AI 인프라
분산형 클라우드를 통해 프론티어 모델 훈련 및 추론, 에이전틱 AI, 과학 컴퓨팅, 추천 시스템 등 가장 까다로운 AI 워크로드를 어디서든 더 빠르게 실행할 수 있습니다. 최대 131,072개 GPU를 통한 제타스케일 컴퓨팅 성능을 제공하는 Oracle Cloud Infrastructure(OCI) Supercluster를 직접 사용해 보세요.

NVIDIA GTC의 Oracle 세션 참가하기
2026년 3월 16~19일
캘리포니아주 산호세 현장 및 가상 이벤트
-
![]() 2026년의 비즈니스에 영향을 미칠 AI 트렌드
2026년의 비즈니스에 영향을 미칠 AI 트렌드
Oracle의 웨비나 시리즈를 통해 귀사의 대비 태세를 유지하기 위한 방법을 확인해 보세요.
-
![]() First Principles: Zettascale OCI Superclusters
First Principles: Zettascale OCI Superclusters
OCI의 최고 아키텍트들이 소수의 GPU부터131,072개의 NVIDIA Blackwell GPU를 탑재한 제타스케일 OCI Supercluster까지 유연하게 확장 가능한 OCI 클러스터 네트워크로 생성형 AI를 지원하는 방법을 소개합니다.
![]() AI 활용 사례: 지금 주목해야 할10가지 최첨단 혁신 기술
AI 활용 사례: 지금 주목해야 할10가지 최첨단 혁신 기술
기업이 유지 보수를 수행하고, 고객과 소통하고, 데이터를 보호하고, 의료 서비스를 제공하는 방법을 재구성할 수 있는 획기적인 AI 기반 기술 10가지를 살펴보세요.
-
![]() AMD Instinct MI300X에 대한 Enterprise Strategy Group의 견해
AMD Instinct MI300X에 대한 Enterprise Strategy Group의 견해
AMD GPU를 탑재한 OCI AI 인프라에 대한 분석가들의 견해, 해당 조합이 생산성 향상, 가치 창출 시간 단축, 에너지 비용 절감에 기여하는 이유를 확인해 보세요.




Oracle과 NVIDIA의 공동 혁신
Oracle과 NVIDIA가 고객의 AI 도입 가속화를 위해 협력하는 방법을 확인해 보세요.
OCI AI 인프라를 선택하는 이유

성능 및 가치
OCI의 독보적인 GPU 베어메탈 인스턴스와 초고속 RDMA 클러스터 네트워킹으로 지연 시간을 최소 2.5마이크로초로 단축시키고 AI 훈련을 강화할 수 있습니다. GPU VM 관련 더 나은 가격 정책을 이용해 보세요.

HPC 스토리지
OCI File Storage는 고성능 마운트 타깃(HPMT)과 Lustre를 통해 테라바이트급의 초당 처리량을 지원합니다. GPU 인스턴스 업계에서 가장 큰 용량인 61.44TB의 NVMe 저장 공간을 사용해 보세요.

소버린 AI
Oracle의 분산 클라우드 서비스는 고객이 원하는 모든 지점에 AI 인프라를 배포해 성능, 보안, AI 주권 관련 요구 사항을 충족시켜 줍니다. 어디서든 소버린 AI를 제공하는 Oracle과 NVIDIA의 파트너십을 살펴보세요.
