Zwiększenie wydajności operacyjnej i efektywności produkcji

Zaawansowane analizy poprawiają wydajność, jakość i proces zrównoważonego rozwoju
W przypadku branży produkcyjnej wykorzystanie danych do poprawy wydajności operacyjnej i efektywności działania jest szczególnie istotne, ponieważ ten przykładowy sposób zastosowania może być użyty do każdego rodzaju systemów produkcji, w tym infrastruktury skomputeryzowanej kontroli cyfrowej, systemów łańcucha zaopatrzenia i magazynów, systemów logistycznych i testowych itd.
Producenci tradycyjnie koncentrują się na historycznych miarach opisowych i diagnostycznych, ale zaczynają używać zaawansowanych analiz, uczenia maszynowego i danologii do mierzenia poprawy wydajności oraz opracowywania proaktywnych, predykcyjnych i preskryptywnych zaleceń.
Ten przykładowy sposób zastosowania koncentruje się na architekturze platformy danych, wymaganej do wchłaniania i przechowywania danych, a także uzyskiwania wglądu na podstawie danych generowanych przez systemy realizacji produkcji (MES), systemy zarządzania magazynem (WHMS), skomputeryzowane systemy zarządzania konserwacją (CMMS) oraz systemy konserwacji w celu zmierzenia wydajności operacyjnej urządzeń, linii i zakładów oraz obliczenia miar wydajności.
Dzięki wchłanianiu, selekcjonowaniu i analizowaniu danych dotyczących procesów produkcyjnych i wyników działania producenci mogą rozpoznawać i eliminować wąskie gardła i przypadki braku efektywności, aby zoptymalizować harmonogramy produkcji i zwiększyć wydajność. Stosując to samo podejście do danych dotyczących jakości produktu, producenci mogą określić wzorce i główne przyczyny usterek, aby wdrożyć skuteczniejsze środki kontroli jakości. Ponadto, poprzez uwzględnienie danych dotyczących zużycia energii producenci mogą zidentyfikować obszary, w których mogą zwiększyć efektywność energetyczną w celu obniżenia kosztów i udoskonalenia procesu zrównoważonego rozwoju.
