
Pick Upテクノロジー
シバタツ流! DWHチューニングの極意
第2回 データ・ローディング
第1回では初期化パラメータと表領域に対して、データウェアハウスに最適なチューニングを行いました。今回はこのデータベースと表領域に、どのようにして高速にデータをローディングするかをご紹介します。大量のデータを扱うデータウェアハウスではデータ・ローディングは大きな時間を占めるでしょうから、ここの高速化は重要です。
■外部表の使用
私がローディングするときに使う方法はSQL*Loaderではなく外部表です。「ローディング=SQL*Loader」と考える方も多いでしょうが、外部表を使ったローディングにはSQL*Loaderにはない、さまざまなメリットがあります。
そもそも外部表とはなんでしょう? 通常の表では表の定義もデータ自体もデータベース内に格納されていますが、外部表では表の定義はデータベース内にあるものの、データ自体はデータベースの外にフラット・ファイルの形式で保存されています。たとえば以下のようなCSVファイルをデータとする外部表を定義してみましょう。
/tmp/employees.csv
198,Donald,OConnell,50
199,Douglas,Grant,50
200,Jennifer,Whalen,10
201,Michael,Hartstein,20
202,Pat,Fay,20
CREATE DIRECTORY datadir AS '/tmp';
GRANT READ, WRITE ON DIRECTORY datadir TO user1;
CREATE TABLE employees_xt (
employee_id NUMBER(6),
first_name VARCHAR2(20),
last_name VARCHAR2(25),
department_id VARCHAR2(4)
)
ORGANIZATION EXTERNAL (
TYPE ORACLE_LOADER
DEFAULT DIRECTORY datadir
ACCESS PARAMETERS (
RECORDS DELIMITED BY NEWLINE
FIELDS TERMINATED BY ',' (
employee_id,
first_name,
last_name,
department_id
)
)
LOCATION ('employees.csv')
)
;
このEMPLOYEES_XT外部表をSELECTすると結果は通常の表と同様に表示されますが、データはまだCSVファイルのままであってデータベース内には存在しません。このように外部表は通常の表のようにSELECTすることが可能ですが、一部の機能が制限されていたりパフォーマンスで劣る点があったりするので、2度以上読み取る場合は通常の表に INSERT SELECT でコピーすることをお勧めします。このコピーこそがフラット・ファイルから通常の表へのロードを意味します。
ALTER SESSION FORCE PARALLEL QUERY;
ALTER SESSION FORCE PARALLEL DDL;
INSERT /*+ APPEND */ INTO employees
SELECT * FROM employees_xt
;
さて、SQL*Loaderにはない外部表からのINSERT SELECTのメリットとはなんでしょうか。まず、INSERT SELECT時点でELT処理(抽出変換加工処理)が行えます。たとえば以下ではDEPARTMENT_ID列が10の場合はNULLに書き換え、それ以外の場合は先頭にAを追加しながらロードしています。ほかにも特定の条件にマッチする行だけロードする、複数表を結合しながらロードする、なんてこともSQLなので簡単に実現できるでしょう。
INSERT /*+ APPEND */ INTO employees
SELECT
employee_id,
first_name,
last_name,
CASE department_id
WHEN '10' THEN NULL
ELSE 'A' || department_id
END
FROM employees_xt
;
また、Oracle Database 11g Release 2 (11.2.0) からは、PREPROCESSOR句を使用してGZIPなどで圧縮されているファイルを事前に展開することなく、展開と同時にロードすることができるようになりました。これによってローディング時間とディスク使用量を減らすことができるでしょう。プリプロセッサ・プログラムには、標準入力から入力して標準出力から出力するものであれば、アーカイバに限らずシェル・スクリプトなども指定できます。
......
ACCESS PARAMETERS (
......
PREPROCESSOR execdir:'zcat'
......
)
......