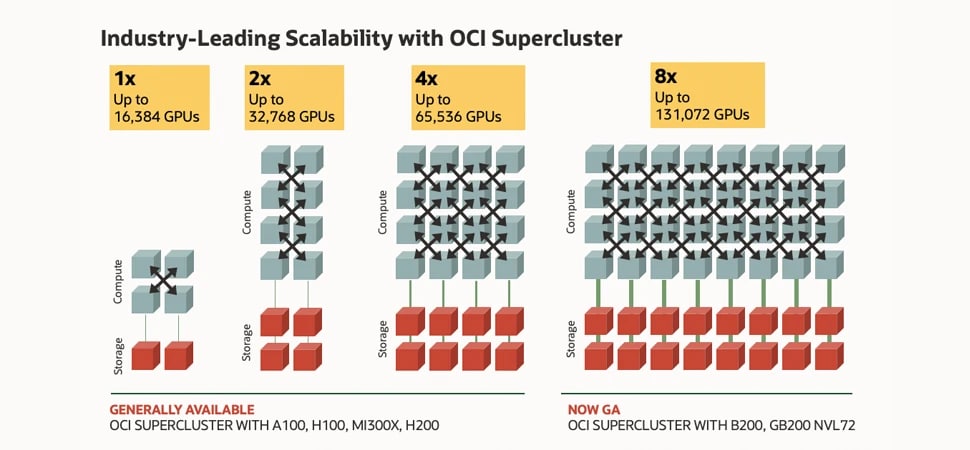 이 이미지는 클러스터 네트워킹 선을 따라 연결되는 컴퓨트 및 스토리지를 나타내는 상자를 보여주고 있습니다. 맨 왼쪽에는 16,000개 NVIDIA H100 GPU가 탑재된 가장 작은 클러스터의 컴퓨팅 상자 4개와 스토리지 상자 2개가 표시되어 있습니다. 그 오른쪽에는 32,000개 NVIDIA A100 GPU가 탑재된 클러스터의 컴퓨팅 상자 8개와 스토리지 상자 4개가 표시되어 있습니다. 다음으로는 64,000개 NVIDIA H200 GPU 클러스터의 컴퓨팅 상자 16개와 스토리지 박스 8개가 표시되어 있습니다. 마지막으로 가장 오른쪽에는 128,000개 NVIDIA Blackwell 및 Grace Blackwell GPU 클러스터의 컴퓨팅 상자 32개와 스토리지 상자 16개가 표시되어 있습니다. 이는 가장 왼쪽의 가장 작은 16,000개 GPU 구성에서 가장 오른쪽의 가장 큰 128,000개 GPU 구성을 비교해 보았을 때 OCI Supercluster의 확장성이 최대 8배 증가됨을 나타냅니다.
이 이미지는 클러스터 네트워킹 선을 따라 연결되는 컴퓨트 및 스토리지를 나타내는 상자를 보여주고 있습니다. 맨 왼쪽에는 16,000개 NVIDIA H100 GPU가 탑재된 가장 작은 클러스터의 컴퓨팅 상자 4개와 스토리지 상자 2개가 표시되어 있습니다. 그 오른쪽에는 32,000개 NVIDIA A100 GPU가 탑재된 클러스터의 컴퓨팅 상자 8개와 스토리지 상자 4개가 표시되어 있습니다. 다음으로는 64,000개 NVIDIA H200 GPU 클러스터의 컴퓨팅 상자 16개와 스토리지 박스 8개가 표시되어 있습니다. 마지막으로 가장 오른쪽에는 128,000개 NVIDIA Blackwell 및 Grace Blackwell GPU 클러스터의 컴퓨팅 상자 32개와 스토리지 상자 16개가 표시되어 있습니다. 이는 가장 왼쪽의 가장 작은 16,000개 GPU 구성에서 가장 오른쪽의 가장 큰 128,000개 GPU 구성을 비교해 보았을 때 OCI Supercluster의 확장성이 최대 8배 증가됨을 나타냅니다.
NVIDIA Blackwell 및 Hopper GPU가 탑재된 OCI Supercluster
최대 131,072개의 GPU로 8배 확장성 향상
OCI Supercluster는 네트워크 패브릭 혁신을 통해 최대 131,072개 NVIDIA B200 GPU, 100,000개 이상의 NVIDIA Grace Blackwell Superchip의 Blackwell GPU, 65,536개 NVIDIA H200 GPU까지 확장할 수 있습니다.
고객의 모든 요구 사항을 충족하는 OCI AI 인프라
OCI는 생성형 AI와 관련하여 추론, 미세 조정, 대규모 수평 확장 모델의 학습 등을 수행하고자 하는 고객을 위해 관련 요건에 부합하는 초고대역폭 네트워크 및 고성능 스토리지를 갖춘 업계 최고의 베어메탈 및 가상머신 GPU 클러스터 옵션을 제공합니다.
