 文章
服务器与存储管理
文章
服务器与存储管理
多租户云环境中的性能分析
作者:Orgad Kimchi

分析虚拟化多租户云环境的性能可能因为抽象层而充满挑战。本文介绍如何使用 Oracle Solaris 11 克服这些限制。
2013 年 12 月发布
|
准备
监视虚拟化环境中的 CPU 负载
监视虚拟化环境中的磁盘 I/O 活动
监视虚拟化环境中的内存利用率
监视虚拟化环境中的网络利用率
清理任务
总结
另请参见
关于作者
注:本文中的信息适用于 Oracle Solaris 11 和 Oracle Solaris 11.1。
Oracle Solaris 11 附带的一组新命令让您能够在虚拟化多租户云环境中执行性能分析。出于以下原因,在不同用户运行多个负载的情况下,虚拟化多租户云环境中的性能分析可以是一项充满挑战的任务:
- 每种类型的虚拟化软件都增加了一个抽象层,以便更好地管理。虽然这简化了虚拟化资源的管理,但很难找到过载的物理系统资源。
- 每个 Oracle Solaris 区域都可能有不同的负载;可能是磁盘 I/O、网络 I/O、CPU、内存,也可能是它们的组合。而且,单个 Oracle Solaris 区域也可能导致所有系统资源过载。
- 观察环境很困难;您需要能够从顶层监视环境,实时查看所有虚拟实例(非全局区域),并且能够下钻到特定资源。
以下是使用 Oracle Solaris 11 进行虚拟化性能分析的好处:
- 可观察性。Oracle Solaris 全局区域是一个功能齐全的操作系统,而不是无法同时观察整体环境(包括主机和 VM)的虚拟机管理程序或精简操作系统。全局区域能够查看所有非全局区域的性能指标。
- 集成。所有子系统都构建在相同的操作系统内。例如,ZFS 文件系统与 Oracle Solaris 区域虚拟化技术集成在一起。虽然这有利于混用多个供应商的技术,但不同操作系统 (OS) 子系统之间无法集成,并且很难同时分析所有不同的 OS 子系统。
- 虚拟化感知。Oracle Solaris 内置的命令能够感知虚拟化,可以提供整个系统(Oracle Solaris 全局区域)的性能统计数据。除了能够下钻到每个资源(Oracle Solaris 非全局区域),这些命令还能在性能分析过程中提供准确的结果。
在本文中,我们将通过四个示例介绍如何使用 Oracle Solaris 11 内置的工具监视包含 Oracle Solaris 区域的虚拟化环境。这些工具能够下钻到特定资源,例如 CPU、内存、磁盘和网络。此外,它们还能够打印每个 Oracle Solaris 区域的统计数据,并提供有关正在运行的应用程序的信息。
在这些示例中,我们将使用涉及 CPU、磁盘和网络负载的 Hadoop MapReduce 基准测试。根据“如何使用 Oracle Solaris 区域搭建 Hadoop 集群”所述搭建 Hadoop 集群。在这些示例中,将使用 Oracle Solaris 区域、ZFS 和网络虚拟化技术安装所有 Hadoop 集群构建块。图 1 显示了架构:

图 1. 架构
准备
首先,使用 zoneadm 命令检查环境:
root@global_zone:~# zoneadm list -civ ID NAME STATUS PATH BRAND IP 0 global running / solaris shared 19 sec-name-node running /zones/sec-name-node solaris excl 23 data-node1 running /zones/data-node1 solaris excl 24 data-node3 running /zones/data-node3 solaris excl 25 data-node2 running /zones/data-node2 solaris excl 26 name-node running /zones/name-node solaris excl
可以看到,我们的环境中包含五个 Oracle Solaris 区域:
name-nodesec-name-nodedata-node1data-node2data-node3
为了利用 Oracle Solaris 的多线程感知提高系统利用率,我们通过给 mapred-site.xml 添加以下属性来为每个 Hadoop 区域启用 25 个作业槽:
<property>
<name>mapred.tasktracker.map.tasks.maximum</name>
<value>25</value>
</property>
<property>
<name>mapred.tasktracker.reduce.tasks.maximum</name>
<value>25</value>
</property>
开始基准测试之前,我们先验证 Hadoop 集群的运行状况:
root@global_zone:~# zlogin -l hadoop name-node hadoop dfsadmin -report Oracle Corporation SunOS 5.11 11.1 December 2012 Configured Capacity: 1445236931072 (1.31 TB) Present Capacity: 1443007083849 (1.31 TB) DFS Remaining: 1440410395136 (1.31 TB) DFS Used: 2596688713 (2.42 GB) DFS Used%: 0.18% Under replicated blocks: 137 Blocks with corrupt replicas: 0 Missing blocks: 0 ------------------------------------------------- Datanodes available: 3 (3 total, 0 dead)
我们将看到三个可用的 DataNode。
注:DataNode 是将数据存储到 Hadoop 分布式文件系统 (HDFS) 的节点;也称为从属节点,运行图 2 所示的任务跟踪器进程。
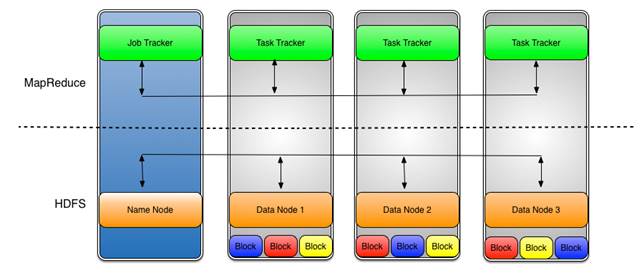
图 2. DataNode
监视虚拟化环境中的 CPU 负载
性能分析的最佳实践是鸟瞰正在运行的环境,以便了解哪个资源最繁忙,然后下钻到每个资源。表 1 汇总显示了我们将在 CPU 性能分析中使用的命令。
表 1. 命令汇总| 命令 | 说明 |
|---|---|
psrinfo |
显示处理器信息 |
zonestat |
报告活动区域统计信息 |
mpstat |
报告每个处理器或每个处理器集的统计信息 |
fsstat |
报告文件系统统计信息 |
vmstat |
报告虚拟内存统计信息和 CPU 活动 |
ps |
报告进程状态 |
pginfo |
打印 CPU 拓扑 |
pgstat |
报告处理器利用率统计信息 |
prstat |
报告活动进程统计信息 |
首先获取物理资源信息,如清单 1 所示。我们有多少个 CPU?
root@global_zone:~# psrinfo -pv
The physical processor has 16 cores and 128 virtual processors (0-127)
The core has 8 virtual processors (0-7)
The core has 8 virtual processors (8-15)
The core has 8 virtual processors (16-23)
The core has 8 virtual processors (24-31)
The core has 8 virtual processors (32-39)
The core has 8 virtual processors (40-47)
The core has 8 virtual processors (48-55)
The core has 8 virtual processors (56-63)
The core has 8 virtual processors (64-71)
The core has 8 virtual processors (72-79)
The core has 8 virtual processors (80-87)
The core has 8 virtual processors (88-95)
The core has 8 virtual processors (96-103)
The core has 8 virtual processors (104-111)
The core has 8 virtual processors (112-119)
The core has 8 virtual processors (120-127)
SPARC-T5 (chipid 0, clock 3600 MHz)
清单 1
在清单 1 中,我们看到一个 Oracle SPARC T5 处理器,其中一个 CPU 已分配。CPU 有 16 个内核和 128 个虚拟处理器(每个内核 8 个),最多能同时运行 128 个软件线程。
注:您可以使用 psrinfo -p 命令计算物理 CPU 的数量。
开始性能分析之前,我们需要了解每个 Oracle Solaris 区域的负载特点,确定其是否受限于 CPU、内存、磁盘 I/O 或网络 I/O。我们将使用 Oracle Solaris 11 zonestat、mpstat 和 fsstat 命令执行该操作。然后使用命令的输出分析环境中运行的负载。
我们将运行的对环境施加负载的第一个 Hadoop 基准测试是 Pi Estimator。Pi Estimator 是一个采用 Monte Carlo 方法估计 pi 值的 MapReduce 程序。
在本例中,我们将使用 128 个映射,每个映射将计算 10 亿个样本(总共 1280 亿个样本)。
注:每个 CPU 运行一个映射。
通过从全局区域运行以下命令启动 Pi Estimator 程序:
root@global_zone:~# zlogin -l hadoop name-node hadoop jar /usr/local/hadoop/hadoop-examples-1.2.0.jar pi 128 1000000000
其中:
zlogin -l hadoop name-node表示命令作为hadoop用户在name-node区域上运行。hadoop jar /usr/local/hadoop/hadoop-examples-1.2.0.jar pi表示 Hadoop.jar文件。128表示映射数量。1000000000表示样本数量。
可选:我们将使用 zlogin 命令在全局区域中运行命令。不过,您可直接从 name-node 区域运行命令,例如:
hadoop@name_node:$ hadoop jar /usr/local/hadoop/hadoop-examples-1.2.0.jar pi 128 1000000000
我们可以使用 hadoop job -list 命令列出 MapReduce 作业。
首先,打开另一个终端窗口,运行清单 2 所示的命令:
root@global_zone:~# zlogin -l hadoop name-node hadoop job -list Oracle Corporation SunOS 5.11 11.1 December 2012 1 jobs currently running JobId State StartTime UserName Priority SchedulingInfo job_201309081525_0135 1 1378711957491 hadoop NORMAL NA
清单 2
在清单 2 中,我们可以看到作业 ID (JobId) 及其开始时间 (StartTime)。
要获取完整的作业说明(例如,映射归约完成百分比和所有作业计数器),请运行以下命令,并提供 JobId 作为 hadoop job -status 命令的参数。
root@global_zone:~# zlogin -l hadoop name-node hadoop job -status job_201309081525_0135
性能分析过程中我们将使用的第一个命令是 zonestat 命令,该命令除了使我们能够监视环境中运行的所有 Oracle Solaris 区域外,还提供有关 CPU 利用率、内存利用率和网络利用率的实时统计信息。
每隔 10 秒运行一次 zonestat 命令,如清单 3 所示:
root@global_zone:~# zonestat 10 10
Interval: 1, Duration: 0:00:10
SUMMARY Cpus/Online: 128/12 PhysMem: 256G VirtMem: 259G
---CPU---- --PhysMem-- --VirtMem-- --PhysNet--
ZONE USED %PART USED %USED USED %USED PBYTE %PUSE
[total] 118.10 92.2% 24.6G 9.62% 60.0G 23.0% 18.4E 100%
[system] 0.00 0.00% 9684M 3.69% 40.5G 15.5% - -
data-node3 42.13 32.9% 4897M 1.86% 6146M 2.30% 18.4E 100%
data-node1 41.49 32.4% 4891M 1.86% 6173M 2.31% 18.4E 100%
data-node2 33.97 26.5% 4851M 1.85% 6145M 2.30% 18.4E 100%
global 0.34 0.27% 283M 0.10% 420M 0.15% 2192 0.00%
name-node 0.15 0.11% 419M 0.15% 718M 0.26% 126 0.00%
sec-name-node 0.00 0.00% 205M 0.07% 363M 0.13% 0 0.00%
清单 3
从清单 3 中的 zonestat 输出可以看出,Pi Estimator 程序是受 CPU 限制的应用程序 (%PART 92.2.0%)。
zonestat 命令打印以下信息:
Zone列显示区域名称:
[total]显示整个系统所使用的资源总量。[system]显示内核或以与特定区域无关的形式所使用的资源数量。
注:
zonestat在非全局区域中运行时,该值是系统和所有其他区域所消耗的资源总和。CPU显示 CPU 信息:
USED显示所使用的 CPU 数量。%PART显示 CPU 利用率,即限制区域的处理器集的计算容量百分比。
注:要查看整个系统的处理器信息,请使用
psrset -i命令或位于/usr/dtrace/DTT/Bin的cputypes.dDTrace 脚本。PhysMem显示物理内存信息:
USED显示已使用的内存量。%USED显示已使用的资源量占总资源的百分比。
VirtMem显示虚拟内存信息:
USED显示已使用的虚拟内存量。%USED显示已使用的资源量占系统中总虚拟内存的百分比。
PhysNet显示网络信息:
