Infrastructure pour l'IA
Exécutez les workloads d'IA les plus exigeants plus rapidement, y compris l'entraînement et l'inférence des modèles de frontières, l'IA agentique, le calcul scientifique et les systèmes de recommandations, où que vous soyez dans notre cloud distribué. Utilisez Oracle Cloud Infrastructure (OCI) Supercluster pour des performances allant jusqu'à 131 072 GPU à zettascale.

Rejoignez Oracle à NVIDIA GTC
Du 16 au 19 mars 2026
San José, Californie et virtuellement
-
![]() Explorez les tendances IA qui auront un impact sur les entreprises en 2026
Explorez les tendances IA qui auront un impact sur les entreprises en 2026
Participez à notre série de webinaires pour découvrir comment votre organisation peut rester prête.
-
![]() Premiers principes : Zettascale OCI Superclusters
Premiers principes : Zettascale OCI Superclusters
Les principaux architectes d'OCI révèlent comment les réseaux de cluster optimisent l'évolutivité pour l'IA générative, de quelques GPU à un supercluster OCI zettascale avec 131 072 GPU NVIDIA Blackwell.
![]() L'IA en action : 10 innovations à découvrir dès maintenant | Oracle
L'IA en action : 10 innovations à découvrir dès maintenant | Oracle
Découvrez 10 technologies révolutionnaires basées sur l'IA qui remodèlent la façon dont les entreprises effectuent la maintenance, interagissent avec leurs clients, sécurisent leurs données, fournissent des soins de santé, etc.
-
![]() Enterprise Strategy Group au sujet d'AMD Instinct MI300X
Enterprise Strategy Group au sujet d'AMD Instinct MI300X
Découvrez le point de vue de l'analyste sur l'infrastructure d'IA OCI avec les GPU AMD et comment cette combinaison peut améliorer la productivité, accélérer le délai de rentabilité et réduire les coûts énergétiques.




Co-innovation d'Oracle et de NVIDIA
Découvrez comment les deux entreprises accélèrent l'adoption de l'IA.
Pourquoi utiliser l'infrastructure d'IA d'OCI ?

Performance et valeur
Boostez l'entraînement de l'IA avec les instances bare metal GPU uniques d'OCI et le réseau de cluster RDMA ultra-rapide qui réduisent la latence à seulement 2,5 microsecondes. Obtenez des tarifs plus avantageux sur les VM GPU.

Stockage pour le calcul haute performance
Tirez parti d'OCI File Storage avec des cibles de montage à hautes performances (HPMT) et Lustre pour des téraoctets par seconde de débit. Utilisez jusqu'à 61,44 To de stockage NVMe, le stockage le plus élevé du secteur pour les instances de GPU.

Souveraineté de l'IA
Le cloud distribué d'Oracle vous permet de déployer une infrastructure d'IA n'importe où pour répondre aux exigences en matière de performances, de sécurité et de souveraineté de l'IA. Découvrez comment Oracle et NVIDIA fournissent une IA souveraine où que vous soyez.
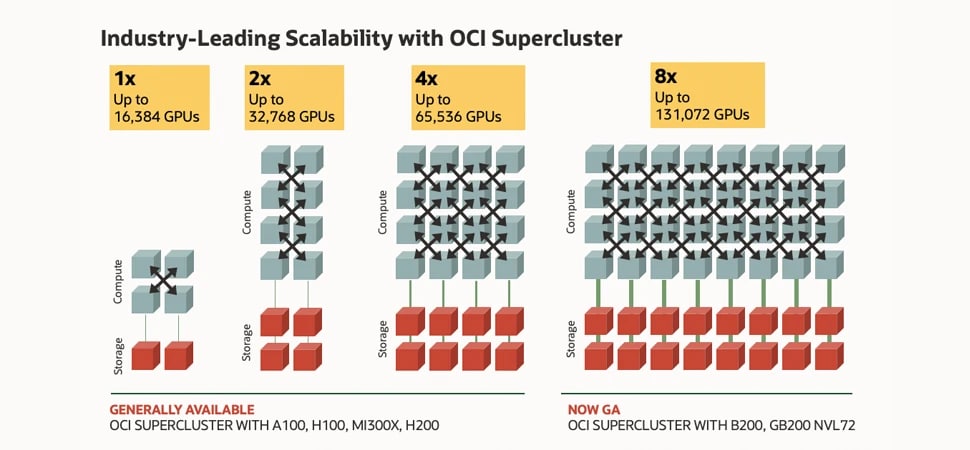 Capture d'écran représentant les zones de calcul et de stockage connectées par des lignes pour la mise en réseau en clusters. Tout à gauche, il y a quatre boîtes de calcul et deux pour le stockage du plus petit cluster avec 16 000 GPU NVIDIA H100. À droite, il y a 8 boîtes de calcul et 4 boîtes de stockage pour 32 000 GPU NVIDIA A100 dans un cluster. Ensuite, il y a 16 boîtes de calcul et 8 boîtes de stockage pour 64 000 GPU NVIDIA H200. Enfin, tout à droite, il y a 32 boîtes de calcul et 16 boîtes de stockage pour 128 000 GPU NVIDIA Blackwell et Grace Blackwell. L'évolutivité d'OCI Supercluster peut être multipliée par 8, de la plus petite configuration de 16 000 GPU tout à gauche jusqu'à la plus grande configuration de 128 000 GPU tout à droite.