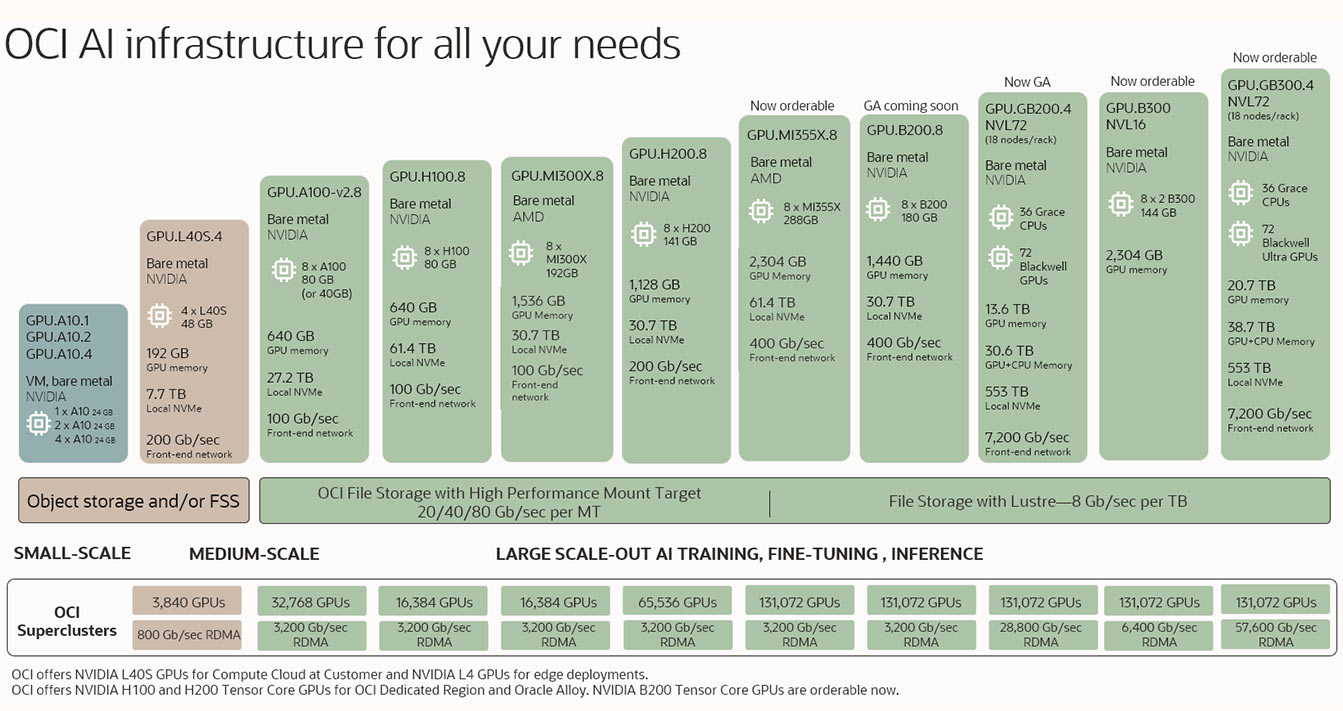 이 이미지는 왼쪽 하단의 가장 소규모 구성으로 시작하여 중간 규모 및 대규모 구성으로 점진적으로 증가하는 여러 AI 인프라 제품을 보여줍니다. 가장 작은 구성은 GPU 1개가 탑재된 가상 머신이고, 가장 큰 구성은 GPU 100,000개 이상이 탑재된 RDMA 클러스터입니다.
이 이미지는 왼쪽 하단의 가장 소규모 구성으로 시작하여 중간 규모 및 대규모 구성으로 점진적으로 증가하는 여러 AI 인프라 제품을 보여줍니다. 가장 작은 구성은 GPU 1개가 탑재된 가상 머신이고, 가장 큰 구성은 GPU 100,000개 이상이 탑재된 RDMA 클러스터입니다. 6월 11일, OCI와 NVIDIA RTX PRO로 운영 환경의 AI를 지원하는 방법을 확인해 보세요.
대규모 AI 학습용 OCI Supercluster 살펴보기
NVIDIA Blackwell 및 Hopper를 활용한 대규모 확장 클러스터
최고의 컴퓨트
• 하이퍼바이저 오버헤드가 없는 베어메탈 인스턴스
• NVIDIA Blackwell(GB200 NVL72, HGX B200),
Hopper(H200, H100), 및 이전 세대 GPU 지원
• AMD MI300X GPU 옵션 지원
• 내장 하드웨어 가속을 위한 데이터 처리 장치(DPU)
대용량 및 고처리량 스토리지
• 로컬 스토리지: 최대 61.44TB NVMe SSD 용량
• 파일 스토리지: Oracle 관리형 파일 스토리지 - Lustre 및 고성능 마운트 타겟 지원.
