 文章
企业管理
文章
企业管理
AWR Warehouse 的高级用法
简介
将所有 AWR 数据纳入一个信息库(通过 Oracle Enterprise Manager 12c 触手可及)的想法非常诱人,但提供直接查询(我的许多伙伴就是这样,他们一有 AWR 报告或 ADDM 比较无法回答的业务问题,就会直接查询)的选项也不可忽视。我毫不怀疑他们会对 AWR Warehouse (AWRW) 信息库的简单优雅背后的数据和设计印象深刻。
我曾有机会使用过 Oracle EM12c AWR Warehouse 界面,也通过 SQL*Plus 使用过信息库。我也曾深入了解 AWR Warehouse 信息库有什么选项和性能优势,还一有机会就唱反调。我很乐意谈谈集中的 AWR Warehouse 为 IT 业务提供的所有令人印象深刻的特性。
设计和功能
建立 AWR Warehouse 的目标与您熟悉的任何 Oracle 数据库的标准 AWR 模式并无二致。主要增强了分区(按 DBID、SNAP_ID 或二者的组合),允许快速加载、高效查询以及根据请求有效地清除不需要的数据。
从源目标提取数据以及将数据加载到 AWR 信息库的作业都设计有“限制”,以确保执行历史加载时,不会感觉到对用户性能有影响。
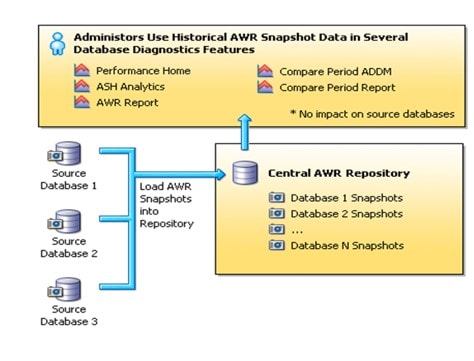
图 1.1 AWR Warehouse 架构和 ETL 加载过程。
如果数据库由于某种原因(如维护或其他中断)不能用于上传到 AWR Warehouse,增加的“限制”可确保 ETL 负载不会过大,且始终首先加载最旧的数据,以确保保留时间不会妨碍将重要 AWR 数据分流到信息库的功能。
在“赶工”期,ETL 作业每三小时运行一次,而不是标准时间间隔的每 24 小时一次。文件通过“代理到代理”推送从源目标文件系统传输到 AWR Warehouse 服务器。这限制了网络上的压力,并使其没有机会触及 EM12c Oracle 管理服务 (OMS) 和/或 Oracle 管理信息库 (OMR) 服务器。
要求
AWR Warehouse 信息库应为 11.2.0.4 数据库或更高版本,对于调优和诊断软件包,随附提供了一个可用于 AWR Warehouse 信息库的有限 EE 许可。不要尝试将 EM12c 信息库 (OMR) 用于本信息库。考虑到将此在容纳的数据量以及使用类型,这两种信息库的使用将长期高度不兼容。另外还有补丁和其他要求,请参见 MOS 说明 1907335.1 了解完整列表和详细的安装步骤。有关一般介绍和安装说明,请参见此处的 Oracle 文档集“AWS Warehouse”部分。
下面将介绍更重要的内容,例如如何直接查询 AWRW!