PBYTE显示占用物理带宽的接收和发送字节数。%PUSH显示接收和发送字节总数占总可用物理带宽的百分比。
zonestat 命令可以就一段时间内的总利用率和高利用率打印一份报告,如果您想了解使用高峰,该报告非常有用。可以使用此信息将当前活动与之前的活动进行比较,有助于为未来增长进行容量规划。
例如,清单 4 中显示的命令将在后台以 10 秒的时间间隔监视 3 分钟,然后生成一份显示总利用率和高利用率的报告。
root@global_zone:~# zonestat -q -R total,high 10s 3m 3m
Report: Total Usage
Start: Wednesday, November 13, 2013 10:37:04 AM IST
End: Wednesday, November 13, 2013 10:40:04 AM IST
Intervals: 18, Duration: 0:03:00
SUMMARY Cpus/Online: 128/12 PhysMem: 256G VirtMem: 259G
---CPU---- --PhysMem-- --VirtMem-- --PhysNet--
ZONE USED %PART USED %USED USED %USED PBYTE %PUSE
[total] 79.9 61.7% 29.5G 11.5% 61.7G 23.7% 7762 0.00%
[system] 3.63 2.83% 9538M 3.63% 37.7G 14.5% - -
data-node3 25.9 19.6% 557M 0.21% 5857M 2.20% 18.4E 100%
data-node2 24.81 19.3% 435M 0.16% 5715M 2.14% 18.4E 100%
data-node1 24.61 19.2% 552M 0.21% 5867M 2.20% 18.4E 100%
global 0.87 0.68% 6014M 2.29% 6134M 2.30% 908K 0.00%
name-node 0.06 0.04% 485M 0.18% 619M 0.23% 18.4E 100%
sec-name-node 0.00 0.00% 260M 0.09% 291M 0.10% 0 0.00%
Report: High Usage
Start: Wednesday, November 13, 2013 10:37:04 AM IST
End: Wednesday, November 13, 2013 10:40:04 AM IST
Intervals: 18, Duration: 0:03:00
SUMMARY Cpus/Online: 128/12 PhysMem: 256G VirtMem: 259G
---CPU---- --PhysMem-- --VirtMem-- --PhysNet--
ZONE USED %PART USED %USED USED %USED PBYTE %PUSE
[total] 111.17 86.8% 31.5G 12.3% 63.8G 24.5% 892K 0.00%
[system] 23.65 18.4% 9643M 3.67% 37.8G 14.5% - -
data-node3 25.85 20.2% 557M 0.21% 976M 0.36% 18.4E 100%
data-node2 22.95 17.9% 435M 0.16% 534M 0.20% 18.4E 100%
data-node1 22.22 17.3% 552M 0.21% 774M 0.29% 18.4E 100%
global 2.87 2.24% 6014M 2.29% 6128M 2.30% 946K 0.00%
name-node 0.08 0.06% 485M 0.18% 619M 0.23% 18.4E 100%
sec-name-node 0.00 0.00% 260M 0.09% 291M 0.10% 0 0.00%
清单 4
我们可以从清单 4 的输出中了解到以下信息:
- 平均 CPU 利用率为 61.7% (
SUMMARY,%PART 61.7%)。 - 高利用率为 86.8% (
Report:High Usage,%PART 86.8%)。
此外,我们还能看到可用 CPU 的利用率是否平衡。在清单 4 中,我们可以看到所用 CPU 的总数为 111,每个 DataNode 包含 22 到 26 个 CPU。
我们也可以使用 zonestat 命令收集较长一段时间内(数天、数周或数月)的系统利用率信息。例如,以下命令将在后台以 10 秒的时间间隔监视 24 小时,每小时都会生成一份总利用率和高利用率报告:
root@global_zone:~# zonestat -q -R total,high 10s 24h 1h
显示可用 CPU 利用率是否平衡的另一个有用命令是 mpstat。
清单 5 是 Oracle Solaris mpstat(1M) 命令的输出。每行代表一个虚拟 CPU。
root@global_zone:~# mpstat 1 CPU minf mjf xcal intr ithr csw icsw migr smtx srw syscl usr sys wt idl 0 85 0 10183 683 59 931 40 269 464 2 1315 30 14 0 56 1 80 0 34872 484 9 1096 39 317 498 2 1437 34 14 0 51 2 72 0 15632 325 4 669 30 166 334 1 1321 37 9 0 54 3 42 0 13422 253 3 553 32 144 277 2 818 31 7 0 62 4 57 0 14009 351 5 736 43 204 352 2 936 28 8 0 64 5 67 0 10445 258 4 562 28 162 297 2 732 27 9 0 64 6 49 0 15770 322 5 660 36 187 304 2 332 32 7 0 60 7 44 0 5872 351 8 802 42 222 396 2 1077 30 9 0 61 8 34 0 12701 391 7 826 35 245 430 2 854 33 11 0 56 9 63 0 11926 578 7 1311 52 372 613 4 958 35 13 0 53 10 82 0 11602 423 7 930 43 222 432 3 991 32 10 0 58 11 24 0 14940 253 4 525 26 139 281 2 692 33 7 0 60 12 35 0 10450 285 3 571 17 141 307 2 713 30 8 0 62 13 46 0 27600 298 7 625 35 172 310 2 580 32 8 0 60 14 49 0 14039 371 5 770 30 212 377 2 726 28 9 0 63 15 73 0 10714 289 4 643 27 163 334 3 883 33 8 0 59
清单 5
如清单 5 所示,mpstat 命令报告以下信息:
CPU列显示逻辑 CPU ID。minf列显示小故障数量。mjf列显示严重故障数量。xcal列显示处理器间交叉调用的次数。intr列显示中断次数。ithr列显示作为线程运行的中断次数(更低的 IPL)。csw列显示上下文切换次数(总数)。icsw列显示无意的上下文切换次数。migr列显示线程迁移(至另一个处理器)的次数。smtx列显示互斥锁上的自旋次数。srw列显示读取器/写入器锁上的自旋次数。syscl列显示系统调用次数。usr列显示 CPU 所用用户时间的百分比。sys列显示 CPU 所用系统时间(内核)的百分比。wt列显示等待 I/O 时间(已弃用,因此始终为零)。idl列显示空闲时间百分比。
通过查看显示空闲时间百分比的 idl 字段,我们可以了解每个 CPU 的繁忙程度。此外,我们还可以使用 dim_stat 工具显示 mpstat 命令的输出,如图 3 所示。
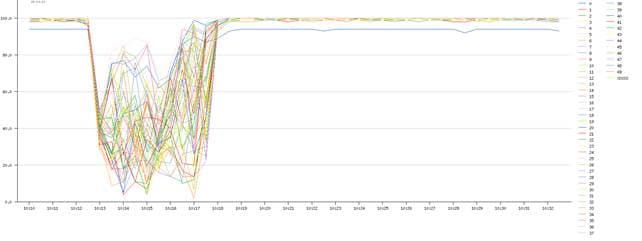
图 3. dim_stat 工具的输出
在多 CPU 系统上,mpstat 输出可能会非常长;但是我们可以监视每个内核的 CPU 利用率,如清单 6 所示。
root@global_zone:~# mpstat -A core 10 COR minf mjf xcal intr ithr csw icsw migr smtx srw syscl usr sys wt idl sze 3074 103 0 23654 1680 697 1264 644 277 502 10 11268 748 52 0 0 8 3078 95 0 32090 893 137 1228 635 281 439 8 10929 759 41 0 0 8 3082 94 0 31574 889 129 1245 629 308 560 9 12792 753 47 0 0 8 3086 111 0 20262 829 121 1200 615 277 512 7 12657 753 47 0 0 8 3090 155 0 16849 896 133 1276 646 281 567 9 12321 749 51 0 0 8 3094 123 0 24022 810 100 1210 617 283 512 8 12009 751 49 0 0 8 3098 101 0 25212 798 96 1186 594 286 577 6 14205 745 55 0 0 8 3102 111 0 25626 734 88 1091 555 230 489 10 11338 762 38 0 0 8 3106 126 0 31042 832 112 1206 614 281 513 11 11111 757 43 0 0 8 3110 126 0 33856 777 88 1167 596 245 596 10 12739 751 49 0 0 8 3114 136 0 21364 895 131 1280 646 273 586 7 13259 748 52 0 0 8 3118 128 0 28063 1021 111 1506 746 265 594 7 11178 752 48 0 0 8 3122 125 0 18047 918 124 1313 667 287 550 12 12720 749 51 0 0 8 3126 87 0 30336 898 130 1257 640 268 533 11 12930 747 53 0 0 8 3130 127 0 21213 944 138 1340 676 292 516 8 13842 748 52 0 0 8 3134 115 0 31696 767 103 1098 561 259 495 7 10162 755 45 0 0 8
清单 6
在清单 6 中,我们可以看到 mpstat 打印每个内核的 CPU 性能统计信息,并显示 SPARC T5 CPU 共有 16 个内核。然后,我们将了解如何监视每个内核,以及如何观察其浮点和整数管道。此外,mpstat 还可打印每个套接字或处理器集的性能统计信息,并可打印每个内核中的 CPU 数量(在 sze 列)。更多示例,请参见 mpstat(1M)。
我们在性能分析中将使用的下一个命令是 fsstat 命令,该命令对磁盘 I/O 监视非常有用。这让我们能够监视每个磁盘或每个 Oracle Solaris 区域的磁盘 I/O 活动。我们将使用此命令检查 Pi Estimator 除受 CPU 限制外,是否还受磁盘 I/O 的限制。
例如,我们可以使用清单 7 所示的命令以 10 秒的时间间隔监视所有 ZFS 文件系统的写入操作。
root@global_zone:~# fsstat -Z zfs 10 10
new name name attr attr lookup rddir read read write write
file remov chng get set ops ops ops bytes ops bytes
0 0 0 744 0 11.4K 0 6.01K 5.87M 0 0 zfs:global
0 0 0 151 0 3.27K 0 1.41K 1.94M 7 1.42K zfs:data-node1
0 0 0 359 0 8.72K 0 2.75K 3.95M 22 4.06K zfs:data-node2
0 0 0 413 0 9.03K 0 2.98K 4.22M 21 4.34K zfs:data-node3
0 0 0 14 0 51 0 0 0 0 0 zfs:name-node
0 0 0 14 0 51 0 0 0 0 0 zfs:sec-name-node
清单 7
默认报告显示常规文件系统活动。如清单 7 所示,输出将类似操作归纳为以下常规类别:
new file列显示文件系统对象(例如,文件、目录、符号链接等)的创建操作数量。name remov列显示名称删除操作的数量。name chng列显示名称更改操作的数量。attr get列显示对象属性检索操作的数量。attr set列显示对象属性更改操作的数量。lookup ops列显示对象查询操作的数量。rddir ops列显示读取目录操作的数量。read op列显示数据读取操作的数量。read bytes列显示通过数据读取操作传输的字节数。write ops列显示数据写入操作的数量。
从清单 7 中的 fsstat 输出可以看出,读取操作和写入操作的数量显示磁盘利用率非常低。
从 fsstat、mpstat 和 fsstat 输出可以看出,Pi Estimator 程序为受 CPU 限制的应用程序。(在第二个示例中,我们将演示如何确定磁盘 I/O 负载。)
因此,让我们继续分析 CPU 性能。接下来,我们将询问是否存在空闲 CPU 时间。
注:如果完成,您可能需要再次返回 Pi Estimator 程序。程序完成后,将打印作业汇总信息,例如:
Job Finished in 309.819 seconds Estimated value of Pi is 3.14159266603125000000
如清单 8 所示,我们可以使用 vmstat 命令查看是否存在空闲 CPU 时间。
