 文章
数字化体验
文章
数字化体验
| |||
|




构建 Oracle WebCenter 默认搜索适配器
作者:Daniel Merchán Garcia
为 Oracle WebCenter Portal 构建 Twitter 搜索适配器的分步指导。
2013 年 11 月
下载
Oracle WebCenter
DefaultSearchAdapter.rar(示例代码)
概述
本指南通过为 WebCenter 搜索服务添加新数据源,进一步完善了 Oracle WebCenter Portal 的官方文档。本指南通过一个用该框架开发的实际示例,为构建新搜索适配器提供分步指导(图 1)。
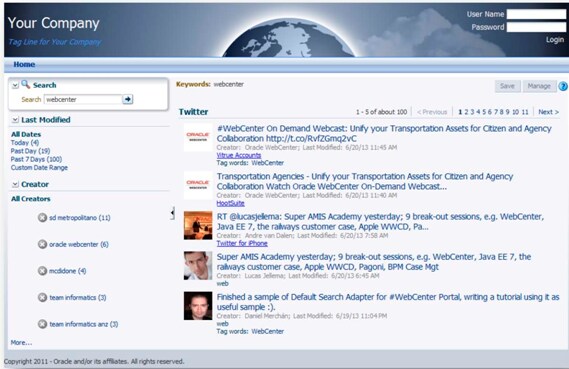
图 1:
该示例包含的默认搜索适配器具有以下功能:
- 为 tweet 资源添加新服务 oracle.webcenter.twitter,实现搜索功能
- 使用 twitter4j API 搜索 tweet
- 显示分页的工作原理
- 根据默认的 WebCenter 搜索筛选器进行筛选:
- 日期
- 创建者
- 通过两种方式显示项目的详细信息(可配置):
- 对详细信息片段页面使用资源查看器任务流
- 使用 URI 直接链接到 Twitter
构建新的搜索适配器
构建新的搜索适配器主要包括三个步骤:
- 在 WebCenter Portal 中注册一个实现搜索功能的新服务
- 实现并扩展一些 oracle.webcenter.search 类
- (可选)为项目的自定义详细信息页面创建有界任务流作为资源查看器。
注册实现搜索功能的新服务
在 service-definition.xml 配置文件中注册新服务(图 2)。
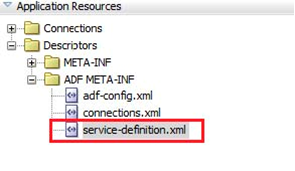
图 2:
<service-definition id="oracle.webcenter.twitter" version="11.1.1.0.0">
<resource-view taskFlowId="/WEB-INF/flows/search/twitter/twitter-viewer.xml#twitter-viewer"/>
<!-- <resource-bundle-class>com.merchan.sample.portal.search.adapter.twitter.resource.
TwitterMessageBundle</resource-bundle-class> -->
<name>Twitter</name>
<!-- <name-key>TWITTER_NAME_KEY</name-key> -->
<description>Adapter to show twitter entries in the results</description>
<!-- <description-key>TWITTER_DESCRIPTION_KEY</description-key> -->
<icon>/oracle/webcenter/portalapp/shared/twitter_logo.png</icon>
<search-definition xmlns="http://xmlns.oracle.com/webcenter/search"
id="com.merchan.sample.portal.search.adapter.twitter" version="11.1.1.0.0">
<query-manager-class>com.merchan.sample.portal.search.adapter.twitter.
