Data Science Service
Oracle Cloud Infrastructure (OCI) Data Science est une plateforme entièrement gérée destinée aux équipes de data scientists pour créer, former, déployer et gérer des modèles de machine learning (ML) à l'aide de Python et d'outils open source. Utiliser un environnement basé sur JupyterLab pour expérimenter et développer des modèles. Adapter la formation aux modèles avec des GPU NVIDIA et une formation distribuée. Mettez les modèles en production et maintenez-les en bonne santé grâce aux fonctionnalités des opérations de machine learning (MLOps), telles que les pipelines automatisés, les déploiements de modèles et la surveillance des modèles.

- OCI Data Science prend en charge les modèles à pondération ouverte d'OpenAI
OpenAI a annoncé la sortie de deux modèles à pondération ouverte, gpt-oss-120b et gpt-oss-20b, qui peuvent être déployés et affinés dans OCI Data Science.
- Simplifiez votre travail avec des modèles de base
Déployez, affinez et évaluez des modèles de base avec OCI Data Science AI Quick Actions.
- Maintenant disponible : Cohere Embed 4 sur OCI Generative AI
Améliorez la génération augmentée de recherche et de récupération d'entreprise avec le dernier modèle d'intégration haute performance de Cohere, désormais accessible via OCI.
- Essayez OCI Data Science gratuitement
Un essai gratuit d'Oracle Cloud vous permet d'accéder à OCI Data Science avec 300 USD de crédit cloud gratuit.
Comment fonctionne OCI Data Science ?
OCI Data Science est un service géré complet conçu pour rationaliser le développement, le déploiement et l'opérationnalisation des modèles d'IA et de machine learning. Les fonctionnalités clés incluent des blocs-notes Jupyter pour l'expérimentation, des outils MLOps évolutifs pour le déploiement et la surveillance de modèles, ainsi que la prise en charge intégrée des grands modèles de langage (LLM) via Hugging Face et d'autres frameworks.
Grâce à des outils robustes pour la collaboration, la détection des anomalies et les prévisions, OCI Data Science permet aux équipes de fournir des informations exploitables de manière efficace et sécurisée.
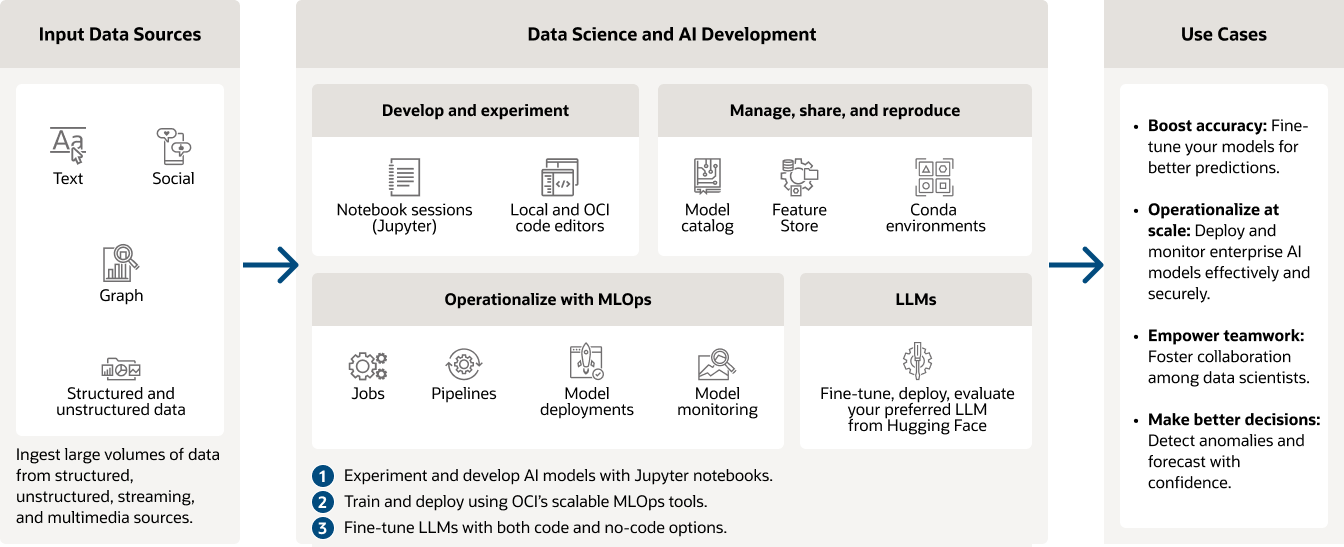
Cas d'usage d'OCI Data Science
Soins de santé : Risque de réadmission des patients
Identifier les facteurs de risque et prédire le risque de réadmission des patients après leur sortie en créant un modèle prédictif. Utiliser les données, telles que les antécédents médicaux du patient, son état de santé, les facteurs environnementaux et les tendances médicales historiques, pour construire un modèle plus solide qui aide à fournir les meilleurs soins à un coût moindre.