Optymalizowanie konserwacji przewidującej i obniżenie kosztów dzięki kompleksowej platformie danych
Przedstawiona tu architektura pokazuje, jak możemy łączyć zalecane składniki Oracle w celu stworzenia architektury analitycznej obejmującej cały cykl życia analizy danych od odkrycia po działanie i pomiar. Umożliwia to osiągnięcie szerokiego wachlarza korzyści biznesowych, o których mowa powyżej.
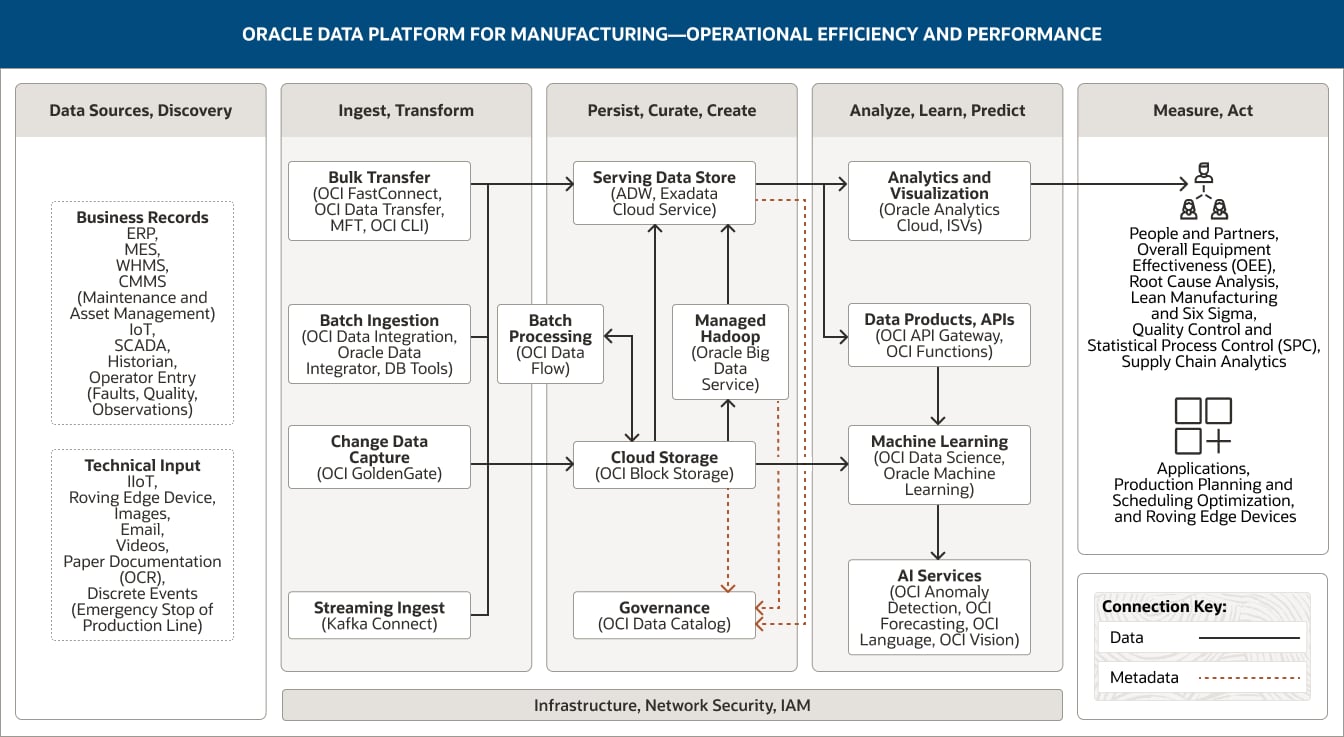
Na rysunku przedstawiono, jak za pomocą platformy Oracle skupiającej dane dla sektora produkcyjnego można wspierać wydajność operacyjną i wyniki. Platforma obejmuje następujące pięć filarów:
- 1. Źródła danych, odkrywanie
- 2. Wchłanianie, przekształcanie
- 3. Utrwalanie, selekcjonowanie, tworzenie
- 4. Analizowanie, uczenie się, przewidywanie
- 5. Pomiar, działanie
Filar „Źródła danych, odkrywanie” zawiera trzy kategorie danych.
- 1. Dane z aplikacji Oracle obejmują dane z aplikacji Fusion SaaS, Oracle E-Business Suite, CX
- 2. Rekordy biznesowe (dane z 1. ręki) z CRM, transakcje, dane klienta, przychody i marża
- 3. Dane zewnętrzne obejmują kursy walut, opłaty rynkowe i ceny towarów
Filar „Wchłanianie, przekształcanie” składa się z czterech funkcjonalności.
- 1. We wchłanianiu wsadowym wykorzystywane są usługi OCI Data Integration, Oracle Data Integrator i narzędzia baz danych.
- 2. W transferze masowym wykorzystuje się OCI FastConnect, OCI Data Transfer, MFT oraz OCI CLI.
- 3. W rejestrowaniu zmian danych wykorzystuje się OCI GoldenGate.
- 4. Wchłanianie przesyłania strumieniowego korzysta z usług OCI Streaming Kafka Connect.
Wszystkie cztery funkcjonalności w jednokierunkowy sposób łączą się z obsługującym magazynem danych i magazynem w chmurze w ramach filaru „Utrwalanie, selekcjonowanie, tworzenie”.
Dodatkowo wchłanianie przesyłania strumieniowego jest połączone z przetwarzaniem strumieniowym w obrębie filaru „Analizowanie, uczenie się i przewidywanie”.
