 文章
身份和安全性
文章
身份和安全性
| |||
|




Oracle Identity Manager 11gR2 目录:域索引优秀实践和常见问题解答
作者:Lokesh Gupta
针对使用 Oracle Identity Management (OIM) 的访问请求目录特性实现基于域的索引的优化和优秀实践。
2014 年 5 月
目标
本文介绍 Oracle Identity Management (OIM) 中广泛使用的访问请求目录特性,包括编制目录时使用的基于域的索引所需的优化和常见问题解答。该特性基于关系数据库管理系统 (RDBMS) 组件 Oracle Text。
OIM 访问请求目录
访问请求目录是可搜索的分类实体集合,这些实体在 OIM 中可通过请求调用。任何通过身份验证的用户均可使用一个或多个关键字和搜索运算符搜索目录、向购物车添加目录项,以及为自己和他人提交请求。
访问请求目录特性的关键要素:
- 可扩展的目录模式,允许管理员使用简单的基于浏览器的 UI 添加属性并指定其呈现方式
- 自动采集角色、应用和授权
- 使用 CSV 文件自动加载目录元数据
- 强大的关键字搜索,支持复杂的搜索运算符
- 灵活的分类模型,允许根据客户选择组织目录
- 根据请求方的查看者权限保护目录搜索结果
- 可通过 Web 服务将目录项数据用于工作流
Oracle Text
Oracle Text(以前称为 interMedia Text 和 ConText)基于 RDBMS Oracle Text 组件,它是一种广泛应用的全文本索引技术,可让您高效地查询免费文本并生成文档分类应用。它提供文本的索引编制、关键字和主题搜索以及查看功能。
Oracle Text 有多种适合基于域的索引的选项:- ConText
- CatSearch
- CtxRule
其中,只有 ConText 在 OIM 的 Oracle Text 范围内。
Oracle ConText
CONTEXT 索引类型用于索引大量文本,如 Word、PDF、XML、HTML 或纯文本文档。在以下示例中,我们将数据存储在二进制大对象 (BLOB) 列中,这样我们就能存储 Word 和 PDF 以及纯文本等二进制文档。如果只使用纯文本文档,则首选字符大对象 (CLOB)。
目录优秀实践
访问请求目录使用 Oracle 数据库的“Oracle Text”选件执行文本搜索功能。
包含目录项的 Catalog 表使用 Oracle Text 的 Context 索引类型编制索引。虽然 Oracle Text 索引运行起来与常规数据库索引类似,但其背后的架构和处理凸显了优秀实践在创建 Text 索引和执行持续维护时的重要性。
重要指南
- 安装 Oracle RDBMS 时请选择 Oracle Text。对于 OIM 11g R2 及更高版本,必须使用 Oracle Text。如果升级客户的数据库上未安装 Oracle Text,则必须自行手动安装。
- 请参照 Metalink 文档 ID 970473.1 手动安装 Oracle Text。您必须验证是否已正确安装 Oracle Text,且 CTXSYS 中无 INVALID 对象。
- 客户不得分析令牌表 (DR$),但可以分析文本索引。
OIM 支持的搜索运算符
使用 Catalog 域指定一个关键字(区分大小写)来搜索或浏览请求目录。支持的搜索运算符如下所示:
一个或多个关键字(示例值:
administrator)该搜索条件将找出所有包含“administrator”一词的目录项。
多个关键字的示例值:
web administrator该搜索条件将找出所有包含“web”和“administrator”二词的目录项。因为关键字之间的空格字符相当于 AND 运算符,此搜索将自动对搜索关键字应用 AND 运算符。您也可以使用 & 运算符显式表示 AND 关系。
例如,web administrator和web & administrator将返回同时包含 web 和 administrator 的目录项。短语:要搜索包含所输入确切短语的目录项,必须在双引号 (") 内指定搜索条件。例如,搜索“web administrator”将返回包含短语“web administrator”的目录项。
OR [|] 搜索:使用 OR [|] 运算符搜索包含任一搜索关键字的目录项。
示例值 1:
web | administrator该搜索条件将返回包含“web”或“administrator”一词的目录项。
示例值 2:
"vision purchasing" | administrator该搜索条件将返回包含短语“vision purchasing”或“administrator”一词的目录项。
通配符搜索:您可以使用星号 (*) 作为通配符执行搜索操作。但目录搜索不支持以星号 (*) 开头的搜索条件。仅用 * 搜索将根据角色、授权、应用实例中选择的选项或全部而返回所有项。
例如,
admin*将返回以 admin 开头的目录项目,如 administrator 和 administration。
针对 OIM Oracle Text 索引的一次性优化
安装 OIM 时,将针对访问请求目录创建 Text 索引,并可能有优化。但根据部署的特性,Oracle Text 可以应用其他更好的优化。为了提升访问请求目录的搜索性能,您应考虑应用以下优化。
应用这些优化时将无法使用访问请求目录,因此优化应在计划内维护窗口期间执行。注:应用这些一次性优化时,应关闭目录同步作业和访问请求目录。
Text 索引存储
