文章
文章
| 开发人员:商务智能
使用 Oracle Application Server Discoverer 进行 Web 分析 了解如何使用 Discoverer 的报表功能以及 Apache Web 服务器生成的日志文件创建自己的网站报表系统。
如果您负责管理公司的网站或管理网站所驻留在的 Web 服务器,则很可能要向管理部门报告有关站点使用情况的统计数据。分析 Web 服务器所生成日志文件中的信息是优化站点以增加商业价值、改进用户体验和增强站点性能的有效途径。 许多公司依靠昂贵的现成分析工具实现此目的。某些公司需要常规报表(如总点击数、访问者会话数、唯一访问者数和页面浏览数)来度量其网站的有效性,某些公司则更深入地研究在日志文件中捕获的信息。更详细的报表提供了诸如请求率最高的页面、点击率最高的推荐页面、使用率最高的浏览器、带宽使用率、搜索引擎等信息。供应商提供的工具大都需要许可证支持成本,且某些程序包可能会根据流量或要报告的网站数量而增加成本。 但是,有时候对所生成跟踪文件的访问多少有些困难;您必须确保您可以访问数据库所在服务器上的 USER_DUMP_DIRECTORY。当数据库的连接基本基于客户端时,该数据库服务器可能并不总是可访问的。如果还要执行 TKPROF 指令将原始跟踪文件变得更具可读性,则一般需要具有从命令行访问数据库服务器的权限。如果 DBA 需要为多个不同服务器上的多个不同数据库提供支持,则访问所生成的跟踪文件以及使用 TKPROF 对这些文件进行格式化的工作就变得更困难了。 本文将概述一个可供运行 Oracle 应用服务器 10g 企业版 的公司使用的另一方法。这些公司不必投资其他昂贵的信息工具,只需将 Oracle Application Server Discoverer 查询和分析工具的报表功能和灵活性应用于信息丰富的 Web 服务器日志文件,即可生成可与独立解决方案提供的报表相媲美的报表。(本文假设您了解 Discoverer 的基础知识;更多详细信息,请参考 Oracle 文档。 昂贵 Web 分析软件的这个低成本替代方法可以通过以下四个步骤实现:
以下部分介绍了建立 Web 分析报表工作薄所需的步骤。 第 1 步:构建 Apache 组合日志文件的数据结构 该示例将使用从 Apache Web 服务器创建的组合日志文件。这些分隔的日志文件可以轻松地导入到电子表格或数据库中,但要针对更大的信息集合(例如,#USER_AGENT)中的数据生成报表则存在一定的困难。这种情况下,使用 ETL 脚本(参见本文的源代码)有助于将信息分解为独立的、更有意义的字段。使用 ETL 脚本预先分析数据,可以消除工作簿中的复杂计算和摘要。 下面显示了 Apache 组合日志文件中的一个条目。 127.0.0.1 - username [09/Sept/2004:13:55:36 -0600] "GET /someimage.gif HTTP/1.0" 200 1234 "http://www.mywebsite.com/index.asp" "Mozilla/4.08 [en] (OS; Version ;Browser)"下表显示了日志文件示例中的各个参数,以及由 Apache Software Foundation 给出的相应定义。