Filar „Utrwalanie, selekcjonowanie, tworzenie” składa się z pięciu funkcjonalności.
- 1. Obsługujący magazyn danych korzysta z usług Oracle Autonomous Data Warehouse i Exadata Cloud Service.
- 2. Magazyn w chmurze korzysta z usługi OCI Object Storage.
- 3. Zarządzane klastry Hadoop korzystają z usługi Oracle Big Data Service
- 4. Przetwarzanie wsadowe korzysta z OCI Data Flow.
- 5. Usługa Governance korzysta z katalogu OCI Data Catalog.
Funkcjonalności te są połączone w ramach filaru. Magazyn w chmurze jest jednokierunkowo połączony z obsługującym magazynem danych, a także dwukierunkowo z przetwarzaniem wsadowym.
Dwie funkcjonalności łączą się z filarem „Analizowanie, uczenie się i przewidywanie”. Obsługujący magazyn danych łączy się zarówno z funkcjonalnościami analiz i wizualizacji, jak i z produktów danych (API). Magazyn w chmurze łączy się z funkcjonalnością uczenia maszynowego.
Filar „Analizowanie, uczenie się i przewidywanie” składa się z dwóch funkcjonalności.
- 1. Analizy i wizualizacje wykorzystują rozwiązania Oracle Analytics Cloud, GraphStudio i niezależnych dostawców oprogramowania (ISV).
- 2. Uczenie maszynowe korzysta z Oracle Machine Learning.
W filarze „Pomiar, działanie” przedstawiono sposób wykorzystania analizy danych w podziale na pracowników i partnerów.
Obszar pracowników i partnerów składa się z wydajności operacyjnej (czas przetwarzania, wskaźniki błędów, wykorzystanie zasobów), identyfikacji wąskich gardeł w procesach, wartości cyklu życia klienta, analizy rynkowej i konkurencji, przypisywania wyników.
Trzy główne filary — „Wchłanianie, przekształcanie”, „Utrwalanie, selekcjonowanie, tworzenie” oraz „Analizowanie, uczenie się i przewidywanie” — są obsługiwane przez infrastrukturę, sieć, zabezpieczenia i IAM.
Łączenie, wchłanianie i przekształcanie danych
Nasze rozwiązanie składa się z trzech filarów, z których każdy obsługuje określone funkcjonalności platformy danych. Pierwszy filar zapewnia możliwość łączenia, pozyskiwania i przekształcania danych.
Istnieją cztery główne sposoby wprowadzania danych do architektury umożliwiające organizacjom produkcyjnym zwiększenie wydajności operacyjnej i wyników.
- Aby rozpocząć nasz proces, włączymy transfer masowy danych transakcji operacyjnych. Usługi transferu masowego są używane w sytuacjach, w których trzeba po raz pierwszy przenieść duże wolumeny danych do Oracle Cloud Infrastructure (OCI), na przykład dane z istniejących lokalnych repozytoriów analitycznych lub innych źródeł w chmurze. Konkretna usługa masowego transferu, której użyjemy, będzie zależeć od lokalizacji danych i częstości przeprowadzania transferów. Na przykład możemy użyć usługi OCI Data Transfer Service lub OCI Data Transfer Appliance do ładowania dużych ilości danych lokalnych z repozytoriów planowania historycznego lub repozytoriów hurtowni danych. W razie konieczności przenoszenia na bieżąco dużych ilości danych zalecamy skorzystanie z OCI FastConnect, która zapewnia szerokopasmowe, specjalne prywatne połączenie sieciowe między centrum danych klienta a OCI.
- Często wymagane są wyodrębnienia w czasie rzeczywistym lub prawie rzeczywistym, a dane są regularnie wchłaniane z systemów zarządzania magazynem, planowania i zarządzania zamówieniami za pomocą OCI GoldenGate. OCI GoldenGate wykorzystuje funkcje przechwytywania zmian danych do wykrywania zdarzeń zmiany w podstawowej strukturze systemów do obsłużenia (na przykład dodanie nowego składnika, ukończone operacje konserwacji, zmiany pogody itp.) i wysyłania danych w czasie rzeczywistym do warstwy utrwalania i (lub) przesyłania strumieniowego.