Capture d'écran représentant les zones de calcul et de stockage connectées par des lignes pour la mise en réseau en clusters. Tout à gauche, il y a quatre boîtes de calcul et deux pour le stockage du plus petit cluster avec 16 000 GPU NVIDIA H100. À droite, il y a 8 boîtes de calcul et 4 boîtes de stockage pour 32 000 GPU NVIDIA A100 dans un cluster. Ensuite, il y a 16 boîtes de calcul et 8 boîtes de stockage pour 64 000 GPU NVIDIA H200. Enfin, tout à droite, il y a 32 boîtes de calcul et 16 boîtes de stockage pour 128 000 GPU NVIDIA Blackwell et Grace Blackwell. L'évolutivité d'OCI Supercluster peut être multipliée par 8, de la plus petite configuration de 16 000 GPU tout à gauche jusqu'à la plus grande configuration de 128 000 GPU tout à droite.
OCI Supercluster avec les GPU NVIDIA Blackwell et Hopper
Jusqu'à 131 072 GPU, 8 fois plus d'évolutivité
Les innovations de structure réseau permettent à OCI Supercluster d'atteindre jusqu'à 131 072 GPU NVIDIA B200, 100 000 GPU Blackwell dans les superpuces NVIDIA Grace Blackwell et 65 536 GPU NVIDIA H200.
Infrastructure OCI pour tous vos besoins d'IA
Que vous cherchiez à effectuer des déductions ou des ajustements, ou à entraîner des modèles à grande échelle pour l'IA générative, OCI offre des options de cluster de GPU bare metal et de machine virtuelle de pointe, optimisées par un réseau à très large bande passante et un stockage à hautes performances pour répondre à vos besoins en IA.
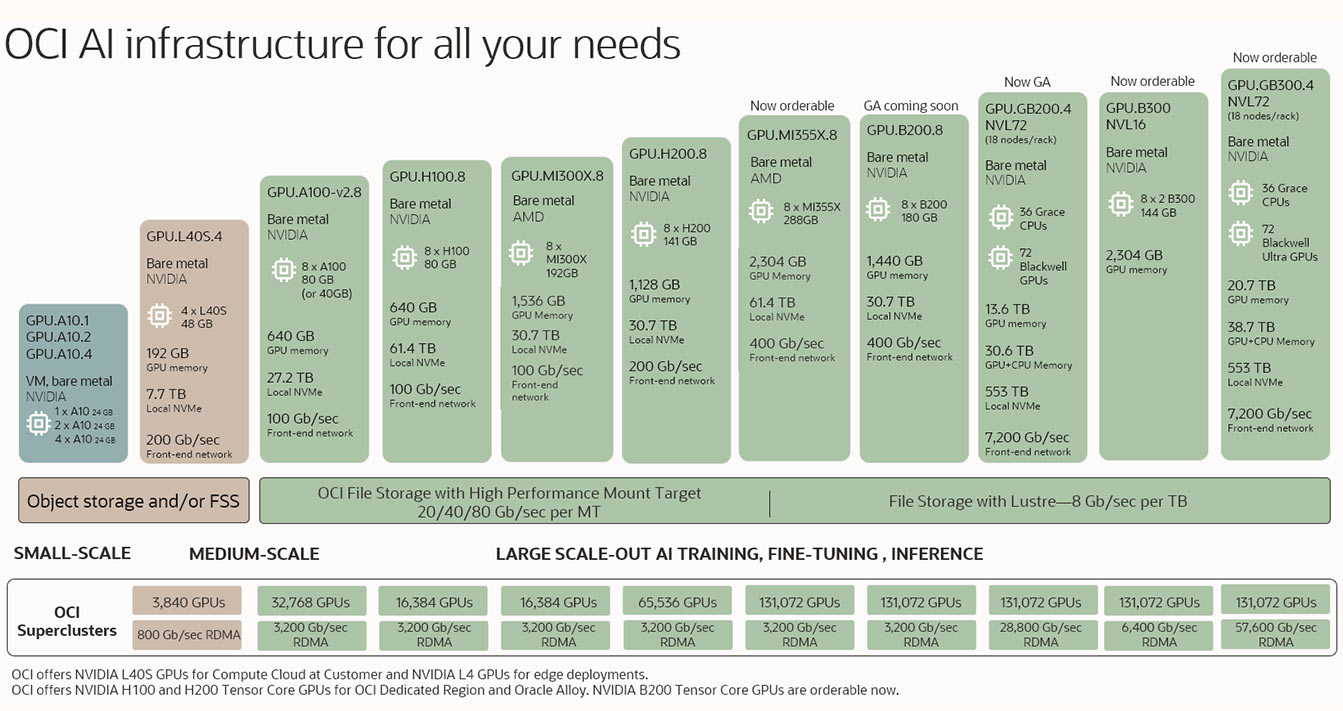 L'image montre plusieurs produits pour l'infrastructure d'IA, en commençant en bas à gauche avec les plus petites configurations, puis en augmentant progressivement jusqu'à des configurations à moyenne et grande échelle. Les configurations les plus petites comptent seulement 1 GPU dans une machine virtuelle et les configurations les plus grandes atteignent plus de 100 000 GPU dans les clusters RDMA.