Oracle Text 索引数据存储在关系表 (DR$) 中,该表目前位于 OIM 模式的默认表空间中。您应使用以下命令将其单独分离到它们自己的专用表空间。下面是用于说明的步骤。
登录到 SYS 模式,创建一个新的表空间来保存 Text 索引内部表。您可以使用以下示例命令执行此操作;将 DATA_DIR 替换为您希望存储数据文件的目录并根据环境的需要调整大小和其他参数。
CREATE TABLESPACE catalog_text_ind_tables DATAFILE 'DATA_DIR/catalog_text_ind_tables_01.dbf' SIZE 2048M REUSE EXTENT MANAGEMENT LOCAL SEGMENT SPACE MANAGEMENT AUTO;
- 使用 OIM 模式连接数据库。
使用以下命令创建存储首选项。Oracle 建议您熟悉 Oracle Text 的 BASIC_STORAGE 子句,并根据需要添加其他存储子句。您可以在 Oracle Text 参考文档中找到有关 BASIC_STORAGE 的更多信息。
Begin Ctx_Ddl.Create_Preference('cat_storage', 'BASIC_STORAGE'); End; / Begin ctx_ddl.set_attribute('cat_storage','I_TABLE_CLAUSE','tablespace catalog_text_ind_tables storage (initial 5M next 5M)'); End; / Begin ctx_ddl.set_attribute('cat_storage', 'K_TABLE_CLAUSE','tablespace catalog_text_ind_tables storage (initial 5M next 5M)'); End; / Begin ctx_ddl.set_attribute('cat_storage', 'R_TABLE_CLAUSE','tablespace catalog_text_ind_tables storage (initial 1M) lob (data) store as (cache)'); End; / Begin ctx_ddl.set_attribute('cat_storage', 'N_TABLE_CLAUSE','tablespace catalog_text_ind_tables storage (initial 1M)'); End; / Begin ctx_ddl.set_attribute('cat_storage', 'I_INDEX_CLAUSE','tablespace catalog_text_ind_tables storage (initial 1M) compress 2'); End; /使用以下命令应用新的存储首选项。确保 Text 索引在此步骤之后的状态为 VALID。
ALTER INDEX CAT_TAGS rebuild parameters ('replace storage cat_storage');通过查询 USER_SEGMENTS 表验证以上各表已移至新的表空间。
Text 索引的 KEEP 池设置
建议您将组成 Text 索引的所有表放入数据库 KEEP 池,以提升访问请求目录搜索的性能。您必须正确调整 KEEP 池的大小 (DB_KEEP_CACHE_SIZE),以便 KEEP 池能够容纳这些 Text 索引表及其他 OIM 对象。
使用 OIM 模式连接数据库。
使用以下查询计算 Text 索引的大小,并使用它相应地设置/调整 DB_KEEP_CACHE_SIZE。
SELECT ctx_report.index_size('CAT_TAGS') FROM dual;以 OIM 模式用户身份运行以下命令,将表放入 KEEP 池。
ALTER INDEX DR$CAT_TAGS$X STORAGE (buffer_pool keep); ALTER TABLE DR$CAT_TAGS$R STORAGE (buffer_pool keep); ALTER TABLE DR$CAT_TAGS$R STORAGE (buffer_pool keep) MODIFY lob (data) (STORAGE (buffer_pool keep)); ALTER TABLE DR$CAT_TAGS$K STORAGE (buffer_pool keep); ALTER TABLE DR$CAT_TAGS$I STORAGE (buffer_pool keep);
OIM 中 Oracle Text 索引的持续维护
Text 索引优化
Text 索引可能会因持续的“目录同步”而碎片化。定期优化 Text 索引可删除旧数据,尽可能减少碎片,并可以提升访问请求目录的搜索性能。
为此,OIM 引入了以下 Oracle Database 计划程序作业:
- FAST_OPTIMIZE_CAT_TAGS
- REBUILD_OPTIMIZE_CAT_TAGS
这些作业驻留在 OIM 数据库模式中,默认情况下是禁用的。Oracle 强烈建议您查看这些作业,如果需要,还可以更改计划并启用它们。更改计划时,确保在默认计划所在行设置新计划。
FAST_OPTIMIZE_CAT_TAGS 意指频繁运行,默认情况下,它定于每天凌晨 1 点运行一次。
REBUILD_OPTIMIZE_CAT_TAGS 执行全面优化并重新构建 Text 索引,并不意味着频繁运行。默认情况下,它定于每周日凌晨 2 点运行。如果您的 Text 索引很大,优化可能需要较长时间。