- Analizowanie danych z wielu źródeł w czasie rzeczywistym może pomóc firmom produkcyjnym w uzyskaniu cennego wglądu w ich wydajność operacyjną i ogólną efektywność działania. W tym przykładowym sposobie zastosowania używamy wchłaniania przesyłania strumieniowego do pobierania wszystkich danych odczytanych z czujników za pośrednictwem Internetu rzeczy, komunikacji między maszynami i innych środków. Funkcjonalność rejestrowania i analizowania strumieni danych w czasie rzeczywistym ma kluczowe znaczenie dla zdolności producenta do przeprowadzania konserwacji zasobów predykcyjnych. Strumienie mogą pochodzić z kilku systemów ISA-95 poziomu 2, takich jak systemy kontroli nadzorczej i pozyskiwania danych (SCADA), programowalne logiczne układy sterowania oraz systemy automatyki wsadowej. Dane (zdarzenia) zostaną wchłonięte, a niektóre podstawowe przekształcenia/agregacje zostaną przeprowadzone przed zapisaniem danych w usłudze OCI Object Storage. Za pomocą dodatkowych analiz strumieniowych można identyfikować zdarzenia korelacyjne, a wszelkie zidentyfikowane wzorce można wprowadzić (ręcznie) w celu sprawdzenia nieprzetworzonych danych przy użyciu OCI Data Science.
- Do zaawansowanego analizowania tych strumieni danych o wysokiej częstotliwości w czasie rzeczywistym korzystamy z przetwarzania strumieniowego. Podczas gdy tradycyjne narzędzia analityczne wyodrębniają informacje z danych w spoczynku, analiza strumieniowa ocenia wartość danych w ruchu, czyli w czasie rzeczywistym. I to nie jest jedyna korzyść. Ponieważ analizy strumieniowe mogą być bardzo zautomatyzowane, są w stanie pomóc producentom zmniejszyć koszty operacyjne. Na przykład analiza strumieniowa może dostarczać dane w czasie rzeczywistym na temat kosztów podstawowych mediów, takich jak energia elektryczna i woda. Fabryki i zakłady mogą następnie za pomocą zautomatyzowanego narzędzia do analizy strumieniowej uzyskać natychmiastowy dostęp do informacji na temat obszarów, które można zoptymalizować pod kątem zmniejszenia kosztów energii i odpowiedniego reagowania na określone zdarzenia operacyjne za pomocą sztucznej inteligencji. Analizy strumieniowe mogą także tworzyć w czasie rzeczywistym prognozy dotyczące zbliżających się terminów wymaganych konserwacji sprzętu, pomagając firmom przygotować się na wszelkie nadchodzące naprawy lub rutynowe remonty.
- Choć potrzeby w zakresie czasu rzeczywistego ewoluują, najczęstszym ekstraktem z systemów ERP, planowania, zarządzania magazynek i logistyką jest wchłanianie wsadowe przy użyciu procesu ETL. Wchłanianie wsadowe służy do importowania danych z systemów, które nie obsługują strumieniowego przesyłania danych (na przykład starszych systemów SCADA lub zarządzania konserwacjami). Ekstrakty te mogą być wchłaniane nawet co 10 lub 15 minut, ale nadal mają charakter wsadowy, ponieważ ekstrahowane i przetwarzane są grupy transakcji, a nie pojedyncze transakcje. OCI zapewnia różne usługi do obsługi wsadowego wchłaniania, takie jak natywna usługa OCI Data Integration i Oracle Data Integrator działające w instancji OCI Compute. Wybór usług opiera się przede wszystkim na preferencjach klienta, a nie wymaganiach technicznych.