L'image montre plusieurs produits pour l'infrastructure d'IA, en commençant en bas à gauche avec les plus petites configurations, puis en augmentant progressivement jusqu'à des configurations à moyenne et grande échelle. Les configurations les plus petites comptent seulement 1 GPU dans une machine virtuelle et les configurations les plus grandes atteignent plus de 100 000 GPU dans les clusters RDMA. Découvrez comment optimiser l'IA en production grâce à OCI et NVIDIA RTX PRO.
Découvrez OCI Supercluster pour un entraînement d'IA à grande échelle
Clusters évolutifs massifs avec NVIDIA Blackwell et Hopper
Calcul superchargé
• Instances bare metal sans surcharge d'hyperviseur
• Accéléré par NVIDIA Blackwell (GB200 NVL72, HGX B200),
Hopper (H200, H100) et les GPU de génération précédente
• Option d'utilisation de GPU AMD MI300X
• Unité de traitement de données (DPU) pour l'accélération matérielle intégrée
Capacité massive et stockage haut débit
• Stockage local : jusqu'à 61,44 To de capacité SSD NVMe
• Stockage de fichiers : Stockage de fichiers géré par Oracle avec Lustre et cibles de montage hautes performances.
• Stockage de blocs : volumes équilibrés, plus performants et ultraperformants avec un contrat de niveau de service de performance
• Stockage d'objets : niveaux de classe de stockage distincts, réplication de bucket et limites de capacité élevées
Réseau ultra-rapide
• Protocole RDMA sur Ethernet convergé personnalisé (RoCE v2)
• 2,5 à 9,1 microsecondes de latence pour le réseau de cluster
• Jusqu'à 3 200 Gb/s de bande passante réseau de cluster
• Jusqu'à 400 Gb/s de bande passante réseau frontale
Calcul pour OCI Supercluster
Les instances bare metal OCI optimisées par les GPU NVIDIA GB200 NVL72, NVIDIA B200, NVIDIA H200, AMD MI300X, NVIDIA L40S, NVIDIA H100 et NVIDIA A100 vous permettent d'exécuter de grands modèles d'IA pour les cas d'utilisation qui incluent le deep learning, l'IA conversationnelle et l'IA générative.