• 블록 스토리지: 성능 SLA를 제공하는 균형, 고성능, 초고성능 볼륨
• 객체 스토리지: 구분된 저장 클래스 계층, 버킷 복제, 고용량 제한
초고속 네트워킹
• 맞춤형으로 설계된 RDMA over Converged Ethernet 프로토콜(RoCE v2)
• 클러스터 네트워킹을 위한 2.5~9.1마이크로초의 저지연시간
• 최대 3,200Gb/초의 클러스터 네트워크 대역폭
• 최대 400Gb/초의 프론트엔드 네트워크 대역폭
OCI Supercluster용 컴퓨트
NVIDIA GB200 NVL72, NVIDIA B200, NVIDIA H200, AMD MI300X, NVIDIA L40S, NVIDIA H100, NVIDIA A100 등의 GPU가 탑재된 OCI 베어메탈 인스턴스를 사용해 딥 러닝, 대화형 AI, 생성형 AI 등의 사용 사례를 위한 대규모 AI 모델을 실행할 수 있습니다.
OCI Supercluster 사용자는 클러스터당 최대 100,000개 이상의 GB200 Superchip, 131,072개 B200 GPU, 65,536개 H200 GPU, 32,768개 A100 GPU, 16,384개 H100 GPU, 16,384개 MI300X GPU, 3,840개 L40S GPU까지 확장할 수 있습니다.

크게 보기+
OCI Supercluster용 네트워킹