Utrwalanie, przetwarzanie i selekcjonowanie danych
Utrwalanie i przetwarzanie danych opiera się na dwóch (opcjonalnie czterech) składnikach. Niektórzy klienci używają wszystkich, a inni kilku z nich. W zależności od ilości i typów dane mogą być ładowane do magazynu obiektów lub bezpośrednio do strukturalnej relacyjnej bazy danych w celu trwałego przechowywania. Gdy przewidujemy zastosowanie funkcjonalności danologii, dane pobierane ze źródeł w postaci nieprzetworzonej (jako nieprzetworzony plik natywny lub ekstrakt) są częściej przechwytywane i ładowane z systemów transakcyjnych do magazynu w chmurze.
- Magazyn w chmurze to najpopularniejsza warstwa utrwalania danych dla naszej platformy danych. Może być używany zarówno w odniesieniu do danych usystematyzowanych, jak i nieusystematyzowanych. Podstawowymi elementami składowymi są usługi OCI Object Storage, OCI Data Flow i Oracle Autonomous Data Warehouse. Dane pobierane ze źródeł danych w ich nieprzetworzonym formacie są wychwytywane i ładowane do usługi OCI Object Storage. OCI Object Storage jest główną warstwą utrwalania danych, a Spark w OCI Data Flow jest podstawowym silnikiem przetwarzania wsadowego. Przetwarzanie wsadowe obejmuje kilka działań, w tym podstawowe techniki radzenia sobie z zakłóceniami (szumem), zarządzanie brakującymi danymi i filtrowanie na podstawie zdefiniowanych zestawów danych wychodzących. Wyniki są zapisywane z powrotem do różnych warstw magazynu obiektów lub do trwałego relacyjnego repozytorium na podstawie wymaganego przetwarzania i stosowanych typów danych.
- Użycie Oracle Big Data Service dla klastra Hadoop (zarządzanego klastra Hadoop) jest alternatywą dla konfiguracji usługi OCI Object Storage i OCI Data Flow. Potencjalnie można użyć obu połączonych konfiguracji w zależności od klienta i tego, czy zainwestował on w produkt lub umiejętności w zakresie ekosystemu Hadoop. Klienci, którzy już używają magazynu obiektów w w ramach klastra Hadoop (a nie systemu Hadoop Distributed File System) mogą przenieść tę konfigurację do Oracle Big Data Service. W grę mogą także wchodzić inne składniki środowiska Hadoop, takie jak Hive, na których może opierać się korzystanie z usługi Big Data Service w zależności od narzędzi do wizualizacji i danologii, które klient używa lub planuje używać w przyszłości. Choć ta architektura zawiera wszystkie oferowane przez Oracle usługi, klienci mogą nadal korzystać z niektórych już istniejących składników, zwłaszcza istniejących narzędzi do wizualizacji i danologii.
- Użyjemy teraz obsługującego magazynu danych do utrwalania wyselekcjonowanych danych w formie zoptymalizowanej pod kątem wydajności zapytań. Obsługujący magazyn danych udostępnia trwałą warstwę relacyjną, używaną do obsługi wyselekcjonowanych danych wysokiej jakości, bezpośrednio użytkownikom końcowym za pomocą narzędzi SQL. Rozwiązanie to tworzy instancję usługi Oracle Autonomous Data Warehouse (ADW) będącej magazynem danych obsługującym hurtownię danych przedsiębiorstwa oraz, jeśli jest to wymagane, bardziej wyspecjalizowane składnice danych na poziomie domeny. Może być także źródłem danych dla projektów dotyczących danologii lub repozytorium potrzebnego do uczenia maszynowego Oracle. Obsługujący magazyn danych może przyjmować jedną z kilku form, w tym Oracle MySQL HeatWave, Oracle Database Exadata Cloud Service lub Oracle Exadata Cloud@Customer.