Avec OCI Supercluster, vous pouvez évoluer pour atteindre jusqu'à plus de 100 000 GB200 Superchips, 131 072 B200 GPU, 65 536 H200 GPU, 32 768 A100 GPU, 16 384 H100 GPU, 16 384 MI300X GPU et 3 840 L40S GPU par cluster.

Agrandir+
Mise en réseau pour OCI Supercluster
La mise en réseau de clusters RDMA à haut débit alimentée par les cartes d'interface réseau NVIDIA ConnectX avec RDMA sur la version 2 de l'ethernet convergé vous permet de créer de grands clusters d'instances GPU avec la même mise en réseau à très faible latence et la même évolutivité des applications attendue on-premises.
Vous ne payez pas de frais supplémentaires pour la capacité RDMA, le stockage de blocs ou la bande passante réseau, et les 10 premiers To de sortie sont gratuits.
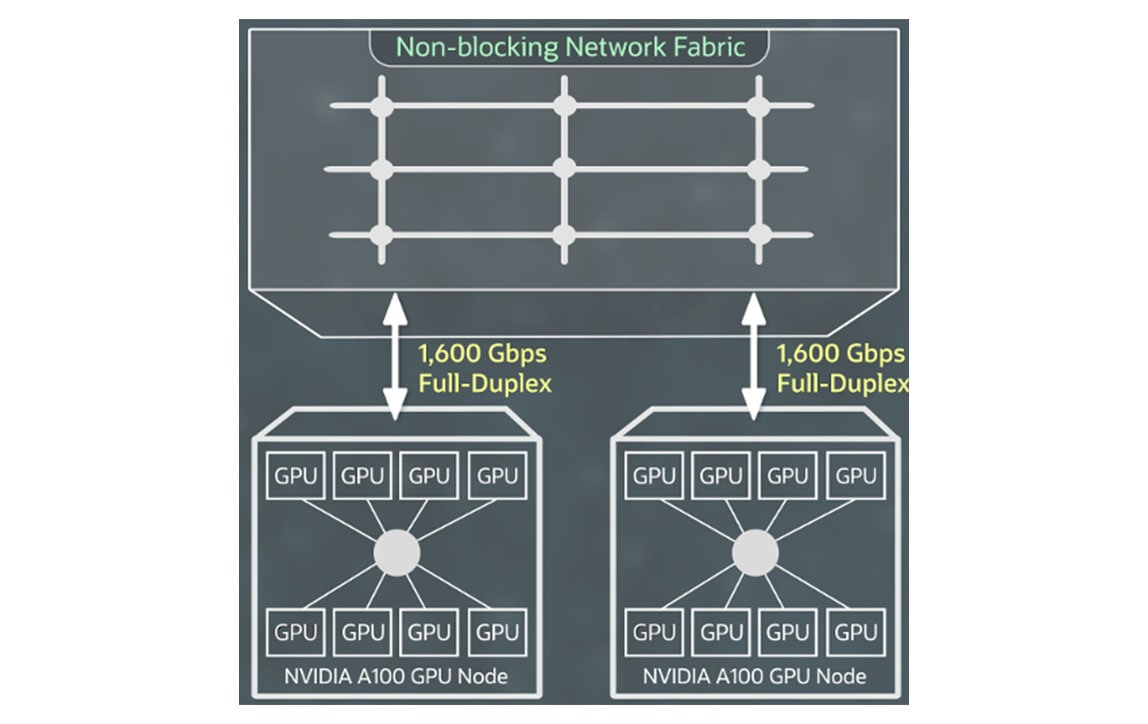
Agrandir+
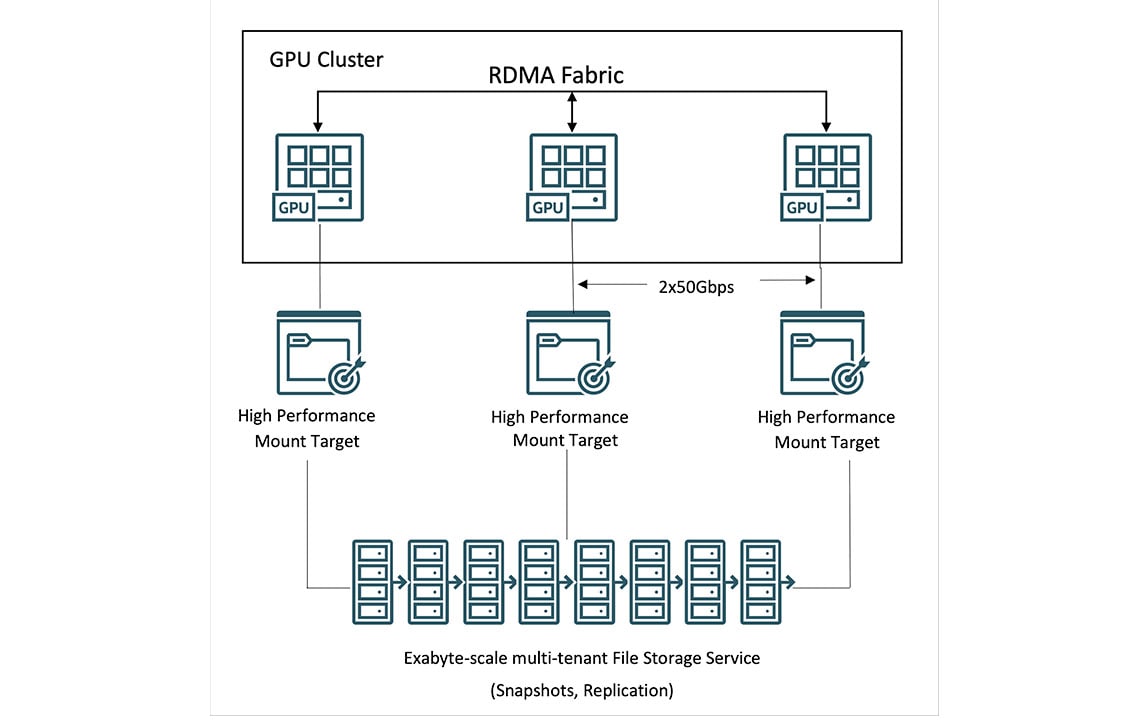
Stockage pour OCI Supercluster
Grâce à OCI Supercluster, les clients peuvent accéder au stockage local, de blocs, d'objets et de fichiers pour le calcul petaflopique. Parmi les principaux fournisseurs de cloud, OCI offre la capacité la plus élevée de stockage NVMe local à hautes performances pour des points de reprise plus fréquents pendant les entraînements, ce qui permet une récupération plus rapide en cas de défaillance.
Pour les jeux de données volumineux, OCI offre un stockage de fichiers hautes performances avec Lustre et des cibles de montage. Les systèmes de fichiers HPC, y compris BeeGFS, GlusterFS et WEKA, peuvent être utilisés pour l'entraînement d'IA à grande échelle sans compromettre les performances.

Superclusters OCI Zettascale
Regardez les meilleurs architectes d'OCI révéler comment les réseaux de cluster alimentent l'IA générative évolutive. De quelques GPU aux superclusters OCI zettascale avec plus de 131 000 GPU NVIDIA Blackwell, les réseaux de cluster offrent une vitesse élevée, une faible latence et un réseau résilient pour votre parcours d'IA.
Seekr choisit Oracle Cloud Infrastructure pour fournir une IA fiable aux entreprises et aux administrations à l'échelle mondiale
Abel Habtegeorgis, Oracle PRSeekr, une entreprise d'intelligence artificielle axée sur la fourniture d'une IA fiable, a conclu un accord pluriannuel avec Oracle Cloud Infrastructure (OCI) pour accélérer rapidement les déploiements d'IA d'entreprise et exécuter une stratégie commune de commercialisation.