root@global_zone:~# vmstat 1 kthr memory page disk faults cpu r b w swap free re mf pi po fr de sr s3 s4 s5 s6 in sy cs us sy id kthr memory page disk faults cpu r b w swap free re mf pi po fr de sr s3 s4 s5 s6 in sy cs us sy id 8 0 0 213772168 245340872 770 5954 0 0 0 0 0 0 0 0 0 17732 161637 39181 93 7 0 12 0 0 213346168 244887200 134 2237 0 0 0 0 0 0 0 0 0 13689 140604 19640 96 4 0 17 0 0 212974464 244353760 124 1939 0 0 0 0 0 0 0 0 0 12079 130895 17225 96 4 0 29 0 0 212657512 243704448 118 2662 0 0 0 0 0 117 0 0 0 13804 131482 18530 95 5 0 41 0 0 210748016 241728920 202 2962 0 0 0 0 0 0 0 78 71 15214 122457 21418 96 4 0 32 0 0 209808688 240699416 80 2509 0 0 0 0 0 0 0 0 0 16524 146238 31628 97 3 0 36 0 0 209122192 239714912 13 1991 0 0 0 0 0 0 0 0 0 16743 132784 35315 97 3 0 22 0 0 207632424 238260184 0 2709 0 0 0 0 0 0 0 0 0 23357 146885 56380 96 4 0 13 0 0 206528520 236636888 0 1346 0 0 0 0 0 100 0 0 0 16161 74431 37560 98 2 0 1 0 0 206277936 236263016 0 1448 0 0 0 0 0 0 0 78 79 14499 59197 28766 96 1 3 0 0 0 206069656 235992504 0 1801 0 0 0 0 0 0 0 0 0 20478 66313 49291 90 2 8 18 0 0 205840984 235578720 0 957 0 0 0 0 0 0 0 0 0 15203 34428 28456 78 1 21 0 0 0 205762976 235447600 0 653 0 0 0 0 0 0 0 0 0 7977 8926 7977 62 0 38 0 0 0 205762976 235443400 910 1353 0 0 0 0 0 137 0 0 0 22505 14974 41402 59 3 39
清单 8
在清单 8 中,我们将在 id 列看到 CPU 空闲时间。id 列的 0 值表示系统的 CPU 处于 100% 繁忙状态!
下一个问题是可用 CPU 是否有线程等待。这称为运行队列延迟,可通过打印运行队列中内核线程数量的 r 列轻松跟踪。您还可以通过使用 prstat -Lm 命令、注意 LAT 列的值来跟踪运行队列延迟。
此外,我们还可以使用 prstat 命令查看 CPU 周期消耗在用户模式还是系统(内核)模式。
root@global_zone:~# prstat -ZmL
Total: 310 processes, 8269 lwps, load averages: 47.63, 48.79, 36.98
PID USERNAME USR SYS TRP TFL DFL LCK SLP LAT VCX ICX SCL SIG PROCESS/LWPID
19338 hadoop 100 0.0 0.0 0.0 0.0 0.0 0.0 0.3 0 73 0 0 java/2
19329 hadoop 100 0.0 0.0 0.0 0.0 0.0 0.0 0.4 0 86 0 0 java/2
19519 hadoop 84 15 0.1 0.0 0.2 0.0 0.0 0.8 56 153 29K 0 java/2
19503 hadoop 88 11 0.1 0.0 0.3 0.1 0.0 1.0 52 168 23K 3 java/2
19536 hadoop 81 18 0.1 0.0 0.4 0.0 0.0 1.1 83 268 32K 0 java/2
19495 hadoop 89 9.6 0.1 0.0 0.3 0.7 0.0 0.7 51 163 21K 2 java/2
19523 hadoop 82 16 0.1 0.0 0.6 0.7 0.0 0.5 87 214 31K 0 java/2
19259 hadoop 97 0.0 0.0 0.0 0.0 2.9 0.0 0.1 4 36 9 1 java/2
19555 hadoop 73 24 0.2 0.0 1.9 0.0 0.1 0.9 207 207 35K 0 java/2
19263 hadoop 97 0.0 0.0 0.0 0.0 2.8 0.0 0.3 6 66 13 2 java/2
19258 hadoop 97 0.0 0.0 0.0 0.0 2.8 0.0 0.3 6 120 15 2 java/2
19285 hadoop 97 0.0 0.0 0.0 0.0 2.8 0.0 0.4 7 89 13 2 java/2
19331 hadoop 97 0.0 0.0 0.0 0.0 3.0 0.0 0.2 5 65 13 2 java/2
19272 hadoop 97 0.0 0.0 0.0 0.0 2.9 0.0 0.3 6 65 13 2 java/2
19313 hadoop 97 0.0 0.0 0.0 0.0 3.1 0.0 0.1 6 68 11 2 java/2
ZONEID NLWP SWAP RSS MEMORY TIME CPU ZONE
12 1722 5073M 3638M 28% 0:54:41 31% data-node1
13 1846 6131M 4757M 37% 0:50:54 39% data-node2
14 1426 4446M 3452M 28% 0:51:54 28% data-node3
0 1726 973M 603M 0.7% 0:45:37 0.1% global
15 446 883M 558M 5.6% 0:04:32 1.9% name-node
Total: 295 processes, 7398 lwps, load averages: 50.67, 49.39, 37.25
清单 9
如清单 9 所示,prstat 输出中显示以下列:
USR列显示进程在用户模式下所花费的时间百分比。SYS列显示进程在系统模式下所花费的时间百分比。TRP列显示进程处理系统陷阱所花费的时间百分比。TFL列显示进程处理文本页面故障所花费的时间百分比。DFL列显示进程处理数据页面故障所花费的时间百分比。LCK列显示进程等待用户锁所花费的时间百分比。SLP列显示进程休眠所花费的时间百分比。LAT列显示进程等待 CPU 所花费的时间百分比。VCX列显示故意上下文切换次数。ICX列显示无意的上下文切换次数。SCL列显示系统调用次数。SIG列显示接收的信号数量。
清单 9 中的 prstat 输出显示系统 CPU 周期消耗在用户模式 (USR) 下。更多 prstat 示例,请参见 http://www.scalingbits.com/performance/prstat。
另一个能够感知虚拟化的有用命令是 ps。使用 -Z 选项时,它将在附加的 ZONE 列标题下方打印与进程关联的区域名称。
注:该命令能够感知其正在非全局区域中运行;因此,从非全局区域运行时,它看不到其他用户进程。
使用 ps -efZ 命令查看现在正在运行 (e) 的每个进程的完整列表 (f) 以及相关联的区域名称 (Z)。例如,要打印现在正在运行的所有 Hadoop 进程,请使用清单 10 所示的命令:
root@global_zone:~# ps -efZ | grep hadoop ZONE UID PID PPID C STIME TTY TIME CMD data-nod hadoop 14024 11795 0 07:38:19 ? 0:20 /usr/jdk/instances/jdk1.6.0/jre/bin/java -Djava.library.path=/usr/local/hadoop- data-nod hadoop 14026 11798 0 07:38:19 ? 0:19 /usr/jdk/instances/jdk1.6.0/jre/bin/java -Djava.library.path=/usr/local/hadoop- name-nod hadoop 11621 1 0 07:20:12 ? 0:59 /usr/java/bin/java -Dproc_jobtracker -Xmx1000m -Dcom.sun.management.jmxremote - name-nod hadoop 11263 1 0 07:20:07 ? 0:27 /usr/java/bin/java -Dproc_namenode -Xmx1000m -Dcom.sun.management.jmxremote -Dc data-nod hadoop 13912 11798 0 07:38:18 ? 0:23 /usr/jdk/instances/jdk1.6.0/jre/bin/java -Djava.library.path=/usr/local/hadoop- data-nod hadoop 11730 1 1 07:20:14 ? 2:58 /usr/java/bin/java -Dproc_tasktracker -Xmx1000m -Dhadoop.log.dir=/var/log/hadoo data-nod hadoop 11458 1 0 07:20:09 ? 0:18 /usr/java/bin/java -Dproc_datanode -Xmx1000m -server -Dcom.sun.management.jmxre data-nod hadoop 13957 11798 1 07:38:18 ? 0:23 /usr/jdk/instances/jdk1.6.0/jre/bin/java -Djava.library.path=/usr/local/hadoop- data-nod hadoop 13953 11795 0 07:38:18 ? 0:24 /usr/jdk/instances/jdk1.6.0/jre/bin/java -Djava.library.path=/usr/local/hadoop- data-nod hadoop 13815 11730 0 07:38:15 ? 0:22 /usr/jdk/instances/jdk1.6.0/jre/bin/java -Djava.library.path=/usr/local/hadoop- data-nod hadoop 13965 11795 0 07:38:18 ? 0:22 /usr/jdk/instances/jdk1.6.0/jre/bin/java -Djava.library.path=/usr/local/hadoop-
清单 10
注:ZONE 列宽仅限 8 个字符。
SPARC T5 CPU 有 16 个内核和 128 个线程,每个内核有两个整数管道和一个浮点管道。有关 SPARC T5 CPU 架构的更多信息,请参见此白皮书。
注:您可以使用 pginfo -p -T 命令查看 CPU 拓扑。更多信息,请参见 https://blogs.oracle.com/d/entry/pginfo_pgstat。
如果我们需要了解正在加载的管道数量,pgstat 工具可提供这种级别的详细信息。
例如,使用清单 11 所示的命令运行三分钟 pgstat 报告:
root@global_zone:~# pgstat -A 60 3
SUMMARY: UTILIZATION OVER 180 SECONDS
------HARDWARE------ ------SOFTWARE------
PG RELATIONSHIP MIN AVG MAX MIN AVG MAX CPUS
0 System - - - 1.8% 79.1% 100.0% 0-127
3 Data_Pipe_to_memory - - - 1.8% 79.1% 100.0% 0-127
4 CPU_PM_Active_Power_Domain - - - 1.5% 78.4% 100.0% 0-15
2 Floating_Point_Unit 0.0% 8.8% 12.7% 1.8% 78.1% 100.0% 0-7
1 Integer_Pipeline 0.7% 91.2% 98.7% 1.8% 78.1% 100.0% 0-7
6 Floating_Point_Unit 0.0% 7.6% 12.7% 1.2% 78.8% 100.0% 8-15
5 Integer_Pipeline 1.0% 90.5% 98.9% 1.2% 78.8% 100.0% 8-15
9 CPU_PM_Active_Power_Domain - - - 2.4% 78.3% 100.0% 16-31
8 Floating_Point_Unit 0.0% 5.8% 12.7% 1.5% 82.0% 100.0% 16-23
7 Integer_Pipeline 0.9% 86.5% 99.2% 1.5% 82.0% 100.0% 16-23
11 Floating_Point_Unit 0.0% 5.5% 12.5% 3.2% 74.5% 100.0% 24-31
10 Integer_Pipeline 1.4% 85.4% 98.2% 3.2% 74.5% 100.0% 24-31
14 CPU_PM_Active_Power_Domain - - - 1.6% 78.8% 100.0% 32-47
13 Floating_Point_Unit 0.0% 7.9% 12.7% 2.5% 79.7% 100.0% 32-39
12 Integer_Pipeline 5.1% 90.5% 99.2% 2.5% 79.7% 100.0% 32-39
16 Floating_Point_Unit 0.0% 7.3% 12.6% 0.5% 77.7% 100.0% 40-47
15 Integer_Pipeline 1.0% 87.3% 98.5% 0.5% 77.7% 100.0% 40-47
19 CPU_PM_Active_Power_Domain - - - 1.2% 81.0% 100.0% 48-63
18 Floating_Point_Unit 0.0% 8.8% 12.8% 1.0% 84.7% 100.0% 48-55
17 Integer_Pipeline 0.7% 95.2% 99.5% 1.0% 84.7% 100.0% 48-55
21 Floating_Point_Unit 0.0% 7.7% 12.7% 1.4% 77.2% 100.0% 56-63
20 Integer_Pipeline 1.2% 90.4% 98.9% 1.4% 77.2% 100.0% 56-63
24 CPU_PM_Active_Power_Domain - - - 2.6% 78.9% 100.0% 64-79
23 Floating_Point_Unit 0.0% 7.1% 12.7% 4.7% 79.8% 100.0% 64-71
22 Integer_Pipeline 9.2% 88.4% 98.9% 4.7% 79.8% 100.0% 64-71
26 Floating_Point_Unit 0.0% 6.2% 12.6% 0.6% 77.9% 100.0% 72-79
25 Integer_Pipeline 0.8% 84.7% 98.4% 0.6% 77.9% 100.0% 72-79
...