Analizowanie danych, przewidywanie i podejmowanie działań
Funkcjonalność analizowania, przewidywania i podejmowania działań jest zapewniona dzięki trzem podejściom technologicznym.
- Zaawansowane funkcjonalności analityczne mają kluczowe znaczenie dla optymalizacji konserwacji i wydajności. W tym przykładowym sposobie zastosowania korzystamy z Oracle Analytics Cloud do dostarczania analiz i wizualizacji. Dzięki temu organizacja może korzystać z analiz opisowych (opisywanie bieżących trendów wraz z histogramami i wykresami), analiz predykcyjnych (przewidywanie przyszłych zdarzeń, identyfikowanie trendów i określanie prawdopodobieństwa niepewnych wyników) oraz analiz preskryptywnych (proponowanie odpowiednich działań wspierających podejmowanie optymalnych decyzji).
- Do wyszukiwania anomalii, przewidywania możliwych obszarów wystąpienia awarii i optymalizowania procesu zakupowego coraz częściej wykorzystuje się, oprócz zaawansowanych analiz, danologię, uczenie maszynowe i sztuczną inteligencję. W bazach danych mogą być wykorzystywane OCI Data Science, OCI AI Services lub Oracle Machine Learning. Używamy metod uczenia maszynowego i danologii do budowania i trenowania naszych modeli konserwacji predykcyjnej. Modele uczenia maszynowego można następnie wdrożyć do oceny za pomocą interfejsów API lub wbudować do potoku analizy OCI GoldenGate. W niektórych przypadkach modele te mogą być nawet wdrażane w bazie danych przy użyciu REST API usług Oracle Machine Learning Services (w tym celu model musi być w formacie Open Neural Network Exchange). Dodatkowo można wdrożyć usługę OCI Data Science do notebooka skoncentrowanego na Jupyter/Python lub Oracle Machine Learning do notebooka Zeppelin w obrębie obsługującego lub transakcyjnego magazynu danych. Podobnie do tworzenia modeli zaleceń/decyzji można użyć Oracle Machine Learning i OCI Data Science (samodzielnie lub w połączeniu). Modele te można wdrożyć jako usługę i umieścić za OCI API Gateway w celu udostępnienia jako „produkty danych” i usługi. Modele uczenia maszynowego mogą być również wdrażane w aplikacjach wchodzących w skład rozproszonego systemu kontroli (jeśli jest to dozwolone) lub wdrażane na granicy za pomocą urządzenia Oracle Roving Edge Device lub podobnego.
Do systemów reagowania i podejmowania decyzji dostarczanych przez usługi sztucznej inteligencji można zastosować wiele modeli tworzonych przez połączenie danologii z wzorcami określonymi przez uczenie maszynowe.
- Usługa OCI Anomaly Detection może pomóc w monitorowaniu wskaźników wydajności łańcucha zaopatrzenia (na przykład zapasów surowców, przepustowości produkcji, produkcji w toku, czasów tranzytu i rotacji zapasów itd.) w czasie rzeczywistym w celu identyfikacji i rozwiązywania problemów. W złożonym łańcuchu dostaw ocena wagi zidentyfikowanych anomalii może pomóc ustalić priorytety zaobserwowanych zakłóceń w prowadzeniu działalności.
- Prognozowanie OCI może ułatwić prognozowanie wskaźników łańcucha zaopatrzenia, takich jak popyt, podaż i wydajność zasobów, aby można było podjąć odpowiednie działania w celu wcześniejszego przygotowania się.
- OCI Vision i OCI Language mogą pomóc zrozumieć dokumenty, takie jak wychodzące raporty dotyczące jakości i wad produktów, w celu wzbogacenia danych łańcucha zaopatrzenia.
