 文章
云计算
文章
云计算
结合使用 Oracle Coherence 和 Spring Batch 进行高性能数据处理
作者:Vijay Nair
使用 Spring Batch 框架,再结合多线程数据加载方法,如何提高基于 Coherence 的应用程序的可管理性和性能
2011 年 12 月发布
随着越来越多的公司准备利用内存中处理在处理大型数据集方面的优势,人们对促进这种处理的产品的兴趣迅速变得浓厚起来。Oracle Coherence 凭借其简单的界面、对流行平台(如 C++、.Net、Hibernate、JPA)的广泛支持,以及可用最小配置容纳 TB 级数据的可伸缩性,在这一领域技压群芳,表现不俗。
此外,随着环境中数据网格缓存重要性的提高,越来越迫切需要确保:
- 将数据从任何源(如平面文件/数据库)加载到缓存所需的时间最短
- 加载到缓存的数据具有认可的质量和可靠性
- 具有恰当的错误处理机制(如通知相应部门)
- 提供缓存数据加载报告
确保数据加载过程的这些方面将保证数据网格缓存上数据的可靠性。Spring Batch(SpringSource 产品系列中的开源项目)是具有上述属性的、为处理大型数据提供基础架构的 Java 批处理框架。
本文演示如何使用 Spring Batch 将 CSV 文件加载到 Oracle Coherence 缓存中。为简单起见,我们将重用包括在与 Oracle Coherence 3.7.1 一起提供的示例分发文件中的同一 contacts.csv 文件(已修改为添加 99,990 条记录)。
在此,我们将假设您对 Coherence、Spring Framework 和 Spring Batch 有一定了解。
项目设置
在此我们将使用 Oracle Enterprise Pack for Eclipse (OEPE),它为使用 Oracle 融合中间件技术(本示例中为 Coherence)作为 IDE 运行/调试应用程序提供了一组全面的插件。OEPE 还为 Spring 提供了全面的工具支持,因此,它成为像我这样同时使用这两套技术的开发人员必不可少的软件。
首先,我们将在 OEPE 中创建一个新的 Spring 项目,包含以下文件夹结构和文件(在这里下载示例)。还需要添加所有 Spring Framework 核心 jar 文件(包括其依赖项)、Spring Batch jar 文件和 Oracle Coherence jar 文件(位于 <<COHERENCE_HOME>>/lib 下)。除了使用随 Coherence 提供的示例模型之外,还需要编译 Coherence 提供的 examples.zip 文件中的所有 Java 文件,并将这些文件导出为一个 jar 文件,例如,导出为 examples.jar。
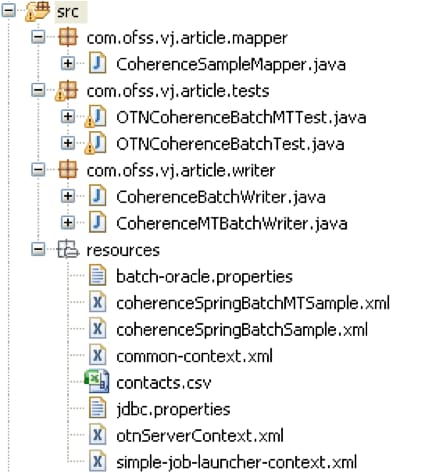
图 1 新 Spring 项目
修改后的 contacts.csv 文件包含联系人信息。此文件的每一行将作为一个映射加载到缓存中,该映射以 ContactId 对象为键,Contact 对象为值。Contact 对象包含:
- 名的字符串表示
- 姓的字符串表示
- 两个“Address”对象(Home 和 Work)