下面介绍如何更改计划和/或启用这些作业:
确保默认计划(FAST 为每天凌晨 1 点,REBUILD 为每周日凌晨 2 点)适合您的环境。否则,请更改计划。(如果无法确定,则保留默认计划,并在必要时进行更改。)
使用以下命令启用作业:
BEGIN DBMS_SCHEDULER.ENABLE ('FAST_OPTIMIZE_CAT_TAGS'); END; / BEGIN DBMS_SCHEDULER.run_job ('REBUILD_OPTIMIZE_CAT_TAGS'); END; /
注:在服务器运行时和搜索访问请求目录时,可执行 Text 索引优化。
收集 OIM 的模式统计信息
按照 FMW 调优指南中提到的实现最佳 SQL 性能的准则收集 OIM 模式统计信息。
DB 模式统计信息收集示例命令:
Exec dbms_stats.gather_schema_stats(OWNNAME=> '<OIM_SCHEMA>',ESTIMATE_PERCENT=>DBMS_STATS.AUTO_SAMPLE_SIZE, options=>'GATHER AUTO',degree => 8,cascade=>TRUE);
OIM 目录常见问题解答
问题 1:排除 Oracle Text 错误
该视图显示当前用户的索引错误,所有用户均可查询。
ctx_user_index_errors 视图将显示源表中失败行的 rowid。使用此 rowid 更新源表中失败的行。具体来说,对保存 Text 索引的列执行虚拟更新(即,update table x set columnx = columnx where rowid = ?)。这将在 ctx_user_pending 视图中生成一行。然后执行 ctx_ddl.sync_index,这将对 ctx_user_pending 视图中的行进行索引。
可以用 CTX_PENDING 和 CTX_USER_PENDING 视图查询待处理的 DML 请求。
可以用 CTX_INDEX_ERRORS 或 CTX_USER_INDEX_ERRORS 视图查询 DML 错误。
SELECT err_timestamp, err_text FROM ctx_user_index_errors ORDER BY err_timestamp
DESC;
SELECT pnd_index_name, pnd_rowid, to_char( pnd_timestamp, 'dd-mon-yyyy hh24:mi:ss'
) timestamp FROM ctx_user_pending;
问题 2:重新创建 OIM 目录的 Text 索引
检查并记录 OIM 索引 CAT_TAGS 的当前状态。
对 OIM 模式运行此 SQL:
SELECT INDEX_NAME,TABLE_NAME,STATUS, PARAMETERS, DOMIDX_STATUS,DOMIDX_OPSTATUS FROM USER_INDEXES WHERE INDEX_TYPE='DOMAIN';
按原定顺序运行以下 PL/SQL 块,删除并重新创建 Text 索引 CAT_TAGS。再次对 OIM 模式运行这些块。
删除 Text 索引重新创建 Text 索引DECLARE P_DROPINDEX NUMBER; P_CREATEINDEX NUMBER; STRERRMESSAGE_OUT VARCHAR2(200); BEGIN P_DROPINDEX := 1; P_CREATEINDEX := 0; OIM_PKG_CATALOG_INDEX.OIM_SP_CREATEDROPCATALOGINDEX( P_DROPINDEX => P_DROPINDEX, P_CREATEINDEX => P_CREATEINDEX, STRERRMESSAGE_OUT => STRERRMESSAGE_OUT ); DBMS_OUTPUT.PUT_LINE('STRERRMESSAGE_OUT = ' || STRERRMESSAGE_OUT); END; /DECLARE P_DROPINDEX NUMBER; P_CREATEINDEX NUMBER; STRERRMESSAGE_OUT VARCHAR2(200); BEGIN P_DROPINDEX := 0; P_CREATEINDEX := 1; OIM_PKG_CATALOG_INDEX.OIM_SP_CREATEDROPCATALOGINDEX( P_DROPINDEX => P_DROPINDEX, P_CREATEINDEX => P_CREATEINDEX, STRERRMESSAGE_OUT => STRERRMESSAGE_OUT ); DBMS_OUTPUT.PUT_LINE('STRERRMESSAGE_OUT = ' || STRERRMESSAGE_OUT); END; /重新运行第 1 步的 SQL。您将看到以下输出:
CAT_TAGS CATALOG VALID sync (on commit) lexer CATALOG_PREFERENCE VALID VALID
问题 3:对带“_”(下划线)字符的授权进行的目录搜索显示不正确
对带下划线项的目录搜索返回错误结果。
- 创建几个可请求项,名称如 A_Req01、A_Req02、B_Req01、C_Req01。
- 目录同步完成后,搜索目录中的 A_Req*。
- 结果:预期结果应为:A_Req01 和 A_Req02,但却返回上述所有项目。