Ostatnim, lecz krytycznym składnikiem jest zarządzanie danymi. Usługa ta jest realizowana przy użyciu OCI Data Catalog, bezpłatnej usługi zapewniającej zarządzanie danymi i metadanymi (zarówno technicznymi, jak i biznesowymi) dla wszystkich źródeł danych w ekosystemie platformy danych. OCI Data Catalog jest także kluczowym składnikiem w przypadku zapytań z Oracle Autonomous Data Warehouse do OCI Object Storage, ponieważ umożliwia szybkie wyszukiwanie danych bez względu na metodę ich przechowywania. Dzięki temu użytkownicy końcowi, programiści i badacze danych mogą używać wspólnego języka dostępu (SQL) we wszystkich utrwalonych magazynach danych w architekturze.
Korzyści z używania danych w celu zwiększenia wydajności operacyjnej i efektywności działania
W miarę przyspieszenia rozwoju działalności i wzrostu poziomu konkurencji starsze systemy, używane do dostarczania krytycznych danych operacyjnych, nie nadążają za zmieniającymi się wymaganiami. Systemy te wymagają znacznej ręcznej interwencji w celu zestawienia, zintegrowania i utworzenia raportów na podstawie rozproszonych i niezintegrowanych danych, a to oznacza, że informacje docierają zbyt późno, aby zapewnić firmie potrzebne korzyści.
Optymalne wykorzystanie zasobów produkcyjnych ma kluczowe znaczenie dla optymalizacji działań produkcyjnych. Każda minuta spędzona na produkcji niewłaściwych produktów lub nieefektywnej produkcji właściwych produktów nie tylko podnosi koszty i powoduje straty, ale także uniemożliwia dostarczanie tego, czego potrzebują klienci. Optymalizacja działalności i poprawa wydajności może przynieść producentom wiele korzyści, takich jak:
- Większa efektywność, wydajność i produktywność oraz krótszy czas produkcji i niższe koszty
- Mniejsza liczba usterek, wyższa jakość produktów i większe zadowolenie klientów
- Szybka identyfikacja zagrożeń dla bezpieczeństwa, co prowadzi do poprawy praktyk BHP i zmniejszenia liczby wypadków w miejscu pracy
- Mniej odpadów, większa wydajność łańcucha zaopatrzenia i optymalizacja stanu zapasów
- Lepsza zdolność konkurowania w zakresie cen, jakości i innowacji, zapewniając przewagę konkurencyjną na rynku
- Poprawa procesu zrównoważonego rozwoju poprzez redukcję ilości odpadów, zwiększenie efektywności energetycznej i zminimalizowanie wpływu procesów produkcyjnych na środowisko
Zasoby powiązane
-
Przykład zastosowania
Wykorzystanie danych do zwiększenia bezpieczeństwa i higieny w miejscu pracy
Dowiedz się, jak zwiększyć bezpieczeństwo działań produkcyjnych, korzystając z platformy danych, która pomaga poprawić bezpieczeństwo i higienę pracy dzięki zaawansowanym narzędziom analitycznym.
-
Przykład zastosowania
Szybsze uzyskiwanie informacji o zakładzie produkcyjnym dzięki obliczeniom brzegowym
Dowiedz się, jak wydajniej konsolidować dane zakładu i szybciej uzyskiwać informacje za pomocą platformy Oracle skupiającej dane dla branży produkcyjnej.
-
Przykład zastosowania
Wykorzystanie danych do przejścia z konserwacji reaktywnej na konserwację przewidującą
Dowiedz się, jak zoptymalizować zasoby za pomocą platformy skupiającej dane, która umożliwia konserwację przewidującą dzięki funkcji samouczeniu się maszyn.
Pierwsze kroki
Przetestuj ponad 20 zawsze bezpłatnych usług chmurowych i zyskaj jeszcze więcej dzięki 30-dniowemu okresowi próbnemu
Oracle oferuje bezpłatną wersję próbną ponad 20 usług, takich jak AI Database, Arm Compute lub Storage, a także 300 USD w postaci bezpłatnych kredytów, które można wykorzystać do wypróbowania dodatkowych usług. Poznaj szczegóły i załóż darmowe konto już dziś.