RDMA over Converged Ethernet version 2를 지원하는 NVIDIA ConnectX 네트워크 인터페이스 카드를 활용한 초고속 RDMA 클러스터 네트워킹을 통해 온프레미스와 동일한 경험을 제공하는 초저지연 네트워킹 및 애플리케이션 확장성을 갖춘 대규모 GPU 인스턴스 클러스터를 생성할 수 있습니다.
RDMA 기능, 블록 스토리지, 네트워크 대역폭에 대한 추가 비용은 발생하지 않으며, 처음 10TB의 이그레스 비용은 무료입니다.
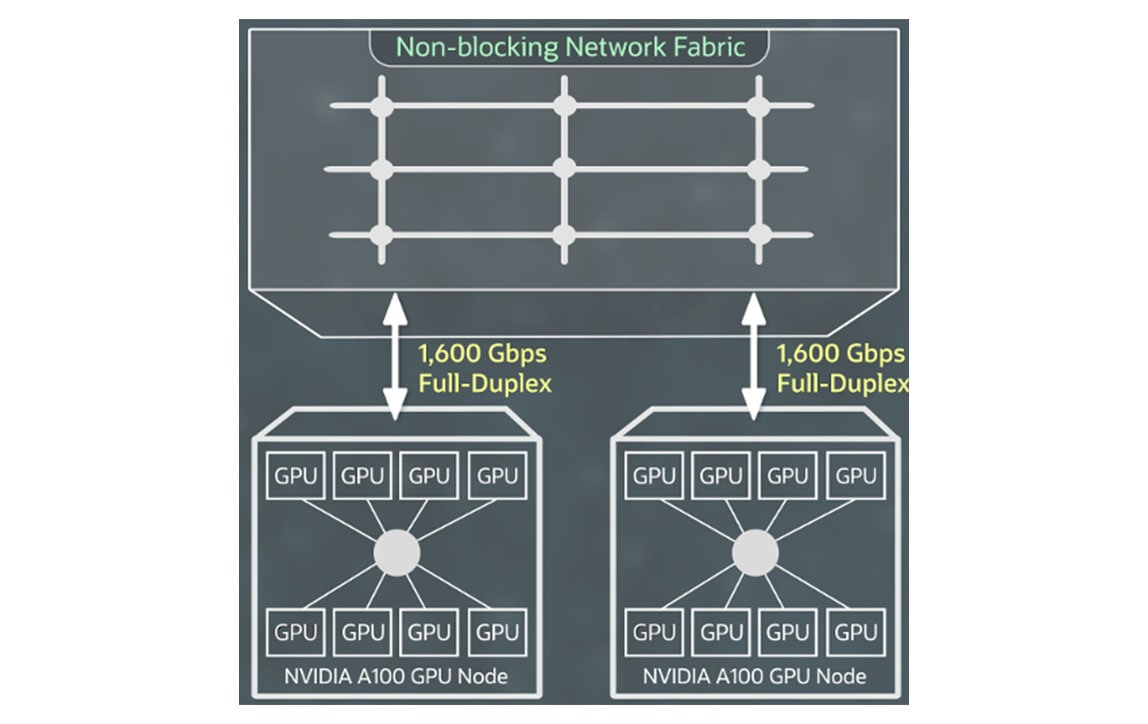
크게 보기+
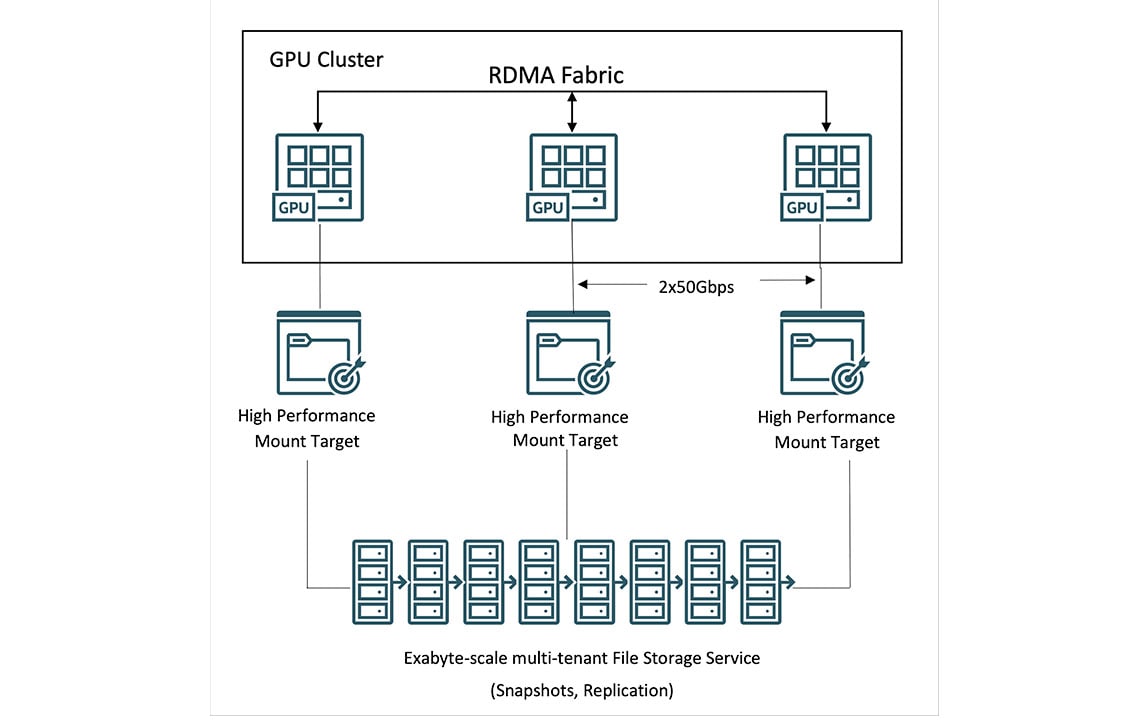
OCI Supercluster용 스토리지
OCI 고객은 OCI Supercluster를 통해 페타바이트급 컴퓨팅을 위한 로컬, 블록, 오브젝트, 파일 스토리지에 액세스할 수 있습니다. OCI는 주요 클라우드 제공업체 중에서도 독보적인 용량의 고성능 로컬 NVMe 스토리지를 제공함으로써 모델 학습 중 체크포인팅을 더 자주 수행하여 보다 신속한 장해 복구를 지원합니다.
대규모 데이터 세트의 경우 OCI는 Lustre 및 마운트 대상이 포함된 고성능 파일 스토리지를 제공합니다. BeeGFS, GlusterFS, WEKA 등의 HPC 파일 시스템을 사용해 성능 저하 없이 대규모 AI 훈련을 수행할 수 있습니다.

