 文章
大数据
文章
大数据
Oracle NoSQL Database 与 Cloudera Distribution for Hadoop 结合使用
作者:Deepak Vohra
通过一个测试项目了解相关的基本原理。
2012 年 6 月发布
2011 年推出的 Oracle NoSQL Database 是一个具有高可用性、高扩展性、基于键/值存储的(非关系)数据库,通过 Java API 为 CRUD 操作提供支持。Hadoop MapReduce 框架作为相关技术,为开发并行处理大型集群上的大量数据的应用提供分布式环境。
在本文中,我们将介绍如何通过 Oracle JDeveloper 项目(下载)将 Oracle NoSQL Database 和 Windows 操作系统上的 Cloudera Distribution for Hadoop 集成在一起。此外,我们还将演示如何在 Hadoop 中使用 MapReduce 作业处理 NoSQL Database 数据。
安装
该项目需要安装以下软件。请按照相应说明下载并安装您尚未安装的下列所有软件。
将 Java 1.7 安装在目录路径中的一个目录中(名称中不含空格)。设置 JAVA_HOME 环境变量。
在 Oracle JDeveloper 中配置 Oracle NoSQL Database
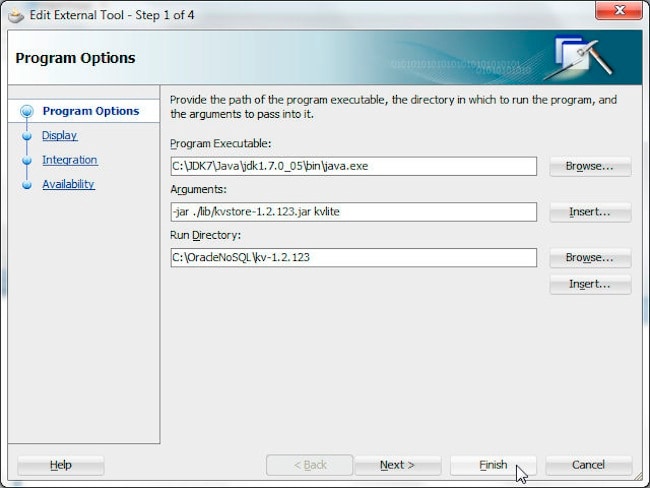
首先,我们需要在 JDeveloper 中将 NoSQL Database 服务器配置成一个外部工具。选择 Tools>External Tools。在 External Tools 窗口中选择 New。在 Create External Tool 向导中,选择 Tool Type: External Program 并单击 Next。在 Program Options 中指定以下程序选项。
| 域 | 值 |
Program Executable | C:\JDK7\Java\jdk1.7.0_05\bin\java.exe |
Arguments | -jar ./lib/kvstore-1.2.123.jar kvlite |
Run Directory | C:\OracleNoSQL\kv-1.2.123 |
在 Create External Tools 中单击 Finish:
此时,Oracle NoSQL Database 已配置为一个外部工具;外部工具的名称可能会有所不同,这取决于是否还配置了需要相同可执行程序的其他工具。在 External Tools 中单击 OK。
接下来,选择 Tools>Java 1。此时将启动 Oracle NoSQL Database 服务器并创建键值 (KV) 存储。
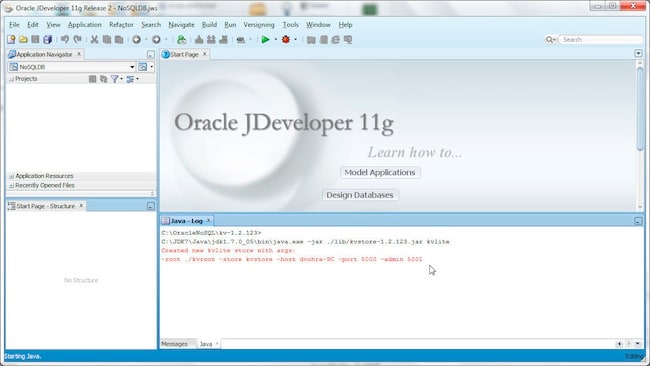
默认情况下,NoSQL Database 存储具有以下参数:
参数 | 值 |
-root | kvroot |
-store | kvstore |
-host | localhost |
-port | 5000 |
-admin | 5001 |
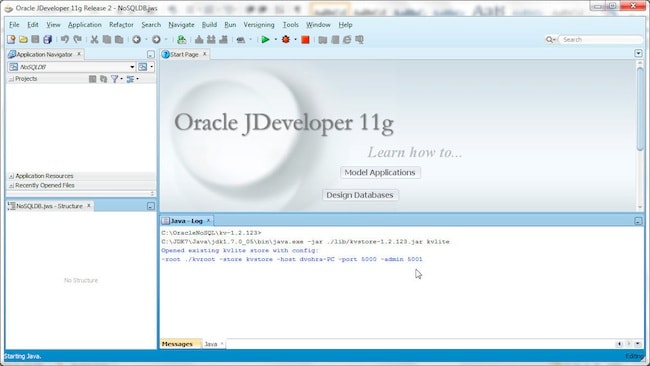
在后续运行 NoSQL Database 服务器这一外部工具时,系统将使用创建时使用的配置打开现有 KV 存储:
运行 HelloBigDataWorld 示例
NoSQL Database 软件包的 C:\OracleNoSQL\kv-1.2.123\examples 目录中包含一些示例。在本文中,我们将运行以下示例:
- hello.HelloBigDataWorld
- hadoop.CountMinorKeys
您可以将 HelloBigDataWorld 示例配置为一个外部工具来运行,也可以将其作为 Java 应用来运行。
用作外部工具
要将 HelloBigDataWorld 作为外部工具来运行,请选择 Tools>External Tools,然后按照 NoSQL Database 服务器的过程重新配置一个外部工具。我们需要创建两个配置,一个用于编译 HelloBigDataWorld 文件,另一个用于运行已编译的应用。为编译 HelloBigDataWorld 指定以下程序选项。
程序选项 | 值 |
Program Executable | C:\JDK7\Java\jdk1.7.0_05\bin\javac.exe |
Arguments | -cp ./examples;./lib/kvclient-1.2.123.jar examples/hello/HelloBigDataWorld.java |
Run Directory | C:/OracleNoSQL/kv-1.2.123 |