さらに、データ・ローディングは1つのSQLにすぎないため、AWRのSQL Statisticsに通常のSQLと同じようにリストされたり、SQL監視レポートが取得できたりします。特にSQL監視レポートが取得できる点は、ローディングのパフォーマンス・チューニングにおいて極めて重要です。(SQL監視については今後の連載で詳しく取り上げます。以下の資料も参考にしてください)
オラクルエンジニア通信:「【セミナー動画/資料】複雑なSQLチューニングもラクにする!SQL監視機能とは」
■パラレル・ロード
大量のデータを高速にローディングするにはパラレルで実行することが必須でしょう。パラレルで実行しないと、外部表であれば1つのサーバー・プロセス、SQL*Loaderであれば1つのsqlldrプロセスがボトルネックになってしまい、CPUもストレージも使いきれません。
SQL*LoaderでもPARALLELパラメータをTRUEにして、複数のSQL*Loaderを同時に起動すればパラレル・ロードが可能です。
sqlldr USERID=user1 CONTROL=load1.ctl PARALLEL=TRUE &
sqlldr USERID=user1 CONTROL=load2.ctl PARALLEL=TRUE &
sqlldr USERID=user1 CONTROL=load3.ctl PARALLEL=TRUE &
wait
しかし、Oracle Real Application Clusters (Oracle RAC) を使用していても、SQL*Loaderは1つのノード上でしかパラレルに実行できません。一方、外部表からのINSERT SELECTでは、インターノード・パラレル実行によって、すべてのノードを使ったパラレル・ロードが行われます。外部表からのINSERT SELECTをパラレルで実行するには、INSERT SELECTの前に挿入元となる外部表と挿入先となる表の両方にPARALLEL句をつけてALTER SESSION ENABLE PARALELL DMLを実行するか、ALTER SESSION FORCE PARALLEL QUERYとALTER SESSION FORCE PARALLEL DML を実行してください。PARALLEL句がついていればパラレル・クエリーは自動で実行されますが、パラレルDMLは自動では実行されない点に注意してください。
ALTER TABLE source_external_table PARALLEL;
ALTER TABLE target_table PARALLEL;
ALTER SESSION ENABLE PARALLEL DML;
ALTER SESSION FORCE PARALLEL QUERY;
ALTER SESSION FORCE PARALLEL DML;
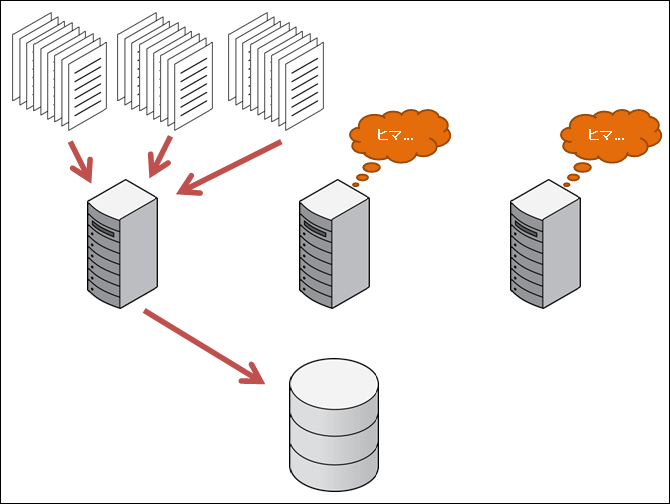
SQL*Loaderの場合のパラレル・ロード
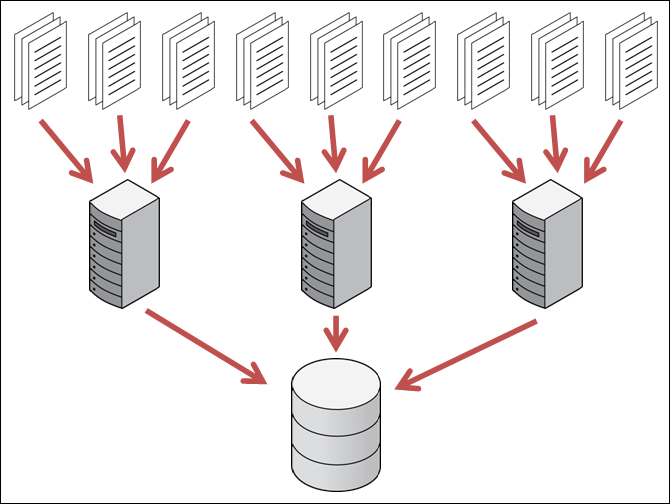
外部表からのINSERT SELECTによるパラレル・ロード
パラレル・ロードをするときにSQL*Loaderに比べて外部表からのINSERT SELECTのほうが良い点はほかにもあります。SQL*Loaderでパラレルに実行するにはフラット・ファイルを事前に分割しておく必要がありますが、外部表からのINSERT SELECTでは、圧縮されていないフラット・ファイルが「US7ASCIIなどのシングルバイト・キャラクタ・セットかAL32UTF8」または「固定長フォーマット」の場合、1つのフラット・ファイルからでもパラレル・ロードが行えます。
また、SQL*Loaderの場合は、万が一パラレルで実行したうちの1プロセスだけが失敗した場合、目的のデータの一部だけがローディングされている状態になっているので、エラー処理をユーザーがスクリプトなどで準備する必要があります。空の表にローディングしているならTRUNCATEで済むかもしれませんが、追記だった場合なんかはエラー処理も大変です。一方、パラレルDMLの場合は、ROLLBACKするだけできれいに元に戻ります。
なお、パラレル・ロード時のパラレル度が高すぎると、競合が発生してローディングが遅くなる場合があります。SQL監視などで競合が見受けられる場合は、SQL*Loaderであれば同時実行プロセス数を減らし、外部表からのINSERT SELECTであればALTER SESSION文などでパラレル度を下げてみましょう。
ALTER SESSION FORCE PARALLEL QUERY PARALLEL 16;
ALTER SESSION FORCE PARALLEL DML PARALLEL 16;
■ダイレクト・パス・ロード
ローディングには通常のINSERTと同じようにデータが挿入されていく従来型パス・ロードと、バッファ・キャッシュなどを使用せずにデータ・ブロックに直接書き込むダイレクト・パス・ロードの2種類があります。ダイレクト・パス・ロードは従来型パス・ロードに比べてはるかに高速ですので、特別な理由のない限りはダイレクト・パス・ロードを使用しましょう。