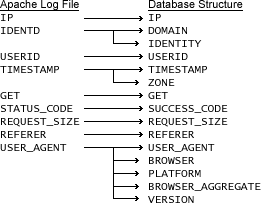
为了理解日志文件记录是如何如何分析的,图 1 显示了为将文件导入到数据库结构中而创建的数据映射。
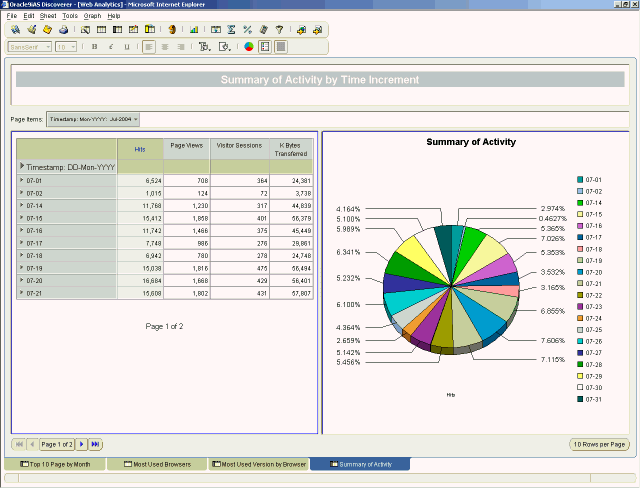
TIMESTAMP 分为两个字段:一个表示时间和日期,另一个表示时区。分析此日志文件时,可以在业务区中创建一个条目,以便钻入和钻出多个级别的时间和日期,如年、季度、周、日和小时。 USER_AGENT 字段包含有关网站访问者的多个类型和级别的信息。通过将此信息划分为不同的字段,您将能够识别浏览器的类型、浏览器的版本以及访问者访问您的网站所使用的平台和平台版本。 当您要跟踪网站上的错误和成功点击时,SUCCESS_CODE 将很重要。该结构是确定访问者会话数的关键所在,用于报告对 web 页的成功点击。将它作为页面项包含在工作簿上可以使您能够在成功代码和错误代码之间进行切换。 在下一部分中,我们将介绍可用于分解组合的日志文件的 ETL 触发器和 SQL 加载器脚本。(源代码下载提供了所有数据库创建脚本、SQL 加载器文件、Discoverer 导出文件和 Discoverer 工作簿文件。) 第 2 步:创建 ETL 触发器和 SQL 加载器脚本 清单 1 中显示的插入触发器将 Apache 日志文件分解为有意义的数据,该数据可用于随后的查询。您可以调整此触发器以满足特定需要。 您转换的第一个数据元素(脚本的第 1 部分)是获取根文档(如 index.htm 和站点名(如 www.mywebsite.com),两者是同义的),并将其设置为同一条目。Apache 将它们作为两个不同的条目存储在日志文件中。出于分析目的,它们对我们而言是同一条目。 在触发器的第 2 部分到第 5 部分中,您从 Apache User Agent 字段中提取不同的数据部分。Apache 中的 User Agent 字段内部包装了几个重要的数据。由于访问网站的操作系统和浏览器的不同,可能很难识别此字段并将其转换为单个有意义的数据元素。 在第 2 部分中,您将获得访问我们站点的浏览器。 在第 3 部分中,您将获得访问我们的站点的平台/操作系统。 在第 4 部分中,您将填充 WEB_DETAIL 表的 BROWSER_AGGREGATE 列。在该部分中,您将所有 Microsoft 浏览器(5.1、5.2、6.0 等)归为“Microsoft Internet Explorer”一个条目。 第 5 部分用于提取所使用浏览器的版本。 第 6 部分只是将请求大小转换为千字节,以便节省随后的计算时间。 第 3 步:构建业务区 源代码包含文件 WebAnalytic.eex,用于将业务区导入到 Discoverer 中。业务区为您创建了日期层次和几个项类,包括状态描述、用户代理、浏览器、平台、浏览器聚合和版本。 建议您将此业务区导入到开发系统中。要这样做,请打开 Discoverer Administrator,选择 File ,选择 Import ,然后浏览到 WebAnalytic.eex。 创建 Discoverer 工作簿 要确定最适合您业务或 Web 服务器管理员需要的报表,应预先定义要求,以免浪费时间创建无关的报表。如果要为不需要知道收入跟踪或产品销售的最终用户发布内容,则查看率最高的 10 个页面、最主要的访问者、来源页面、进入/退出页面、带宽使用情况、浏览器、平台等报表即可满足需要。根据经验,您可能需要一个摘要页面,用于显示某个日期范围(多数情况下为一个月)的高层次数字。此摘要可以轻松地实现流量模式(如点击数、访问者会话数、页面浏览数和带宽使用情况)的可视化。