TwitterQueryManager</query-manager-class>
</search-definition>
</service-definition>
service-definition 的配置:
- <service-definition>:开始标记包括服务的 ID 和版本
- id:服务 ID(例如 oracle.webcenter.doclib、oracle.webcenter.page 等)
- version:维护服务的版本控制
- <resource-view>:注册一个任务流来显示已定义服务的资源详细信息
- (可选)<resource-bundle-class>:如果我们要构建多语言服务,则需注册一个 Java 包类为 <name>、<description> 及与新服务有关的信息提供翻译
- <name> 或 <name-key>:服务名称;当提供 resource-bundle-class 时,使用 name-key 而非 name
- <description> 或 <description-key>:服务摘要
- <icon>:服务的代表图标
- <search-definition>:此标记负责将我们的新服务添加到搜索框架,包括以下配置:
- <query-manager-class>:注册 QueryManager 类,它将是自定义搜索适配器的入口点
实现
搜索框架需要实现三个接口(图 3):
- oracle.webcenter.search.QueryManager:负责初始化搜索参数的初始类。在执行搜索服务之前准备参数的初始化。
- oracle.webcenter.search.QueryExecutor:这个主类与来源集成以搜索结果。生成结果行并管理筛选器(作者和日期)和分页。
- oracle.webcenter.search.Row:封装结果列表中某个项目行的信息。
还对下面的类进行了扩展:
- oracle.webcenter.search.util.WrapperQueryResult:按搜索框架要求的格式封装结果行。
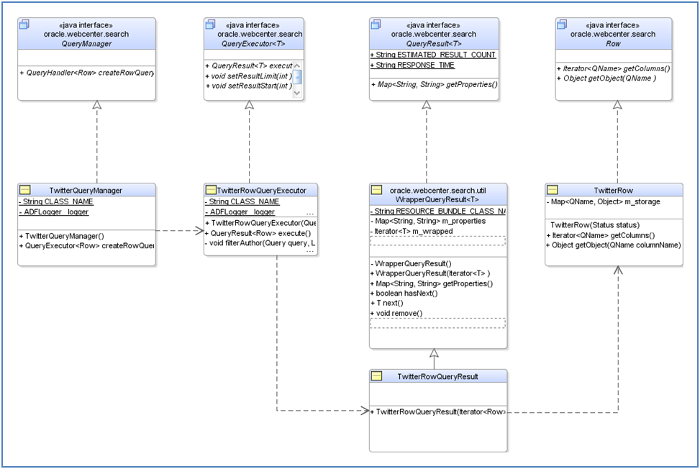
图 3:
以下步骤描述如何通过扩展和实现前面所述的框架类来创建 Twitter 类:
第 1 步:TwitterQueryManager 实现 oracle.webcenter.search.QueryManager
该类是适配器的入口点,它可用于适配器的初始化配置。
必须实现以下方法:
| 方法 | 说明 |
| createRowQueryHandler | 初始化适配器值。负责创建执行器。 |
public QueryExecutor<Row> createRowQueryHandler(Query query,
List<QName>
columns) {
final String METHOD_NAME = "createRowQueryHandler";
if (_logger.isFine()) {
_logger.fine(CLASS_NAME,METHOD_NAME,"Query: " + query.toString());
}
return new TwitterRowQueryExecutor(query, columns);
}
重要事项:用户每次单击或删除筛选器时,都会创建新的搜索,并在启动时执行此方法。
第 2 步:创建实现 oracle.webcenter.search.QueryExecutor 的类
该类负责与源 API 集成以及构建/筛选结果列表中的行。
TwitterRowQueryExecutor 由 TwitterQueryManager 创建,依赖于两个类:TwitterRow 和 TwitterQueryResult。
| 属性 | 说明 |
| m_resultStart | 保存当前分页索引。 |
| m_resultLimit | 保存每页的项目数。第一次搜索(没有筛选器)时的值为 MAX_INT。 |
| m_query | 具有当前的 oracle.webcenter.search.Query 对象。包括存储所应用筛选器的关键字和谓词,比如作者或日期。 |