用于编译 hello/HelloBigDataWorld.java 文件的程序选项如下所示。单击 Finish。
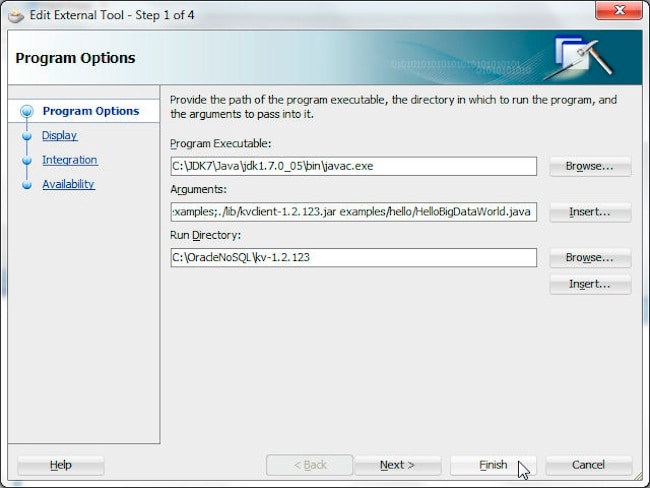
外部工具 Javac 创建完毕。选择 Tools>Javac 编译 hello/ HelloBigDataWorld.java 类。接下来,使用以下配置创建一个用于运行 hello.HelloBigDataWorld 类文件的外部工具。
程序选项 | 值 |
Program Executable | C:\JDK7\Java\jdk1.7.0_05\bin\java.exe |
Arguments | -cp ./examples;./lib/kvclient-1.2.123.jar hello.HelloBigDataWorld |
Run Directory | C:/OracleNoSQL/kv-1.2.123 |
类路径应包含 kvclient-1.2.123.jar 文件。单击 Finish。
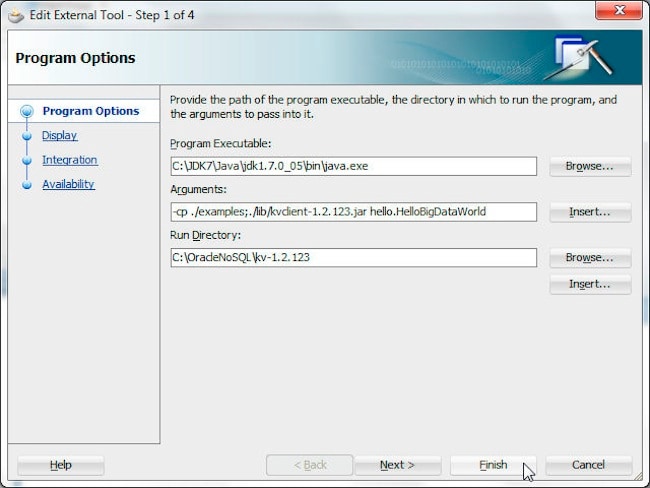
要运行 hello.HelloBigDataWorld 类,请选择 Tools>Java。此时,系统将运行 hello.HelloBigDataWorld 应用并编写一条短消息。
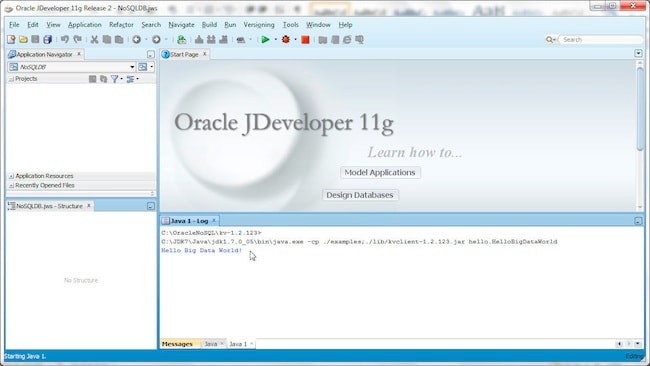
在 Java 应用中运行
接下来,我们将 hello.HelloBigDataWorld 应用作为 Oracle JDeveloper 项目中的一个 Java 应用运行。新建一个应用:
- 在 New Gallery 中选择 Java Desktop Application。
- 指定 Application Name(例如,NoSQLDB)并选择默认目录。单击 Next。
- 指定 Project Name(例如,NoSQLDB),然后单击 Finish。
接下来,在项目中创建 Java 类。
- 在 New Gallery 中选择 Java Class,然后单击 OK。
- 在 Create Java Class 中,将类名指定为“HelloBigDataWorld”,将软件包指定为“hello”。单击 OK。此时,hello.HelloBigDataWorld 类已添加到应用中。