清单 11
在清单 11 中,我们可以了解每个管道(Integer_Pipeline、Floating_Point_Unit)的繁忙程度,并且还可以看到系统的整数利用率达到了 90% 以上。此外,我们还可以看到内存带宽 (Data_Pipe_to_memory)。
接下来,我们想要查看产生该负载的应用程序。例如,导致 CPU 繁忙的代码路径是什么?各区域中哪个进程产生了该系统负载?
在下一个示例中,我们将下钻到其中一个 Oracle Solaris 区域,了解哪个应用程序或进程产生了该负载。
让我们登录 data-node1 区域:
root@global_zone:~# zlogin data-node1
注:您可以使用 zonename 命令打印当前区域名称,验证是否已成功登录 data-node1 区域。
root@data-node1:~# zonename data-node1
如清单 12 所示,我们可以在区域中使用 prstat 命令查看哪个进程产生了该系统负载。
root@data-node1:~# prstat -mLc PID USERNAME USR SYS TRP TFL DFL LCK SLP LAT VCX ICX SCL SIG PROCESS/LWPID 22866 root 24 74 1.6 0.0 0.0 0.0 0.0 0.0 122 122 85K 0 prstat/1 22715 hadoop 80 3.3 0.1 0.0 0.0 4.0 0.1 12 45 201 4K 4 java/2 22704 hadoop 80 3.3 0.2 0.0 0.0 6.2 0.4 10 61 277 4K 10 java/2 22721 hadoop 79 3.4 0.2 0.0 0.0 3.5 0.3 14 52 290 4K 5 java/2 22740 hadoop 78 3.5 0.2 0.0 0.0 3.2 0.1 15 67 400 4K 9 java/2 22710 hadoop 78 3.2 0.2 0.0 0.0 5.9 0.1 13 53 313 4K 5 java/2 22691 hadoop 78 3.0 0.2 0.0 0.0 4.6 0.2 14 49 349 3K 5 java/2 22734 hadoop 77 3.5 0.2 0.0 0.0 3.5 0.2 15 55 373 4K 7 java/2 22746 hadoop 77 3.6 0.2 0.0 0.0 4.1 0.2 15 71 356 4K 9 java/2 22752 hadoop 76 3.6 0.2 0.0 0.0 5.6 0.2 14 76 323 4K 10 java/2 22767 hadoop 76 3.9 0.1 0.0 0.0 3.4 0.4 16 61 374 4K 9 java/2 22698 hadoop 76 3.3 0.2 0.0 0.0 4.2 0.0 16 65 324 4K 11 java/2 22792 hadoop 75 4.3 0.1 0.0 0.0 4.3 0.3 16 63 271 4K 6 java/2 22760 hadoop 76 3.7 0.1 0.0 0.0 6.0 0.9 14 67 280 4K 11 java/2 22685 hadoop 76 2.9 0.1 0.0 0.0 4.5 0.0 16 43 259 3K 4 java/2 Total: 58 processes, 2011 lwps, load averages: 58.00, 55.80, 41.70
清单 12
在清单 12 中,我们可以看到 hadoop 进程产生了该系统负载。
注:清单 12 显示,我们可以从本地区域内运行 prstat 命令查看每个区域的性能统计信息。我们也可以从全局区域运行该命令获取完整的系统视图。这是一个能够感知虚拟化的命令示例;如果在非全局区域内运行,该命令能感知到,从而无法查看其他用户进程。
监视虚拟化环境中的磁盘 I/O 活动
在第二个示例中,我们将使用 Hadoop 内置的基准测试来观察和监视磁盘 I/O 活动。表 2 显示我们将用来监视磁盘 I/O 活动的命令汇总。
表 2. 命令汇总| 命令 | 说明 |
|---|---|
fsstat |
显示每个 Oracle Solaris 区域的磁盘 I/O 负载 |
zpool iostat |
显示指定池的 I/O 统计信息 |
iostat |
报告磁盘 I/O 统计信息 |
iotop |
按进程显示每个区域最频繁的磁盘 I/O 事件 |
rwtop |
按进程显示最频繁的读取/写入字节 |
iopattern |
显示所有磁盘 I/O 访问模式的详细信息 |
图 4 显示了 ZFS 和磁盘布局。
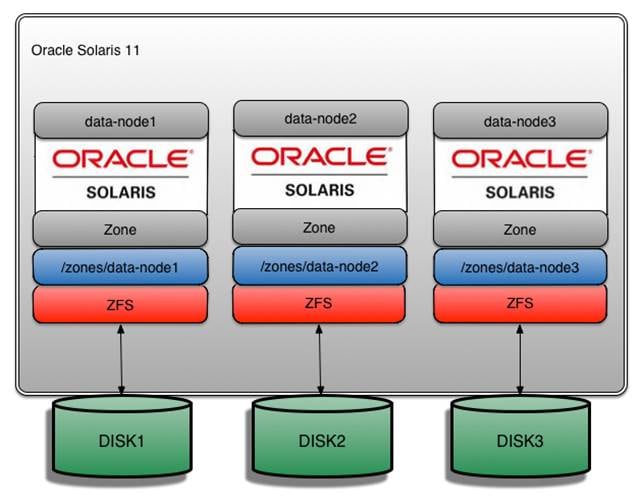
图 4. 磁盘布局
我们来打印系统中的硬盘数量:
root@global_zone:~# format < /dev/null
Searching for disks...done
AVAILABLE DISK SELECTIONS:
0. c0t5001517803D013B3d0 <ATA-INTEL SSDSA2BZ30-0362 cyl 35769 alt 2 hd 128 sec 128> solaris
/scsi_vhci/disk@g5001517803d013b3
/dev/chassis/SPARC_T5-2.AK00104209//SYS/SASBP/HDD0/disk
1. c0t5000CCA0160D3264d0 <HITACHI-H109060SESUN600G-A31A-558.91GB>
/scsi_vhci/disk@g5000cca0160d3264
/dev/chassis/SPARC_T5-2.AK00104209//SYS/SASBP/HDD1/disk
2. c0t5000CCA01612A4F0d0 <HITACHI-H109060SESUN600G-A31A-558.91GB>
/scsi_vhci/disk@g5000cca01612a4f0
/dev/chassis/SPARC_T5-2.AK00104209//SYS/SASBP/HDD2/disk
3. c0t5000CCA016295ABCd0 <HITACHI-H109060SESUN600G-A31A-558.91GB>
/scsi_vhci/disk@g5000cca016295abc
/dev/chassis/SPARC_T5-2.AK00104209//SYS/SASBP/HDD3/disk
4. c0t5000CCA016359F94d0 <HITACHI-H109060SESUN600G-A31A cyl 64986 alt 2 hd 27 sec 668>
/scsi_vhci/disk@g5000cca016359f94
/dev/chassis/SPARC_T5-2.AK00104209//SYS/SASBP/HDD4/disk
5. c0t5000CCA0162A6E0Cd0 <HITACHI-H109060SESUN600G-A31A cyl 64986 alt 2 hd 27 sec 668> solaris
/scsi_vhci/disk@g5000cca0162a6e0c
/dev/chassis/SPARC_T5-2.AK00104209//SYS/SASBP/HDD5/disk
Specify disk (enter its number):
分析磁盘 I/O 性能时,我们将询问以下问题:
- 目标 I/O 设备是什么?
- 读取/写入故障是什么?此外,磁盘的 I/O 访问模式是什么?例如,随机事件和有序事件各占多大比例?
- 每个设备(硬盘)处理磁盘 I/O 的速度有多快?
- 哪些代码路径(应用程序)导致磁盘处于忙碌状态?