Zettascale OCI Superclusters
OCI의 최고 아키텍트들이 클러스터 네트워크로 확장 가능한 생성형 AI를 지원하는 방법을 설명합니다. 소수의 GPU부터 131,000개 이상의 NVIDIA Blackwell GPU가 탑재된 제타스케일 OCI 슈퍼클러스터에 이르기까지, 클러스터 네트워크는 귀사의 AI 여정을 지원하는 빠른 속도, 짧은 지연 시간, 탄력적인 네트워크를 제공합니다.
Seekr, 전 세계의 기업 및 정부 고객에게 믿을 수 있는 AI를 제공하기 위해 Oracle Cloud Infrastructure(OCI) 선택
Oracle PR, Abel Habtegeorgis믿을 수 있는 AI를 제공하기 위해 노력하는 인공지능 기업 Seekr는 기업용 AI 배포를 가속화하고 공동 시장 진출 전략을 실행하기 위해 Oracle Cloud Infrastructure(OCI)와 다년간의 계약을 체결했습니다.
게시물 전문 읽어보기추천 블로그
- 2025년 3월 26일 퍼블릭, 온프레미스, 서비스 제공업체 클라우드를 위한 NVIDIA Blackwell의 새로운 AI 인프라 기능 발표
- 2025년 3월 17일 AI 혁신을 선도하다: OCI 상의 NVIDIA AI Enterprise 및 NVIDIA NIM
- 2025년 3월 17일 어디서든 소버린 AI를 제공하는 Oracle과 NVIDIA의 파트너십
- 2025년 3월 11일 AI 영웅이 되는 가장 빠른 방법—OCI에 AI 워크로드를 신속히 배포하기
일반적 AI 인프라 사용 사례
GPU, RDMA 클러스터 네트워킹, OCI Data Science로 구동되는 OCI 베어메탈 인스턴스에서 AI 모델을 학습시킬 수 있습니다.
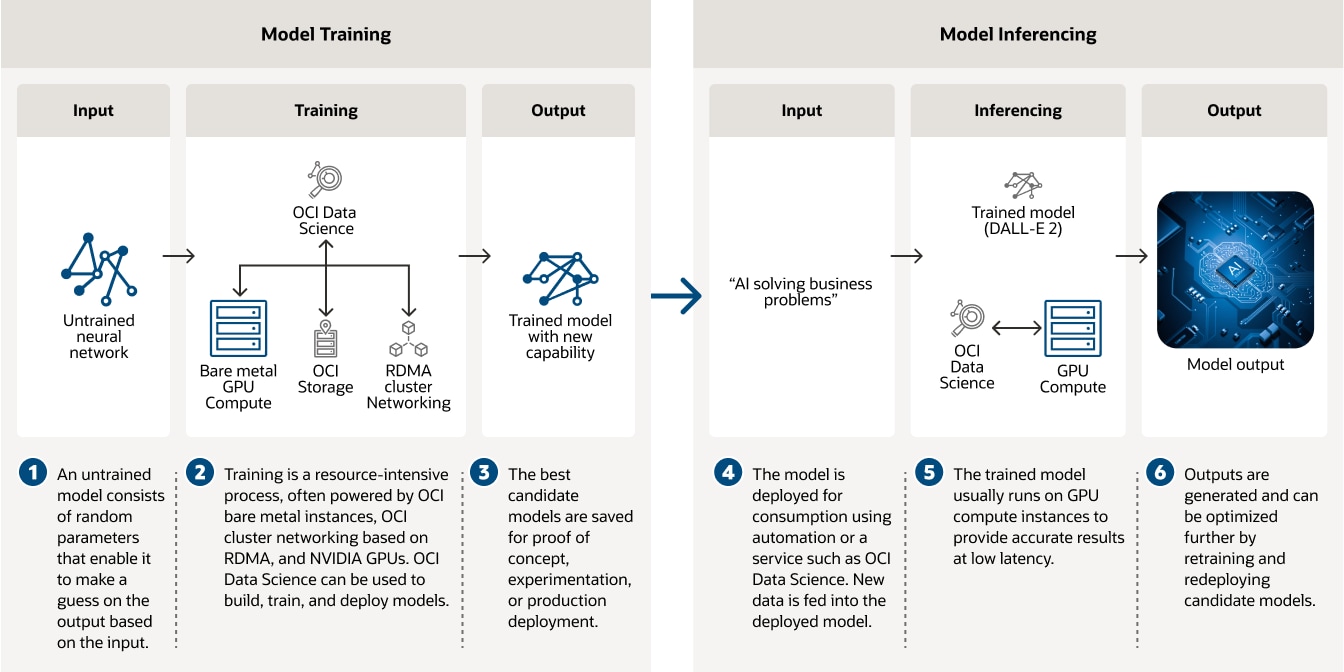
매일 수십억 건씩 이루어지는 금융 거래를 보호하기 위해서는 대량의 과거 고객 데이터를 분석할 수 있는 향상된 AI 도구가 필요합니다. NVIDIA GPU 기반의 OCI Compute에서 실행되는 AI 모델과 OCI Data Science 및 기타 오픈 소스 모델 등의 모델 관리 도구는 금융 기관의 사기 감지 및 방지에 도움을 줍니다.