-
Co zapewnia Oracle Cloud Free Tier?
- Dwie instancje Autonomous AI Database po 20 GB każda
- Maszyny wirtualne AMD i Arm Compute
- Magazyn bloków o łącznej pojemności 200 GB
- 10 GB pamięci obiektowej
- 10 TB transferu danych wychodzących na miesiąc
- Dodatkowe 10+ zawsze bezpłatnych usług
- 300 USD w postaci darmowych kredytów ważnych 30 dni, które można przeznaczyć na dodatkowe usługi
Nauka krok po kroku
Poznaj szeroki zakres usług OCI poprzez samouczki i zajęcia praktyczne. Bez względu na to, czy zajmujesz się programowaniem, administrowaniem czy analizami, pokażemy Ci, jak działa OCI. Wiele szkoleń jest dostępnych za pośrednictwem Oracle Cloud Free Tier lub w udostępnionym przez Oracle bezpłatnym środowisku laboratoryjnym.
-
Podstawowe usługi OCI — wprowadzenie
Te warsztaty obejmują wprowadzenie do podstawowych usług Oracle Cloud Infrastructure (OCI), takich jak wirtualne sieci w chmurze (VCN), usługi obliczeniowe czy pamięć masowa.
Rozpocznij szkolenie już teraz -
Autonomous AI Database — szybki start
Podczas tych warsztatów dowiesz się, jak zacząć korzystać z Oracle Autonomous AI Database.
Rozpocznij szkolenie już teraz -
Tworzenie aplikacji w oparciu o arkusz kalkulacyjny
Podczas tego kursu dowiesz się, jak przesłać arkusz kalkulacyjny do tabeli Oracle Database i jak stworzyć aplikację na podstawie tej tabeli.
Zacznij to laboratorium już teraz
Ponad 150 modeli najlepszych praktyk
Zobacz, w jaki sposób nasi architekci i inni klienci wdrażają różnorodne obciążenia — od aplikacji przedsiębiorstwa po HPC, od mikrousług po repozytoria data lake. Zapoznaj się z najlepszymi praktykami, posłuchaj wypowiedzi innych architektów w ramach serii Built & Deployed i wdrażaj wiele obciążeń poprzez klikanie gotowych opcji (click to deploy) lub skorzystaj z naszego repozytorium GitHub.
Popularne architektury
- Apache Tomcat z usługą MySQL Database Service
- Oracle Weblogic w Kubernetes z systemem Jenkins
- Środowiska uczenia maszynowego i sztucznej inteligencji
- Serwer Tomcat w architekturze Arm z usługą Oracle Autonomous AI Database
- Analiza dziennika z użyciem stosu ELK
- HPC z OpenFOAM
Zobacz, ile możesz oszczędzić dzięki OCI
Cennik Oracle Cloud jest przejrzysty, zapewnia równie niskie stawki na całym świecie i obejmuje różne przypadki użycia. Aby oszacować swoją niską stawkę, skorzystaj z estymatora kosztów i skonfiguruj usługi dopasowane do potrzeb swojej firmy.
Zauważ różnice:
- 1/4 kosztów ruchu wychodzącego
- 3-krotnie lepszy stosunek ceny do wydajności obliczeniowej
- Równie niska cena w każdym regionie
- Niskie ceny bez zobowiązań długoterminowych
Skontaktuj się z działem sprzedaży
Chcesz dowiedzieć się więcej o platformie Oracle Cloud Infrastructure? Nasi eksperci chętnie pomogą.
-
Mogą odpowiedzieć na następujące pytania:
- Jakiego rodzaju obciążenia najlepiej działają w OCI?
- Jak w pełni wykorzystać moje inwestycje w Oracle?
- Jak OCI wypada na tle innych dostawców usług przetwarzania w chmurze?
- W jaki sposób OCI może wspomóc Twoje plany związane z IaaS i PaaS?