SQL*LoaderでもDIRECTパラメータをTRUEにすることで、ダイレクト・パス・ロードが可能です。
sqlldr USERID=user1 CONTROL=load1.ctl DIRECT=TRUE
外部表からのINSERT SELECTではAPPENDヒントをつけます。
INSERT /*+ APPEND */ TO target_table
SELECT * FROM source_external_table
;
表にNOLOGGING句をつけておくとダイレクト・パス・ロードに関するREDOログが作成されなくなります。データウェアハウスのローディングには一般的にREDOログは必要ないので、NOLOGGINGの使用を検討してください。
ALTER TABLE target_table NOLOGGING;
パーティション・エクスチェンジ・ロード
ロード先がパーティション表である場合、パーティション・エクスチェンジ・ロードを使うことでさらに高速にすることができます。パーティション・エクスチェンジ・ロードについては次回のパーティションの記事で紹介したいと思います。
■データ・ローディング前の列使用統計情報の取得
統計情報を取得するDBMS_STATS.GATHER_TABLE_STATSなどのプロシージャのmethod_optのデフォルトは、Oracle Database 10g Release 1 (10.1.0) からFOR ALL COLUMNS SIZE AUTOになっています。AUTOの場合、対象列が過去に条件式として使われたかどうかという列使用統計情報を使用するので、使われていない列にはヒストグラムを作成しません。そのため、データ・ローディング前の空の表に対してすべてのクエリーを実行しておくと、完全な列使用統計情報が取得でき、ヒストグラムが必要な列に最初から自動で作成されます。もちろん、データが入ってからクエリーを流しても列使用統計情報は取得されますが、空の表の時点ではすべてのクエリーが一瞬で完了するので時間短縮になります。
統計情報取得前にクエリーを実行できず、しかもシステム稼働後には統計情報を再取得しない場合、FOR ALL COLUMNS SIZE AUTOではヒストグラムがまったく作られないことを意味します。また、使われていれば必ずヒストグラムを作るわけではなく、データの偏りなども考慮してヒストグラムの必要性が自動で判断されますので、ヒストグラムが確実に必要な場合はAUTOではなく、バケット数を手動で設定してください。
■データ・ローディング後の索引再作成
ローディング先の表に索引が存在していると、ローディングしながら索引のメンテナンスが行われます。これを回避するために、ローディングを始める前に索引を削除してしまうことを検討してください。たとえば空の表にローディングする場合のように、表の全行数に対してローディングする行数が多い場合は、索引を一度削除してしまってローディング後に再作成したほうが高速です。索引を再作成するときにはパラレルDDLで行うことをお忘れなく。
■フラット・ファイルのフォーマット
フラット・ファイルのフォーマットを事前に定義できるのであれば、以下の点に注意して定義することで高速にローディングできるようになります。
- 固定長フォーマットのほうがCSVなどの可変長フォーマットよりもはるかに高速にローディングできます。
- データファイルのキャラクタ・セットとデータベースのキャラクタ・セットが同じであるほうが高速にローディングできます。
- データファイルのデータ型とデータベースのデータ型が同じであるほうが高速にローディングできます。
- JA16SJISのような可変長キャラクタ・セットの場合、列長セマンティクスがバイト単位 (BYTE) のほうが文字単位 (CHAR) よりも高速にローディングできます。
オラクルエンジニア通信:「【セミナー動画/資料】意外と知らない?! データローディングの基礎」 次回は「パーティショニング」に関する極意を伝授します!

■シバタツより
Oracle Exadataリリース当初から、お客様のSQLやデータを使用したPoC (Proof of Concept) を実施し続け、本番稼働しているたくさんのシステムのパフォーマンス・チューニングを行ってきました。2010年には米オラクルの開発部門に所属し、米国のお客様のPoCを実施しつつ、そこから見えてきたOracle Databaseのパフォーマンス課題の解決に取り組みました。
日米どちらのPoCでも共通に、いつも思うことは「もっとシンプルでいいのに」ということです。Oracle Databaseにはたくさんのパラメーターやらなんやらがありますが、OLTPでは効果があっても、データウェアハウスではほとんど効果がないどころか、逆に遅くなるだけということも。そこでこの連載では、データウェアハウスのパフォーマンス・チューニングに本当に効果があることだけにポイントを絞ってご紹介していきたいと思います。これらのチューニング手法はExadataに限ったものではなく、Oracle Databaseすべてにおいて使えるものですので、多くの方の参考になればと思います。
日本オラクル株式会社 テクノロジー製品事業統括本部 技術本部 Exadata技術部 プリンシパルエンジニア 柴田竜典(しばたたつのり)