- 将 C:\OracleNoSQL\kv-1.2.123\examples 目录中的 hello/HelloBigDataWorld.java 文件复制到 Oracle JDeveloper 的类文件中。
在示例应用中,系统将使用 KVStoreFactory 类新建一个 oracle.kv.KVStore:
store = KVStoreFactory.getStore(new KVStoreConfig(storeName, hostName + ":" + hostPort));
系统将创建键/值对并将其存储在 KV 存储中:
final String keyString = "Hello";
final String valueString = "Big Data World!";
store.put(Key.createKey(keyString), Value.createValue(valueString.getBytes()));
系统将从存储和输出中检索键/值。之后,KV 存储将关闭。
final ValueVersion valueVersion = store.get(Key.createKey(keyString));
System.out.println(keyString + " " + new String(valueVersion.getValue().getValue())+ "\n ");
store.close();
hello.HelloBigDataWorld 类如下所示。
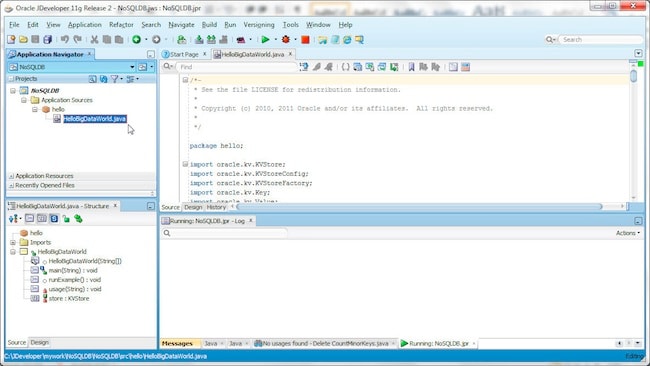
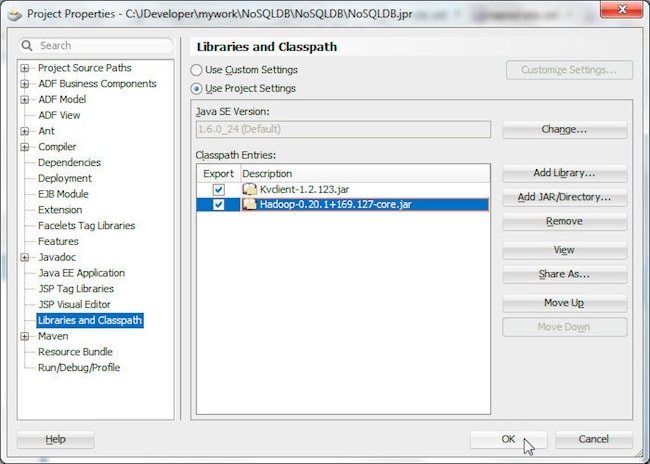
要运行 HelloBigDataWorld 类,请将 C:\OracleNoSQL\kv-1.2.123\lib\kvclient-1.2.123.jar 文件添加到 Libraries and Classpath 中。
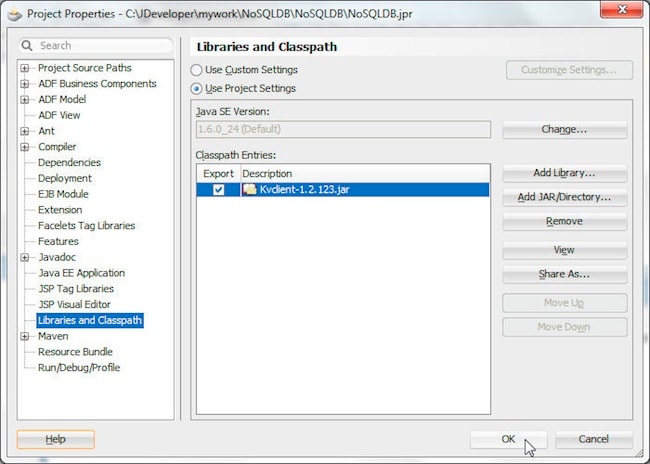
要运行该应用,请右键单击类并选择 Run。此时,系统将运行 hello.HelloBigDataWorld 类并生成一行输出。该示例应用将仅创建一个键/值对。