Vente au détail : Prédire la valeur de la vie du client
Utiliser des techniques de régression sur les données pour prédire les dépenses futures des clients. Examinez les transactions passées et combinez les données historiques des clients avec des données sur les tendances, les niveaux de revenus, voire des facteurs tels que la météo, pour construire des modèles de ML qui déterminent s'il faut créer des campagnes marketing pour conserver les clients actuels ou en acquérir de nouveaux.
Manufacturing : maintenance prédictive
Créez des modèles de détection d'anomalies à partir de données de capteurs pour détecter les pannes d'équipement avant qu'elles ne deviennent un problème plus grave ou utilisez des modèles de prévision pour prévoir la fin de vie des pièces et des machines. Augmenter le temps de fonctionnement des véhicules et des machines grâce au machine learning et à la surveillance des paramètres d'exploitation.
Finance : détection de fraude
Prévenir la fraude et les délits financiers grâce à la science des données. Construire un modèle de machine learning capable d'identifier les événements anormaux en temps réel, notamment les montants frauduleux ou les types de transactions inhabituels.
Pourquoi OCI Data Science ?
-
Data science à haute performance
Accéder à des workflows automatisés pour la construction de modèles. Faciliter l'exploitation du ML grâce à des tâches réutilisables et à une orchestration de bout en bout du cycle de vie du ML. Exécutez des workloads distribués et à haute performance en accédant à des GPU à moindre coût.
-
Plate-forme ouverte
Découvrez le meilleur de l'apprentissage automatique sur Oracle grâce à des partenariats majeurs. Apporter des modèles, des données et du code dans le format dont vous avez besoin.
-
Excellent support
Bénéficiez d'un traitement de premier plan pour les partenariats de ML stratégiques. Les data scientists d'Oracle se consacrent à la réussite de votre entreprise.
Succès clients et partenariats pour OCI Data Science




Architectures de référence pour l'IA/le machine learning
-
Guide stratégique de solutions
Découvrez comment les données sont stockées, utilisées et analysées par un système de santé pour suivre le parcours d'un patient, du diagnostic au traitement en passant par la guérison.
-
Architecture de référence
Développement d'applications innovantes - Apprentissage automatique et IA
Utilisez ce modèle pour créer des plateformes de machine learning conçues pour les data scientists.
-
Créé et déployé
Déployez rapidement une architecture pour gérer en toute sécurité de grandes quantités de données source afin de créer des modèles prédictifs et de les exploiter dans des applications développées rapidement.
-
Architecture de référence
Enrichissez les données des applications d'entreprise avec des données brutes provenant d'autres sources et utilisez des modèles de machine learning pour apporter des analyses et des analyses prédictives dans les processus métier.
OCI Data Science - Ressources
-
Cloud learning
- OCI Data Science - Vidéos
- Atelier : Oracle Cloud Infrastructure Data Science Professional (Laboratoire Oracle University - 9h 14m) - Oracle MyLearn
- Atelier pratique gratuit
- Exemples de carnets de notes et tutoriels sur Github
- Cours : Oracle Cloud Infrastructure Data Science Professional - Oracle MyLearn