| m_columns | 指定了服务要返回的列的 QName 列表。 |
| m_properties | 存储 QueryHandler 的配置,如超时或预计显示行数。 |
以下是有关类属性的详细信息:
示例:搜索任务流中每页使用 5 个项目:
| 操作 | m_resultStart | m_resultLimit |
| 第一次搜索 | 0 | MAX_INT |
| 单击 第 1 页 | 0 | 5 |
| 单击 第 2 页 | 5 | 5 |
| 单击 第 4 页 | 15 | 5 |
m_query 和 m_columns 是从 TwitterQueryManager 传递的值。
必须实现以下接口方法:
| 方法 | 说明 |
| Execute | 负责调用源 API 和构建/筛选结果行的主要方法。返回 oracle.webcenter.search.QueryResult<Row> 类型的对象。 |
| setResultStart | 当前结果开始标志的设置器。 |
| setResultLimit | 当前结果限制标志的设置器。 |
execute() 方法返回结果列表中要显示的集合。
public QueryResult<Row> execute() {
// List of resutl rows
List<Row> rows = new ArrayList<Row>();
try {
this.searchTwitterRows(rows);
} catch (TwitterException e) {
_logger.warning("Twitter Adapter not working: " + e.getMessage(),e);
}
// Create the QueryResult based on the rows to show
QueryResult<Row> ret = new
TwitterRowQueryResult(rows.iterator());
// Estimated Row Count comes from the full list searched in our
// service and stored in PageFlow
String estimatedResultCount =
PageFlowScopeUtils.get(TwitterAdapterConstants.PF_ROWS_ESTIMATED_COUNT);
ret.getProperties().put(QueryResult.ESTIMATED_RESULT_COUNT, estimatedResultCount);
return ret;
}
重要事项:调用 QueryResult.ESTIMATED_RESULT_COUNT 根据返回的行数显示分页时,请填写 m_properties 字段。它与返回的行列表大小不匹配,因为返回的行列表可以只包含当前页面的行。
要执行搜索,我们必须先知道如何构建 oracle.webcenter.search.Query 类型对象的 m_query。
示例:
只包含关键字的默认查询类似于:
查询 - 范围:空谓词:ComplexPredicate(TextPredicate(webcenter))
包含作者筛选器的查询:
查询 - 范围:空谓词:
ComplexPredicate(TextPredicate(webcenter),ComplexPredicate(AttributePredicate(http://purl.org/dc/elements/1.1/creator equals Daniel Merchan)))
包含作者和日期的查询:
查询 - 范围:空谓词:
ComplexPredicate(TextPredicate(webcenter),ComplexPredicate(AttributePredicate(http://purl.org/dc/terms/1.1/modified greater.than.or.equals 2013-06-19T00:00:00.00 +0100),AttributePredicate(http://purl.org/dc/terms/1.1/modified less.than 2013-06-20T00:00:00.00 +0100)),AttributePredicate(http://purl.org/dc/elements/1.1/creator equals Daniel Merchan))
必须实现对 Query 对象信息进行解析和检索的算法,并将其传递给源 API 以获得所需结果。
TwitterRowQueryExecutor 提供的一些辅助方法可从 oracle.webcenter.search.Query 对象检索信息,以调用和使用 twitter4j 返回所需内容。
示例:
检索指定了查询谓词的作者。
private String getAuthor(Predicate predicate) {
String author = null;
if (predicate instanceof NamedPredicate) {
QName predQName = ((NamedPredicate)predicate).getName();
if (predQName.equals(AttributeConstants.DCMI_CREATOR)) {
author = (String)((AttributePredicate)predicate).getValue();
}
} else if (predicate instanceof ComplexPredicate){
List<Predicate> predicateList =
((ComplexPredicate)predicate).getChildren();
for (Predicate pred : predicateList) {
author = this.getAuthor(pred);
}
}
return author;
}
第 3 步:创建实现 oracle.webcenter.search.Row 的类
该类表示结果列表中的一行。它具有特定的格式来填充信息(图 4)。
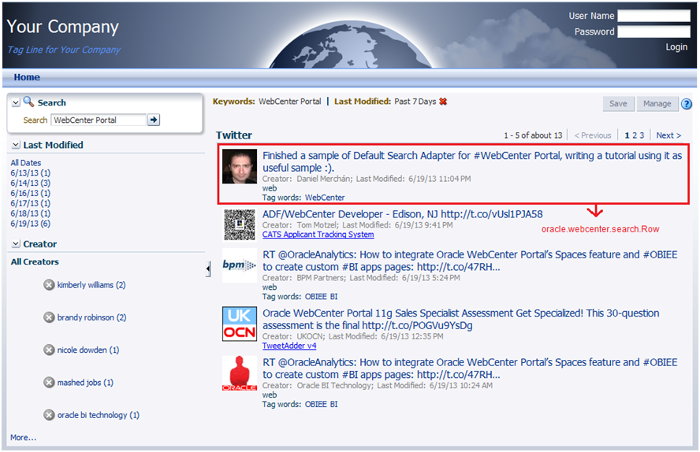
图 4:
该类的属性:
| 变量 | 值 |
| m_storage | 用于创建行响应的辅助映射,存储所有必要的 QName 列及相关值以便在结果页面打印该行。 |
TwitterRow 为 oracle.webcenter.search.Row 接口实现的方法:
| 方法 | 说明 |
| getObject | 从指定的 QName 中获取值 |
| getColumns | 获取 QName 的 Iterator 以呈现结果页面 |
m_storage 属性是填充 QName 列的映射,只需调用 keySet().iterator() 方法即可轻松检索 getColumns 和框架都需要的 Iterator。
创建行时需要填写的最重要的 QName 列包括:
| QName | 说明 |
| oracle.webcenter.search.AttributeConstants.DCMI_TITLE | 行中应该出现的标题。 |
| oracle.webcenter.search.AttributeConstants.DCMI_IDENTIFIER | 行的唯一标识符;如果单击标题时使用资源查看器打印行的详细信息,使用该列将 resourceId 参数传递给资源查看器。 |
| oracle.webcenter.search.AttributeConstants.DCMI_MODIFIED | 最近修改日期。如果不提供此列,那么 Last Modified 筛选器将不会出现在结果页面中 |
| oracle.webcenter.search.AttributeConstants.DCMI_CREATOR | 行的创建者。由筛选器使用。如果未提供,将不会出现 Creator 筛选器。 |
| oracle.webcenter.search.AttributeConstants.WPSAPI_ICON_PATH | 结果列表的行中显示的图标。 |