在下一节中,我们将运行 hadoop.CountMinorKeys.java 示例。为此,我们需要重新运行 HelloBigDataWorld 示例,在 KV 存储中创建其他键/值对:
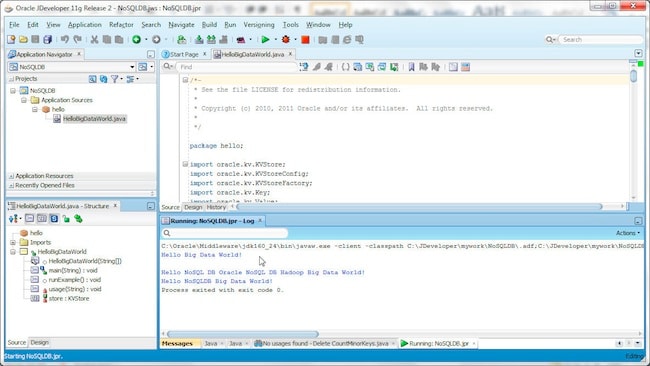
在 Hadoop 中处理 NoSQL Database 数据
接下来,我们将运行 C:\OracleNoSQL\kv-1.2.123\examples\hadoop\CountMinorKeys.java 中的 Hadoop 示例。创建一个名为 hadoop/CountMinorKeys.java 的 Java 类,然后将 \examples\hadoop\CountMinorKeys.java 文件复制到该类。
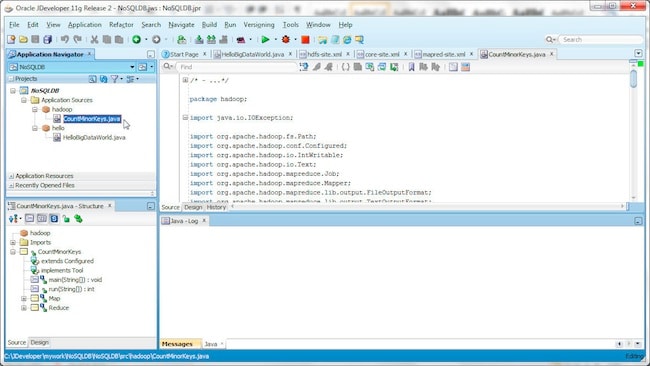
将 CDH jar 文件添加到项目中。
配置 Hadoop 集群
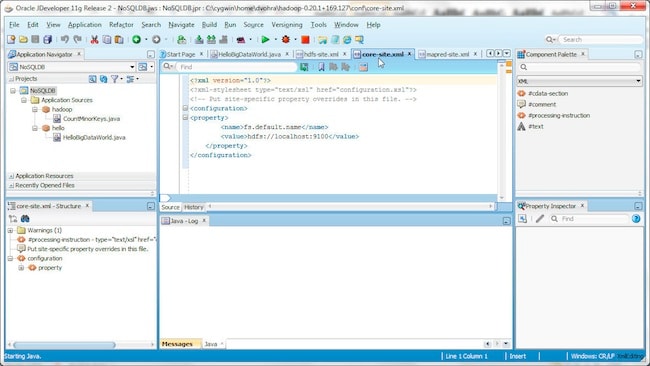
接下来,我们将配置 Hadoop 集群。CDH2 中有三个配置文件:core-site.xml、mapred-site.xml 和 hdfs-site.xml。在 conf/core-site.xml 中指定 fs.default.name 参数,即 NameNode 的 URI。
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9100</value>
</property>
</configuration>
core-site.xml 如下所示。
在 conf/mapred-site.xml 中,为 JobTracker 的主机或 IP 和端口指定 mapred.job.tracker 参数。将主机指定为 localhost,将端口指定为 9101。
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>localhost:9101</value>
</property>
</configuration>
conf/mapred-site.xml 如下所示。
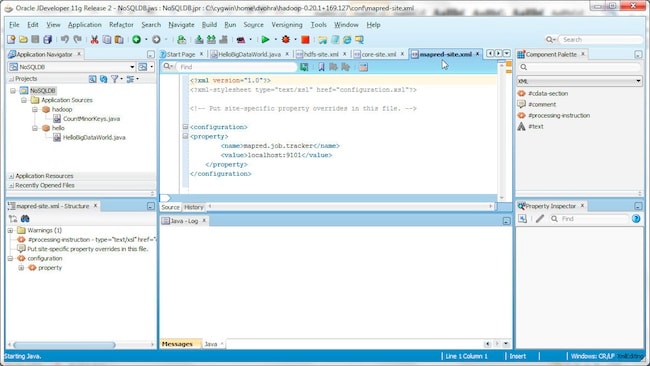
在 conf/hdfs-site.xml 配置文件中指定 dfs.replication 参数。dfs.replication 参数指定单个文件应复制到多少台计算机上后方才可用。该值不应超过 DataNodes 的数量。(在本例中,我们只使用一个 DataNode)