- 包含由“PhoneNumber”对象表示的两个电话号码的映射
ContactId 对象包含:
- 名的字符串表示
- 姓的字符串表示
需要确保所有记录的名与姓的组合是唯一的,因为需要用它作为映射的键。下面显示了一些示例数据。
John,Loehe,1968-01-01,675 Beacon St.,,Dthaba,SC,91666,US,Yoyodyne Propulsion Systems,330 Lectroid Rd.,Grover's Mill,NM,41888,US,home,11,74,286,6864191,work,11,45,362,5379579,
John,Vadrypkwiy,1978-12-29,62 Beacon St.,,Zxnmgcw,OR,18083,US,Yoyodyne Propulsion Systems,330 Lectroid Rd.,Grover's Mill,DC,81140,US,home,11,82,98,4330491,work,11,56,422,7695959,
使用 Spring Batch
Spring Batch 基于项目读取器和项目写入器的概念。它还提供工具来创建将文件中的每一行数据映射到模型文件的自定义映射器类。为使示例更有趣,我们将分别演示使用单个执行线程以及通过多个执行线程来执行加载。
首先,定义一个名为 batchCoherence 的作业,其中有一个步骤将使用 Spring Batch 提供的 FlatFileItemReader 作为读取器,还使用一个自定义映射器 (CoherenceSampleMapper.java) 和一个自定义写入器 (CoherenceBatchWriter.java)。

图 2 batchCoherenceJob
“块”的提交间隔配置为 1,000,即它将调用读取器 1,000 次并使用 1,000 个项目填充列表。在此块中,写入器将只调用一次,由此提供一种高可伸缩性的架构。
对于读取器,配置如下:
- 将要加载的资源,本例中为 contacts.csv
- 分隔符为“,”的 DelimitedLineTokenizer
- FieldSetMapper 为自定义映射器 (CoherenceSampleMapper.java),将每一行转换成期望的模型
映射器实现 Spring Batch 框架提供的 FieldSetMapper,并且对于从该文件读取的每一行都会调用该映射器。然后映射器将对其可用的数据转换成返回到 Spring Batch 基础架构的 Contact 模型。
读取器如下所示:
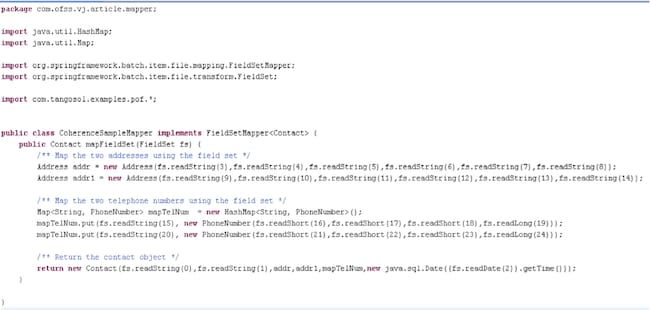
图 3 CoherenceSampleMapper.java
自定义写入器具有以下特征:
- 我们让它来实现由 Spring Batch 框架提供的 ItemWriter 接口并实现 write() 方法。如前所述,在每个块操作期间,将调用读取器 1,000 次,且在映射到模型之后,将块作为项目列表提供给写入器,写入器可以选择对块执行任何操作 — 在本例中,是将块写入 Coherence 缓存。
