納されているデータを操作するための機能を提供します。OML4Sparkは、Hadoopクラスタのすべてのノードを利用して、ビッグデータ環境におけるスケーラブルで高パフォーマンスの機械学習モデルを実現します。OML4Spark機械学習アルゴリズムは、Sparkのパラレル実行向けに最適化された、分かりやすいR計算式オブジェクトを使用します。
OML4Sparkにより、カスタム線形モデル(LM)、一般化線形モデル(GLM)、およびMLPニューラル・ネットワーク・アルゴリズムがSparkインフラストラクチャで実行されます。OML4SparkはApache SparkMLアルゴリズムへのインタフェースを提供しますが、OML4SparkアルゴリズムはSparkMLよりもスケーラビリティとパフォーマンスに優れていることに注意してください。R関数は、R計算式仕様およびDistributed Model Matrixデータ構造を使用して、OML4Sparkフレームワーク内にSparkMLアルゴリズムをラップします。
Oracle Cloud SQLとOML4SparkをOracle DatabaseまたはAutonomous Databaseと組み合わせることによって、検出されるべきソースデータとパターンがビッグデータ、リレーショナルデータ、またはこの2つの組み合わせの中に存在するような、大規模で複雑なデータ主導の問題に対処できます。OML4Sparkは、データベース外部での機械学習処理向けに、または大規模で複雑な機械学習パイプラインの強力なコンポーネントとして、さまざまなオプションを提供します。
製品詳細
すべて開く すべて閉じる機能概要
- 自然なR APIから、スケーラブルな分散型の機械学習アルゴリズム、データ準備、データ探索、統計分析を使用
- Hadoopクラスタのすべてのノードを利用して、ビッグデータ環境におけるスケーラブルで高パフォーマンスの機械学習モデルを実現する、並列で分散された機械学習アルゴリズム
- Sparkベースのカスタム線形モデル、一般化線形モデル、およびMLPニューラル・ネットワーク・アルゴリズム
- R計算式およびDistributed Model Matrixインフラストラクチャを使用する、Apache SparkMLとのインタフェース
- Sparkのパラレル実行向けに最適化された、分かりやすいR計算式オブジェクトを使用した関数
- モデルと結果をHDFSまたはファイルシステムに保存して、実稼働環境などの他のビッグ・データ・クラスタにロードして実行
ビジネス上のメリット
- Rインタフェースを介して、ビッグデータクラスタを高パフォーマンスのコンピュート環境として利用
- HIVE、Impala、SparkSQLを利用して、簡略化されたR APIから大規模なデータセットを処理
- データ移動を最小限に抑制
- Rコミュニティによって提供されるRパッケージを使用
- OCIを介してOracle Databaseからのデータを統合し、JDBCを介して他の環境からのデータを統合
主な機能
透過性レイヤー - R data.frameプロキシオブジェクトを利用することで、データはHIVE/Impalaのテーブルやビューとして保持されます。オーバーロードされたR関数により、選択したR機能がクラスタ処理用の同等のSQLに変換され、並列処理、スケーラビリティ、およびセキュリティが強化されます。データ・サイエンティストは使い慣れたR構文を使用して、クラスタに保持されたデータベースデータを操作できます。
機械学習アルゴリズム - Rユーザーは、選択したSpark MLアルゴリズム、およびR言語を使用して、並列分散アルゴリズムによるOracle Machine Learning for Sparkのライブラリを利用できます。ユーザーは、使い慣れたR計算式構文を使用して機械学習モデルを指定できます。アルゴリズムは、分類、回帰、クラスタリング、および特徴抽出をサポートします。
Sparkデータフレームの操作 - RのSparkデータフレーム・プロキシ・オブジェクト上で特殊関数(SQLを含む)を直接管理および呼び出して、クラスタで実行することができます。ランダムサンプリング、データ分割、データの一覧表示、および出力に至るまで、このインタフェースはデータを操作、作成し、データをSparkに対してプッシュおよびプルするための独自の機能を提供します。
その他の機能
OAAgraph - Oracle Spatial and Graphに存在する強力なグラフ分析機能の利用に興味があるユーザー向けに、Oracle Machine Learning for Sparkとの互換性があり、Sparkベースの機械学習アルゴリズム、およびParallel Graph AnalytiX(PGX)エンジンの操作を容易にする、OAAgraphパッケージが用意されています。Oracle Machine Learning for SparkのRを使用したデータの準備、モデルの構築とデータのスコアリングによるグラフデータおよび分析の強化、グラフメトリクスの計算による、Spark機械学習アルゴリズムに提供されるデータの強化といったさまざまな機能はすべて、モデル品質とグラフ分析の向上を目的としています。