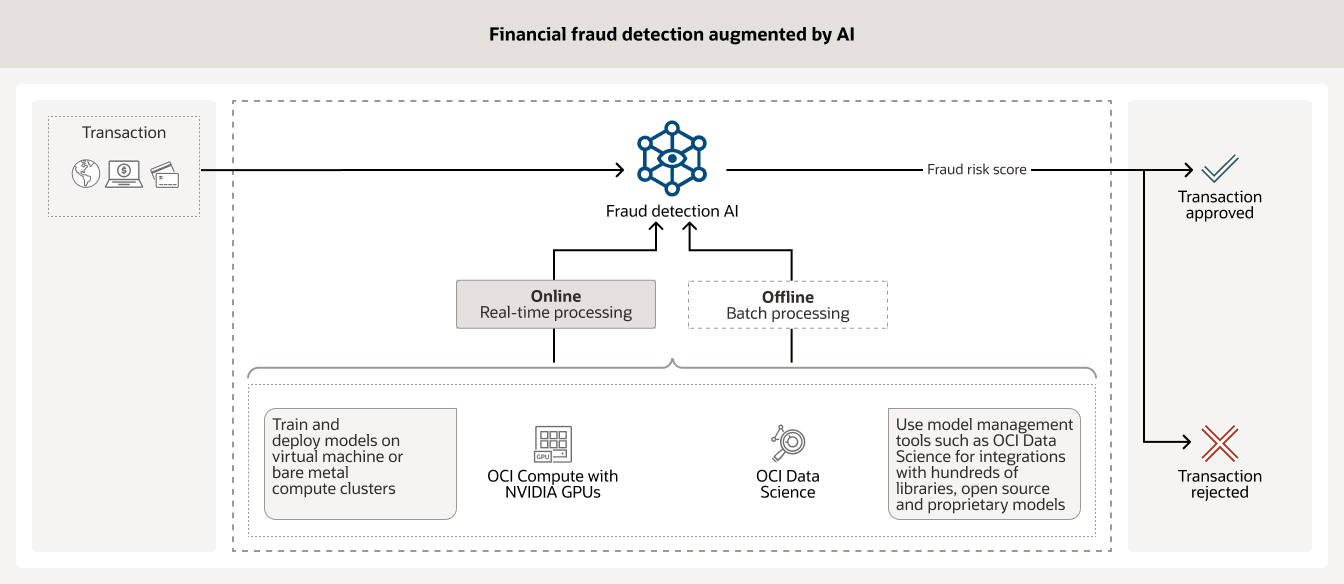
많은 병원이 다양한 유형의 의료 이미지를 분석하기 위해 AI를 사용하고 있습니다(예: 엑스레이 및 MRI). 학습된 AI 모델은 방사선 전문의가 즉각적으로 검토해야 하는 케이스를 우선순위로 설정하고, 그 외의 케이스에 대한 최종 결과 보고에 도움을 줄 수 있습니다.