Lire la suite de l'articleBlogs à la une
- 26 MARS 2025 Annonce de nouvelles fonctionnalités d'infrastructure d'IA avec NVIDIA Blackwell pour les clouds publics, on-premise et fournisseurs de service
- 17 mars 2025 Faire progresser l'innovation en matière d'IA : NVIDIA AI Enterprise et NVIDIA NIM sur OCI
- 17 mars 2025 Oracle et NVIDIA fournissent une IA souveraine partout
- 11 mars 2025 Devenez un héro de l'IA : déployez rapidement vos workloads d'IA sur OCI
Cas d'usage typique de l'infrastructure d'IA
- Entraînement et inférence de deep learning
- Détection des fraudes augmentée par l'IA
- Analyse d'images médicales basée sur l'IA
- Utilisation de l'IA pour accélérer la découverte de médicaments
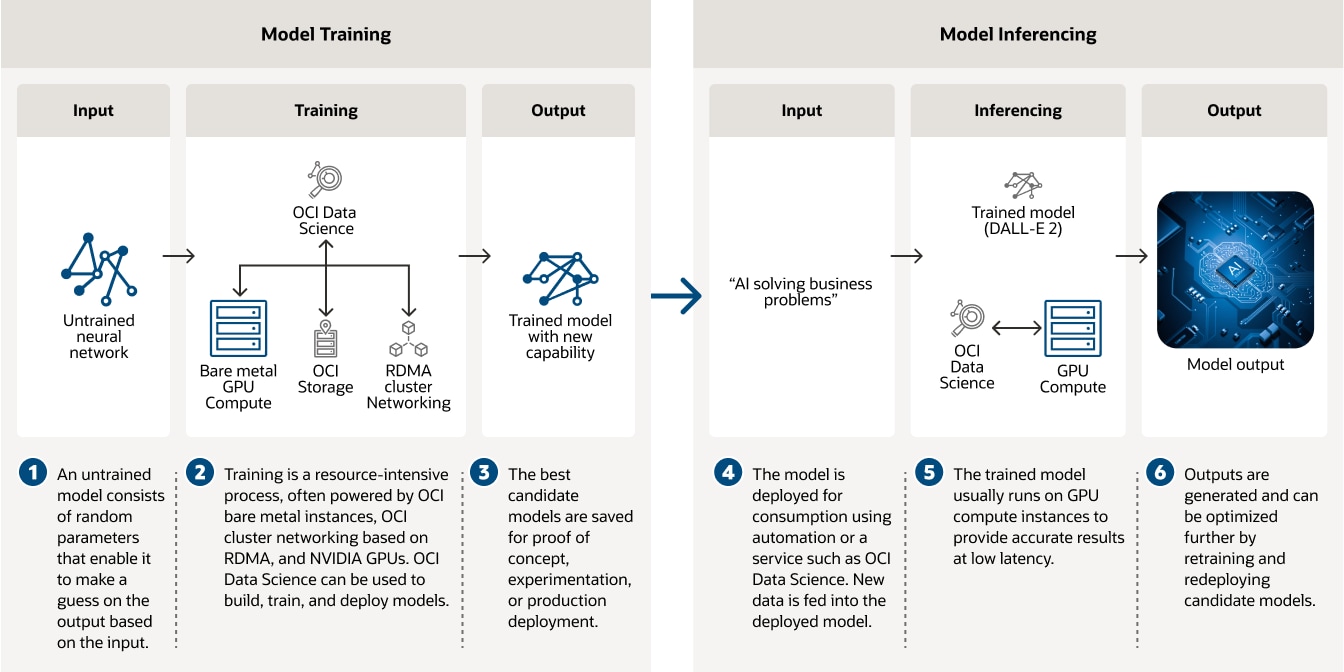
Entraînez des modèles d'IA sur des instances bare metal OCI optimisées par des GPU, des réseaux de clusters RDMA et OCI Data Science.