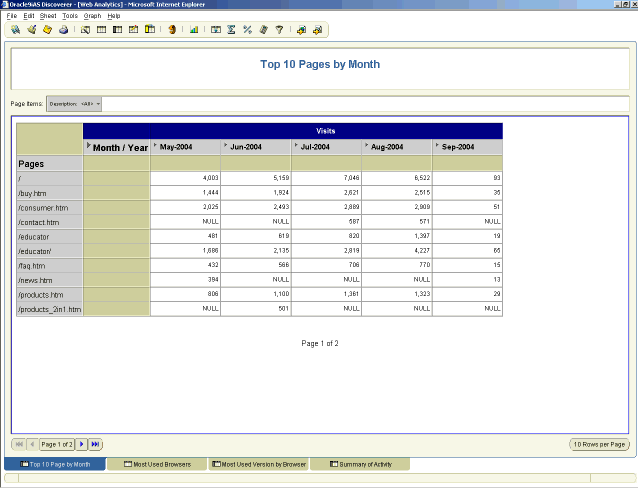
对于电子商务站点,除了上述报表外,您可能还会创建访问者图形、购买历史、销售模式、畅销产品、帐单首选设置以及支付类型、引用以及搜索引擎。 尽管需要对 ETL 和 Web 服务器进行某些配置以生成上面提到的某些字段,但 Web 服务器创建的日志文件的信息中提供了所有这些项。 定义了要度量的内容后,您可以开始创建表视图和交叉表 Discoverer 报表。您可能发现交叉表报表功能更适合您跨日期范围和类别比较数据的需要。创建 RANKING 条件并将它应用于 IP 计数将使您能够查看“前 X”个记录(前 10 个最为常见)。
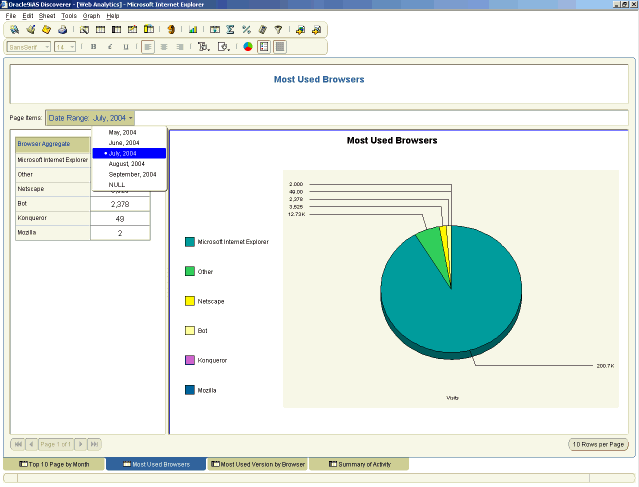
确保利用将页面项分配给报表以添加快速过滤功能。TIMESTAMP 可以用作报表(如前 10 个页面、访问者会话和点击数)的页面项。您可能还选择将 BROWSER 指定为页面项以进一步获得 VERSION。
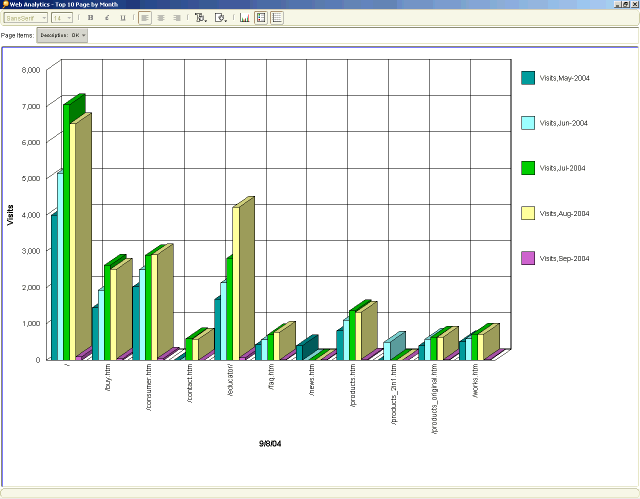
除显示特殊类别的详细信息和摘要以外,Discoverer 还提供了一个易于使用的图形特性。可以饼图和条形图、面积图和直线图的形式将二维和三维图形添加到报表中。可以定制每个图形,以便针对行或列数据、总计或详细信息产生报告。Discoverer 图形允许设计者添加 X 和 Y 轴的定制标题和标签。
另一个可能有帮助的特性是 Workbook Scheduler,它使您能够在非核心业务时间外处理工作簿。对于复杂和需要大量时间的报表而言,该方法可以减少用户等待报表生成的时间。 完成工作簿后,可以通过 Discoverer Plus 或 Discoverer Viewer 将 Web 分析报表工作簿提供给最终用户。然后,用户可以通过选择要使用的工作表来查看报表和图形。 结论 现在您应已经很好地了解了 Apache 日志文件以及如何使用 Oracle Application Server Discoverer 将它转换为强大和可操作的商务智能。 由于许多 Apache 日志文件包含大量记录,因此您可以考虑使用分区或其他功能来改进性能。通过这些步骤,您已经完成了对到达企业站点的流量进行特定分析的所有必要工作。 Timothy Cambier ( cambier@neo.rr.com) 是一位居住在俄亥俄州格林的高级 Web 开发人员。他还在 DevX.com 上发表了不少有关开放源方面的文章。 Brian Carr ( bcarrdba@neo.rr.com) 是一位居住在俄亥俄州托尔马其的高级 Oracle 数据库管理员和 Oracle 认证专家。 Database Trends and Applications、 JavaWorld、 Database Journal 和 SELECT Journal 中都曾发表过他的文章。
|