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
conf/hdfs-site.xml 如下所示。
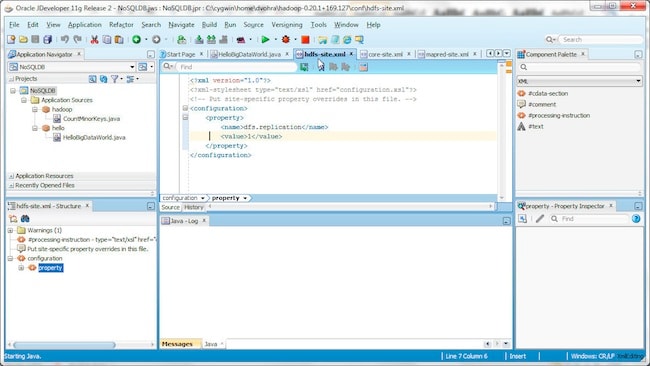
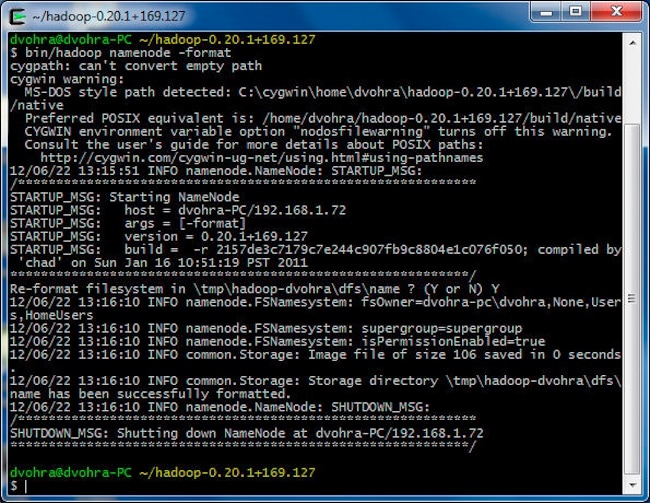
Hadoop 集群配置完毕,现在我们启动该集群。但首先,我们需要为处理 Hadoop 数据时使用的文件创建 Hadoop 分布式文件系统 (HDFS)。在 Cygwin 中运行以下命令。
>cd hadoop-0.20.1+169.127
>bin/hadoop namenode -format
存储目录 \tmp\hadoop-dvohra\dfs 创建完毕。
- 此外,我们还需要为 hadoop.CountMinorKeys 应用创建一个部署配置文件。在 Application Navigator 中选择项目节点,然后选择 File>New。
- 在 New Gallery 中选择 Deployment Profiles JAR File,然后单击 OK。
- 在 Create Deployment Profile 中,指定 Deployment Profile Name (hadoop) ,然后单击 OK。
- 在 Edit JAR Deployment Profile Properties 中,选择默认设置,然后单击 OK。
- 新部署配置文件创建完毕。单击 OK。
要部署该部署配置文件,请右键单击 NoSQL 项目并选择 Deploy>hadoop。
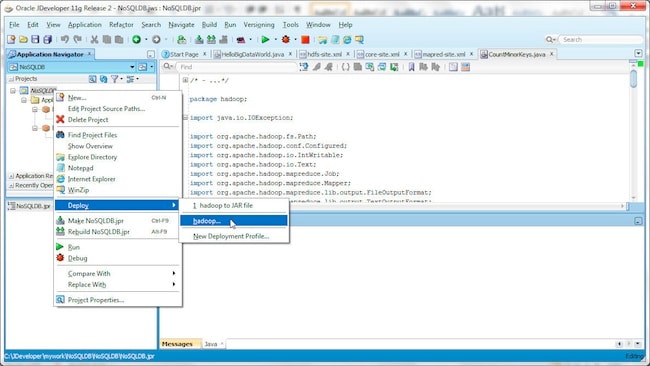
在 Deployment Action 中,选择 Deploy to JAR file 并单击 Next。在 Summary 中,单击 Finish。此时,hadoop.jar 已部署到 JDeveloper 项目的部署目录中。将 hadoop.jar 复制到 C:\cygwin\home\dvohra\hadoop-0.20.1+169.127 目录下,因为该应用将从 Cygwin 中的 hadoop-0.20.1+169.127 目录运行。