- 我们让它来实现由 Spring Batch 框架提供的 StepExecutionListener 接口并实现 beforeStep() 和 afterStep() 方法。顾名思义,这是一个可以基于特定事件触发方法的监听器类。因此在本例中,我们希望在开始读/写之前在 beforeStep() 方法中打开 CacheFactory,并在推入缓存之后在 afterStep() 方法中从容关闭 CacheFactory。
- 我们让它来实现由 Spring Batch 框架提供的 ChunkListener 接口并实现 beforeChunk() 和 afterChunk() 方法。这有助于在读取和处理每个“块”之前和之后执行某些活动。在本例中,我们在每次缓存推送之后清除映射“mapBatch”。
写入器如下所示:

图 4 CoherenceBatchWriter.java
可以看到,Spring Batch 提供了许多有用的方法,可以帮助您通过将职责非常明确的映射出去来维护代码。此外,在这些监听器方法的任何一个中,均可实现一种有用的通知/触发器机制,使之在加载输入文件失败或在数据推入缓存失败时发出通知/触发告警。(但这不在本文的讨论范围内。)
准备多线程示例
接下来,为准备比较单线程方法和多线程方法,我们将定义一个名为 batchCoherenceJobmt 的新作业,其中有一个步骤将使用与单线程示例相同的 FlatFileItemReader 以及相同的自定义映射器 (CoherenceSampleMapper.java)。还将准备一个新的自定义多线程写入器 (CoherenceMTBatchWriter.java)。

图 5 batchCoherenceJobmt
此次分配一个小任务,用于使用异步任务执行器(Spring 提供的任务执行器实现)执行,其中调节限制设置为 5。(注意,您可以分配任何类型的 Spring 任务执行器实现,只要有助于重用线程资源。)
与前面一样,“块”的提交间隔配置为 1,000,即它将调用读取器 1,000 次并使用 1,000 个项目填充列表。在此块中,写入器将只调用一次。
读取器和映射器的配置与单线程示例中的相同:
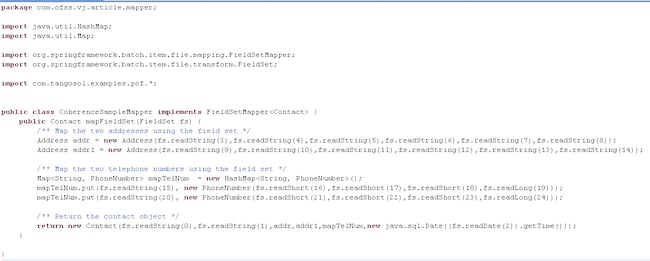
图 6 CoherenceSampleMapper.java(多线程版本)
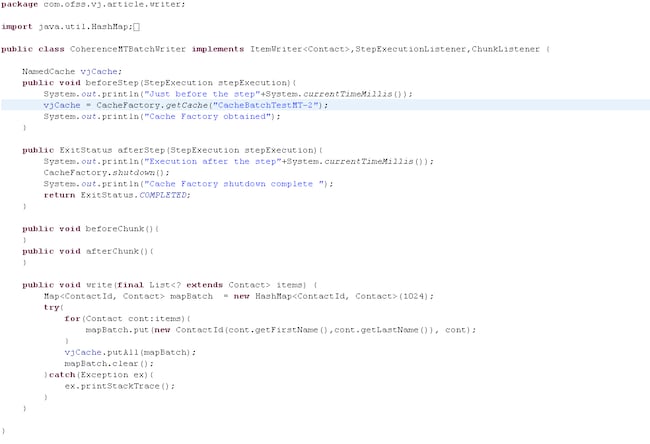
图 7 CoherenceBatchWriter.java(多线程版本)
至此,我们创建了新的 Map<ContactId,Contact> 并在写入方法本身清除它,从而使得它从多线程执行的角度来看是线程安全的。
接下来,我们继续测试阶段并比较单线程和多线程的数据加载方法。所有测试均在一台笔记本电脑上进行,它的配置为 Intel 双核 CPU @2.4 Ghz,2GB 的 RAM。
执行:单线程
由于使用 Oracle 数据库信息库作为批处理信息库来存储有关每个作业执行的信息,对于数据库中存在的 Spring Batch 元数据表也同样必须如此(参见 static.springsource.org/spring-batch/reference/html/metaDataSchema.html)。对于此示例,可以配置资源文件夹下的 jdbc.properties 使其指向测试数据库。(在执行之前,您需要在 classpath 中添加 ojdbc.jar [或相应的内容]。)