Hadoop 附带多个能够测试整个 MapReduce 系统的基准测试,有助于提供真实的负载。
我们将使用基准测试执行三个主要任务:
- 生成一些随机数据。
- 对随机数据进行排序。
- 验证结果(即数据已排序)。
在第一步中,我们将使用 RandomWriter 生成随机数据。该工具将对每个节点的 10 个映射运行 MapReduce 作业,每个映射将生成(大约)10 GB 的随机二进制数据(共 100 GB),具有大小各异的键和值。表 3 显示配置变量。
注:由于存在复制因子 (3),所以将写入的实际数据量是三倍大小。
表 3. 配置变量| 名称 | 默认值 | 说明 |
|---|---|---|
test.randomwriter.maps_per_host |
10 | 每台主机的映射数量 |
test.randomwrite.bytes_per_map |
1073741824 | 每个映射写入的字节数 |
test.randomwrite.min_key |
10 | 字节中键的最小大小 |
test.randomwrite.max_key |
1000 | 字节中键的最大大小 |
test.randomwrite.min_value |
0 | 最小值 |
test.randomwrite.max_value |
20000 | 最大值 |
注:如果您愿意,可通过设置 Hadoop 配置文件中的属性来更改这些值。有关详细信息,请参见 RandomWriter。
首先,我们来编辑 HADOOP_INSTALL 环境变量,以提供更好的命令可读性。
root@global_zone:~# export HADOOP_INSTALL=/usr/local/hadoop
可选:您可以在 .profile 文件中添加以下环境变量来设置持久性配置:
export HADOOP_INSTALL=/usr/local/hadoop
更改基准测试文件权限,以便您能够执行基准测试:
root@global_zone:~# chmod +x /usr/local/hadoop/hadoop-examples-1.2.0.jar
然后,使用清单 13 所示的命令生成随机数据:
root@global_zone:~# zlogin -l hadoop name-node hadoop jar $HADOOP_INSTALL/hadoop-examples-1.2.0.jar randomwriter random-data
清单 13
其中:
zlogin -l hadoop name-node表示命令作为hadoop用户在name-node区域上运行。hadoop jar /usr/local/hadoop/hadoop-examples-1.2.0.jar randomwriter表示 Hadoop.jar文件。random-data表示输出目录。
默认情况下,随机数据写入 /user/hadoop/random-data 目录中。
您可使用以下命令查看生成的文件:
root@global_zone:~# zlogin -l hadoop data-node1 hadoop dfs -ls /user/hadoop/random-data Oracle Corporation SunOS 5.11 11.1 December 2012 Found 32 items -rw-r--r-- 3 hadoop supergroup 0 2013-10-07 080 2013-10-07 08:26 /user/hadoop/random-data/_SUCCESS drwxr-xr-x - hadoop supergroup 0 2013-10-07 08
观察磁盘 I/O 性能时我们将使用的第一个命令是 fsstat 命令,该命令让我们能够分析每个 Oracle Solaris 区域的磁盘 I/O 负载,以及查看每个文件系统的文件系统统计信息。
清单 14 显示系统上每个区域的统计信息,以及 tmpfs 和 zfs 文件系统的系统级汇总。
root@global_zone:~# fsstat -A -Z tmpfs zfs 10 10
new name name attr attr lookup rddir read read write write
file remov chng get set ops ops ops bytes ops bytes
126 0 128 1.57K 512 15.9K 0 0 0 127 15.9K tmpfs
0 0 0 0 0 0 0 0 0 0 0 tmpfs:global
20 0 20 260 80 2.55K 0 0 0 20 2.50K tmpfs:data-node2
52 0 52 612 208 6.36K 0 0 0 52 6.50K tmpfs:data-node3
0 0 0 40 0 70 0 0 0 0 0 tmpfs:name-node
0 0 0 40 0 70 0 0 0 0 0 tmpfs:sec-name-node
54 0 56 656 224 6.83K 0 0 0 55 6.88K tmpfs:data-node1
156 0 162 1.78K 0 22.9K 0 28 3.16K 175K 5.45G zfs
0 0 0 0 0 3 0 2 599 0 0 zfs:global
52 0 54 511 0 4.52K 0 0 0 58.3K 1.82G zfs:data-node2
52 0 54 512 0 8.46K 0 12 1.28K 58.3K 1.82G zfs:data-node3
0 0 0 140 0 514 0 1 4 106 19.2K zfs:name-node
0 0 0 140 0 510 0 0 0 0 0 zfs:sec-name-node
52 0 54 518 0 8.95K 0 13 1.29K 58.3K 1.81G zfs:data-node1
清单 14
清单 14 中的命令输出显示了 tmpfs 和 zfs 文件系统(read bytes 和 write bytes)上已写入的数据量。
接下来,我们将明确特定针对 Oracle Solaris 区域统计哪些信息。
以下示例显示区域 data-node1、data-node2 和 data-node3 的统计信息,以及 tmpfs 和 zfs 文件系统的系统级汇总。
root@global_zone:~# fsstat -A -Z -z data-node1 -z data-node2 -z data-node3 tmpfs zfs 10 10 new name name attr attr lookup rddir read read write write file remov chng get set ops ops ops bytes ops bytes 140 13 116 3.16
MapReduce 基准测试的下一步是运行排序程序,对上一步生成的随机数据进行排序。运行清单 15 所示命令:
root@global_zone:~# zlogin -l hadoop name-node hadoop jar $HADOOP_INSTALL/hadoop-examples-1.2.0.jar sort random-data sorted-data Oracle Corporation SunOS 5.11 11.1 December 2012 Running on 3 nodes to sort from hdfs://name-node/user/hadoop/random-data into hdfs://name-node/user/hadoop/sorted-data with 67 reduces. Job started: Mon Oct 07 08:34:16 IST 2013 13/10/07 08:34:16 INFO mapred.FileInputFormat: Total input paths to process : 30 13/10/07 08:34:17 INFO mapred.JobClient: Running job: job_201310062308_0015 13/10/07 08:34:18 INFO mapred.JobClient: map 0% reduce 0%
清单 15
其中:
zlogin -l hadoop name-node表示命令作为hadoop用户在name-node区域上运行。hadoop jar /usr/local/hadoop/hadoop-examples-1.2.0.jar sort表示 Hadoop.jar文件。random-data表示输入目录。sorted-data表示输出目录。
接下来,我们将下钻观察单个磁盘的读写操作。
首先,我们使用清单 16 所示的命令获取 ZFS 池名称:
root@global_zone:~# zpool list NAME SIZE ALLOC FREE CAP DEDUP HEALTH ALTROOT data-node1-pool 556G 56.7G 499G 10% 1.00x ONLINE - data-node2-pool 556G 56.3G 500G 10% 1.00x ONLINE - data-node3-pool 556G 56.4G 500G 10% 1.00x ONLINE - rpool 278G 21.7G 256G 7% 1.00x ONLINE -
清单 16
在清单 16 中,我们可以看到表 4 所示的四个 ZFS zpool。
表 4. Zpool 汇总| 池名称 | 区域名称 | 挂载点 |
|---|---|---|
rpool |
name-nodesec-name-node |
/zones/name-node/zones/sec-name-node |
data-node1-pool |
data-node1 |
/zones/data-node1 |
data-node2-pool |
data-node2 |
/zones/data-node2 |
data-node3-pool |
data-node3 |
/zones/data-node3 |
注:Hadoop 最佳实践是为每个 DataNode 使用单独的硬盘。因此,每个 DataNode 区域都有自己的硬盘,以便提供更好的 I/O 分配,如图 4 所示。
我们可以使用以下命令同时监视所有 ZFS zpool:
root@global_zone:~# zpool iostat -v 10
capacity operations bandwidth
pool alloc free read write read write
------------------------- ----- ----- ----- ----- ----- -----
data-node1-pool 31.1G 525G 2 9 124K 6.49M
c0t5000CCA0160D3264d0 31.1G 525G 2 9 124K 6.49M
------------------------- ----- ----- ----- ----- ----- -----
data-node2-pool 31.0G 525G 2 10 91.0K 6.50M
c0t5000CCA01612A4F0d0 31.0G 525G 2 10 91.0K 6.50M
------------------------- ----- ----- ----- ----- ----- -----
data-node3-pool 31.0G 525G 1 9 103K 6.49M
c0t5000CCA016295ABCd0 31.0G 525G 1 9 103K 6.49M
------------------------- ----- ----- ----- ----- ----- -----
rpool 22.0G 256G 10 7 95.0K 64.1K
c0t5001517803D013B3d0s0 22.0G 256G 10 7 95.0K 64.1K
------------------------- ----- ----- ----- ----- ----- -----
我们还可以下钻,所以我们来监视与 data-node1 区域关联的磁盘。
我们可以将 ZFS 池名称用作参数,观察单个磁盘的读写操作,如清单 17 所示。
root@global_zone:~# zpool iostat -v data-node1-pool 10
capacity operations bandwidth
pool alloc free read write read write
----------------------- ----- ----- ----- ----- ----- -----
data-node1-pool 55.8G 500G 1 8 403K 2.57M
c0t5000CCA0160D3264d0 55.8G 500G 1 8 403K 2.57M
----------------------- ----- ----- ----- ----- ----- -----
capacity operations bandwidth
pool alloc free read write read write
----------------------- ----- ----- ----- ----- ----- -----
data-node1-pool 50.0G 506G 157 18 25.7M 181K
c0t5000CCA0160D3264d0 50.0G 506G 157 18 25.7M 181K
----------------------- ----- ----- ----- ----- ----- -----
capacity operations bandwidth
pool alloc free read write read write
----------------------- ----- ----- ----- ----- ----- -----
data-node1-pool 31.0G 525G 0 21 612 72.721 612 72.7K
c0t5000CCA0160D3264d0 31.0G 525G 0 21 612 72.721 612 72.7K
----------------------- ----- ----- ----- ----- ----- -----
capacity operations bandwidth
pool alloc free read write read write
----------------------- ----- ----- ----- ----- ----- -----
data-node1-pool 31.0G 525G 36 17 19.4M 135K
c0t5000CCA0160D3264d0 31.0G 525G 36 17 19.4M 135K
----------------------- ----- ----- ----- ----- ----- -----
清单 17
在清单 17 中,我们可以通过查看所显示的 bandwidth read 和 bandwidth write 值,了解与 data-node1-pool zpool 池相关联的 c0t5000CCA0160D3264d0 磁盘上发生的读写数据量。
我们还可以使用 iostat 命令查看每台设备处理磁盘 I/O 操作的速度,如清单 18 所示。
root@global_zone:~# iostat -xnz 5 10
extended device statistics
r/s w/s kr/s kw/s wait actv wsvc_t asvc_t %w %b device
1.6 10.8 47.9 3765.1 0.0 0.2 0.1 16.4 0 2 c0t5001517803D013B3d0
1.2 7.1 365.9 2238.4 0.0 0.2 0.1 19.6 0 2 c0t5000CCA0160D3264d0
0.9 8.5 279.4 2237.7 0.0 0.2 0.1 16.7 0 2 c0t5000CCA01612A4F0d0
1.1 8.8 335.9 2237.2 0.0 0.2 0.1 16.3 0 2 c0t5000CCA016295ABCd0
extended device statistics
r/s w/s kr/s kw/s wait actv wsvc_t asvc_t %w %b device
0.0 16.6 0.0 50.1 0.0 0.0 0.0 0.3 0 0 c0t5001517803D013B3d0
31.0 15.6 13346.7 44.4 0.0 0.8 0.0 17.1 0 12 c0t5000CCA0160D3264d0
0.0 15.0 0.0 47.0 0.0 0.0 0.0 1.8 0 1 c0t5000CCA016295ABCd0
extended device statistics
r/s w/s kr/s kw/s wait actv wsvc_t asvc_t %w %b device
0.0 28.6 0.0 249.4 0.0 0.0 0.0 0.4 0 0 c0t5001517803D013B3d0
0.0 15.4 0.0 43.1 0.0 0.0 0.0 1.2 0 0 c0t5000CCA0160D3264d0
88.4 27.6 40257.3 238.9 0.0 2.5 0.0 21.9 1 32 c0t5000CCA016295ABCd0
extended device statistics
r/s w/s kr/s kw/s wait actv wsvc_t asvc_t %w %b device
0.0 15.4 0.0 38.3 0.0 0.0 0.0 0.2 0 0 c0t5001517803D013B3d0
0.0 26.4 0.0 205.7 0.0 0.1 0.0 2.6 0 1 c0t5000CCA0160D3264d0
0.0 14.2 0.0 38.1 0.0 0.0 0.0 1.4 0 0 c0t5000CCA016295ABCd0
清单 18
在清单 18 中,我们可以看到多个磁盘保持中等读取速度 (r/sec),吞吐率量介于 13346 KB/sec 和 40257 KB/sec 之间 (kr/sec),最大延迟约 22 毫秒 (asvc_t)。
可选:您可以使用 -M 选项显示数据吞吐量(单位是 MB/sec,而非 KB/sec)。
注:在非全局区域内执行时,iostat 打印系统中所有磁盘的磁盘 I/O 统计信息。我如何在区域处于空闲状态时查看磁盘活动,这可能有点费解。iostat 命令无法确定其是否运行在非全局区域中,从这个意义上说,它不能感知虚拟化。
另一个有用的工具是 iotop DTrace 脚本,它按进程显示每个 Oracle Solaris 区域最频繁的 I/O 事件,如清单 19 所示。
root@global_zone:~# /usr/dtrace/DTT/iotop -Z 10 10
Tracing... Please wait.