启动 Hadoop 集群
通常,多节点 Hadoop 集群包含下列节点。
节点名称 | 功能 | 类型 |
NameNode | 用于 HDFS 存储层管理。在上一节中,在创建存储层之前,我们已格式化 NameNode。 | master |
JobTracker | 管理 MapReduce 数据处理;分配任务 | master |
DataNode | 存储文件系统数据、HDFS 存储层处理 | slave |
TaskTracker | MapReduce 处理 | slave |
Secondary NameNode | 存储对文件系统所做的修改并定期将改动与 HDFS 现状合并。 |
|
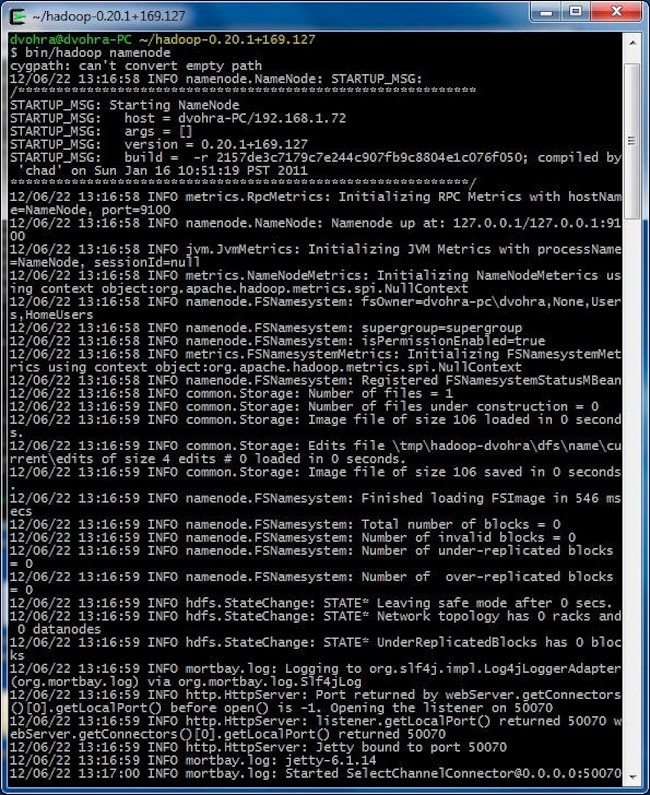
接下来,我们将启动集群中的节点。要启动 NameNode,请在 Cygwin 中运行以下命令。
> cd hadoop-0.20.1+169.127
> bin/hadoop namenode
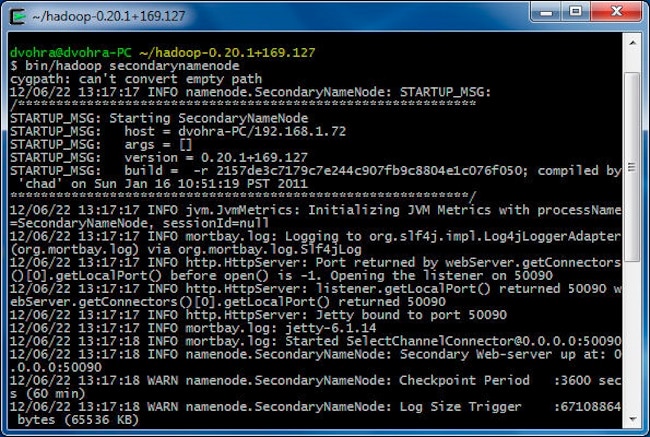
使用以下命令启动 Secondary NameNode:
> cd hadoop-0.20.1+169.127
> bin/hadoop secondarynamenode
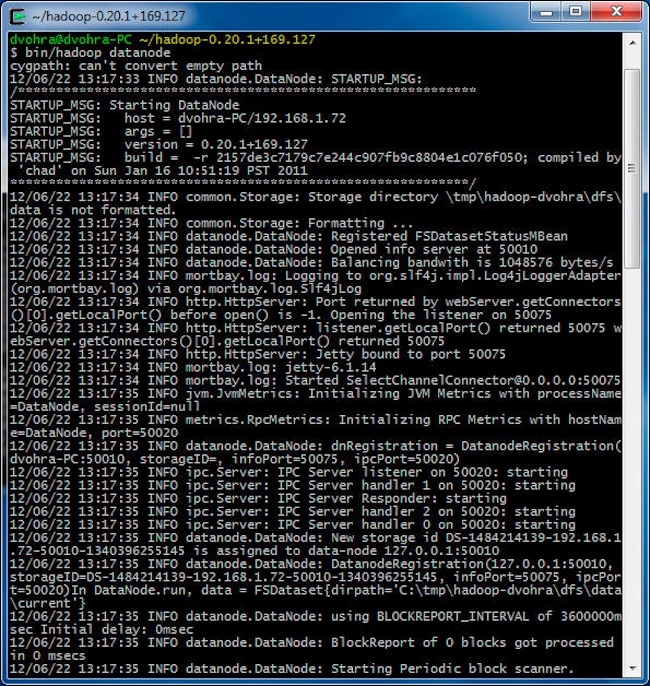
启动 DataNode:
> cd hadoop-0.20.1+169.127
> bin/hadoop datanode
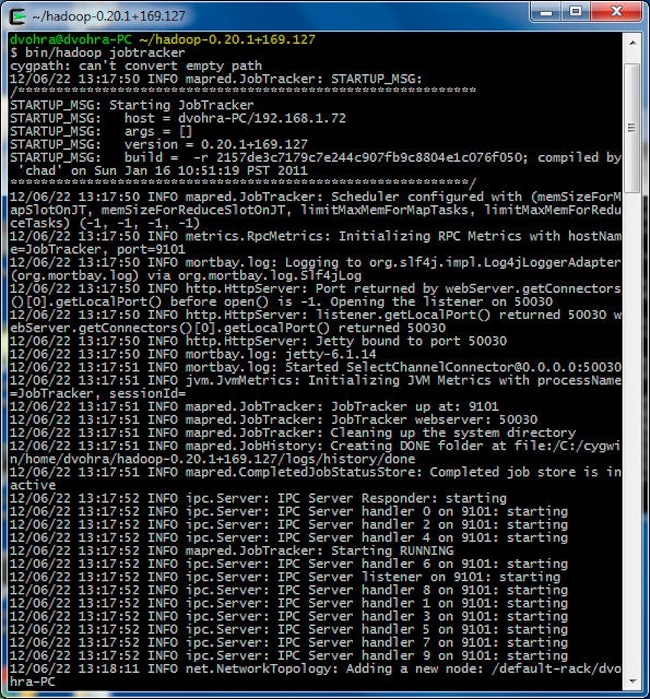
启动 JobTracker:
> cd hadoop-0.20.1+169.127
> bin/hadoop jobtracker
启动 TaskTracker:
> cd hadoop-0.20.1+169.127
> bin/hadoop tasktracker
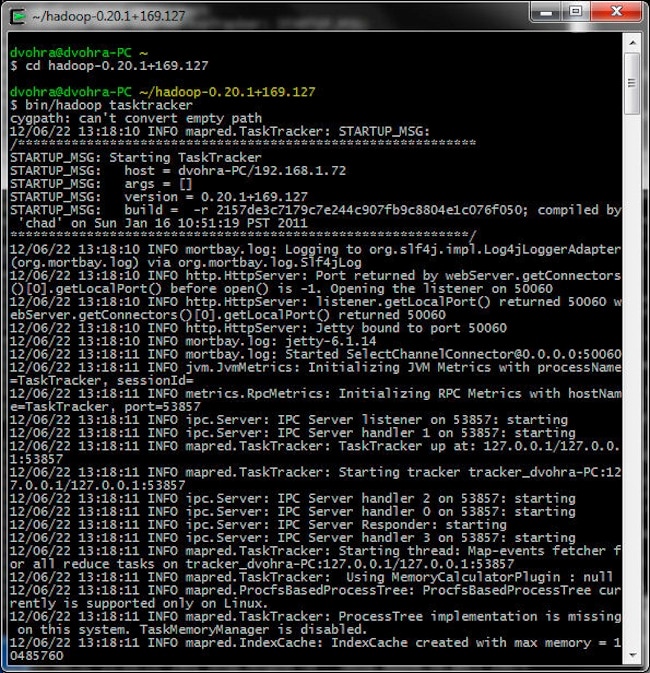
运行 MapReduce 作业
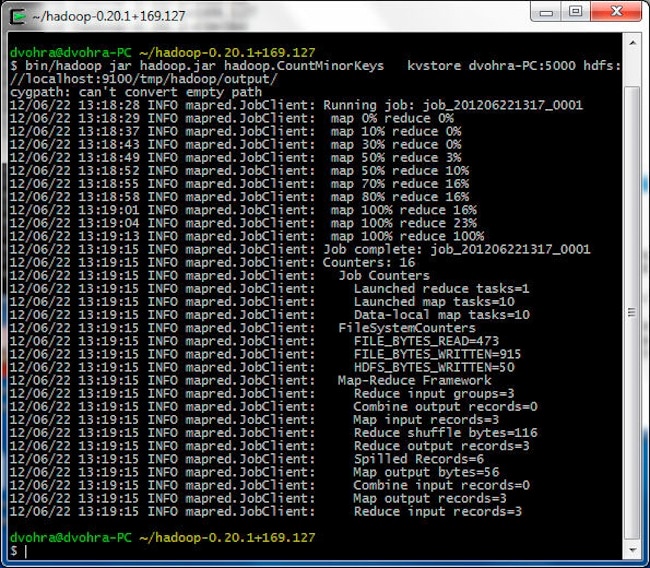