首先使用位于 <<COHERENCE_HOME>>/bin 下的 cache-server.cmd 启动一个常规 coherence 服务器。
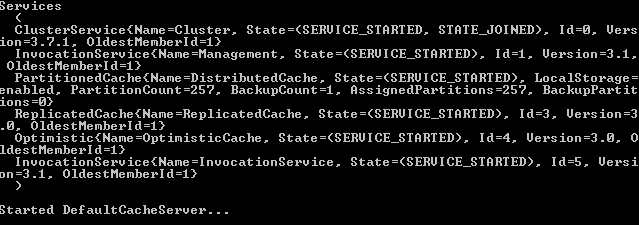
图 8 启动服务器
还要使用 <<COHERENCE_HOME>>/bin 下的 coherence.cmd 启动另一个 coherence 节点并输入:
Map <?>: cache CacheBatchTestNonMT
(为单线程场景指定的缓存)
这将显示一个要求输入指定缓存的提示。使用 size 命令的快速测试表明此指定缓存是空的: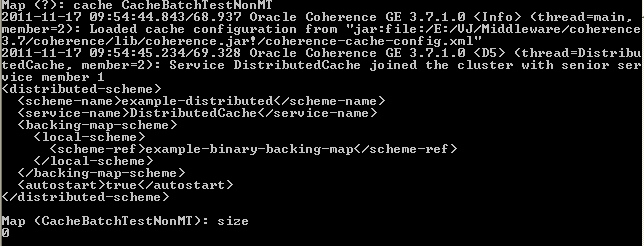
图 9 运行 size 测试
回退到 Eclipse,打开一个用 Spring 的 JUnit 支持编写的简单测试用例 (OTNCoherenceBatchTest.java),它将加载 Spring 应用程序上下文所需的所有文件。
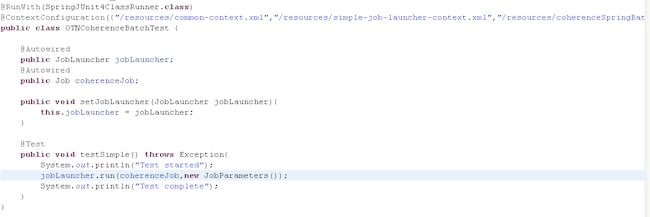
图 10 OTNCoherenceBatchTest.java
右键单击该类并选择 Run as JUnit test。在 Eclipse 控制台中,可以清楚地看到它加入现有集群并获得一个缓存连接工厂。
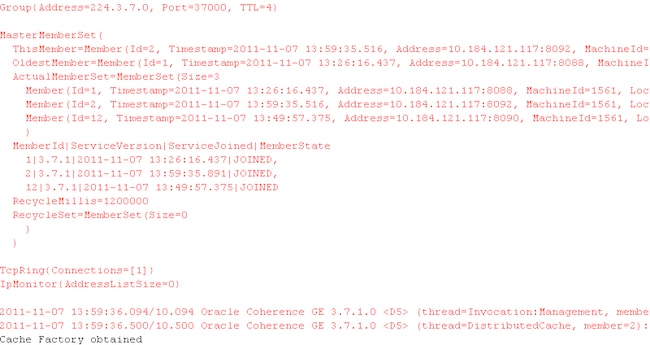
图 11 JUnit 测试的结果
在主服务器(使用 cache-server.cmd 启动的服务器)中,可以看到数据正在传送。

图 12 数据传送正在进行
Coherence 节点使用 coherence.cmd 启动,键入 size 后的结果表明缓存中包含从文件加载的数据:
Map <CacheBatchTestNonMT): size
99990
查询批处理步骤执行表,可得到执行时间为 53.297 秒。
接下来,我们将这一结果与多线程方法的结果进行比较。
执行:多线程
我们遵循与前面相同的步骤,只是这一次使用一个新的名为 CacheBatchTestMT-2 的指定缓存。
运行创建的另一个 JUnit 测试用例来测试此用例 (OTNCoherenceBatchMTTest.java) 并检查大小:
Map <CacheBatchTestMT-2>:size
99990
查询批处理步骤执行表,可得到执行时间为 28.218 秒,这比顺序执行法节省了约 45% 的时间。
总结
Oracle Coherence 通过提供对内存中数据网格的快速访问(批处理中的一个重要方面),帮助全球金融机构提高批处理负载的性能。但随着 Coherence 数据网格大小的增长,最大程度缩短加载数据和访问数据所需的时间已成为一个极其重要的性能因素。从上面的结果已经看到,这两个操作中的多线程方法大大优于顺序方法。使用 Spring Batch 基础架构可以帮助我们非常轻松地以声明方式(例如使用 Spring 任务执行器)配置此方法。
Vijay Nair 是 Oracle FLEXCUBE Private Banking(Oracle 的金融服务全球业务部门的一部分)的一名技术架构师。他的兴趣主要围绕可伸缩计算以及如何将这些原理应用于私人银行领域的实际情况中。