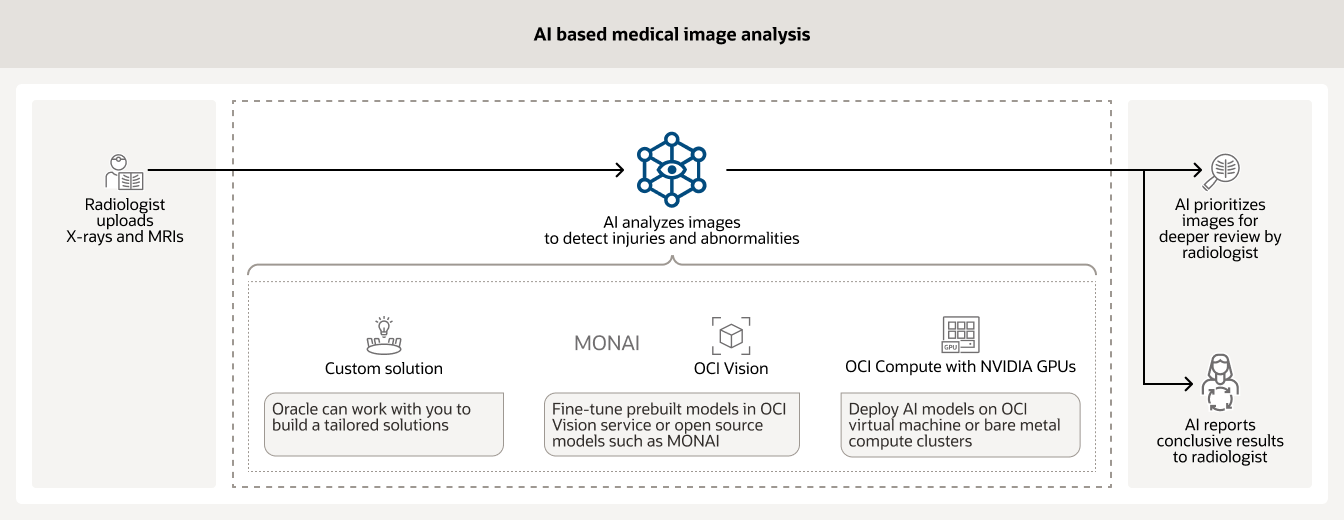
신약 개발은 여러 해의 시간과 수백만 달러가 소요될 수도 있는, 시간과 비용이 매우 많이 드는 프로세스입니다. 연구자들은 AI 인프라 및 데이터 분석을 활용하여 신약 개발을 가속화할 수 있습니다. 또한 OCI 고객은 NVIDIA GPU 기반의 OCI Compute와 BioNeMo 등의 AI 워크플로 관리 도구를 사용하여 데이터를 큐레이팅하고 전처리할 수 있습니다.
AI 인프라 고객 성공 사례















OCI AI 인프라 시작하기
AI 전문가와 상담하기
Oracle 전문가들이 AI 솔루션 구축, OCI AI 인프라에 워크로드 배포하기와 같은 다양한 AI 관련 주제에 대한 상담을 제공합니다.
-
다음과 같은 문의사항들에 답해드립니다.
- Oracle Cloud를 시작하려면 어떻게 해야 하나요?
- OCI에서는 어떤 종류의 AI 워크로드를 실행할 수 있나요?
- OCI는 어떤 유형의 AI 서비스를 제공하나요?
즉시 적용 가능한 AI 솔루션 살펴보기
귀사의 비즈니스를 돕기 위해 개발된 생성형 AI 솔루션이 제공하는 차원이 다른 생산성을 직접 경험해 보세요. Oracle의 지원을 바탕으로 Oracle의 전체 기술 스택에 내장된 AI 기능을 완전히 활용하는 방법을 살펴보세요.
-
Oracle AI 서비스를 활용하여 어떤 일들을 할 수 있나요?
- OCI에서 LLM 미세 조정
- 송장 처리 자동화
- RAG를 활용한 챗봇 구축
- 생성형 AI로 웹 콘텐츠 요약하기
- 그 외 다수!
추가 리소스
RDMA 클러스터 네트워킹, GPU 인스턴스, 베어메탈 서버 등과 관련된 정보를 더 자세히 살펴보세요.
OCI를 통해 얻을 수 있는 절감 효과 확인하기
Oracle Cloud는 저렴한 가격을 전 세계적으로 동일하게 적용하며, 간편하고 다양한 사용 사례를 지원합니다. 예상 요금 절감액을 확인하려면, 비용 계산기를 사용하여 필요에 맞게 서비스를 구성해보세요.
차이를 경험해보세요
- 1/4의 아웃바운드 대역폭 비용
- 가격 대비 컴퓨트 성능 3배
- 모든 리전에 동일하게 적용되는 저렴한 가격
- 장기 약정 없는 저렴한 가격 정책