2013 Oct 7 08:40:19, load: 24.38, disk_r: 0 KB, disk_w: 1886 KB
ZONE PID PPID CMD DEVICE MAJ MIN D BYTES
0 717 0 zpool-data-node3 sd6 73 48 W 347648
0 5 0 zpool-rpool sd3 73 24 W 417280
0 896 0 zpool-data-node1 sd4 73 32 W 1195520
清单 19
在清单 19 中,您可以看到区域 ID (ZONE)、进程 ID (PID)、操作类型(读取或写入,D)以及操作的总大小 (BYTES)。
注:要获取区域 ID,您可以使用 zoneadm list -v 命令。
您可以测量应用程序级的读写操作,如清单 20 所示。这将读写操作与系统调用相匹配。
root@global_zone:~# /usr/dtrace/DTT/rwtop -Z 10 10
Tracing... Please wait.
2013 Oct 7 08:41:41, load: 21.88, app_r: 219241 KB, app_w: 306995 KB
ZONE PID PPID CMD D BYTES
3 3792 13851 java R 2588146
3 3725 13851 java R 2637274
6 4263 13929 java R 2662831
3 5382 138513 5382 13851 java R 2684596
6 3951 13929 java R 2697760
6 5508 13929 java R 2725159
6 4403 13929 java R 2760624
6 3482 139296 3482 13929 java R 2804553
6 5721 13929 java R 2809765
6 3494 139296 3494 13929 java R 2940105
3 3847 13851 java R 2961552
6 4509 13929 java R 2994121
6 4109 13929 java R 3060994
3 3660 13851 java R 3099585
6 3749 13929 java R 3161943
3 3435 13851 java R 3531230
6 3663 13929 java R 3730160
3 5101 138513 5101 13851 java R 3968720
6 4823 13929 java R 4030110
3 3905 13851 java R 4037610
3 4654 13851 java R 4106273
3 5230 138513 5230 13851 java R 4608408
3 4654 13851 java W 22666584
3 5101 138513 5101 13851 java W 23468253
6 5258 13929 java W 28658892
3 13851 1 java R 50977972
3 13851 1 java W 50999762
6 13929 1 java W 59310428
6 13929 1 java R 59433776
3 5382 138513 5382 13851 java W 88006519
3 5230 138513 5230 13851 java W 88185430
清单 20
在清单 20 中,我们可以看到 rwtop 命令对磁盘 I/O 最忙碌的进程进行排序,打印区域名称 (ZONE)、进程名称 (CMD)、操作是读取还是写入 (D) 以及已读取或写入的字节数 (BYTES)。
接下来,我们可以使用 DTrace iopattern 脚本分析磁盘 I/O 模式,以确定其为随机模式还是有序模式,如清单 21 所示。
root@global_zone:~# /usr/dtrace/DTT/iopattern %RAN %SEQ COUNT MIN MAX AVG KR KW 69 31 236 1024 1048576 448830 103441 0 75 25 577 512 1048576 327938 184306 479 92 8 598 512 1048576 198293 114275 1525 74 26 379 512 1048576 330296 121954 294 66 34 281 1024 1048576 500550 137358 0 80 20 346 1024 1048576 332114 112218 0 81 19 444 512 1048576 290734 124694 1366 65 35 337 512 1048576 490375 161139 244 75 25 704 512 1048576 353086 241105 1642 75 25 444 1024 1048576 386634 167642 0 77 23 666 1024 1048576 397105 258274 0 77 23 853 512 1048576 385908 320740 725 77 23 525 512 1048576 345048 175352 1553 68 32 253 512 1048576 508290 125355 228 64 36 237 1024 1048576 501317 116027 0
清单 21
清单 21 中的输出显示以下项目:
%RAN列显示随机事件的百分比。%SEQ列显示有序事件的百分比。COUNT列显示 I/O 事件数量。MIN列显示最小的 I/O 事件大小。MAX列显示最大的 I/O 事件大小。AVG列显示平均 I/O 事件大小。KR列显示本例中读取的总千字节数。KW列显示本例中写入的总千字节数。
从脚本输出可以看出,I/O 负载主要为随机读取(%RAN 和 KR)。
注:如果大多数 I/O 负载均为随机负载,我们可以使用 闪存设备 提升 I/O 性能。
监视虚拟化环境中的内存利用率
在下一个示例中,我们将监视内存子系统。表 5 显示我们将用来监视内存利用率的命令汇总。
表 5. 命令汇总| 命令 | 说明 |
|---|---|
vmstat |
报告可用内存量 |
prstat |
报告活动进程统计信息 |
zonestat |
报告活动区域统计信息 |
zvmstat |
显示每个区域的 vmstat 风格信息 |
首先,我们来打印系统的物理内存:
root@global_zone:~# prtconf -v | grep Mem Memory size: 262144 Megabytes
我们可以看到,系统有 256 GB 内存。
然后,详细了解系统内存是如何分配的,如清单 22 所示。
root@global_zone:~# echo ::memstat | mdb -k Page Summary Pages MB %Tot ------------ ---------------- ---------------- ---- Kernel 1473974 11515 4% ZFS File Data 4990336 38987 15% Anon 2223697 17372 7% Exec and libs 3342 26 0% Page cache 5244141 40969 16% Free (cachelist) 27122 211 0% Free (freelist) 19591820 153061 58% Total 33554432 262144
清单 22
清单 22 所示的类别如下:
Kernel。用于不可分页内核分配的总内存。即内核所使用的内存大小。ZFS File Data。ZFS 自适应替换缓存 (ARC) 所使用的内存总量。Anon。匿名内存量。其中包括用户进程堆、栈、写入时复制页面和共享内存映射。Exec and libs。用于用户二进制文件和共享二进制文件的内存总量。Page cache。未映射的页面缓存量,即缓存列表上没有的页面缓存。此类别还包括 /tmp 中的文件。Free (cachelist)。空闲列表上的页面缓存量。空闲列表包含未映射的文件页面,通常还包含大多数文件系统缓存。Free (freelist)。实际空闲的内存量。这部分内存与任何文件或进程均无关联。
要了解系统当前可用的空闲内存量,可以使用 vmstat 命令(如清单 23 所示)查看除第一行以外任意行的 free 列中的值(单位为 KB)。(vmstat 的第一行表示从启动到现在的信息汇总。)
root@global_zone:~# vmstat 10 kthr memory page disk faults cpu r b w swap free re mf pi po fr de sr s3 s4 s5 s6 in sy cs us sy id 1 0 0 202844144 233325872 315 1311 0 0 0 0 1 15 19 19 18 23352 32919 46222 3 4 93 4 0 0 110774160 142093304 347 3681 0 0 0 0 0 0 27 15 18 72275 48754 148884 1 11 88 5 0 0 110862440 142055728 347 3671 0 0 0 0 0 19 15 22 16 72286 48292 148838 1 11 88 3 0 0 111113056 142043608 331 3525 0 0 0 0 0 0 20 29 20 70099 49362 143970 1 11 88
清单 23
清单 23 显示系统的空闲内存约为 138 GB。这部分内存与任何文件或进程均无关联。
为了确定系统的物理内存是否已所剩无几,请查看清单 23 所示的 vmstat 输出中的 sr 列,其中 sr 表示扫描速度。在内存所剩无几的情况下,Oracle Solaris 会开始扫描最近未访问过的内存页,并将其移至空闲列表。使用 Oracle Solaris 时,sr 的非零值表示系统的物理内存所剩无几。
您还可以使用 vmstat -p 查看内存页调入、调出以及释放活动,如清单 24 所示。
root@global_zone:~# vmstat -p 10
memory page executable anonymous filesystem
swap free re mf fr de sr epi epo epf api apo apf fpi fpo fpf
201865936 232351696 315 1332 0 0 1 0 0 0 0 0 0 0 0 0
111431576 141932424 264 2779 0 0 0 0 0 0 0 0 0 0 0 0
111179136 141752728 243 2580 0 0 0 0 0 0 0 0 0 0 0 0
110802088 141459648 247 2656 0 0 0 0 0 0 0 0 0 0 0 0
清单 24
从清单 24 中的 vmstat 输出,我们可以看到三种类型的内存:
- 可执行文件(
epi、epo、epf)内存页,用于程序和库文本。 - 匿名(
api、apo、apf)内存页,与文件无关。例如,匿名内存用于进程堆和栈。再比如,进程页换入或换出时,api和apo列的数值通常比较大。 - 文件系统(
fpi、fpo、fpf)内存页,用于文件 I/O。
有关 Oracle Solaris 应用程序内存管理的更多信息,请参见“Solaris 应用程序内存管理。”
我们可以用来查看系统和虚拟机(非全局区域)进程统计信息的第三个命令是 prstat 命令,如清单 25 所示:
root@global_zone:~# prstat -ZmLc
PID USERNAME SIZE RSS STATE PRI NICE TIME CPU PROCESS/NLWP
20025 hadoop 293M 253M cpu60 59 0 0:00:49 12% java/68
20739 hadoop 285M 241M sleep 59 0 0:00:49 10% java/68
17206 hadoop 285M 237M sleep 59 0 0:01:07 10% java/68
17782 hadoop 281M 229M sleep 59 0 0:00:57 7.4% java/67
17356 hadoop 289M 241M sleep 59 0 0:01:04 7.0% java/68
11621 hadoop 166M 126M sleep 59 0 0:02:32 5.9% java/90
20924 hadoop 289M 237M sleep 59 0 0:00:49 5.3% java/68
17134 hadoop 289M 237M sleep 59 0 0:01:04 5.1% java/67
17498 hadoop 297M 257M sleep 59 0 0:00:57 4.8% java/68
17298 hadoop 297M 253M sleep 59 0 0:01:05 4.6% java/68
17940 hadoop 297M 249M sleep 59 0 0:00:52 4.3% java/68
18474 hadoop 289M 237M sleep 59 0 0:00:49 3.9% java/67
19600 hadoop 297M 253M sleep 59 0 0:00:49 3.8% java/68
20617 hadoop 297M 249M sleep 59 0 0:00:49 3.7% java/67
17432 hadoop 297M 249M sleep 59 0 0:01:03 3.6% java/68
ZONEID NPROC SWAP RSS MEMORY TIME CPU ZONE
4 74 7246M 6133M 2.3% 2:31:34 43% data-node2
3 53 7442M 6248M 2.4% 2:23:01 30% data-node1
5 52 7108M 6001M 2.3% 2:27:40 22% data-node3
2 32 675M 468M 0.1% 0:04:36 4.0% name-node
0 82 870M 414M 0.1% 1:19:20 1.0% global
Total: 322 processes, 8024 lwps, load averages: 15.54, 18.25, 20.09
清单 25
从清单 25 中的 prstat 输出可以看到每个 Oracle Solaris 区域的以下信息:
SWAP列显示每个区域的总虚拟内存大小。RSS列显示区域驻留集总大小(主内存使用量)。MEMORY列显示消耗的主内存占整个系统资源的百分比。CPU列显示消耗的 CPU 占整个系统资源的百分比。ZONE列显示每个区域的名称。
要查看每个区域的详细内存统计信息,可以使用 zonestat 命令。例如,可以使用 zonestat -r 命令分析内存利用率,如清单 26 所示。
root@global_zone:~# zonestat -r memory 10
Collecting data for first interval...