接下来,我们将运行为其创建了 hadoop.jar 文件的 hadoop.CountMinorKeys 应用。hadoop.CountMinorKeys 应用将对 KV 存储中的 Oracle NoSQL Database 数据运行 MapReduce 作业,并在 Hadoop HDFS 中生成输出。NoSQL Database 服务器 Java API 位于 kvclient-1.2.123.jar 目录中。将 C:\NoSQLDB\kv-1.2.123\lib 目录中的 kvclient-1.2.123.jar 复制到 C:\cygwin\home\dvohra\hadoop-0.22.0\lib 目录(该目录位于 Hadoop 的类路径中)。在 Cygwin 中,使用以下命令运行 hadoop.jar。
> cd hadoop-0.20.1+169.127
> bin/hadoop jar hadoop.jar hadoop.CountMinorKeys kvstore dvohra-PC:5000 hdfs://localhost:9100/tmp/hadoop/output/
此时,系统将运行 MapReduce 作业并在 hdfs://localhost:9100/tmp/hadoop/output/ 目录中生成输出。
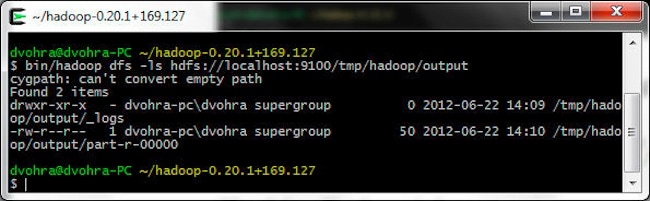
使用以下命令列出 temp/hadoop/output 目录中的文件。
> bin/hadoop dfs -ls hdfs://localhost:9100/tmp/hadoop/output
此时,系统将在 part-r-00000 文件中生成 MapReduce 作业输出,使用上述命令即可列出输出。
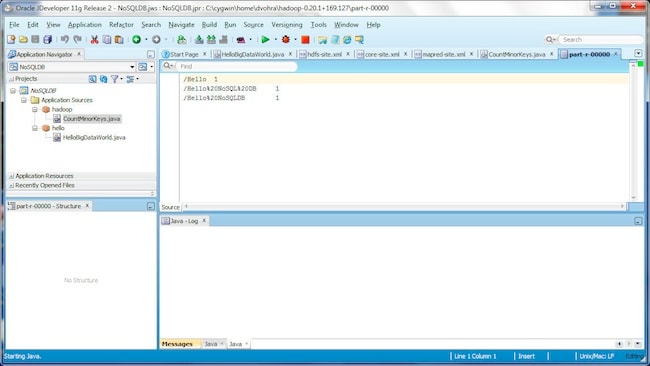
使用以下命令将 part-r-00000 文件获取到本地文件系统中:
bin/hadoop dfs -get hdfs://localhost:9100/tmp/hadoop/output/part-r-00000 part-r-00000
此时,Oracle JDeveloper 中将显示 MapReduce 作业输出;该输出将列出使用第一个示例应用 hello.HelloBigDataWorld 创建的 KV 存储中各个主键的记录数量。
祝贺您,项目已完成!
Deepak Vohra 是一名 NuBean 顾问,也是 Web 开发人员和 Oracle Database 10g 领域的 Oracle 认证专员。