映射为什么重要
如果您要“按原样”接受 AWR 查询并在 AWR Warehouse 中运行,几乎可以保证结果不准确。为了证明这一点,我们用一个具体的 AQL_ID:“d17f7tgcaa416”来说明原因。
在以下查询中,以 SQL_ID ‘d17f7tqcaa416’ 为例,您很快会认识到用于创建 SQL_ID 的算法不是数据库独有的,而是由 Oracle 软件分配的,无论在哪个数据库中运行,都会分配给该查询。如果您是要解决从生产到测试到开发的性能问题,或者报告在何处为特定的语句统一生成唯一的标识符是有价值的,这很容易被视为一个特性。
因此,任何修改后针对 AWR Warehouse 运行的 AWR 查询必须添加一个映射 DBID 的 join 操作,以便将结果限制于所涉及的源目标。
为了映射此数据,接下来我们将检查 AWR Warehouse DBSNMP 模式以及对 AWR Warehouse 中的信息库非常重要的表:
此表设计虽然简单,但很有效,用于将数据映射为 ETL 负载的一部分,EM12c 将使用此表通过与 AWR Warehouse 相对的用户界面提供报表,并且也可以由任何希望高效查询 AWR Warehouse 的用户使用。
现在,我们可以轻松地将此表添加到查询,根据 NEW_DBID 执行 join 操作(如果您重命名 DBID,就会理解 OLD_DBID 为什么对有些历史查询这么重要……),并将 TARGET_NAME 添加到 where 子句。
查询 AWR Warehouse
要更新查询,首先使用一个简单查询检查有关特定 SQL_ID 及每次执行计划的 CPU 使用情况的信息。
进行几个简单更改,现在可以看到 db305 数据库中 SQL_ID d17f7tqcaa416 的计划值发生更改。
然后可以据此构建,并添加另一个数据库进行比较:
我们已经演示了一个简单联接如何为跨多个数据库的同一查询提供性能数据。
下一个查询将获取更多信息,但仍然只要求请求一个 DBNAME(也可以请求两个,如果您希望比较或查看多个数据库,如上一个查询中的那样……),然后根据 DBID 执行到 NEW_DBID 的 join 操作。
现在可以查询计划、IO 信息等方面的不同,并比较 2010 年 6 月与 2014 年 6 月的中期执行。我们可以使用此信息回答非常具体的业务问题、性能变化或提供执行计划以供比较,因为所有 DBA_HIST_XX 数据均在 AWR Warehouse 中。从源数据库获得所有这些数据之后,现在将其分流到可用的 AWR Warehouse,即可对该数据库的所有历史记录执行全面分析。与先前驻留在生产环境中并可能影响生产使用(如果对源数据库执行高级分析)的 AWR 信息库相比,AWR Warehouse 旨在提供高级报告。
跨一台主机上的多个数据库
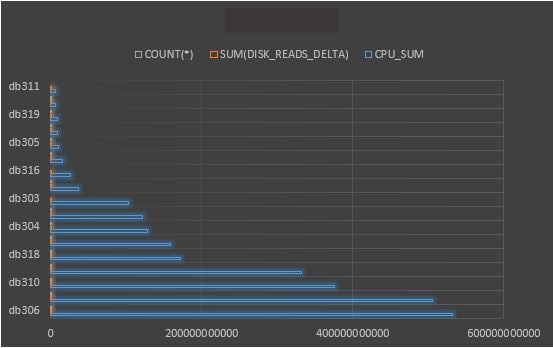
如前面的查询所示,现在我们将演示跨多个数据库的结果,但重点是关注整个主机和/或集成系统的值。
上面显示的是最近 120 天此主机上所有数据库的 CPU 使用情况、磁盘读取和执行次数的高级视图。我们还可以用这些数据创建一个图表,提供此数据的可视化视图,以便企业了解各数据库间的需求:
还有什么是 AWR Warehouse 做不到的吗?
如以上示例所示,极少有 AWR Warehouse 信息库无法识别的性能问题。无限保留和高级仓库特性在回答有关企业数据库领域的所有信息技术问题方面,只要用户想不得到,没有它们回答不了的。
使用这种宝贵数据的增强方式和新方式层出不穷,越来越多人将在未来一年内接纳 AWR Warehouse。构建数据库,安装 AWR Warehouse,开始使用 — 前景无限。
----
关于作者
Kellyn Pot'Vin 是 Oak Table 成员和战略客户计划(Oracle Enterprise Manager 专家的一个专业小组)的咨询人员。她专攻环境优化调优、自动化和创建强健的企业级系统。Kellyn 的工作几乎全是多 TB 数据库(包括 Exadata 和固态磁盘解决方案)工作,并以 Oracle Enterprise Manager 12c 及其命令行界面的大量工作而闻名。她与人合著了一些技术书籍,并主持 ODTUG、OTN 和 All Things Oracle Web 研讨会,还在甲骨文全球大会、HotSos、Collaborate、KSCOPE 及其他许多美国和欧洲会议上做过演讲。Kellyn 积极倡导科技女性 (WIT),例如其关于模式化的主题教育以及将及早提供机会视为克服挑战的途径。通过 Twitter @DBAKevlar 及其在 http://dbakevlar.com 上的博客关注她。