Interval: 1, Duration: 0:00:10
PHYSICAL-MEMORY SYSTEM MEMORY
mem_default 256G
ZONE USED %USED CAP %CAP
[total] 87.0G 34.0% - -
[system] 68.9G 26.9% - -
data-node2 5956M 2.27% - -
data-node1 5942M 2.26% - -
data-node3 5702M 2.17% - -
name-node 444M 0.16% - -
global 285M 0.10% - -
sec-name-node 219M 0.08% - -
VIRTUAL-MEMORY SYSTEM MEMORY
vm_default 259G
ZONE USED %USED CAP %CAP
[total] 122G 47.0% - -
[system] 42.3G 16.2% - -
data-node2 27.1G 10.4% - -
data-node3 25.8G 9.96% - -
data-node1 25.4G 9.78% - -
name-node 762M 0.28% - -
sec-name-node 416M 0.15% - -
global 388M 0.14% - -
LOCKED-MEMORY SYSTEM MEMORY
mem_default 256G
ZONE USED %USED CAP %CAP
[total] 15.7G 6.16% - -
[system] 15.7G 6.16% - -
data-node1 0 0.00% - -
data-node2 0 0.00% - -
data-node3 0 0.00% - -
global 0 0.00% - -
name-node 0 0.00% - -
sec-name-node 0 0.00% - -
清单 26
清单 26 所示的输出显示了用于物理内存 (PHYSICAL-MEMORY)、虚拟内存 (VIRTUAL-MEMORY) 以及锁定内存 (LOCKED-MEMORY) 的内存大小,其中虚拟内存是物理内存的抽象。例如,有权限的进程可以锁定虚拟内存,表示这部分内存不会被调出。我们可用来监视虚拟化环境中内存利用率的另一个命令是 zvmstat 命令,其打印每个区域的 vmstat 输出,如清单 27 所示。
root@global_zone:~# /usr/dtrace/DTT/Bin/zvmstat 10
ZONE re mf fr sr epi epo epf api apo apf fpi fpo fpf
global 273 218 0 0 0 0 0 0 0 0 0 0 0
sec-name-node 0 0 0 0 0 0 0 0 0 0 0 0 0
name-nodenode 0 0 0 0 0 0 0 0 0 0 0 0 0
data-node1ode 0 0 0 0 0 0 0 0 0 0 0 0 0
data-node2ode 0 0 0 0 0 0 0 0 0 0 0 0 0
data-node3ode 0 0 0 0 0 0 0 0 0 0 0 0 0
清单 27
清单 27 显示了以下项目:
Zone列显示区域名称。re列显示页回收数量。mf列显示小故障数量。fr列显示释放的页数量。sr列显示扫描速度。epi列显示调入的可执行文件页数量。vepo列显示调出的可执行文件页数量。epf列显示释放的可执行文件页数量。api列显示调入的匿名页数量。apo列显示调出的匿名页数量。apf列显示释放的匿名页数量。fpi列显示调入的文件系统页数量。fpo列显示调出的文件系统页数量。fpf列显示释放的文件系统页数量。
例如,通过显示 name-node 区域的内存利用率,我们可以明确内存统计信息并检查特定区域。
root@global_zone:~# prstat -mLz name-node
让我们下钻到 data-node1 区域,查看内存统计信息。如何检查特定 Oracle Solaris 区域来查看占用物理内存的进程?
首先,登录区域:
root@global_zone:~# zlogin data-node1
然后,我们可以使用清单 28 所示的命令,根据进程的内存驻留集大小 (RSS)(其为 RAM 保存的进程内存的一部分)对进程进行排序。最大的内存占用项列在顶部。
root@data-node1:~# prstat -s rss PID USERNAME SIZE RSS STATE PRI NICE TIME CPU PROCESS/NLWP 10236 hadoop 179M 151M cpu20 52 0 0:05:26 8.5% java/132 11365 hadoop 193M 140M sleep 59 0 0:00:55 3.0% java/63 11381 hadoop 189M 136M cpu29 20 0 0:00:55 5.5% java/63 11346 hadoop 189M 120M cpu44 10 0 0:00:58 5.2% java/63 10648 hadoop 204M 120M sleep 59 0 0:02:09 0.1% java/151 11355 hadoop 165M 112M cpu8 50 0 0:00:56 6.1% java/63 11319 hadoop 165M 112M sleep 59 0 0:00:56 1.3% java/63 11337 hadoop 165M 112M cpu30 50 0 0:00:52 4.2% java/63 11327 hadoop 165M 112M cpu40 20 0 0:00:57 3.0% java/63 11332 hadoop 165M 112M cpu122 20 0 0:00:57 3.2% java/63 11323 hadoop 161M 108M sleep 10 0 0:00:56 5.2% java/63 11374 hadoop 149M 96M cpu88 10 0 0:00:55 3.2% java/63 7109 root 18M 18M sleep 59 0 0:00:11 0.0% svc.configd/17 7073 root 35M 17M sleep 59 0 0:00:05 0.0% svc.startd/14 9392 root 22M 16M sleep 59 0 0:00:00 0.0% fmd/11 Total: 43 processes, 1047 lwps, load averages: 31.82, 8.25, 3.02
清单 28
在清单 28 中,我们可以看到 hadoop 进程占用的 RSS 内存最多。
监视虚拟化环境中的网络利用率
在最后一个示例中,我们将监视网络性能。表 6 显示了将用于此操作的命令汇总。
表 6. 命令汇总| 命令 | 说明 |
|---|---|
dladm |
管理数据链路 |
dlstat |
报告数据链路统计信息 |
zonestat |
报告活动区域统计信息 |
flowadm |
管理带宽资源控制 |
flowstat |
报告流统计信息 |
在 Hadoop 集群中,大多数网络流量用于在 DataNode 之间复制 HDFS 数据。
我们需要回答以下问题:
- 哪些区域的网络流量最高,哪些区域的网络流量最低?
- 根据当前处理的网络连接数量,哪个区域最繁忙?
- 如何监视特定网络资源,例如 Oracle Solari 区域、物理网卡或虚拟网络接口卡 (VNIC)。
首先,我们使用 dladm 命令查看网络设置,以显示物理网卡的数量:
root@global_zone:~# dladm show-phys LINK MEDIA STATE SPEED DUPLEX DEVICE net0 Ethernet up 1000 full ixgbe0 net2 Ethernet unknown 0 unknown ixgbe2 net1 Ethernet unknown 0 unknown ixgbe1 net3 Ethernet unknown 0 unknown ixgbe3 net4 Ethernet up 10 full usbecm0
现在,使用 dladm 命令打印 VNIC 信息,如清单 29 所示。
root@global_zone:~# dladm show-vnic LINK OVER SPEED MACADDRESS MACADDRTYPE VID name_node1 net0 1000 2:8:20:d4:31:b3 random 0 name-node/name_node1 net0 1000 2:8:20:d4:31:b3 random 0 secondary_name1 net0 1000 2:8:20:41:78:4b random 0 sec-name-node/secondary_name1 net0 1000 2:8:20:41:78:4b random 0 data_node1 net0 1000 2:8:20:f:3f:f7 random 0 data-node1/data_node1 net0 1000 2:8:20:f:3f:f7 random 0 data_node2 net0 1000 2:8:20:d0:38:ea random 0 data-node2/data_node2 net0 1000 2:8:20:d0:38:ea random 0 data_node3 net0 1000 2:8:20:54:da:7b random 0 data-node3/data_node3 net0 1000 2:8:20:54:da:7b random 0 sec-name-node/net0 net0 1000 2:8:20:da:2e:5b random 0 name-node/net0 net0 1000 2:8:20:30:cc:45 random 0 data-node1/net0 net0 1000 2:8:20:8b:7b:f6 random 0 data-node2/net0 net0 1000 2:8:20:6a:3f:38 random 0 data-node3/net0 net0 1000 2:8:20:5d:7:8e random 0
清单 29
如清单 29 所示,dladm 打印相关的物理接口 (OVER)、速度 (SPEED)、MAC 地址 (MACADDRESS) 以及 VLAN ID (VID)。
可以看到,我们有五个 VNIC,每个区域一个,如图 5 所示。
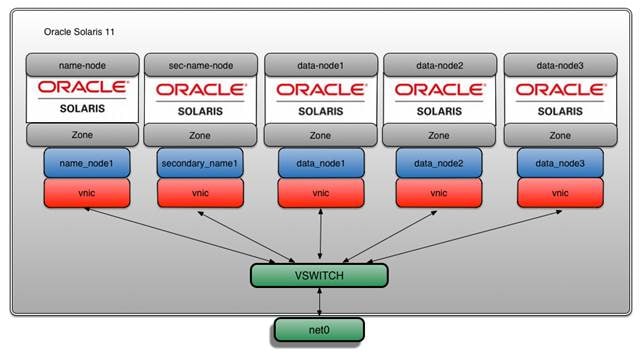
图 5. VNIC
我们可以使用带 -r 和 -x 选项的 zonestat 命令获取更多网络信息,以明确特定 Oracle Solaris 区域的统计信息,例如,监视三个 DataNode 区域(data-node1、data-node2 和 data-node3)上的网络流量,如清单 30 所示。
root@global_zone:~# zonestat -z data-node1 -z data-node2 -z data-node3 -r network -x 10
Collecting data for first interval...