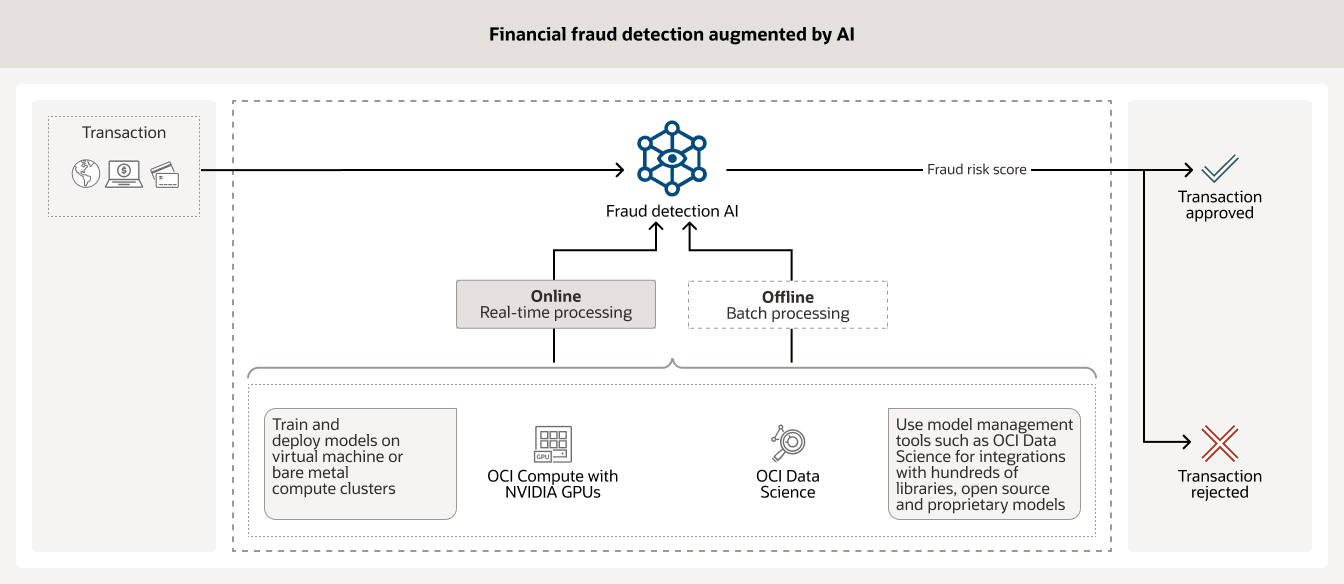
La protection des milliards de transactions financières qui se produisent chaque jour nécessite des outils d'IA améliorés capables d'analyser de grandes quantités de données client historiques. Les modèles d'IA exécutés sur OCI Compute alimentés par des GPU NVIDIA, ainsi que des outils de gestion de modèles tels qu'OCI Data Science et d'autres modèles open source aident les institutions financières à réduire la fraude.
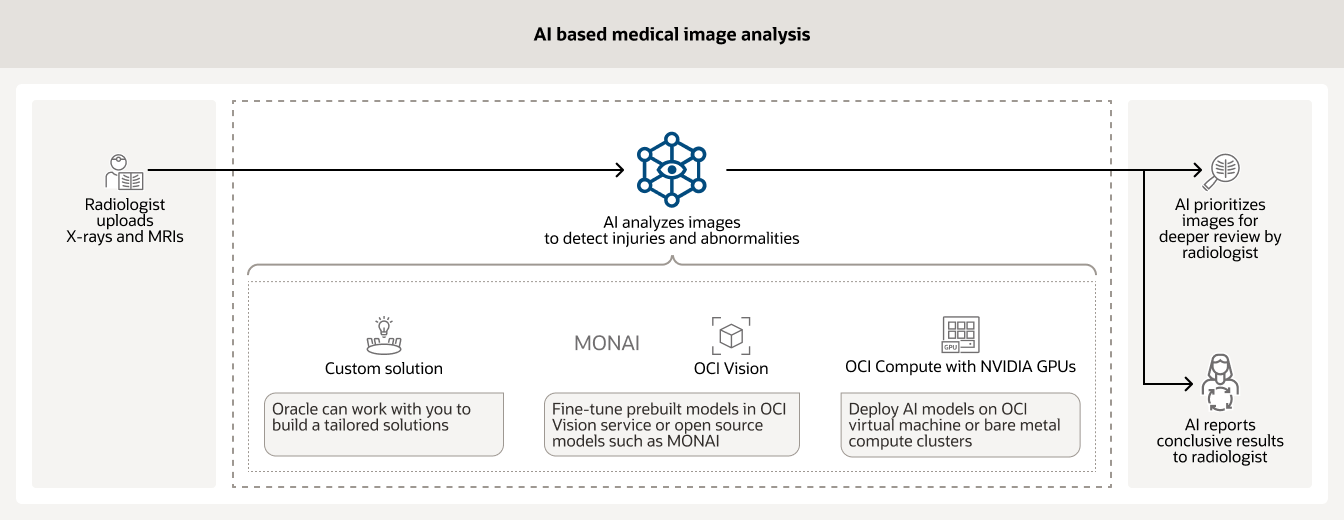
L'IA est souvent utilisée pour analyser divers types d'images médicales (comme les rayons X et les IRM) dans un hôpital. Les modèles entraînés peuvent aider à hiérarchiser les cas nécessitant une révision immédiate par un radiologue et à rapporter des résultats concluants sur d'autres.