| oracle.webcenter.search.AttributeConstants.DCMI_URI | 行的类型。该值作为调用 resourceType 的输入参数传播到资源查看器任务流。 |
| oracle.webcenter.search.AttributeConstants.DCMI_TYPE | 行的类型。该值作为调用 resourceType 的输入参数传播到资源查看器任务流。 |
此外,还可以填充其他 QName 列来提供更多功能或信息。
| QName | 说明 |
| oracle.webcenter.search.AttributeConstants.WPSAPI_TAG_WORDS | 由空格分隔的字符串,包含标签文字。单击标签时,将执行 WebCenter 服务的标签服务。 |
| oracle.webcenter.search.AttributeConstants.DCMI_DESCRIPTION | 添加更多与行有关的信息。 |
| oracle.webcenter.search.AttributeConstants.WPSAPI_MODIFIER | 最后修改项目的用户。不能是创建者。 |
| oracle.webcenter.search.AttributeConstants.WPSAPI_ICON_PATH | 结果列表的行中显示的图标。 |
WebCenter Portal API 中的 oracle.webcenter.search.AttributeConstants 类提供了更多属性。
示例:
图 5 说明了部分 QName 列值与搜索任务流结果页面的对应方式。
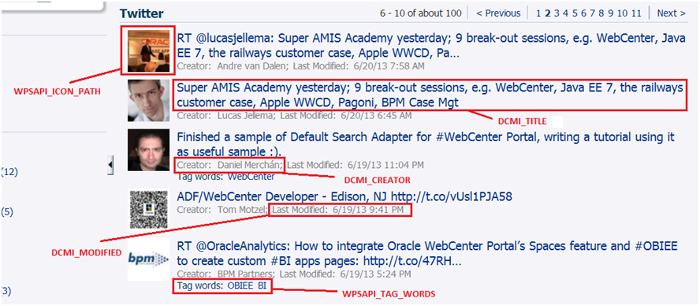
图 5:
第 4 步:创建扩展 oracle.webcenter.search.WrapperQueryResult 的类
表示要在结果页面中显示的 oracle.webcenter.search.Row 的集合。
TwitterQueryResult 只能存储 TwitterQueryExecutor 中生成的一个 Iterator<Row>。
public final class TwitterRowQueryResult extends WrapperQueryResult<Row> {
public TwitterRowQueryResult(Iterator<Row> rows) {
super(rows);
}
}
项目详细信息
可以用两种方法在结果列表中显示项目详细信息:
- 使用详细信息链接打开一个外部 URI。
- 在已注册为资源查看器的自定义有界任务流中打开详细信息。
外部 URI
通过填充行的 oracle.webcenter.search.AttributeConstants.DCMI_URI,使用外部页面打开项目的详细信息。
单击结果标题将打开提供的外部 URI(图 6)。
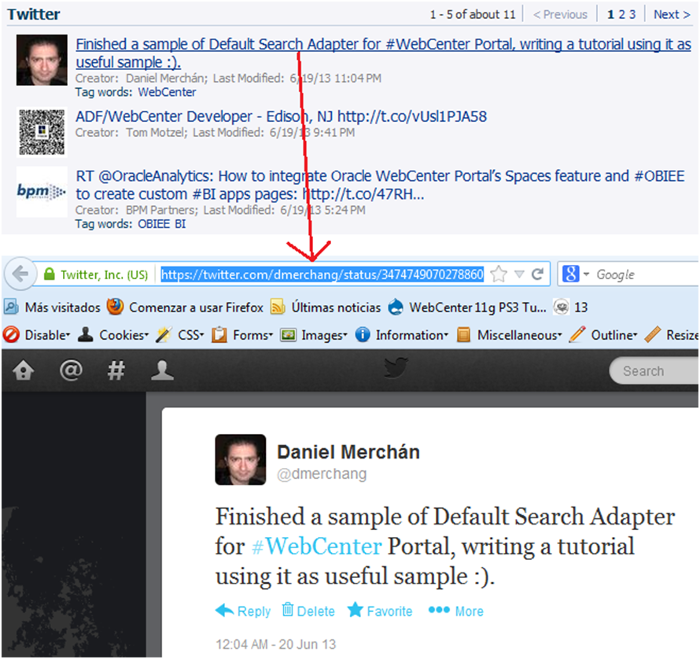
图 6:
在资源查看器任务流中
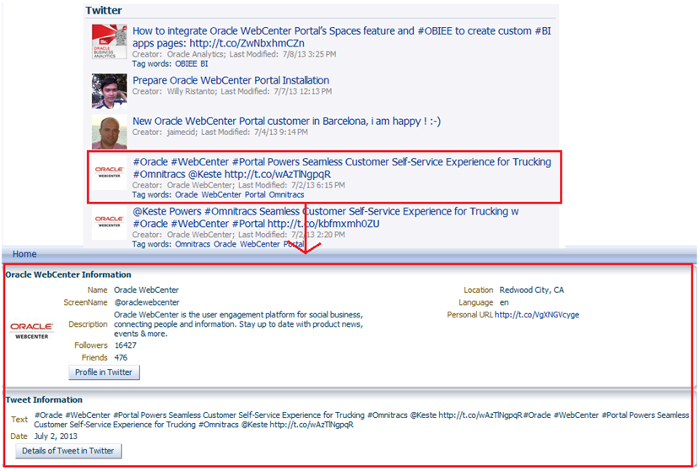
图 7:
要使用资源查看器任务流显示详细信息,请按如下配置:
- 不提供 oracle.webcenter.search.AttributeConstants.DCIM_URI QName 列值。
- 在 service-definition.xml 配置文件中为指向任务流的服务注册一个资源查看器(图 8)。

图 8:
资源查看器任务流应具有下述配置(图 9):
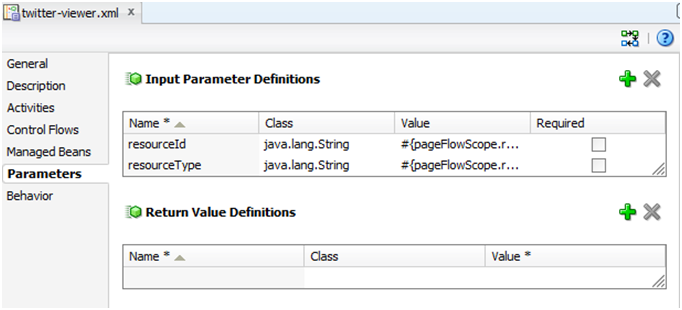
图 9:
- 必要的输入参数:
- resourceId:检索待显示资源的 ID,对 Twitter 适配器来说,是 Tweet ID。
- resourceType:检索内容的类型。此外,还可用来传递有助于检索资源详细信息的更多信息。
- 可选的输入参数:
- resourceTitle:与资源关联的标题。
- resourceScope:指示资源是与特定空间关联,还是与一般空间关联。
这些输入参数来自何处?