Interval: 1, Duration: 0:00:10
NETWORK-DEVICE SPEED STATE TYPE
net0 1000mbps up phys
ZONE LINK TOBYTE MAXBW %MAXBW PRBYTE %PRBYTE POBYTE %POBYTE
[total] net0 269M - - 198 0.00% 18.4E 100%
global net0 2642 13474770085G - 198 0.00% 284 0.00%
data-node1 data-node1/net0 93.6M - - 0 0.00% 18.4E 100%
data-node3 data-node3/net0 91.3M - - 0 0.00% 18.4E 100%
data-node2 data-node2/net0 84.4M - - 0 0.00% 18.4E 100%
name-node name-node/net0 304K - - 0 0.00% 18.4E 100%
data-node3 data_node3 2340 - - 0 0.00% 0 0.00%
sec-name-node sec-name-node/net0 2340 - - 0 0.00% 0 0.00%
data-node2 data_node2 2280 - - 0 0.00% 0 0.00%
name-node name_node1 2280 - - 0 0.00% 0 0.00%
data-node1 data_node1 2220 - - 0 0.00% 0 0.00%
sec-name-node secondary_name1 2220 - - 0 0.00% 0 0.00%
清单 30
清单 30 中的命令输出显示以下内容:
- 数据链路的名称 (
LINK) - 数据链路或虚拟链路发送和接收的字节数 (
TOBYTE) - 数据链路上配置的最大带宽 (
MAXBW) - 所有发送和接收的总字节数占所配置最大带宽的百分比 (
%MAXBW) - 已接收的消耗物理带宽的字节数 (
PRBYTE) - 可用于接收
PRBYTE的物理带宽百分比 (%PRBYE) - 已发送的消耗物理带宽的字节数 (
POBYTE) - 可用于发送
POBYTE的物理带宽百分比 (%POBYE)
可以使用 dlstat 命令监视与三个 DataNode 相关联的三个 VNIC,如清单 31 所示。
root@global_zone:~# dlstat -z data-node1,data-node2,data-node3 -i 10
LINK IPKTS RBYTES OPKTS OBYTES
data-node1/data_node1 25.89K 1.57M 0 0
data-node2/data_node2 25.89K 1.57M 0 0
data-node3/data_node3 25.89K 1.57M 0 0
data-node1/net0 49.32M 54.99G 15.24M 52.59G
data-node2/net0 49.88M 55.80G 15.66M 54.16G
data-node3/net0 49.29M 54.60G 14.98M 52.95G
data-node1/data_node1 27 1.62K 0 0
data-node2/data_node2 27 1.62K 0 0
data-node3/data_node3 27 1.62K 0 0
data-node1/net0 50.69K 55.93M 16.06K 56.24M
data-node2/net0 49.20K 56.13M 16.32K 50.86M
data-node3/net0 46.87K 51.50M 13.90K 50.45M
清单 31
如清单 31 所示,dlstat 命令显示了以下信息:
- 入站数据包数量 (
IPKTS) - 已接收的字节数 (
RBYTES) - 出站数据包数量 (
OPKTS) - 已发送的字节数 (
OBYTES)
我们可以下钻到特定网络资源,例如,可以监视物理网络接口 (net0):
root@global_zone:~# dlstat net0 -i 10
LINK IPKTS RBYTES OPKTS OBYTES
net0 39.41K 2.63M 8.16K 1.44M
net0 45 2.74K 1 198
net0 43 2.61K 1 150
net0 41 2.47K 1 150
^C
注:要停止 dlstat 命令,请按 Ctrl-c。
我们也可以只监视与 data-node1 区域关联的 VNIC:
root@global_zone:~# dlstat name_node1 -i 10
LINK IPKTS RBYTES OPKTS OBYTES
data_node1 26.30K 1.59M 0 0
data_node1 42 2.70K 0 0
data_node1 43 2.58K 0 0
data_node1 31 1.86K 0 0
^C
注:从非全局区域运行时,dlstat 仅显示该区域链路的统计信息。非全局区域无法查看其他区域的链路。
验证数据集
如“监视虚拟化环境中的磁盘 I/O 活动”部分所述,MapReduce 基准测试包括三个阶段。MapReduce 基准测试的最后一步是验证数据是否已排序。
首先,更改文件权限以执行 .jar 文件:
root@global_zone:~# chmod +x /usr/local/hadoop/hadoop-test-1.2.0.jar
然后,为了验证已排序数据是否准确,我们将运行 testmapredsort 程序对未排序和已排序数据执行一系列检查。
我们通过运行以下命令来确定已排序数据是否已真正排序:
root@global_zone:~# zlogin -l hadoop name-node hadoop jar /usr/local/hadoop/hadoop-test-1.2.0.jar testmapredsort -sortInput random-data -sortOutput sorted-data
其中:
zlogin -l hadoop name-node表示命令作为hadoop用户在name-node区域上运行。hadoop jar /usr/local/hadoop/hadoop-test-1.2.0.jar testmapredsort表示 Hadoop.jar文件。-sortInput random-data表示随机数据的输入目录。-sortOutput sorted-data表示已排序数据的输出目录。
如果数据经验证已排序,那么将显示以下消息:
SUCCESS! Validated the MapReduce framework's 'sort' successfully.
监视特定 TCP 或 UDP 网络端口上两个系统之间的网络流量
我们还可以监视特定 TCP 或 UDP 端口上的网络流量。如果我们想监视如何在两个 Hadoop 集群之间复制数据,这非常有用。例如,监视 Hadoop 集群 A 中的数据如何复制到 Hadoop 集群 B(位于不同的数据中心),如图 6 所示。
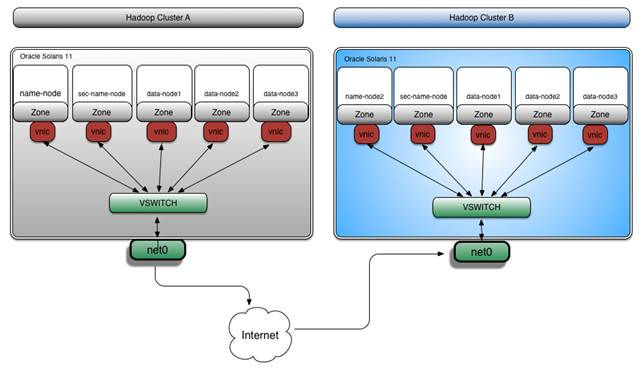
图 6. 在 Hadoop 集群之间复制数据
要在 Hadoop 集群之间复制数据,可使用 distcp 命令,这个内置的 Hadoop 命令用于在 Hadoop 集群之间复制数据。
root@global_zone:~# zlogin -l hadoop name-node hadoop distcp "hdfs://name-node:8020/benchmarks hdfs://name-node2:8020/backup"
注:name-node 是第一个集群上 NameNode 的主机名称,name-node2 是第二个集群上 NameNode 的主机名称。
如果要监视 distcp 使用的特定 TCP 端口 (8020) 上这些集群之间的网络流量,可以使用流。
流 是新的 Oracle Solaris 11 网络虚拟化架构中内置的复杂的服务质量 (QoS) 机制,让我们能够统计或限制特定网络接口上特定网络端口的网络带宽。此外,还可在全局区域和非全局区域创建、修改和删除流。
在以下示例中,我们将创建 name_node1 VNIC 上与 TCP 网络端口 8020 相关联的流。
首先,登录 name-node 区域:
root@global_zone:~# zlogin name-node
现在,在 name_node1 VNIC 上创建流:
root@name-node:~# flowadm add-flow -l name_node1 -a transport=TCP,local_port=8020 distcp-flow
注:无需重新启动区域即可启用或禁用流。这在需要调试生产系统上的网络性能问题时非常有用!
验证流的创建,如清单 32 所示:
root@name_node:~# flowadm show-flow FLOW LINK IPADDR PROTO LPORT RPORT DSFLD distcp-flow name_node1 -- tcp 8020 -- -
清单 32
在清单 32 中,您可看到相关 VNIC (name_node1) 和 TCP 端口号 (8020) 的 distcp-flow 流。
在 name_node 区域,我们可以使用 flowstat(1M) 命令报告关于用户定义的流的运行时统计信息。此命令只能报告接收端或发送端的统计信息。此外,此命令还可显示特定链路上所有流的统计信息或特定流的统计信息。
要报告监视 TCP 端口 8020 的 distcp-flow 流的带宽,请使用清单 33 所示的命令:
root@name_node:~# flowstat -i 1 FLOW IPKTS RBYTES IDROPS OPKTS OBYTES ODROPS distcp-flow 24.72M 37.17G 0 3.09M 204.08M 0 distcp-flow 749.28K 1.13G 0 93.73K 6.19M 0 distcp-flow 783.68K 1.18G 0 98.03K 6.47M 0 distcp-flow 668.83K 1.01G 0 83.66K 5.52M 0 distcp-flow 783.87K 1.18G 0 98.07K 6.47M 0 distcp-flow 775.34K 1.17G 0 96.98K 6.40M 0 distcp-flow 777.15K 1.17G 0 97.21K 6.42M 0 ^C
清单 33
注:要停止 flowstat 命令,请按 Ctrl-c。
在清单 33 中可以看到,flowstat 命令显示 TCP 端口 8020 的网络统计信息。而且,启用 name_node1 网络接口上的流不会降低网络性能!
可选:完成网络测量之后,您可以删除流:
root@name_node:~# flowadm remove-flow distcp-flow
然后验证流的删除:
root@name_node:~# flowadm show-flow
注:无需重新启动区域即可删除流;这在生产环境中非常有用。
有关网络性能监视的更多示例,请参见“使用 Oracle Solaris 11 工具进行高级网络监视。”
清理任务
(可选)完成基准测试后,可以使用以下命令从 HDFS 删除生成的所有文件:
root@global_zone:~# zlogin -l hadoop name-node hadoop dfs -rmr hdfs://name-node/user/hadoop/random-data root@global_zone:~# zlogin -l hadoop name-node hadoop dfs -rmr hdfs://name-node/user/hadoop/sorted-data
总结
在本文中,我们了解了如何利用新的 Oracle Solaris 11 性能分析工具观察和监视托管 Hadoop 集群的虚拟化环境。
另请参见
- “如何控制应用程序的网络带宽”
- Oracle Solaris 11.1 管理:Oracle Solaris 区域、Oracle Solaris 10 区域和资源管理
- “如何为 Oracle Solaris 11 构建本地 Hadoop 库”
另请参见该作者发表的其他文章:
- “如何使用 Oracle Solaris 搭建 Hadoop 集群”
- “使用 Oracle Solaris 11 工具进行高级网络监视”
- “如何使用 Oracle Solaris 区域搭建 MongoDB NoSQL 集群”
- “如何使用 Oracle Solaris 区域搭建 Hadoop 集群”
- “如何将 Oracle 数据库从 Oracle Solaris 8 迁移至 Oracle Solaris 11”
- “使用 Oracle VM Server for SPARC 的实时迁移特性提高应用程序可用性:Oracle Database 示例”
- “Traffix Systems 如何使用 Oracle 硬件和软件优化其 LTE Diameter 负载平衡和路由解决方案”
- Orgad 的博客:虚拟化艺术:云计算和虚拟化用例与教程
下面是其他 Oracle Solaris 11 资源:
- 下载 Oracle Solaris 11
- 访问 Oracle Solaris 11 产品文档
- 访问所有 Oracle Solaris 11 方法文章
- 通过 Oracle Solaris 11 培训和支持了解更多信息
- 阅读官方 Oracle Solaris 博客
- 阅读 The Observatory 和 OTN Garage 博客,获得 Oracle Solaris 提示和技巧
- 在 Facebook 和 Twitter 上关注 Oracle Solaris
关于作者
Orgad Kimchi 是 Oracle(之前任职于 Sun Microsystems)ISV 工程小组的首席软件工程师。6 年来,他一直专注于虚拟化、大数据和云计算技术。
| 修订版 1.0,2013 年 12 月 16 日 |