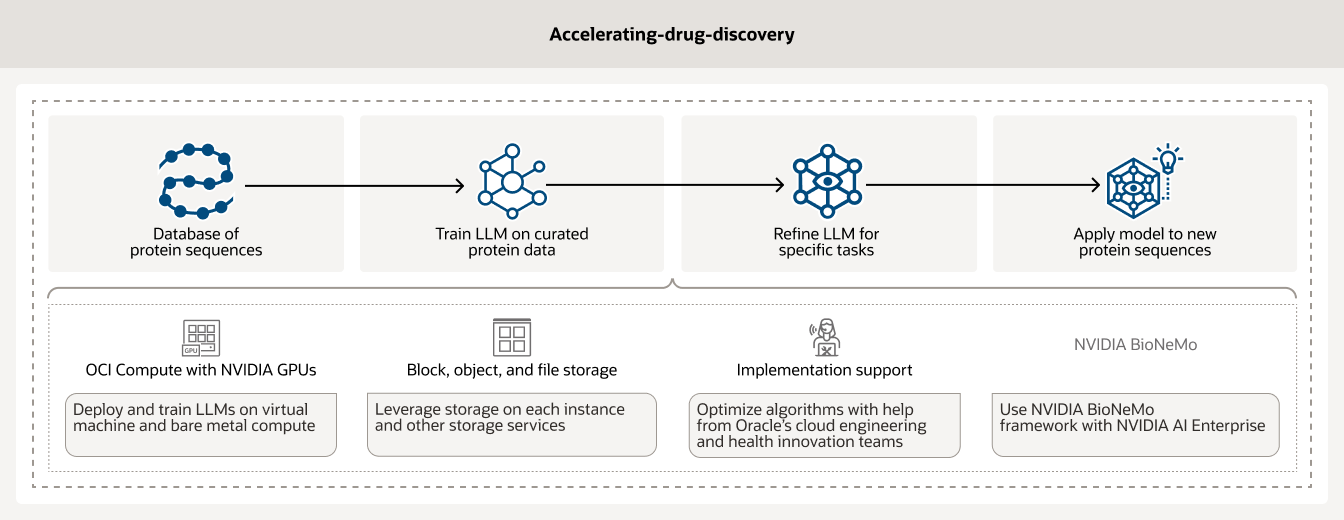
La découverte de médicaments est un processus long et coûteux qui peut prendre de nombreuses années et coûter des millions de dollars. En tirant parti de l'infrastructure et de l'analyse de l'IA, les chercheurs peuvent accélérer la découverte de médicaments. En outre, OCI Compute s'appuie sur des GPU NVIDIA ainsi que sur des outils de gestion des workflows d'IA tels que BioNeMo pour permettre aux clients de traiter et de prétraiter leurs données.
Témoignages client sur l'infrastructure de l'IA















Introduction à l'infrastructure d'IA d'OCI
Mise en contact avec des experts de l'IA
Obtenez de l'aide pour créer votre prochaine solution d'IA ou déployer votre workload sur l'infrastructure d'IA d'OCI.
-
Il peut répondre à des questions telles que :
- Comment se lancer avec Oracle Cloud ?
- Quels types de workloads d'IA puis-je exécuter sur OCI ?
- Quels types de services d'IA OCI propose-t-il ?
Découvrez comment exploiter l'IA aujourd'hui
Entrez dans une nouvelle ère de productivité avec des solutions d'IA générative pour votre entreprise. Découvrez comment Oracle aide les clients à tirer parti de l'IA intégrée dans l'ensemble de la pile technologique.
-
Que pouvez-vous réaliser avec Oracle AI ?
- Affiner des LLM dans OCI
- Automatiser le traitement des factures
- Créer un chatbot avec de la RAG
- Résumer du contenu web avec l'IA générative
- et bien plus encore !
Ressources complémentaires
En savoir plus sur la mise en réseau de clusters RDMA, les instances GPU, les serveurs bare metal, etc.
Découvrez combien vous pouvez réaliser des économies avec OCI
La tarification d'Oracle Cloud est simple, avec des tarifs faibles homogènes dans le monde entier et prenant en charge un large éventail de cas spécifiques. Pour estimer votre tarif réduit, consultez l’estimateur de coûts et configurez les services en fonction de vos besoins.
Ressentez la différence
- 1/4 des coûts de bande passante sortante
- Rapport prix/performances de calcul 3 fois plus élevé
- Tarifs faibles et identiques dans chaque région
- Tarifs bas sans engagements à long terme