单击服务中某个项目的详细信息时,WebCenter 的默认 ResourceHandler 将负责传递这些参数。
例如,对于文档服务,当 Twitter 查看器收到博文 ID 时,文档资源查看器通过内容的 resourceId 接收 dDocName。
一旦注册了资源查看器任务流并为 jazn-data.xml 中的角色分配了正确的权限,那么当用户单击某个项目时,任务流将打开。
配置搜索任务流
使用搜索功能配置新服务后,应通过添加新服务 ID 来配置搜索任务流(图 10)。
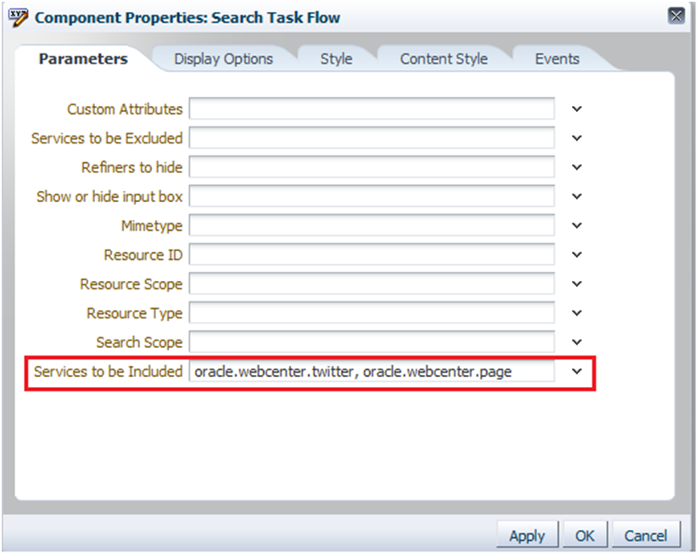
图 10:
常见问题和技巧
adf-config 文件中没有 Oracle WebCenter Framework 信息
单击项目时,日志文件中出现以下堆栈跟踪:
<ResourceActionUtils> <getHandlerClass> No Oracle WebCenter Framework information in adf-config file.
要修复这个问题,请只在 adf-config.xml 中注册处理程序。您可以选择:
- PopUpResourceActionViewHandler — 单击搜索结果时,在弹出窗口中显示资源。
- NavigationResourceActionHandler — 单击搜索结果时,在资源的导航节点中显示资源。
adf-config.xml 配置示例:
<wpsC:adf-service-config xmlns="http://xmlns.oracle.com/webcenter/framework/service">
<resource-handler class="oracle.webcenter.portalframework.sitestructure.handler.
NavigationResourceActionHandler"/>
</wpsC:adf-service-config>
在 ADF JAR 库中创建可重用的适配器
在真实项目中新建默认活动适配器时,最佳做法是创建可重用的 ADF JAR 库,而不是直接在 Portal Framework 应用程序内工作。然后可将它们作为共享库部署在 Portal 和 Spaces 中。
必须在项目中手动创建 service-definitions.xml 等必要文件。
运行示例
示例 (DefaultSearchAdapter.rar) 是用 Oracle JDeveloper 11.1.1.6(PS5 版 Oracle WebCenter Portal)和 twitter4j(作为 Twitter 搜索 API)实现的。
必须使用 Twitter OAuth 密钥配置 twitter4j.properties 文件(图 11)。
图 11:
从这里获取钥匙(图 12): https://dev.twitter.com/docs/auth/obtaining-access-tokens
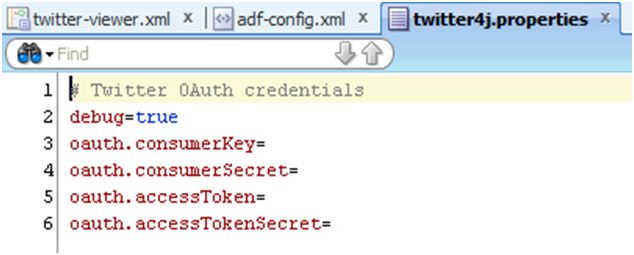
图 12:
参考资料
关于作者
Daniel Merchán Garcia 是位于英国伦敦的 Vass 的 Oracle WebCenter Portal/Content 解决方案架构师。
![]()
![]()
![]()