原因:之所以出现这种情况,是因为在 Oracle Text 中,A、D、I、S 和 T 是非索引字(用于目录搜索)。非索引字不被索引。
这意味着,“A_Role1”解释为“A 后面跟着 Role1”,由于 A 是非索引字,这会转换成只有“Role1”,这将与所有“<something>_Role1”匹配。如果搜索“B_Role1”,这将解释为“B 后面跟着 Role1”,由于 B 不是非索引字,这将视为短语搜索,不会与任何其他字符串匹配。
解决方案
从默认的非索引字列表中删除以下字符/单词:
a、d、i、s、t、II、non、one
为此,可在使用 CTXSYS 用户登录 DB 之后执行以下命令:
begin ctx_ddl.remove_stopword('DEFAULT_STOPLIST','a'); ctx_ddl.remove_stopword('DEFAULT_STOPLIST','d'); ctx_ddl.remove_stopword('DEFAULT_STOPLIST','i'); ctx_ddl.remove_stopword('DEFAULT_STOPLIST','s'); ctx_ddl.remove_stopword('DEFAULT_STOPLIST','t'); ctx_ddl.remove_stopword('DEFAULT_STOPLIST','II'); ctx_ddl.remove_stopword('DEFAULT_STOPLIST','non'); ctx_ddl.remove_stopword('DEFAULT_STOPLIST','one'); end; /以下查询确认是否已经删除这些单词。您可以在运行删除命令之前运行同样的查询,看看这些单词是否还在。
select * from ctx_stopwords where spw_word in (<all of the above words>)
运行
OIM_PKG_CATALOG_INDEX.OIM_SP_CreateDropCatalogIndex删除 CATALOG 表 TAGS 列上的 Text 索引。传递 1 作为
P_DROPINDEX参数值。运行
OIM_PKG_CATALOG_INDEX.OIM_SP_CreateDropCatalogIndex在 CATALOG 表 TAGS 列上创建 Text 索引。传递 1 作为
P_CREATEINDEX参数值。
问题 4:通配符搜索出现大量数据匹配错误输出
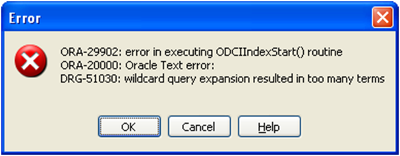
原因
这是 interMedia (Oracle Text) 中的默认功能。我们无法在搜索字符串中使用通配符(如 % 或 *)。Oracle Text 自行将此关联为通配符并尝试返回所有结果,就像是只使用 % 搜索一样。这导致 Oracle Text 出错。
在 11g 中,一个通配符可以匹配且不出错的最大不同令牌(不是行)数为 50000。
解决方案
如果决定返回超过 20000 个不同的令牌(在 11g 中)或超过 5000 个不同的令牌(在 10gr2 中),可以使用单词表的
wildcard_maxterms属性。wildcard_maxterms
以通配符 (%) 扩展形式指定最大查询词数。使用此参数将通配符查询性能保持在一个可接受的限制之内。当通配符查询扩展超过此数量时,Oracle 将返回错误。
要实现该解决方案,请执行以下步骤:
以 Portal 模式登录 SQL*Plus,执行以下语句:
begin ctx_ddl.create_preference('<Pref_name>','BASIC_WORDLIST'); ctx_ddl.set_attribute('<Pref_name>','WILDCARD_MAXTERMS', 50000); end; / alter index WWSBR_THING_CTX_INDX rebuild parameters ('replace metadata wordlist WWSBR_WDL');重复搜索。
在此,如果数据库版本低于 10.2.0.3,则最大数量为 15000;如果数据库版本是 10.2.0.3 或更高版本,则为 50000。
该数可设置在 5000(默认值)和 15000/50000 之间,根据数据库版本的不同,可设置为其间任何一个能够实现成功搜索的数量。但,此值设得越高,所需内存越大。
问题 5:如何处理分隔/转义字符
可以使用反斜杠“\”字符将具有特殊意义的字符转义为普通文本。
解决方案
Sql> BEGIN CTX_DDL.CREATE_PREFERENCE ('my_lexer', 'BASIC_LEXER'); CTX_DDL.SET_ATTRIBUTE ('my_lexer', 'PRINTJOINS', '~!@$%^&*()-_=+|;:,"./'); OR CTX_DDL.SET_ATTRIBUTE ('my_lexer', 'SKIPJOINS', '`-=[];''\,./~!@#$%^&*()_+{}:"|?§'"???¤Φ£€???'); END; /问题 6:如何收集 Oracle Text 索引的其他数据
解决方案
select CTX_REPORT.CREATE_INDEX_SCRIPT('CAT_TAGS') from dual; select CTX_REPORT.DESCRIBE_INDEX('CAT_TAGS') from dual;关于作者
Lokesh Gupta 是 Oracle Identity Manager 的 Oracle 服务器技术组的项目主管,专攻数据库、企业性能和选型设计以及安全相关问题。

